未知环境下基于虚拟子目标的对立Q学习机器人路径规划
2019-01-10汪盛民
汪盛民,林 伟,曾 碧
(广东工业大学 计算机学院,广东 广州 510006)
随着服务、仓储物流产业的快速发展及其相关产业出现的升级难题,移动机器人成为安全公司、物流公司的研究热点[1-2]. 路径规划是移动机器人实现自主导航的关键技术之一,路径规划是指在具有障碍物的环境中,按照一定的评价标准,寻找一条从起始位姿到目标位姿无碰撞的最优路径[3]. 目前,大多数移动机器人是在高度结构化的已知地图中执行预先规定的动作序列. 例如,在已知静态环境中的路径规划算法已经比较成熟,主要有人工势场法[4]、可视图法[5]、RRT[6]、遗传算法[7]、粒子群算法[8]等. 相对来说在未知、非结构化或动态的环境中时,移动机器人对实际环境没有主动学习和自适应能力,导致移动机器人缺乏对环境的认识,无法确定自身的位置信息和环境中全部障碍物的信息. 因此,采用强化学习使机器人在无法预先感知障碍物具体信息的前提下,在不断地与环境交互的过程中,可以自适应规划出一条从起始点到目标点且满足一定优化标准的无碰撞路径尤为重要[9]. Q学习是一种在线的、无监督的机器学习算法,这使得Q学习成为了强化学习在未知环境下移动机器人路径规划的一个研究热点[10].
近年来,对于改进的Q学习移动机器人路径规划问题可以分为5类:(1) 重新定义环境的状态空间;(2) 动作的随机选择策略;(3)Q表的初始化策略;(4)Q函数的更新策略;(5) 奖惩函数的设计. 对此,国内外的一些学者对Q学习算法提出了一些改进方法.Konar A等[11]提出了一种改进的确定性Q学习路径规划方法,假设知道从当前状态到下一个状态和目标之间的距离,该算法就可以通过利用Q学习的4个派生性质有效地用于更新Q表中的条目,而不是像传统Q学习算法重复更新,因此节省了存储空间,但算法时间复杂度被提高了,导致收敛速度下降的问题.Hwang H J[12]提出了一种学习算法,有效加快了收敛速度,但在生成单链的过程中会去除原始状态路径中的所有环,导致算法能找到一个可行解,但可能不是最优路径. Pietersm[13]提出了一种基于经验回放的Q学习算法,通过经验函数来弥补前期对环境模型认知不足的缺点,在一定程度上加快了算法的收敛速度,但是在算法中除了要更新Q值函数的同时还要更新,增加了算法的时间复杂性,并且忽略了在环境规模比较大时Q值存在“维数灾难”的问题.
针对上述研究现状及不足,本文提出了基于虚拟子目标的对立Q学习机器人路径规划. 该算法通过建立双向的状态链,使当前状态的动作决策快速地影响到前面的状态动作对,来改善传统Q学习数据传递的滞后性,提高收敛速度,同时通过在局部探测域内寻找最优虚拟子目标的方法解决了大规模环境下Q学习容易产生的维数灾难问题.
1 相关算法
1.1 激光雷达及激光数据坐标转换算法
本文采用sick的激光雷达如图1所示,截取后的扫描范围为180°,通过扫描可以得到栅格地图[14]. 利用激光雷达测距速度快、精度高、抗干扰能力强和范围广等特点,机器人可以快速有效地获取周围的环境信息. 机器人的感知信息来自于激光雷达旋转180°所得的距离数据,通过旋转角度和激光末端点的测量距离,计算出机器人离周围障碍物的距离. 在二维坐标系中,激光末端点坐标假设以形式表示,激光雷达在全局坐标系中的位姿为而通过转换矩阵Tφ,将s转换到全局坐标系中,如式(1)所示.
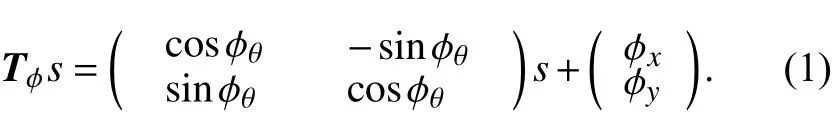

图1 激光雷达与移动平台Fig.1 Lidar and mobile platform
1.2 经典的Q学习算法
Q学习算法[15]采用每个状态-动作对所对应的作为估计函数通过不断地循环更新Q值,使相邻状态间Q值估计的差异达到一定的收敛条件,即
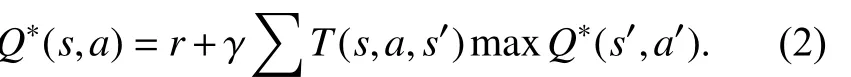
其中,r表示执行动作a得到的奖惩值,γ表示折扣因子,T(s,a,s′)表示在状态s采取动作a之后转换到状态s′的概率. 通过查找给定状态对应的所有可能动作,根据贪婪策略选择一个具有最大Q值的动作执行,选择策略为
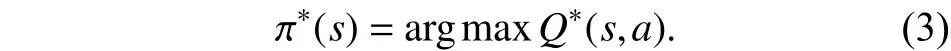
Q学习算法中Q值得更新公式为
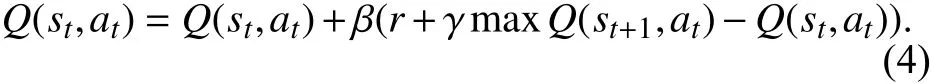
其中,β表示学习因子,Q(st,at)为t时刻的Q值.
2 基于虚拟子目标的对立Q学习算法
针对已有算法存在的问题,本文算法的基本思想是根据移动机器人传感器的检测范围,以机器人为中心取得一个局部的环境作为一个窗口,以窗口滚动的方式来遍历整个环境,移动机器人在局部环境中根据得到的虚拟子目标来进行对立Q学习,并得到一条局部的最优路径. 移动机器人按照该路径前进一段距离L后,再产生一个新的窗口,再次进行对立Q学习并得到最优路径. 随着窗口的移动会产生一系列的局部最优路径并到达虚拟子目标点,将这些路径有序地组织起来就构成了一条全局优化的路径.
假设工作环境为G,移动机器人的起始点为Rstart,终点为Rgoal.G中存在的障碍物分别为,obs2,···,obsn要求移动机器人从起始位置无碰撞地移动到目标位置.
定义1任意两个栅格之间的距离计算公式为

定义2S为所有状态空间{s1,s2,···,sn}的集合,A表 示动作集合,A={左,左上,上,右上,右,右下,下,左下}.
定义3obs为所有障碍物 {obs1,obs2,···,obsn}的集合,表示第i个栅格,如果gi∈G,∧∉obs,则称gi是可行点,所有的可行点集合称之为AVg.
定义4记表为线性表用来记录机器人已经过的栅格集合.
定义5记Precord和Plength分别表示当前迭代的可行路径和路径长度,Precord_his 和Plength_his分别表示历史最优的可行路径和路径长度.
定义6 机器人的视野区域,其中为激光雷达探测的最远距离.
2.1 对立Q学习算法
对立意味着在每个时间t,如果移动机器人在给定状态下接受采取动作a2的奖励,那么在这一时刻移动机器人也可以在相同状态下接受针对相反动作的惩罚,而不需采取相反的动作来训练. 它将会同时更新2个Q值,如图2所示,分别为状态相反动作值). 因此,移动机器人可以同时探索正向行动和反向行动,每个时间步长更新当前正向动作Q值的同时,更新了相反动作的Q值,“双重更新”加快了学习过程.
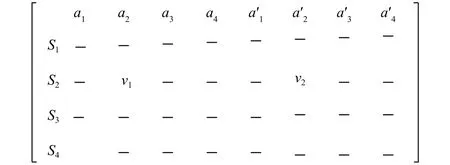
图2 Q值矩阵Fig.2 Q Matrix
其中,定义M(t)←[st,at,rt]来记录移动机器人所经历过的状态-动作对,rt表示为t时刻回报值. 定义来记录移动机器人所经历过的状态-反向动作对,则可以通过记忆矩阵中的状态-动作对的回溯来更新Q值,其更新过程如下:
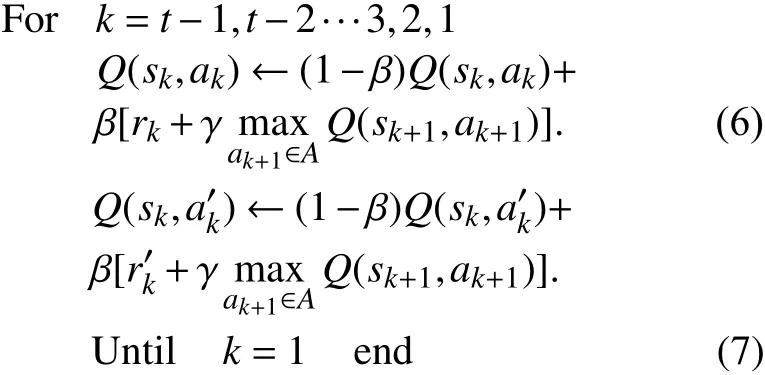
其中,s是状态,ak是k时刻的动作,是k时刻反向动作. 在不断的迭代过程中,t+1时刻最新状态st对应Q值的同时,会对两个单链中状态st之前的状st-1,st-2,···,s3,s2,s1也进行更新操作.
第1步训练:
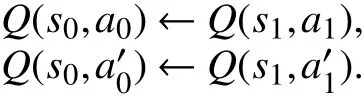
第2步训练:
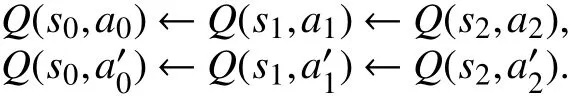
…
第n步 训练:
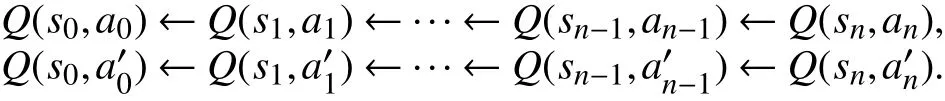
根据对立链的数据更新过程可知,状态s0要获得状态sn的反馈信息只需要一次回溯过程,无需训练n次. 算法步骤如下.
步骤1对当前的环境进行栅格的划分,设置初始位置和目标位置Rgoal并将机器人置于起始位置,初始化迭代次数 count=0,设置最大的迭代次数,初始化先验信息即对每个栅格的Q值进行式(8)的计算.
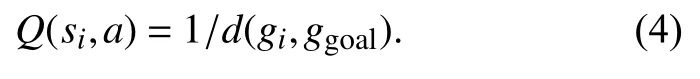
步骤2机器人对当前位置gi的所有邻域进行判断,根据当前栅格gi的状态根据式(3)选择一个动作a. 执行动作a后,机器人移动到gj,如gj∈obs,跳转到步骤3;如果gj=Rgoal,则跳转到步骤4;如果gj∈AVg,跳转到步骤5.
步骤3对当前状态-动作给予一定的惩罚,对立状态-动作对给予一定的奖励.
步骤4到达目标点,记录下当前的Precord和Plength ,如Plength<Plength_his 将Precord_his 和Plength_his更新为当前的Precord和Plength. 对当前状态-动作给予最高的奖励.
步骤5将加入到线性表中,对当前状态-动作给予一定的奖励,同时根据式(6)、(7)更新Q值函数,并跳转到步骤2.
步骤6如果跳转到步骤2;如果跳转到步骤7.
步骤7迭代结束,根据得到一条从起始位置到终点位置的最优路径.
按照上述步骤,其流程图如图3所示.
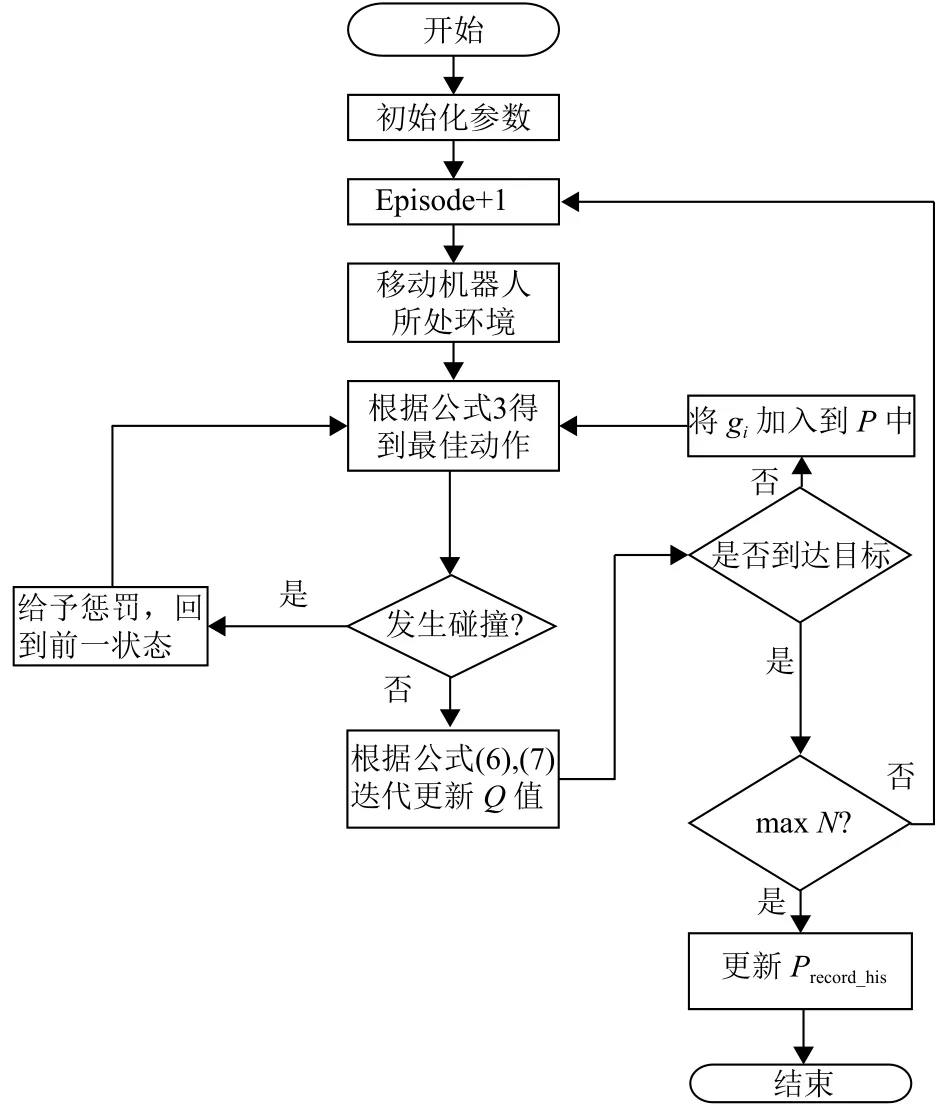
图3 对立Q学习路径规划Fig.3 Opposite Q learing path planing
2.2 虚拟子目标的选取策略
根据移动机器人传感器的检测范围,以机器人为中心取得一个局部的环境作为一个窗口,将窗口内的环境栅格化,根据移动机器人的当前位置计算每个栅格的坐标位置,并将目标点的位置作为指引,如果将通过和障碍物信息选择一个虚拟目标点作为局部窗口的目标位置. 如图4所示.
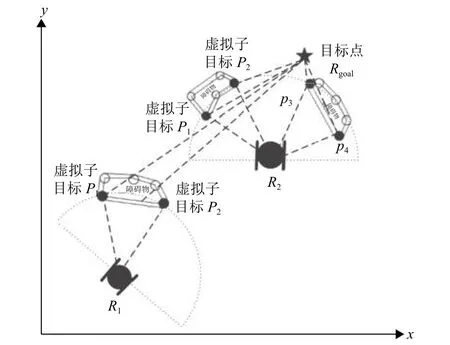
图4 虚拟子目标点的选取Fig.4 Choose virtual sub targets
虚线圆表示的是激光雷达的最大扫描范围,在扫描区域与障碍物膨胀边界交汇的点分别为.这两个点将作为虚拟子目标的候选点. 由于、到目 标 点的 距 离因此将视为最佳的子目标点. 同样,在位置得到机器人最优的虚拟子目标点为.
由上面的分析,可得式(9)为当前探测域内最优虚拟子目标的策略:
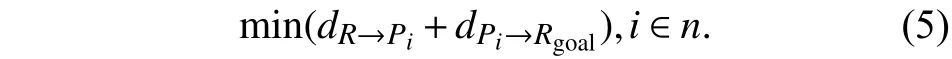
虚拟子目标生成算法的基本步骤如下.
步骤1根据激光雷达的扫描范围和障碍物的信息,获得个虚拟子目标候选点.
步骤2将间隔小于某个固定值的相邻可视点组合成一个障碍物群组.
步骤3根据式(9)计算出当前探测区域中最优虚拟子目标.
2.3 基于虚拟子目标的对立Q学习算法步骤
为了提高全局规划的速度将给出障碍物的密度函数为
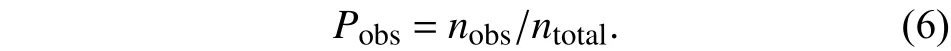
在一个窗口中前进的距离L定义为

步骤1初始化移动机器人的激光雷达的视野半径,阈值和,起始点和终点.
步骤2如果是在移动机器人当前的视野范围内,则使用对立Q学习算法规划出一条从机器人当前位置到目标点位置的优化路径,并且算法结束.
步骤3根据式(9)计算最终选取最优虚拟子目标,对立Q学习算法规划出一条从机器人当前位置到目标点位置的优化路径,并记录下路径长度.
步骤4根据式(10)计算,根据式(11)计算,并且移动沿局部规划路径移动L.
步骤5根据当前位置和视野,更新当前环境,并对当前环境进行栅格化处理,然后回到第二步骤.
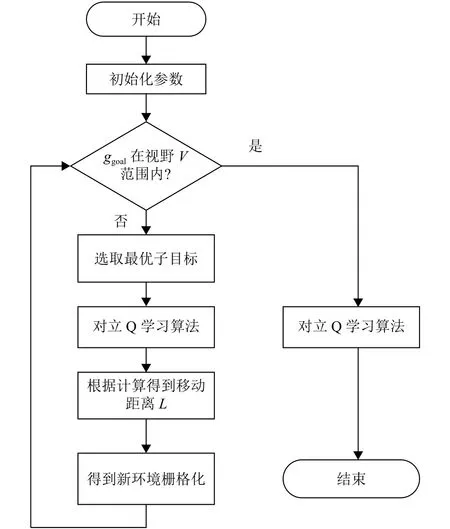
图5 本文算法流程图Fig.5 The flow chart of the algorithm in this paper
3 实验结果与分析
为了验证在大规模环境下基于虚拟子目标对立Q学习算法的效果,本文在ROS机器人仿真平台上搭建未知环境,环境中包括了四周的墙壁、箱子和挡板等障碍物. 在50×50的未知环境下进行实验,实验中相关参数设置如下:学习因子=0.4,折扣因子=0.95,最大迭代数每一次迭代,移动机器人都是从规定的起始位置开始训练,当迭代次数达到最大的时候结束整个的训练过程. 机器人的视野半径为根据前面大量实验的经验总结,设置在第一个视野范围内,机器人采用对立Q学习算法规划出一条局部路径为,根据公式(11)计算出,所以移动机器人将L设置为长度的1/3(即);然后沿着前进3步之后,更新环境信息重新设置虚拟子目标并根据对立Q学习规划路径,重新计算L;重复这个过程,直到探测到最终的目标. 通过实时的调整L,减少了局部规划的次数,提高了算法的效率. 下面4种算法都是在相同的条件下进行的,根据收敛的Q指导移动机器人完成最终的导航,如图6所示.
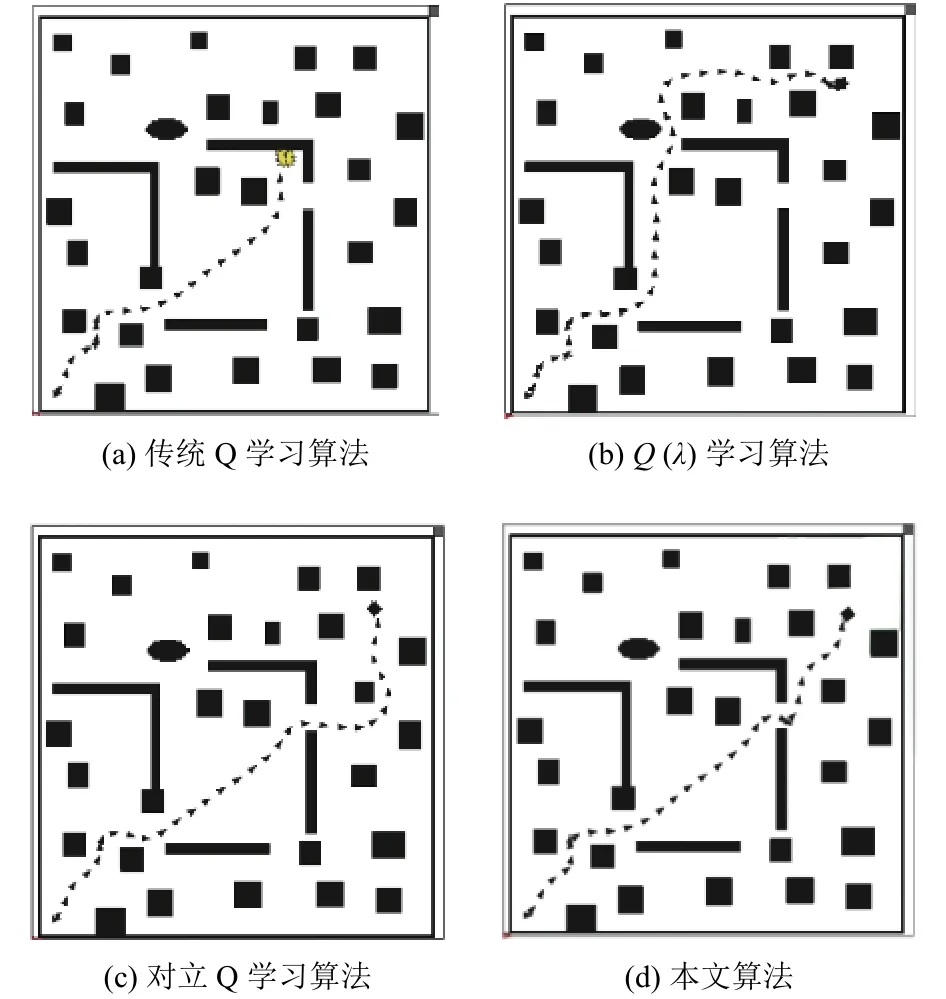
图6 复杂环境中机器人导航路径Fig.6 Robot navigation path in complex environment
从图6可以看到,每个算法的导航路径有所差异,传统Q学习算法由于在U型区域无法找到合适的路径,与障碍物发生了碰撞,学习算法走了35步,对立Q学习算法走了27步,本文算法走了20步.
图7中传统的Q学习算法在训练的过程中陷入到U型区域一直在角落徘徊,导致无法到达目的地,其他3种算法都能到达目标点,并且可以看出本文算法在训练到第8次左右就开始收敛,优于其他3种算法.
为了验证本文算法的实时性,在这32个障碍物随机变化的环境中进行了20组实验,测得的规划时间结果如图8所示. 平均规划时间为0.152 s,基本能满足移动机器人动态路径规划的实时性的要求.
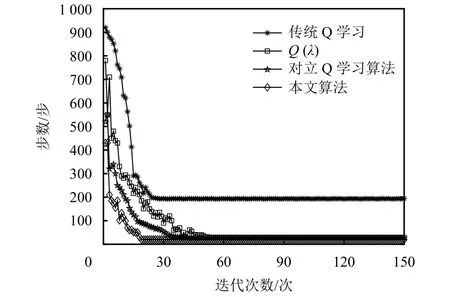
图7 4种算法迭代收敛速度Fig.7 Iterative convergence rate of four algorithms
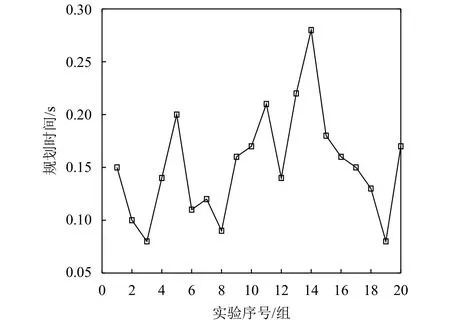
图8 测试规划时间Fig.8 The measurements experimental planning
根据获得的导航路径表明本文提出的强化学习算法可以在未知环境中完成导航任务. 同时在相同的环境条件下,与传统的Q学习,算法和对立Q学习算法进行对比,各个算法的性能如表1所示.
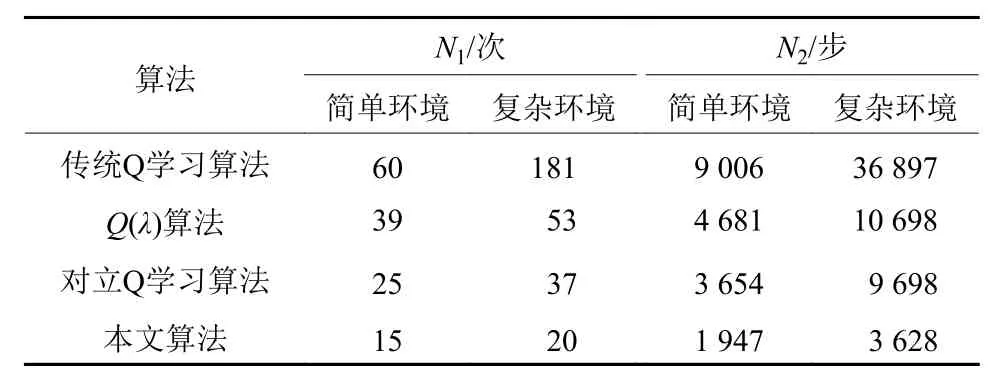
表1 收敛性能对比Tab.1 Convergence performance comparison
其中,N1表示收敛尝试的次数,N2表示收敛时行走的总步数,从表1可以看出在简单环境中本文算法收敛的速度是对立Q学习算法的1.67倍,是的2.6倍,是传统Q学习算法的4倍. 在复杂环境中本文算法收敛的速度是对立Q学习算法要快1.85倍,是的2.65倍,是传统Q学习算法的9.05倍. 在复杂环境中更能体现本文算法的优越性.
为了进一步验证本文算法对环境适应能力,在障碍物更加复杂的环境中进行仿真实验,如图9所示,在复杂的环境中移动机器人也能规划一条无碰撞的路径,表明本文算法对各种环境有较强的适应能力.
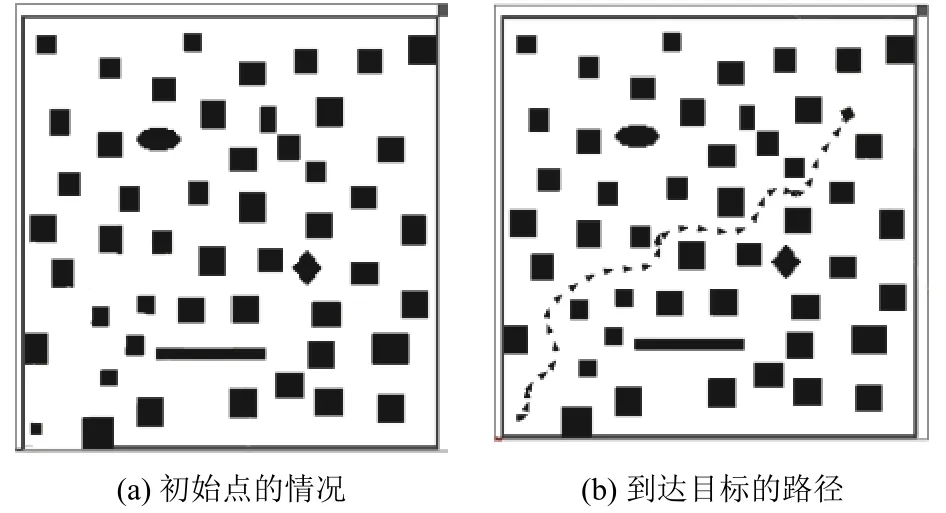
图9 复杂环境下的规划路径Fig.9 Path planning in complex environment
4 结语
虽然传统的Q学习算法能够在未知的环境下找到一条到达目标点的无碰撞路径,但是由于对环境的先验知识不足,使得算法迭代速度慢,特别是在环境规模增大,状态空间会急剧增大导致维数灾难. 本文针对上述问题,在传统Q学习的基础上,依据实际情况,提出了基于虚拟子目标的对立Q学习,该算法通过建立两条单链来回溯更新Q值并通过设置虚拟子目标将复杂大环境转化为局部简单环境. 采取这些措施后,大幅度地提高了算法的实时性和对环境的适应能力. 实验结果表明该算法简单、速度快、对环境的适应能力强等特点,特别是当环境规模较大时,更能体现算法的优越性.
