基于双麦克风的室内语音分离与声源定位系统
2019-01-07陈斌杰陆志华叶庆卫
陈斌杰,陆志华,周 宇,叶庆卫
(宁波大学 信息科学与工程学院,浙江 宁波 315211)(*通信作者电子邮箱zhouyu@nbu.edu.cn)
0 引言
基于双麦克风的室内多声源信息感知系统,相比基于麦克风阵列[1-3]或麦克风网络[4-5]的系统,具有体积小、功耗少、成本低等特性[6],更适合智能产品小型化的发展趋势。 然而,基于双麦克风的系统采集的信号样本维度比声源数量小(欠定问题),空间信息相对较少,可利用的其他信息也相对较少,如何在欠定情况下融合有限的信息,成为了研究的重点。
在过去的研究中,基于双通道的语音分离技术的研究已经取得了许多丰厚的成果。2004年,Yilmaz等[7]利用两信道间信号的时延差和强度差来分离任意数量的源信号。2007年,Sawada等[8]通过高斯混合模型来拟合时频点对混合信号进行了分离。2009年,Kim等[9]通过提取双麦克风之间的相位差信息实现了语音的分离。2012年,Kim等[10]又通过信道加权角度分布的统计建模提高了分离性能。2017年,Zermini等[11]将深度神经网络应用到双通道的语音分离,提高了混响环境下的分离质量。然而,这些方法主要侧重于从双通道混合信号中分离出不同的声源信号,几乎不涉及声源的位置信息。
另一方面,基于声达时间差(Time Delay of Arrival, TDOA)的麦克风定位方法可以通过估计声源到达两麦克风的时间差来确定声源的空间位置。2007年,Izumi等[12]在稀疏假设的前提下通过期望最大化(Expectation Maximization, EM)算法估计了每个源的方位角。2011年,Cobos等[13]利用拉普拉斯混合模型对时频域中的方位角分布进行了建模。2014年,Escolano等[14]利用贝叶斯方法估计了声源位置的概率分布。2016年,Wang等[15]利用两个远端的麦克风之间的相位差建模在混响环境中定位出了多个声源。但是,这些技术大多只能估计出声源的方向(一维定位),而不能确定声源在二维平面中的具体位置,更不能重构出声源信号。
本文通过推导衰减参数与信号能量比之间的关系,在同一个时延-衰减模型的基础上,将DUET(Degenerate Unmixing Estimation Technique)算法和基于到达时间差(TDOA)的定位方法相结合,利用两个麦克风实现语音分离的同时完成了声源的定位。实验利用两个麦克风对多个声源进行了分离和定位。实验结果表明,该系统有效地降低了麦克风的数目,和传统的麦克风阵列的定位系统相比较,在一定程度上减小了阵列尺寸,有助于手机、助听器等小型通信设备的发展。
1 系统框架
整个系统分为语音信号的采集及预处理、参数估计、语音信号分离和声源定位四个阶段。其中,信号的采集及预处理又包括信号的接收,信号的幅度归一化、分帧及加窗处理。参数估计阶段,通过两个麦克风建立混合信号模型,应用DUET算法估计模型的时延-衰减参数,接着采用二值掩蔽的方法对信号进行分离,得到源信号,与此同时,将模型参数进行转化并应用到声源定位中,进行几何计算,从而确定声源在平面中的具体位置。基于双麦克风的语音分离与声源定位系统框图如图1所示。
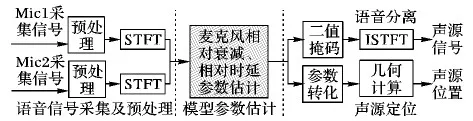
图1 基于双麦克风的语音分离与声源定位系统框图Fig. 1 System block diagram of speech separation and sound source locating based on dual-microphone
2 模型建立与参数估计
2.1 混合模型
DUET算法处理由一对麦克风采集多个声源组成的混合信号,其基本模型[16]如式(1):

(1)
式中:t=1,2,…,T表示离散时刻;N为声源信号的数量;x1(t)和x2(t)表示两个麦克风接收到的信号;sj(t)表示第j个源信号;αj和δj分别表示第j个源信号到两个麦克风的相对衰减和相对延迟,这两个参数均与两个麦克风与信号源之间的路径之比相关。
2.2 模型假设与参数求解
信号从时域通过短时傅里叶变换(Short-Time Fourier Transform, STFT)到时频域。式(1)在时频域的表达式如式(2)所示:
(2)

假设语音信号具有短时不相关正交性,在时频域中可表示为:

(3)

由语音信号的W-DO(W-Disjoint Orthogonality)特性可知,在每个时频域点至多只有一个源占主导,式(2)可化简为:
(4)
根据式(4),一个信号的相对衰减和相对时延可表示为:
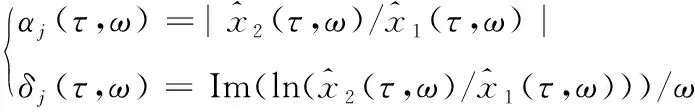
(5)
式中:ln(·)为取对数;Im(·)为取虚部。
2.3 创建参数直方图
若将混合信号中的每个时频点描绘在参数空间中,那么就能得到各个声源信号在此空间中的分布直方图。计算出混合参数后,由最大似然估计(Maximum-Likelihood estimation, ML)[7]算式得到每个时频点的加权幅值:
(6)
其中:p和q为调整指数,一般情况下,取p=1,q=0。每个幅值都对应一个衰减和时延参数对。
为了方便绘图,定义对称衰减a(τ,ω)表示为:
a(τ,ω)=α(τ,ω)-1/α(τ,ω)
(7)
将具有相同对称衰减和相对延时的参数对进行累加,即可得到二维直方图的矩阵幅值:

(8)

2.4 参数估计实验
实验使用Roomsimove工具箱[17]对房间内麦克风接收的信号进行模拟,设定房间尺寸为4.25 m×3.55 m×2.5 m(长×宽×高),两个麦克风的坐标分别设定为(2, 1.775,1.4)m和(2, 1.825,1.4)m。实验使用声源为SISEC2008[18]中“欠定的语音和音乐混合”数据库中的时长为11 s的5个男语音信号(s1,s2,s3,s4,s5),采样频率fs=16 kHz。实验共分为3组 ,分别设定各组实验声源在房间中的位置坐标,声源与麦克风处于同于平面,设定Z轴坐标都为1.4 m,X轴、Y轴坐标如表1所示。设置无混响的环境下,将声源信号进行混合得到两个麦克风采集的混合信号。

表1 声源个数及坐标位置Tab. 1 Number and coordinate positions of sound sources
然后对麦克风采集的信号进行归一化、分帧和加窗处理,
采用1 024点的汉明窗,帧移512点,然后作1 024点的STFT。对每个时频点的对称衰减a(τ,ω)和相对时延δ(τ,ω)进行加权聚类并描绘二维直方图。调整指数p=1、q=0,得到的参数估计直方图如图2所示,峰的个数代表着声源的个数,峰值中心坐标即为参数估计的值。
参数直方图的绘制是本系统的关键部分,直方图的好坏程度决定了后续语音分离和声源定位的精度。对于各个峰值坐标的提取,利用了自动搜索峰值最大点的方法。由图2可知,本文在进行多声源参数估计的过程中,能够顺利地估计各个声源的参数对。
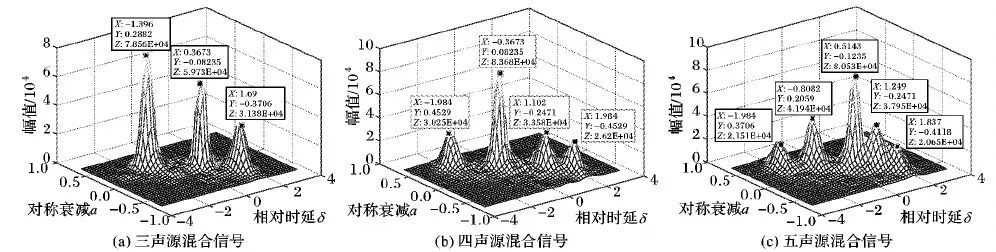
图2 不同声源混合信号参数分布直方图Fig. 2 Parameter distribution histogram of different sound source mixed signals
3 语音分离
3.1 语音分离算法原理
将混合信号x1(t)变换到时频域可得:
(9)
在假设条件下,各信号源满足式(3),在任意时频点(τi,ωk),至多存在一个声源信号的频率分量,即:

(10)

(11)

Mj(τ,ω)={mj(τi,ωk)|i=1,2,…,I;k=1,2,…,K}
(12)
式中:I和K分别表示混合信号所有的时间点和频率点。称Mj(τ,ω)为二进制时频掩膜(Binary Time-Frequency Masking, BTFM),通过它能直接实现声源信号的分离。
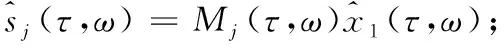
(13)
将时频掩膜应用到参数直方图中,以直方图峰值中心坐标的欧氏距离作为相似度,对峰值附近的时频域点进行聚类[7],使用BTFM将属于一类的时频点标记如下:
(14)
式中,aj和δj为第j个声源的对称衰减和相对延时。
利用式(14)将声源信号的时频单元提取出来,通过逆STFT(Inverse STFT, ISTFT)将提取的时频域下的源信号恢复到时频,从而达到语音分离的目的。
3.2 语音分离算法步骤
语音分离算法的具体步骤如下:
步骤1 构建时频掩膜。构建N个声源所对应的时频掩膜。
步骤2 将属于同一源信号的时频单元提取出来,得到单一声源的时频域表示。
步骤3 时频域反变换。将分离的单一声源的时频域经过短时傅里叶反变换到时域得到需要的源信号。
3.3 语音分离实验结果
根据图2所得到的参数直方图,首先确定各个声源峰值中心坐标,然后为每个峰值中心构建BTFM,得到信号的时频域表达,再对其进行短时傅里叶逆变换,将信号变换回时域,最后得到估计的声源信号。原始信号与其对应的估计信号如图3所示。
源估计采用SISEC2008[18]中的评价标准,定义信号失真比率(Signal to Distortion Ratio, SDR),信号源与干扰成分比率(Source to Interference Ratio, SIR),信号源与人造成分比率(Sources to Artifacts Ratio, SAR)分别如下:
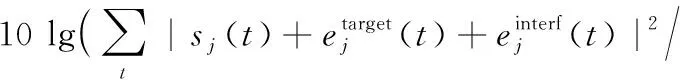
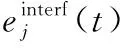
由表2可以看出,在无混响的条件下,本系统可以识别和分离出多个声源,在三声源和四声源实验中,分离效果较好。随着声源个数的增加,系统分离出的信号质量下降,主要原因在于在同一个时频域点,假设一个源占主导的情况不一定成立。
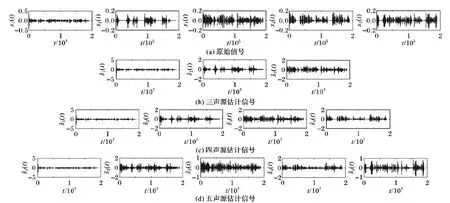
图3 原始的声源信号与分离后的估计信号Fig. 3 Original sound source signals and separated estimated signals

表2 语音分离结果评价Tab. 2 Speech separation result evaluation
4 声源定位
4.1 算法原理
在单位时间内,两个麦克风所获得的同一声源的能量的比值是固定的[19]。在一个时间点,仅存在单个源时,其能量的计算公式为:

(15)
其中,Ei(i=1,2)为第i个麦克风接受到的信号能量;xi(t)为第i个麦克风接受到的时域信号。
经过短时傅里叶变换后,信号在时频域中的能量公式为:

(16)
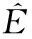
式(1)变换到时频域又可以表示为:

(17)


(18)


(19)
在时频点(τi,ωk),到达两麦克风之间的能量比为:

(20)
设(xi,yi)为第i(i=1,2)个麦克风的位置坐标,(xl,yl)为第l个声源的位置坐标,根据麦克风接收到信号的能量与麦克风到声源距离的关系[20]可得:
(21)
当估计出的第j个源到达两个麦克风的相对时延δj后,可得方程:
cδj
(22)
其中c为声速。
根据式(20)~(22),化简可得:

(23)
由于到达两麦克风的相对衰减αj和相对时延δj在语音分离阶段已经估计出来,其余各个参数都是已知的,求解方程组式(23),最后通过进一步的变换便可以得到方程的闭合解,从而确定声源在二维平面中的具体位置坐标。
4.2 声源定位实验结果
根据图2得到的信号参数分布直方图,首先读取各个峰的峰值坐标,然后根据式(7)将对称衰减aj转化为相对衰减αj,通过计算,得到参数对(δj,αj),再将参数分别代入到方程组式(20)中,根据实际情况舍去无关解,最终可以确定声源位置坐标。
声源定位结果和误差如表3所示,对定位精度的衡量采用文献[21]中的评价准则:
误差率=(估计坐标-原始坐标)/原始坐标×100%
由表3可知,系统进行多声源定位时,在X轴上的平均误差的绝对值分别为15 mm(三声源)、7.5 mm(四声源)和13.6 mm(五声源),在Y轴上的平均误差的绝对值分别为10.9 mm(三声源)、6.25 mm(四声源)和10.2 mm(五声源)。针对于三声源、四声源和五声源的定位,所有情况下的定位误差均在2%以下。由此可见,本文的模型可以在分离出多个声源的同时获得声源在二维平面中的位置,该方法具有一定的有效性。

表3 声源定位结果Tab. 3 Source localization results
5 结语
本文利用两个麦克风实现了多声源目标的分离和定位,在一定程度上克服了利用双麦克风进行分离定位时空间信息不足的缺陷,一定程度上能够满足系统对误差的要求,具有一定的实用价值,例如会议记录、助听装置、车载通信等。但是本文系统目前只考虑了二维平面中的定位,也仅适用于室内说话人数量较少的情况。在以后的研究中,为了更加接近实际的需要,除了考虑混响和环境噪声的干扰外,还应该将此模型扩展到三维空间,增加房间内声源的个数,进一步提高系统的性能。
