基于卷积神经网络的舌象分类
2018-12-28胡继礼阚红星
胡继礼,阚红星
(安徽中医药大学医药信息工程学院,安徽合肥230012)
卷积神经网络[1](Convolutional Neural Network,CNN)由Hinton 教授于2006年提出,它是一种前馈神经网络,深度学习[2]卷积神经网络通过建立多层神经网络来模仿人脑对图像进行解释和分析,可以发现更深层次的数据分布式特征表示。目前在工业、生物医疗、智能制造等多个领域采用深度学习技术,已经取得了令人瞩目的成果,谷歌通过分析病人眼球的视网膜图像,可以预测一个人的血压、年龄和吸烟状况[3]。中医体质学[4],是以中医理论为指导,以生命个体的人作为研究出发点,旨在研究人体不同体质构成的特点对疾病演变过程造成的影响,从而指导疾病的预防、诊治、康复与养生的一门学科。舌象的变化可以直观灵敏地反映人的各个器官的新陈代谢的变化,通过对舌象的分析来探究人体的阴阳盛衰、虚实寒热,具有很大的参考价值。目前关于舌象的处理[5-7],大部分是surf特征提取技术,但这些研究存在局限性:(1)他们使用的舌象都是过于理想化的舌象样本数据,没有复杂背景;(2)底层特征没有高层语义的特征信息,大部分是直接从原始图片中直接进行像素提取,不能作为特征识别的可靠依据。本文在TensorFlow[8]平台下构建舌象图像识别分类模型,将卷积神经网络图像处理技术引入到中医体质辨识系统,实现中医体质辨识的客观化,从而为中医体质辨识提供新的研究思路和手段,辅助医生对体质进行快速诊断,提高医生的工作效率。
1 卷积神经网络原理
卷积神经网络[9-11]的每一层通常会包含卷积层、池化(Pooling)层、修正线性单元(ReLU)层或激活层,在每一层中一般会定义一个权值矩阵与图像的像素点进行卷积。卷积层的目的是用来滤波,以便更有效地查看图像区域的特征,前一层的卷积运算结果经过激活函数运算会输出成为下一层的神经元,以便构成下一层对应某一特征的特征图。在经过多轮的卷积、ReLU、池化后,会检测出图像的高级特征。网络最后进行全连接,这一层主要处理由卷积层、也可能是ReLU层或是池化层的输出内容,最后输出一个N维向量,N一般代表分类的数量。由于卷积神经网络比普通神经网络增加了卷积层、池化、降采样层,非常适合视觉处理和图像识别分类处理领域,卷积层一方面可以很好地提取相邻图像像素之间的共同特性,另一方面能减少训练过程中产生的神经网络参数数量。
图1所示为卷积神经网络结构,一般从输入层input输入图像,卷积层与输入层相连,中间层由卷积层和降采样层相互交替连接,每进行一次卷积运算,就会进行一次下采样,然后再进行卷积。经过这样多次的卷积与下采样后,再进行全连接,最终得到整个网络的output[12]。
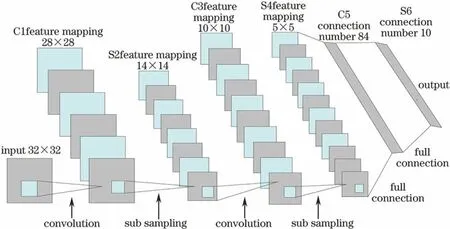
图1 卷积神经网络结构
在进行分类时,输出层使用带有标签的目标信息,采用softmax函数进行网络收敛计算,特征映射结构一般采用sigmoid函数作为卷积网络的激活函数,sigmoid是使用范围最广的一类激活函数,在物理意义上最为接近生物神经元,使得特征映射具有位移不变性。为降低CPU和GPU运算的复杂度,通常卷积神经网络会共享神经元的权重,用不同的卷积核去提取不同的特征,可以有效地减少训练过程复杂度和参数数量。在进行卷积时,不同的卷积核进行卷积可提取前一层特征图的不同特征,这些不同特征的特征图一起作为下一层子采样的输入数据。例如第l层卷积中的第j个神经元可表示为
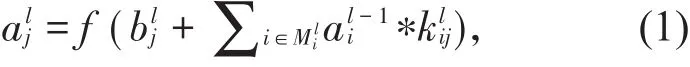
其中f()表示激活函数,b为偏置量,k代表卷积核,M代表输入层感受野。通常一个卷积层会由多个特征图构成,并且相互共享权值,以便降低卷积网络中的参数数量。一般在卷积层之后进行子采样层,也叫池化层,子采样层一般选取多个像素的平均值或最大值,将多个像素值压缩为一个进行特征提取,达到减少数据规模,降低网络分辨率的目的。由子采样计算神经元的公式为
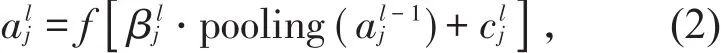
公式中的pooling()表示池化函数,β表示加权因子。卷积神经网络训练过程一般分为前向和后向传播两个阶段,在前向传播阶段,输入层逐层向前传播信息,通过各种卷积层和完全连接层,最后到达输出层,网络在此过程执行的计算公式为
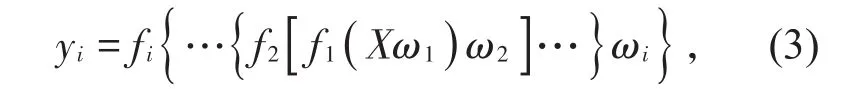
其中,fi()代表第i层的激活函数,ωi代表第i层卷积核的权值向量,第i层卷积网络的输出记为yi。在卷积神经网络的后向传播过程中,先计算标签信息和实际输出差值,再按照极小化误差的方法,采用随机梯度下降法反向传播调整卷积神经网络各层的权值。卷积神经网络能够实现自动特征学习,和传统识别算法相比,其模型构建复杂度低、权值数量少、可实现权值共享[13-14],并且可避免复杂的手动提取特征和重建数据过程,在应用到大规模的图像识别分类时具有较大优势。
2 基于Tensorflow的卷积神经网络舌象分类
中医根据舌象的不同特征,将人体的体质类型分为9种,体质类型和舌苔症状对照见表1所示。将CNN卷积神经网络技术引入到舌象分类数据处理中,可自动对舌象进行特征提取。根据其数据的特点和性能需求,实验选用MobileNets[15]模型进行分类训练,然后将训练后的模型文件用于舌象的分类,从而辅助医生进行体质类型诊断。

表1 体质舌象对照表
2.1 数据来源和预处理
本文的舌象数据来源于某中医药大学附院。根据病人的舌诊信息,图片已经进行了标注。本文选取了阴虚和阳虚中的部分图片集作为实验训练数据,每个分类下面有2 000张图片。由于原始的舌象图片分辨率为2 592×1 728 px,过大,训练会耗费大量的CPU资源和内存资源,并且很容易造成内存OOM,所以首先使用python的第三方包PIL(Python Imaging Library)对原始图片进行缩放处理,将分辨率降低到600 px。处理后舌象数据集如图2所示
图2 舌象数据集图
2.2 工具和环境
以Tensorflow1.4版作为卷积神经网络训练工具。TensorFlow是Google公司于2015年开发,它是一个开源的深度学习框架。Tensorflow通过计算图graph形式先描绘出一个交互操作图的方式,图中的节点op代表数学运算,而图中的边则代表在这些节点之间传递的张量(即多维数组),费时的矩阵运算在Python语言外部进行,这种灵活的架构可以高效地构建深层神经网络。在使用TensorFlow进行编程时,开发者一般需要使用import导入需要使用的第三方函数库,因自身并不包含所有的运算函数,比如处理图形的函数库PIL,处理科学计算的函数库NumPy,当需要使用NumPy函数库时,通常采用“import numpy as np”命令调用NumPy的科学计算函数。
实验环境和主要配置参数如下:在MacOS操作系统中运行TensorFlow1.4进行实验,处理器3.1 GHz Intel Core i5,内存 16 GB 2 133 MHz LPDDR3,显卡 Intel Iris Plus Graphics 650 1 536 MB,磁盘SSD 256 G。
2.3 实验过程
(1)创建项目文件夹tf_files,创建命令如下:
cd~
mikdir-p pythonsrc/tf_files
(2)创建舌象数据集文件夹及其子文件夹
首先在项目文件夹tf_files下创建tongue_photos文件夹,然后再创建两个子文件夹yinxu(阴虚)和qixu(气虚),再分别将收集到的具有不同体质特征的舌象图片放入其中,比如将具有阴虚和气虚体质特征的舌象图片分别放入相应的文件夹用于后面的图像分类识别,创建好的目录截图如图3所示。
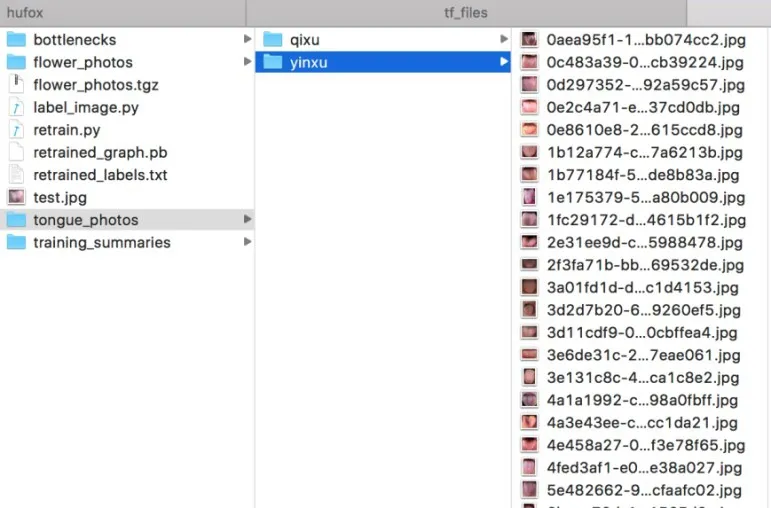
图3 文件夹目录图
(3)创建迁移训练代码retain.py
该段代码源自Tensorflow examples中的image_retraining示例代码,通过curl命令下载获取。命令如下:
curl–O代码地址
其中代码地址为:https://raw.githubusercontent.com/tensorflow/tensorflow/r1.4/tensorflow/examples/label_image/label_image.py
(4)执行训练脚本
在命令行窗口执行python retain.py即可执行迁移训练,后面需要跟上一些必要参数进行训练,执行如下命令:
python retrain.py
--image_dir~/pythonsrc/tf_files/tongue_photos/
--output_graph=retrained_graph.pb
--output_labels=retrained_labels.txt
--learning_rate=0.0001
--testing_percentage=20
--validation_percentage=20
--train_batch_size=32
--validation_batch_size=-1
--flip_left_right True
--random_scale=30
--random_brightness=30
--eval_step_interval=100
--how_manytraining_steps=600
--architecture mobilenet_1.0_224
--summaries_dir=training_summaries/basic
--bottleneck_dir=bottlenecks
该训练脚本基于MobileNets模型进行训练,MobileNets模型不仅实现了70.5%的精度,而且生成的模型大小只有18 MB,占用资源率低,非常适合在移动手机端运行和应用。其中--how_many_training_steps用于指定训练的迭代次数,--architecture用于指定使用哪种训练模型。本实验参数值设置为mobilenet_1.0_224,其中1.0是模型的相对大小,可以采用1.0,0.75,0.50或0.25,推荐使用1.0作为初始设置,较小的型号虽然运行速度会更快,但精确度会降低;224是指输入图像分辨率,可以使用128,160,192或224像素,更高分辨率的图像需要更多的训练和处理时间,但是会有更好的分类精度,这里推荐224作为初始设置。其他参数的含义可以通过运行“python retrain.py–h”脚本查看。
(5)利用TensorBoard查看训练过程
TensoFlow提供了非常方便的可视化工具TensorBoard(a suite of visualization tools),可以帮助开发者方便理解、调试和优化TensorFlow程序。打开TensorBoard可以对训练进行可视化查看,执行如下命令启动TensorBoard:
tensorboard--logdir tf_files/training_summaries&
启动后,打开浏览器,在地址栏输入http://localhost:6006/,回车后即可看到可视化的训练界面,单击SCALARS可以查看训练精度(如图4)和交叉熵(如图5)的变化。在训练过程中,会产生一系列步进输出,每个输出会显示训练的准确性、验证精度和交叉熵:其中震荡变化的折线表示在当前批次训练中带有正确标签分类的训练精度;另一条变化平滑的线代表验证准确性,不同集合随机选择的图像组的精度,被正确标记的图像的百分比;交叉熵代表损失函数,较低的数字在这里表示更好的分类精度。

图4 训练精度变化图
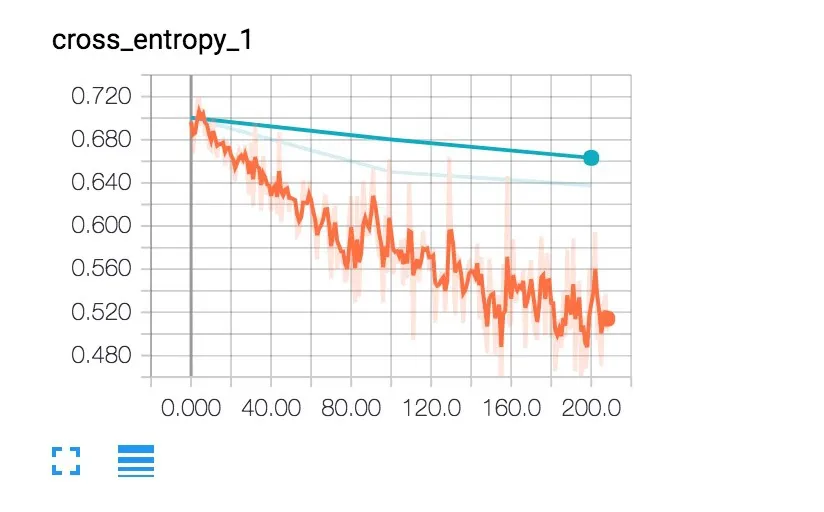
图5 交叉熵变化图
训练完成后,会在当前文件夹生成两个文件,tf_files/retrained_graph.pb是模型文件,包含了在舌象类别上进行迁移训练的最后一层的模型版本,tf_files/retrained_labels.txt是标签文本文件,包含了舌象分类识别的标签名称,即qixu(气虚)和yinxu(阴虚)。
2.4 检验实验结果
(1)下载labelimage源码
curl-O代码地址:https://raw.githubusercontent.com/tensorflow/tensorflow/r1.4/tensorflow/examples/label_image/label_image.py
(2)准备一张舌象图片test.jpg,然后执行如下命令:
python label_image.py
--graph=retrained_graph.pb
--labels=retrained_labels.txt
--image=test.jpg
--input_layer=input
--output_layer=final_result
--input_mean=128
--input_std=128
--input_width=224
--input_height=224
注意:因为上一步生成模型时指定了参数architecture为mobilenet_1.0_224,图像分辨率是224,所以这一步也必须指定输入的宽度和高度分辨率为224,即input_width和input_height为224,运行结果如图6所示,最后显示气虚(qixu)的概率为1.0,阴虚(yinxu)的概率为2.387 58e-14。
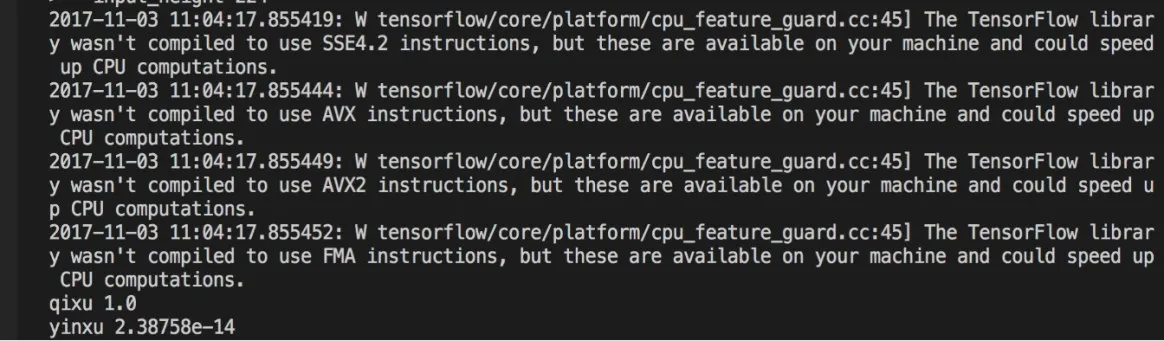
图6 检测结果图
3 结 论
本文将深度学习卷积神经网络运用到中医舌象识别分类中,利用TensorFlow机器学习软件平台搭建舌象分类MobileNets模型,对舌象图像数据进行数据预处理后进行训练,可以得到较好的识别精度和计算效率,分析中医体质与舌象之间的关系,用以发现中医舌诊的规则和模式,从而辅助医生对病人体质进行诊断。将机器学习卷积神经网络技术引入到舌象识别分类中,为中医的舌象诊断提供了一种新的方法和手段。
