叠前多属性反演在储层非均质性描述中的应用
——以渤海B田为例
2019-01-16贾海良陈华靖张鹏志任百聪
贾海良, 陈华靖, 张鹏志, 任百聪
(中海石油(中国)有限公司 天津分公司,天津 300459)
0 引言
在渤海油田,随着油田勘探开发程度逐渐深入,储层参数预测发挥着越来越重要的作用,在有利勘探目标选择、油田开发方案设计和油井生产动态分析等工作中,成为一种必要的技术手段。尤其在河流相油田,储层非均质性较强,物性横向变化快,给井位部署和潜力动用带来了较大的困难。为了解决这些困难,我们首先需要将能够反映储层性质的地球物理参数与地质、钻井等信息结合起来,综合多种信息来预测储层物性,以储层物性的变化描述储层的非均质性[1-2]。
研究证实,在渤海B田区域,叠后地震资料不能有效描述储层的非均质性,因此我们把目光转向叠前地震资料。与叠后资料相比,叠前地震资料还包含有横波信息,可以更好地反映流体和岩性特征,提高储层预测的精度。因此,近年来叠前反演成为研究的热点,与此同时,叠前地震同时反演技术的应用也越来越广泛,在叠前反演中发挥着重要的作用[3]。我们使用叠前同时反演得到不同的叠前地震属性,在“分步逼近法”进行敏感属性优选的基础上,使用神经网络方法对储层物性参数进行直接反演,实现了物性预测由定性到定量的转变,通过储层物性预测方法研究,探索建立了一套砂体非均质性表征的研究流程。
1 叠前同时反演
叠前同时反演是利用Aki-Richards方程的近似形式来进行反演,在地震角道集数据的基础上,通过测井数据、地震层位和地质模型的约束完成反演,从而得到密度、纵横波阻抗等数据体,然后通过密度、纵横波速度与岩石弹性参数之间的理论关系得到拉梅常数、泊松比等多种岩石弹性参数数据体[4-5]。

图1 同时反演过程Fig.1 Simultaneous inversion process
同时反演过程中,首先通过制作合成地震记录进行井震标定,它是后续所有研究的基础,准确的井震标定才能保证结果的可靠性。通常对于叠前数据,从近偏移距到远偏移距,高频能量会损失。这意味着对于CDP道集的每一道都需要不同的子波。实际上,我们发现每10°入射角提取一个子波就够了。因此提取了从近道集到远道集不同角度的多个地震子波。结合层位、测井数据建立初始模型,在初始模型的基础上进行多次迭代计算,然后对初始模型进行不断更新并可以得到反演结果。为了评判反演结果,需要先在井位置处反演并进行质控,得到最优的反演参数,利用最优反演参数进行全区同时反演(图1)。完成同时反演之后,可以得到纵横波阻抗、密度等叠前属性数据体。
2 地震多属性反演理论基础
2.1 地震多属性反演基本思路
地震多属性反演是使用多个地震属性对物性参数进行反演,它是通过一定的方法,在已知井点处建立起目标物性参数与地震多属性的数学关系,使用该关系对未知点处的物性参数进行反演,从而得到研究区域全区的目标物性参数。地震多属性反演目前应用已比较广泛,方法也较为成熟,与传统多属性反演不同的是,笔者使用了分布逼近法进行敏感属性优选,提高了工作效率。
2.2 敏感属性优选
多属性反演的一个关键问题是敏感属性的优选问题,选取哪些地震属性作为优选属性进行反演,它直接关系到多属性反演的准确性。储层的类型、埋深、结构等因素的不同,都会使得储层的物性存在差异,所对应的敏感属性也不一样。针对敏感属性优选的问题,前人已经做了大量的研究,并提出了一系列技术方法,传统的方法有专家经验法、正演模拟法等方法[6-7]。为了提高工作效率,我们选用“分步逼近法”进行属性优选。
分步逼近法是基于:假设最优X个属性组合是已知的,则最优的X+1个属性包含之前的X个属性。具体的运算过程如下:
1)通过穷举法找到单个最优属性。假设有n个属性A1、A2、A3、……、An,计算每个属性的预测误差值,最优属性就是有最小预测误差的那个属性,命名为attribute1。
2)找到最优的两个属性组合。用attribute1与其余任意一个属性进行组合,找到预测误差最小的一对属性组合,并将第二个属性命名为attribute2,形成组合(attribute1,attribute2)。
3)找到最优的三个属性组合。前两个属性分别是attribute1、attribute2,与其余任意一个属性组合,找到预测误差最小的三个属性的组合,并将第三个属性命名为attribute3,形成组合(attribute1,attribute2,attribute3)。
……
按照以上规则持续运算,在所有组合中误差最小的就是最优属性组合。
在实际属性优选过程中,将所有数据分为训练数据和验证数据两类。随着属性个数增加,训练数据误差呈逐渐减小趋势,还可能会造成训练过度。如图2所示,随着属性个数增加,红色的验证误差在减小到一定程度后便不再减小。交互验证的目的就是确定训练过度的临界点,这个临界点就是最优的属性个数。

图2 交互验证示意图Fig.2 Cross validation
2.3 概率神经网络法多属性反演
人工神经网络是基于生物学中神经网络的基本原理,模拟大脑处理信息的方式进行信息处理,它实际上是一个由大量处理单元组成的信息处理系统,具有非线性和自适应的特点[8-9]。目前人工神经网络在科技界有着非常广泛的应用,谷歌开发的基于神经网络的翻译系统可以将误差降低55%,我们采用概率神经网络法进行多数性反演。
应用神经网络方法建立目标储层参数与敏感属性之间的非线性关系[10-11]。假设有n个训练样本,并且利用分步逼近法优选出了3个敏感属性,则训练数据可以写成以下形式:
{A11,A21,A31,L1}
{A21,A22,A32,L2}
{A31,A32,A33,L3}
……
{A1n,A2n,A3n,Ln}
其中:Aij为第j个样本对应的第i个属性值,Li为第i个样本对应的目标物性参数值。对于新的样点x={A1j,A2j,A3j},其对应的物性参数值可以估算为:
(1)
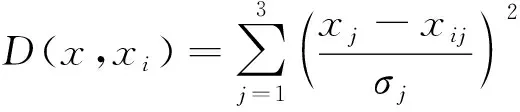
(2)
参量D(x,xi)为目标点与训练样点xi之间的距离。这个距离是在由敏感属性组成的多维空间中测量的并且用参量σj来衡量。
式(1)和式(2)阐述了概率神经网络方法的具体实现方法。网络训练需要确定一套最优的平滑参数σj,参数选择的标准是预测结果的校验误差最小。
将第m个目标样本的校验结果定义为:
(3)
如果第m个样本不包括在训练数据中,利用式(3)就能得到第m个样本的预测值。由于训练样本的实际值是已知的,我们就可以计算这个样本的预测误差。对所有样本都重复上述过程就能得到全部样本的预测值,所有训练数据的总预测误差可以定义为:
(4)
从式(4)中可以看出,预测误差的大小取决于参数σj的选择。预测误差可以使用共轭梯度算法来达到最小化。
3 实际应用

图3 W1井、W2井在S砂体平面分布位置Fig.3 Planimetric position of W1、W2 in sand S

图4 W1井、W2井在S砂体实钻剖面Fig.4 Drilling result of W1、W2 in sand S

图5 孔隙度反演剖面与T1井孔隙度曲线对比Fig.5 Comparison of predicted porosity section and logging curve in well T1
在渤海油田,新近系油田的储量占比超过了60%,但这些油田油水关系复杂,多呈现“一砂一藏”的特点,储层非均质性强是制约油田稳产的主要因素。渤海B油田主要含油层系为明下段,其中明下段III、IV油组主要发育河道型砂体,储层非均质性强。S砂体为河道砂体。从常规叠后属性来看,W1井和W2井均部署在河道中间位置(图3),但是实钻结果却相差很大,W1井钻遇15 m厚储层,而W2井仅钻遇6 m厚储层(图4),常规叠后属性不能反应储层的这种非均质性。
为了有效识别S砂体的储层非均质性,应用叠前多属性反演对孔隙度进行定量预测。首先使用分步逼近法对地震属性进行优选,并用交互验证确定最优的属性个数。从图2中可以看出,属性个数为6时,验证误差最小。因此,选取前六种属性(表1)作为最优属性组合进行神经网络反演。将反演结果与训练井T1井点处实测孔隙度进行对比,可以看出井上孔隙度高的位置反演结果颜色深,孔隙度低的位置颜色浅,说明反演结果与实测值吻合较好(图5)。

表1 优选的6种属性及其训练误差Tab.1 6 optimized attributes and their training error
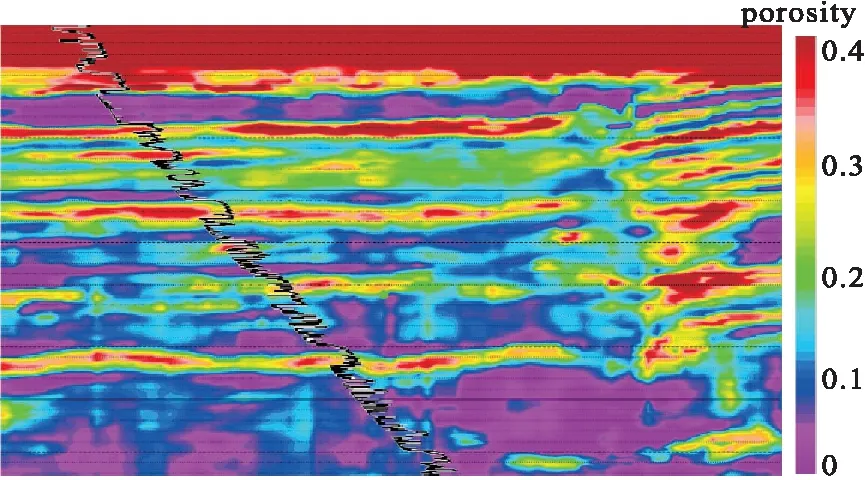
图6 孔隙度反演剖面与T2井孔隙度曲线对比Fig.6 Comparison of predicted porosity section and logging curve in well T2
为了进一步验证反演结果的可靠性,选取没有参与训练的T2井为验证井进行分析。T2井井点处的孔隙度反演剖面如图6所示。对T2井钻遇的5个含油砂体的预测孔隙度和实际孔隙度进行统计并对比,可以看出预测误差主要分布在10%~16%之间(表2),说明预测结果是可靠的。

图7 S砂体局部区域孔隙度分布图Fig.7 Part of the porosity distribution of sand S
综合以上分析认为,使用基于分步逼近法属性优选的地震多属性反演,得到的反演孔隙度结果可靠,能够对储层进行精细描述。因此,在反演孔隙度数据体上提取了S砂体的孔隙度分布平面(图7),从图7来看,W1井区域属于高孔隙度,位于河道中间位置,W2井属于高孔隙度与低孔隙度交界的位置,位于河道边部,这就解释了W1井与W2井钻遇S砂体厚度差别如此之大的原因,这种变化在常规叠后地震属性上是没有显示的。这种孔隙度分布可以有效指示储层内部的非均质性,为油田调整井的部署及潜力有效动用提供了很重要的参考。

表2 T2井钻遇砂体预测孔隙度与实际孔隙度误差Tab.2 The predicted porosity and real porosity of the sands along T2
4 结论
1)属性优选是地震属性反演的基础,“分步逼近法”属性优选能够提高运算效率,保证属性组合与目标参数关系最优。
2)与传统反演方法相比,地震多属性反演不依赖于模型,操作简便。
3)地震多属性反演预测的储层参数结果与实际钻井情况非常接近,实现了储层物性预测由定性预测向定量预测的进步。
