文本分类中基于CHI改进的特征选择方法*
2019-01-15宋呈祥陈秀宏
宋呈祥, 陈秀宏, 牛 强
(江南大学 数字媒体学院,江苏 无锡 214122)
0 引 言
合理的特征选择,不仅可以降低文本特征维度,还能降低分类时间复杂度,提高分类效果[1]。近年来,越来越多的特征选择算法涌现,这些方法大多数都是基于频率或者概率对特征词进行权重计算,并根据排名选取TOP-K特征词。卡方统计量(Chi-square statistics,CHI)是一种常用的特征选择方法,具备更低的时间复杂度和应用便利性[2],其统计特征词在文本中是否出现,但没有考虑词频和特征词分散度、集中度等信息。Galavotti L等人[3]通过研究特征词与类别的正负相关性问题,引入一种新的相关系数方法对CHI模型进行优化,使得模型性能有了一定的提高。Jin C等人[4]使用样本方差计算词的分布信息,并考虑最大词频信息来改进CHI方法,在三个数据集上均取得较好的结果。叶敏等人[5]通过在CHI特征选择算法中引入分散度、频度等特征因子,并考虑位置和词长信息改进词频-逆文本频率(term frequency-inverse document frequency,TF-IDF)赋权公式,提出一种用来描述特征词的权重分布情况的特征选择算法,提高特征词的类别鉴别能力。高宝林等人[6]通过引入类内和类间分布因子,提出基于类别的CHI特征选择方法,减少了低频词带来的干扰,并且降低了特征词在类间均匀分布时对分类带来的负贡献。袁磊[7]考虑不均衡文本长度的影响,对特征词频进行归一化处理,同时融合特征词的类别信息,提出了一种改进CHI特征选择算法。但这些方法都没有考虑分布在少数文本集合的高频特征词。
由于传统CHI方法是在全局范围内进行特征选择而未考虑特征词频信息,且没有考虑特征词的出现与类负相关的情况,故本文提出一种新的基于CHI特征选择方法,考虑位置特性而改进TF-IDF权重计算公式,并分别使用支持向量机(support vector machine,SVM)和朴素贝叶斯(naive Bayes)方法对文本分类。实验结果表明,该方法分类效果优于传统CHI方法和文献[6]的方法。
1 相关概念与方法
1.1 CHI
CHI是用来衡量特征词tk和类别ci之间的相关联程度。假设tk和ci之间符合具有一阶的自由度χ2分布,则tk与ci的CHI值定义为[2]
(1)

(2)
式中m为类别数目。
1.2 特征权重计算
特征选择后需计算各特征词的权重大小,以衡量某个特征词在文本中区别能力的强弱。TF-IDF是一种经典的特征权重计算方法,在信息检索占有重要地位[8],其计算公式如下
(3)
式中nij为特征词wi在第j篇文本中出现的频度,|Dj|为第j篇文本的长度,n为文本集的文本总数,df(wi)为文本集中出现特征词wi的文本数目。如果一个词在某篇文本出现的次数多且在其他文本中包括该词的文本数少,那么其就越和该文本主题相关,区分能力也就越强[9]。为了消除文本长度对TF-IDF值的影响,一般将其进行归一化处理。
2 改进的文本分类方法
2.1 基于位置改进的TF-IDF权重计算公式
传统的TF-IDF公式在计算特征词权重时只考虑词频和包含它的文本数量,没有考虑特征词出现的位置,然而特征词的位置信息从某种程度也反映了其重要性。如果特征词出现在文本的标题、摘要或者关键词处,则其应该获得更高的权重。于是,改进的频度 (称为位置频度,pos_n)为
pos_nij=nij×(1+log2(T(wi)+1))
(4)
式中T(wi)为特征词wi出现在标题、摘要或者关键词处的总次数。当T(wi)=0时,pos_nij=nij,该式值即为传统的特征词频度。式(4)表明,如果一个特征词在标题、摘要、关键词出现的次数越多,那么它的权值应越高,也就越重要。将式(4)替换式(3)中的nij,便可得到包含特征词位置的改进TF-IDF权重公式位置 TF-IDF (position TF-IDF,PTF-IDF)
(5)
2.2 CHI的优化

针对传统CHI全局特征选择以及未考虑词频信息等问题,考虑特征分布系数(feature distribution coefficient,FDC)如下
(6)

(7)
式中N(tk,ci)为类ci出现特征tk的文本数,N(tk)为文本集中出现tk的文本总数,m为类别数。于是,当类ci中出现特征tk的文本数小于平均每个类中出现tk的文本数时,NCF值为负数,CHI值就会是负数,此时删除与类ci负相关的特征即可避免负相关对分类的影响。最后给出改进的特征选择公式IMPCHI(improved CHI)为
IMPCHI(tk,ci)=CHI(tk,ci)FDC(tk)NCF(tk,ci)
(8)
综上所述,得到以下改进的特征选择和权重计算的文本分类算法流程:
1)文本预处理。文本预处理包括词性标注、去除特殊符号以及停用词;只保留名词、动词和形容词等重要词语,获取文本词语(标题、关键词、摘要、正文和类别)集合。
2)特征选择。使用本文算法计算训练集文本词语集合和每个类别的NCF,CHI,FDC值,得到每个词和对应类别的IMPCHI值;对于重复的词,取最大值作为该词最终的IMPCHI值。将每个词按IMPCHI降序排序,根据语料文本特征选取TOP-K作为整个语料集的特征词集合。
3)权重计算。对于每篇文本的词语集合,若步骤(2)的特征词集合含有该词,使用考虑特征词位置特性的PTF-IDF赋权公式计算该词的权重,构造文本特征向量。
4)分类器训练。利用步骤(3)得到训练集文本特征向量,并训练分类器。
5)测试分析。将测试集分别进行步骤(1)、步骤(3)处理获取测试集文本特征向量,并对步骤(4)得到的分类器测试评估,输出实验结果。
3 实验与结果分析
实验数据利用网易新闻语料库和复旦大学中文语料库,其中网易新闻语料库包括汽车、文化、经济、医药、军事和体育六个大类,随机选取每个类别的300篇文本,以2∶1的比例组成训练集和测试集;复旦大学中文语料库,随机选取的训练集和测试集文本数量如表1。

表1 复旦大学中文语料库训练集和测试集的选取情况
实验中,使用中科院NLPIR[10]工具对语料进行预处理。实验分别采用TF-IDF和PTF-IDF公式对特征选择后的特征词计算其权重;并利用台湾大学的Chang Chih-chung教授等人[11]开发的线性核函数SVM分类器和Weka平台Naive Bayes分类器[12]对语料文本进行分类。
实验性能评估使用宏F1值 (macro_F1)来度量所有类别的总体分类指标
(9)
式中m为类别个数;Pi,Ri分别为ci类的查准率(Precision,P)和查全率(Recall,R);macro_P为宏查准率;macro_R为宏查全率。
实验中各个方法表示为:E1为传统CHI特征选择+TF-IDF权重计算的实验;E2为传统CHI 特征选择+PTF-IDF权重计算的实验;E3为文献[6]提出的C-ICHI方法+TF-IDF权重计算的实验;E4为IMPCHI特征选择 +TF-IDF权重计算的实验;E5为IMPCHI特征选择 +PTF-IDF权重计算的实验。
3.1 在不同语料库上的SVM分类实验
在不同语料库的SVM分类对比实验结果如图1。

图1 不同特征维度的SVM分类宏F1值
可见,当特征集合维度增大时,宏F1值也随着变大。在网易新闻语料库中,特征维度1 500时,E5达到宏F1值最大值87.46 %,但E1此时宏F1已经下降,E4,E5虽然宏F1值也在轻微下降,但E1,E3下降更加明显,表明本文提出的IMPCHI方法更加稳定,综合性能更好。在复旦大学新闻语料库中,特征集合维度2 500时,达到86.27 %的宏F1值,E5比E1,E3分别高出4.31 %,1.47 %,但是当特征集合维度继续增大时,因为特征词集合含有很多冗余特征,致使宏F1值变小。E3引入类内和类间分布因子等因素,虽然宏F1值比E1高,但低于E4,E5。因为在特征选择时,对于位置特性、一些大量分布于少量文本集的特征等因素,对于提升CHI特征选择的分类性能不可忽视。在计算特征权重时,本文提出的PTF-IDF权重公式,考虑特征词位置权重,出现的位置越重要,得分越高,网易新闻语料库和复旦大学中文语料库中E2比E1分别提升平均1.19 %,2.85 %的宏F1值。PTF-IDF单纯考虑位置特性不能达到理想的分类效果,使E2结果不如E3和E4方法。
在网易新闻语料库和复旦大学中文语料库中,在宏F1值分别达到最大值时分析各个类别的宏F1值,如表2、表3。各个类别宏F1值差别明显,原因是不同文本长度对于结果的影响,如果文本较短,含有很多空值,使向量稀疏,造成分类结果较低。若文本含有词数较多,并含有一些类别区分度高频词语,使宏F1值较大,本文提出的方法能有效改善传统CHI和TF-IDF的缺陷,过滤掉低频词语,改善不同特征词的权重,使得分类效果更好,性能更稳定。

表2 网易新闻语料库中特征维度1500时的不同类别的SVM分类宏F1值 %
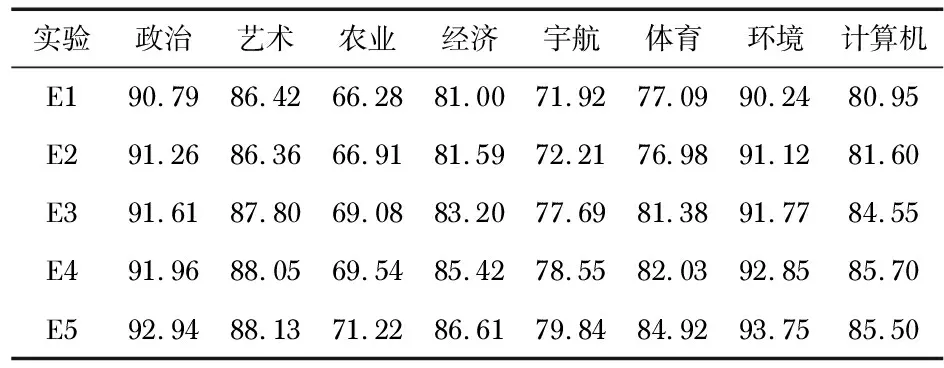
表3 复旦大学中文语料库中特征维度2500时不同类别的SVM分类宏F1值 %
3.2 在复旦语料库上的Naive Bayes分类实验
为了验证本文方法在不同分类器的可行性,Naive Bayes分类对比实验结果如图2所示。

图2 复旦中文语料库中不同特征维度的Naive Bayes分类宏F1值
由图2可得,随着特征维度增大,宏F1值变化比较平缓;在特征维度3 000维时,E5达到86.98 %宏F1值,而E3在2 500维达到最大值84.79 %。同时,还验证了本文提出的方法在不同分类器上都是可行的。
4 结束语
特征选择在文本分类过程中具有重要作用。本文提出了一种改进的CHI统计特征选择方法,同时提出修正因子解决特征词与类别负相关的困扰,并将改进后TF-IDF的权重计算方法用于特征词的权值计算,使其分类效果有了明显提高。在后续工作中,将考虑特征词的语义关系,进一步进行特征降维,在减少算法时间复杂度的同时提高分类效果。
