基于Hadoop的Linux系统日志分析平台的设计与实现
2018-12-28刘亮
摘要:本文以Hadoop大数据框架为基础,将Hadoop框架与关联规则分析法相结合,对Linux系统的日志文件进行挖掘与分析,对于提高Linux系统日志的存储能力、分析效率具有重要意义。
关键词:Linux系统;Hadoop平台;日志分析平台
一、引言
Linux系统是当前主流的操作系统之一,因其功能强大、性能稳定而成为大型服务器、数据库服务器的主要支撑性操作系统。Linux系统具有非常强大且灵活的日志功能,无论是用户的操作还是系统内核与程序所产生的各类信息,均能够以日志的形式记录下来,为用户查询历史操作以及管理员全面掌控Linux系统的运行状态提供重要依据[1]。Linux系统的日志随着系统的长时间运行而不断累积,其增长速度非常快,累积的日志文件会占用大量的系统硬盘存储空间,而Linux系统中的syslog只负责将操作记录与日志信息接收并存储在日志文件中,无法对日志文件进行精细化管理与深度化应用,一方面会导致日志文件中的记录不断新增会导致日志文件过大,日志文件的存储、组织与管理存在难度;另一方面日志中记录的累加给传统数据挖掘分析方法带来了大数据量的挑战,管理员或用户在检索、挖掘分析与应用日志文件时存在越来越大的难度[2]。Hadoop是当前应对大数据存储、管理与应用的平台,其HDFS为大数据存储提供方法支撑,MapReduce为大数据分析与挖掘提供平台支撑,将Hadoop应用到Linux系统日志文件管理与分析中,可以提高Linux系统日志的存储能力与管理效率。
二、基于Hadoop的Linux系统日志分析平台需求分析
Linux系统的日志文件中全面记录了系统的运行状态、错误信息等,对于挖掘与诊断Linux系统中存在的问题、解决系统存在的问题具有重要价值,为Linux系统的故障诊断与信息挖掘提供“有据可查”的综合性线索。利用Hadoop大数据平台存储与管理Linux系统的日志文件,可以有效存储Linux系统海量的日志文件,快速挖掘分析Linux系统日志文件中的潜在规律,当Linux系统遭到攻击时,可以借助系统日志文件以及Hadoop系统快速寻找到攻击者留下的痕迹[3]。基于Hadoop的Linux日志分析平台需要能够对导入到Hadoop平台的日志数据进行清洗与过滤,对日志数据进行关联规则分析,并对日志数据挖掘与分析结果进行数据展示。
三、基于Hadoop的Linux系统日志分析平台设计
基于Hadoop的Linux系统日志分析平台总体架构包括如下:
(1)基础设施层
基础设施层为存储各类Linux系统日志文件数据以及Hadoop大数据平台运行提供所依赖的基础软硬件环境与基础硬件设备设施,包括存储系统、网络环境等。
(2)数据资源层
数据资源层为基于Hadoop的Linux系统日志分析平台中的各类数据,包括用户日志、程序日志、内核与系统日志等。数据资源层为基于Hadoop的Linux系统日志分析平台提供丰富的数据支撑。
(3)服务资源层
服务资源层是基于Hadoop的Linux系统日志分析平台的基础服务支撑层,用于连接数据层与应用层,包括资源服务总线、各类服务接口、接口构建工具[4]。基于Hadoop的Linux系统日志分析平台的服务资源层基于数据资源层提供的数据支撑,向应用层提供查询检索、统计分析等基础服务。
四、基于Hadoop的Linux系统日志分析平台实现
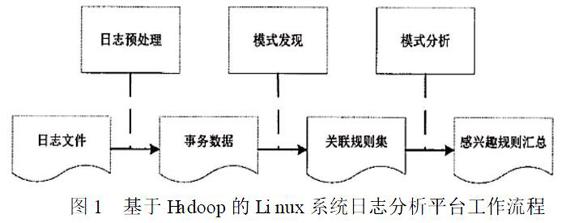
基于Hadoop的Linux系统日志分析平台工作流程如图1所示。
基于Hadoop的Linux系统日志分析平台中主要的两个核心功能包括日志数据预处理功能与关联规则挖掘分析功能,其具体实现如下:
(1)日志数据预处理
Linux系统的Syslog协议提供了一种传输方式,允许一台主机通过IP 网络发送事件给事件的接收者(Syslog服务器)。Syslog的消息内容没有一个统一的格式。Syslog协议是发送者与接收者之间的通信,不需要额外的协调机制。Syslog消息格式由三部分组成,如下是一个Syslog消息[5]:
<30>Oct 9 22:33:20 hlfedoraauditd[1787]: The audit daemon is exiting.
其中:
“<30>”是PRI 部分;
“Oct 9 22:33:20 hlfedora”是HEADER部分;
“auditd[1787]: The audit daemon is exiting.”是MSG部分。
由于各个日志记录描述事件的格式不同,从日志记录收集到的事件,经过解析后,必须要采用统一的格式,以便于进一步数据挖掘处理。可以采用对日志分类编号的方法,对安全设备与其产生的日志统一进行标号,每一中日志的分类号为Signature ID,该安全设备的日志编号为Normalized ID。从而日志进行统一(Normalization)后的格式为:事件触发时间(Frist time)、事件结束时间(Last time)、源地址(Source IP )、目的地址(Dest. IP)、源端口(Source Port)、目的端口(Dest. Port)、事件严重级别(Event Subtype)、唯一事件号(Signature ID),事件类别编号(Normalized ID)等等。使用对日志分类编号的统一化方法,可以简化日志分析,避免针对日志内容分类的复杂性。
(2)关联规则分析
关联分析是在大规模数据集中寻找有趣关系的任务。这些关系可以有两种形式:频繁项集、关联规则,频繁项集(frequent item sets)是经常出现在一块的信息日志集合,关联规则(association rules)暗示两种日志之间可能存在很强的关系。关联分析的目标包括两项:发现频繁项集和发现关联规则。首先需要找到频繁项集,然后才能获得关联规则(正如前文所讲,计算关联规则的可信度需要用到频繁项集的支持度)。Apriori算法是发现频繁项集的一种方法。Apriori算法的两个输入参数分别是最小支持度和数据集。
五、结论
日志文件对于诊断和解决系统中的問题很有帮助,因为在Linux系统中运行的程序通常会把系统消息和错误消息写入相应的日志文件,这样系统一旦出现问题就会“有据可查”。此外,当主机遭受攻击时,日志文件还可以帮助寻找攻击者留下的痕迹,本文对基于Hadoop的Linux系统日志分析平台的功能需求、总体框架设计以及主要功能的实现进行详细阐述,为基于Hadoop的Linux系统日志分析平台设计与实现提供参考。
参考文献:
[1]王全民,王蕊,赵钦.Linux环境下的日志分析系统LASL[J].北京工业大学学报,2005(04):420-422.
作者简介;;刘亮,长沙民政职业技术学院助教,研究生,硕士,研究方向:大数据技术与应用。
