基于PLSA的新闻评论情绪类别自动标注方法①
2019-01-18林江豪顾也力周咏梅阳爱民
林江豪, 顾也力, 周咏梅, 阳爱民
1(广东外语外贸大学 语言工程与计算实验室, 广州 510006)
2(广东外语外贸大学 东方语言文化学院, 广州 510420)
3(广东外语外贸大学 信息科学与技术学院, 广州 510006)
网络新闻是社会事件传播的载体, 人们通过评论新闻参与事件, 形成了海量信息. 对新闻评论文本进行情绪分析可应用到舆情管理、民意调查、商业营销情报等领域, 有着广阔的应用空间和发展前景[1,2]. 新闻评论语料库是进行新闻评论情绪分析研究的重要基础,要提高语料的利用价值, 关键在于语料的标注, 所谓标注[3]就是对语料库中的原始语料进行加工, 把各种表示语言特征的附码标注在相应的语言成分上, 以便于计算机的识读. 然而, 规模庞大的评论文本如果通过人工标注, 是非常困难的. 当前在文本情绪分析研究领域还没有标准的语料库, 特别是细粒度的情绪标注语料库更是缺乏, 这在一定程度上影响了该领域的研究. 为了减轻标注人员的负担, 提高标注的效率和精确度, 减少标注的错误率, 非常有必要研究自动标注方法, 以便协助标注人员的工作. 因此, 探索研究新闻评论文本情绪类别自动标注方法是一项非常重要的工作.
目前, 在文本自动标注领域, 文献[4]提出了一种汉语意见型主观性文本标注语料库的构建方法, 重点讨论了语料的选取、标注、存储、检索和统计等工作.阳爱民等提出了中文微博语料情感类别自动标注的方法, 包括基于关键词的、基于概率求和的和基于概率乘积的3种自动标注方法和一种集成标注方法, 实验验证了集成方法的准确率可达到90%以上[5]. 文献[6]对网络新闻评论数据的特点进行归纳总结, 选取不同的特征集、特征维度、权重计算方法和词性等因素进行文本情感自动标注. 文献[7]使用机器学习方法进行新闻的情感自动标注, 发现选择具有语义倾向的词汇作为特征项、对否定词正确处理和采用二值作为特征项权重能提高分类的准确率, 准确率能达到90%. 文献[8]基于语义的方法, 实现了微博情感类别的自动标注.文献[9]通过抽取主题句, 将抽取到的主题句与JST模型结合, 对新闻评论文本进行情感标注. 吴江等基于语义规则, 对金融领域的文本进行情感标注[10]. Khoo等[11]案例分析了基于认知理论的在线新闻文本情感标注方法. Moreo等[12]提出了一种基于词典的新闻评论情感自动标注系统(LCN-SA), 多维度分析网民的情感倾向.Penalver-Martinez等[13]运用本体论, 提出了基于特征的观点挖掘方法. 国内已公开的人工标注语料包括NLPCC评测的语料、谭松波等人标注的酒店评论语料等.
在现有语料情感类别自动标注研究中, 主要将标注结果设定为正向和负向来进行研究, 这种方法下自动标注的语料不能适用于细粒度的文本情绪分析. 鉴于此, 本文以新闻评论的乐、好、怒、哀、惧、恶、惊七类情绪作为标注的类别, 提出一种基于概率潜在语义分析 (Probabilistic Latent Semantic Analysis, PLSA)的新闻评论情绪类别自动标注方法. 这种方法通过利用PLSA计算获得语料集的“文档-主题”和“词语-主题”概率矩阵, 基于“词语-主题-文档”之间的概率转换关系, 认为某一类情绪词汇出现的概率最高的主题与词汇的情绪类别相同, 对主题进行情绪类别标注; 认为出现在某一主题概率最高的文档与主题的情绪类别相同, 对文档进行情绪类别标注, 达到自动标注的效果.文章的内容安排如下, 第1节重点介绍了基于PLSA的新闻评论情绪自动标注方法; 第2节给出了基于PLSA的概率矩阵抽取方法; 第3节对文本提出的方法进行实验验证和分析; 第4节给出了结论以及下一步的改进方向.
1 基于PLSA的新闻评论情绪自动标注方法概述
本文采用如图1所示的新闻评论情绪自动标注方法, 首先将采集的新闻评论集进行文本预处理, 分词后过滤掉停用词和无用词, 进行词频统计, 获得“文档-词汇”矩阵; 接着, 利用 PLSA 模型计算, 获得“词汇-主题”和“文档-主题”概率矩阵; 结合情感本体库[14]和“词汇-主题”, 认为某一类情绪词汇出现的概率最高的主题与词汇的情绪类别相同, 对主题进行情绪类别标注; 最后,基于“文档-主题”概率矩阵, 认为出现在某一主题概率最高的文档与主题的情绪类别相同, 达到对文档情绪类别的自动标注.
根据图 1, 用[Mword-topic]m×k和“文档-主题”矩阵[Mdoc-topic]n×k来表示分类为k个主题的PLSA计算结果, 其中[Mword-topic]m×k表示词汇在对应主题中的概率,也即词汇对主题的贡献度, 则对于词汇wordj在k个主题中的概率p有pj1+pj2+…+pjk=1. 分别对每个主题下的词语概率按照由大到小排序, 利用情感本体库OL,抽取概率高的情绪词汇, 对情绪词汇的情绪强度直接加总计算, 得到主题在每一类情绪中的强度, 则主题在m类情绪中的权重分布Et={e1,e2,e3,···,em}, 通过判断Et中的最大值, 获得主题的情绪类别. 同理, 利用“文档-主题”矩阵, 认为对主题贡献度高的文档与主题的情绪类别相同, 对文档的情绪类别进行标注. 则基于PLSA的新闻评论情绪自动标注算法如算法1.

算法1. 基于PLSA的新闻评论情绪自动标注算法输入: 情感本体库OL, 语料集Data_set输出: [doc, e]m

步骤1. 对Data_set进行预处理, 包括分词、词频统计等, 获得“文档-词频”矩阵 Mt;步骤 2. 计算 PLSA(Mt)→“词汇-主题”矩阵[Mword-topic]m×k 和“文档-主题”矩阵[Mdoc-topic]n×k;Zk={[w1,w2,w3,··,wo]1,[w1,w2,w3,··,wp]2,··,步骤3. 逐列对[Mword-topic]m×k进行排序, 获取每个主题zj中概率较高的情绪词汇, 得到;EZk={[wt1,wt2,wt3,··,wto]1,[w1,w2,w3,··,wq]k}步骤4. 在情感本体库查询情绪词的权重, 得到主题的情绪权重矩阵[wt1,wt2,wt3,··,wtp]2,··,[wt1,wt2,wt3,··,wtq]k};步骤 5. 对每个主题 zj的情绪权重进行加总, 得到;{[e1,e2,e3,··,em]1,[e1,e2,e3,··,em]2,··,[e1,e2,e3,··,em]k}Etk=

步骤6. 逐列对Etk进行排序, 获得情绪强度最强的类别为对应主题的情绪, 则主题情绪标注结果为ZEk;步骤 7. 逐列对[Mdoc-topic]n×k 进行排序, 结合 ZEk, 将对主题贡献度高文档的情绪类别标注为主题的情绪类别, 对每一个doc获得对应的情绪类别e;结束. 输出[doc, e]n.
算法的最终输出为[doc,e]m, 为验证该标注结果的准确性, 本文采集了凤凰网涉及中日关系的新闻评论语料, 自动筛选出含有两个情绪词汇以上的评论语料, 进行人工标注, 与自动标注结果对比验证[doc,e]m的准确率.
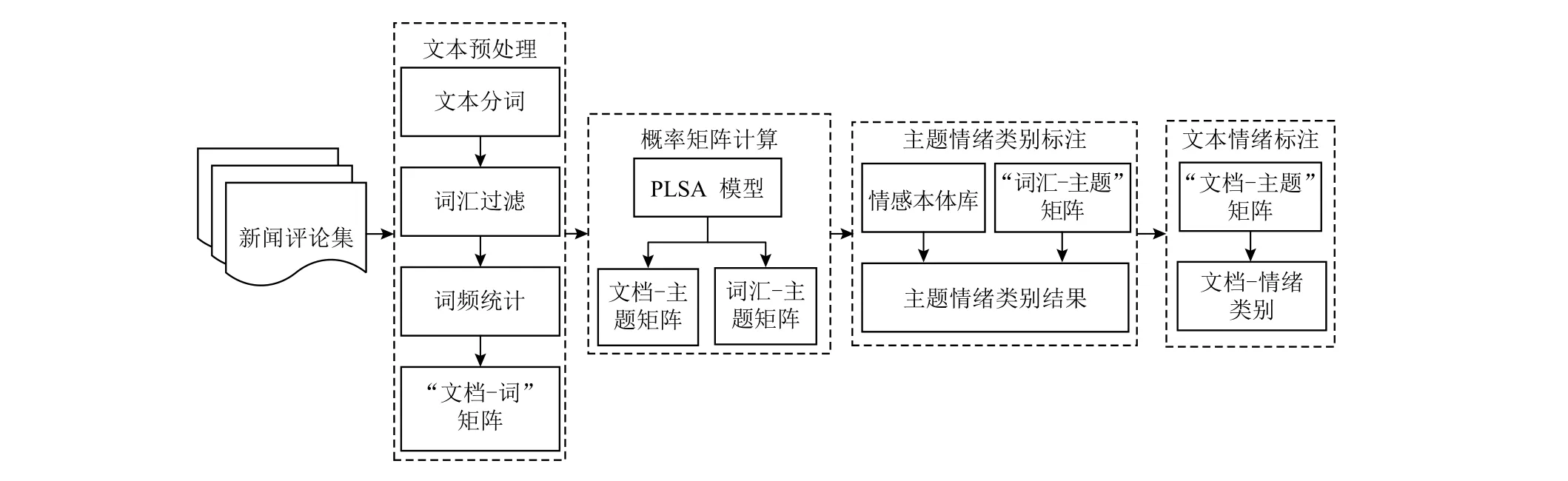
图1 基于PLSA的新闻评论情绪自动标注过程
2 基于PLSA的概率矩阵抽取方法
PLSA模型是由Hofmann在1999年提出的, 首先给定文档集D={d1,d2,···,dn}和词集W={w1,w2,···,wm},用freq(di,wj)表示词wj在文档di中出现的概率, 则“文档-词语”共现矩阵MD-W=[freq(di,wj)]. 假设主题类别Z={z1,z2,···,zk},k为主题个数. PLSA模型假设词与文档之间、话题与文档或者词之间的概率服从条件独立, 由此得到相应的联合分布概率为:
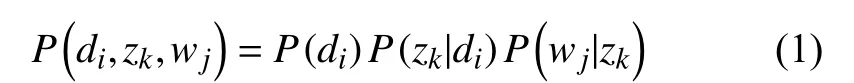
P(di)表示选择文档di的概率,P(zk|di)表示某个主题zk在给定文档di下出现的概率;P(wj|zk)表示词wj在给定主题zk下出现的概率, 本文基于该“词语-主题”的概率分布获取事件Evt, 根据贝叶斯法则可得到:
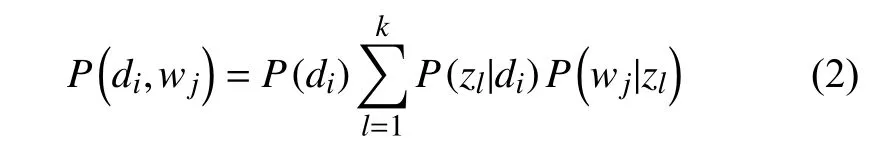
采用最大期望算法(Expectation Maximization,EM) 算法对潜在语义模型进行拟合[13]. 用随机数初始化之后, 交替执行E步骤和M步骤进行迭代计算.E步骤计算(di,wj)所产生的潜在语义zk的先验概率:

在 M 步骤中, 根据P(z|d,w)对P(w|z)和P(z|d)矩阵重新估计:
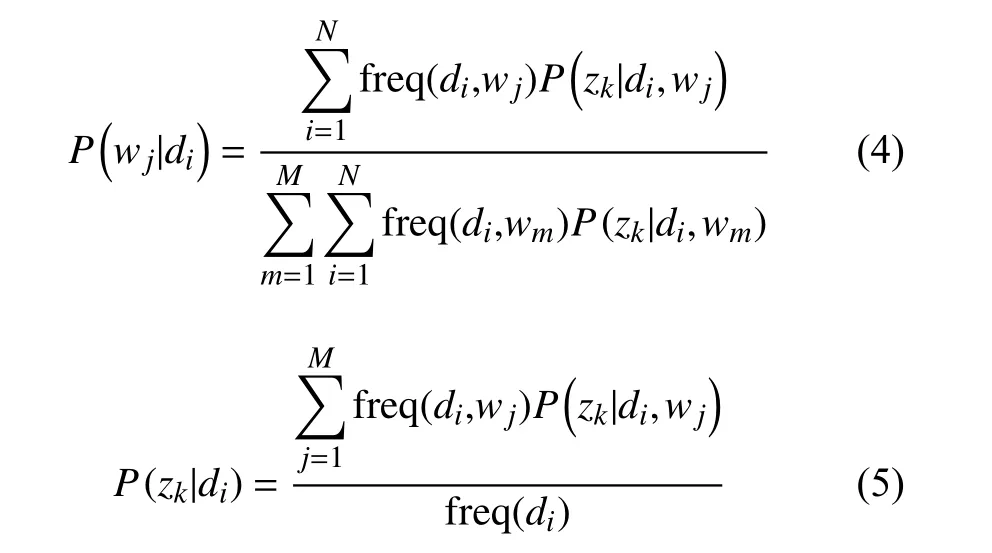
似然函数的对数如下:
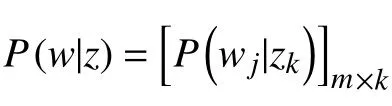
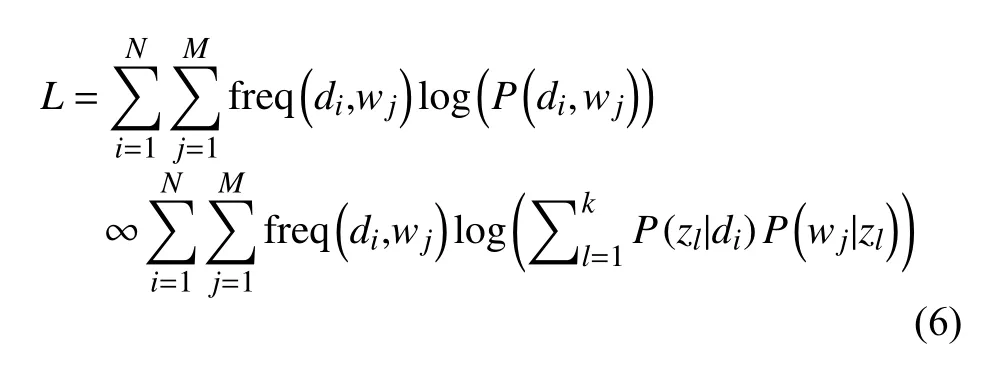
3 实验结果及分析
3.1 实验数据采集
实验采集了凤凰网(http://www.ifeng.com/)涉及中日关系新闻“习近平应约会见日本首相安倍晋三”, 新闻为2014年APEC期间发布的, 共有2346条新闻评论. 由于本文利用情感本体库结合“词汇-主题”矩阵实现主题的情绪类别标注, 因此对不含情绪词汇和评论长度小于10的评论直接去掉, 取其中1500条来进行标注. 请3名研究人员对语料进行人工标注, 标注为7类情绪, 对于标注结果采用投票方式, 有两人标注结果为一致, 则认为语料标注有效, 最终取1200条新闻评论作为本文的实验语料.
3.2 PLSA中主题数的确定
利用PLSA进行计算时, 需要先设定主题的数量,而主题数的确定受到语料的规模和内容的影响. 对于主题明确的语料, 设定了正确的主题数量, 能有效提升主题的自动情绪标注准确性, 进而提高文档的情绪类别自动标注准确率. 鉴于此, 本文利用情感本体库OL作为情绪标注的基础, 而本体库中将情绪分为7类,分别是乐、好、怒、哀、惧、恶、惊. 因此, 本文主题的数量的设定从7类开始, 一直增加到28类, 探索最适合于选定语料的主题数量.
对于主题zj的情绪强度向量Vzj=[e1,e2,e3,···,em]j,如果Vzj中除了情绪最强的类别之外, 其他情绪类别ei的强度不能同时满足公式(7), 则认为该主题的情绪类别不能准确分类.

因此, 主题情绪类别自动标注准确率的计算公式如公式(8)所示.

根据公式(8), 在本文选定的语料集中, 计算主题情绪自动标注的准确率随着主题数增加的结果, 如图2所示,x轴表示主题数量,y轴表示自动标注准确率.

图2 主题数与标注准确率

3.3 基于PLSA的文本情绪类别自动标结果
将主题数设定为17, 利用PLSA的分析结果, 对主题进行情绪标注, 能正确标注的主题数为16个, 则7类情绪对应的主题数如表1所示, 主流情绪为乐、好. 进一步观察语料发现, 多数网民对中日两国友好关系和共同发展, 表示支持和高兴. 同时, 网民也对中日的钓鱼岛、靖国神社、南京大屠杀等中日历史事件表现出其他情绪.
利用表1中主题情绪类别标注结果, 根据算法1中的步骤7, 对文档进行情绪标注, 各类情绪下语料标注的准确率如表2所示.
从表2的实验结果可以看出, 每一类情绪对应的文档自动标注准确率均高于85%, 最高准确率达到93.7%,7类情绪的平均准确率达到88.98%, 总体的准确率达到90.87%. 说明了采用PLSA可有效对文档进行细粒度的情绪类别自动标注, 特别是大规模语料, 可以快速地实现语料的自动标注.
4 结论与展望
文本自动标注能有效解决手工标注的困难, 本文提出一种基于PLSA的新闻评论文本情绪类别自动标注方法, 这种方法主要利用的PLSA计算输出“文档-主题”和“词语-主题”概率矩阵, 基于“词汇-主题-文档”三者的关系, 认为某一类情绪词汇出现的概率最高的主题与词汇的情绪类别相同, 对主题进行情绪类别标注;认为出现在某一主题概率最高的文档与主题的情绪类别相同, 对进行情绪类别标注. 实验结果表明, 这种方法是可行的和有效的, 标注准确率达到90%以上.

表1 主题情绪标注结果

表2 新闻评论情绪类别自动标注结果
由于语料的规模和内容对PLSA的分析有一定的影响, 同时本体库的词汇涵盖面以及领域适应性等问题, 都会影响标注的效果. 因此, 本文的下一步工作是探索领域自适应性的语料标注方法, 拓展本体库, 利用句法依存关系等抽取领域关键情绪词汇, 提升自动标注的准确率.
