基于XGBoost方法的葡萄酒品质预测
2018-12-26孙逸菲袁德成王建龙
孙逸菲, 袁德成, 王建龙, 白 杨
(沈阳化工大学 信息工程学院, 辽宁 沈阳 110142)
葡萄酒是一种成分复杂的饮品,其质量测定是葡萄酒行业进行质量管理的重要手段之一.测定葡萄酒质量主要通过专业品酒师的品尝和测量葡萄酒的物理化学性质来进行判定.质量评价主要依靠品酒师的感官,品酒师通过观察葡萄酒的颜色、质感等外观特性和嗅闻葡萄酒的香气,并结合品尝的方式进行葡萄酒的质量评价.而测量葡萄酒的物理化学性质是指测量其非挥发性酸度、密度及pH等,这种测量方法对葡萄酒的质量测评比较有效.
在数据分析过程中,经常需要对数据建模并做出预测.Boosting分类器属于监督学习范畴,它的基本思想是把成百上千个分类准确率较低的树模型组合起来,组合成为一个准确率较高的模型[1].这个模型会不断地迭代,每次迭代生成一颗新的树.对于如何在每一步生成合理的树,有很多种解决方法,其中在1999年由Jerome Friedman提出的梯度推进机(Gradient Boosting Machine)[2]是一个相对效率较高的算法.它在生成每一颗树的时候采用梯度下降的思想,以之前生成的所有树为基础,向着最小化给定目标函数的方向多走一步.现在希望能通过XGBoost工具更好地解决这个问题.XGBoost(Extreme Gradient Boost)是Gradient Boosting Machine的一个C++实现[3],它最大的特点在于能够自动利用CPU的多线程进行并行,同时在算法上加以改进,提高精度.
随着科学技术的进步,使得收集、存储和处理数据成为可能,机器学习技术在葡萄酒品质预测中也得到了广泛的应用.对葡萄酒质量的评价方法较多,刘延玲[4]利用改进的人工神经网络对葡萄酒物理化学性质及感官进行了分类预测;李运等[5]介绍了运用聚类算法、主成分分析方法、相关分析方法等对葡萄酒质量进行评价;徐海涛[6]提出利用改进的近似支持向量机方法对葡萄酒质量进行鉴定和预测;林劼等[7]利用随机森林算法对葡萄酒品质进行了预测,通过与其他方法的比较表明其预测精度较高;Cortez等[8]将线性回归、神经网络和支持向量机这三个回归技术应用于对葡萄酒品质的预测.
针对葡萄酒质量检测这一问题,本文采用机器学习中XGBoost算法进行葡萄酒品质预测,将该方法与线性回归、神经网络和支持向量机算法相比较[8],发现该方法具有预测准确率高及运算时间短的特点,在葡萄酒品质测定过程中,能够有效地减少因品酒师个人因素所带来的偏差,对于提高酿酒品质和葡萄酒的生产测定都具有重要意义.
1 XGBoost机器学习算法
监督学习算法的重要组成部分包括模型、参数和目标函数.模型和参数本身指定了给定输入,我们如何做预测;目标函数的作用是使我们能够找到一个比较好的预测.一般的目标函数包括下面两项[3]:
Obj(Θ)=L(Θ)+Ω(Θ)
(1)
L(Θ)表示误差函数,Ω(Θ)是正则化项.
1.1 回归树的重要组成部分
XGBoost最基本的组成部分叫做回归树.对于树的集合,可以把模型写成:
(2)
其中每个f是一个函数空间F里面的函数,而F是包含所有回归树的函数空间.设计的目标函数包含两部分,误差函数和正则化项:
fk∈F
(3)
1.2 Gradient Boosting学习模型
(1) 学习方法:公式(3)中第一部分是误差函数,第二部分是每棵树的复杂度的和.对于树模型,每一次保留原来的模型不变,加入一个新的函数f到模型中.
(4)

(2) 目标:选取一个f来最小化目标函数
Ω(ft)+C
(5)
其中C为常数.
(3) 再采用如下的泰勒展开定义一个近似的目标函数,用泰勒展开近似原来的目标.泰勒展开式为:
f(x+Δx)≈f(x)+f′(x)Δx+
(6)
定义gi和hi:
(7)
(4) 得到新的学习目标函数:
(8)
当把常数项移除之后
(9)
这个目标函数的特点是它只依赖于每个数据点在误差函数上的一阶导数和二阶导数.
(5) 重新定义每棵树
先对f的定义作细化,把树拆分成结构部分q和叶子权重部分ω.结构函数q把输入映射到叶子的索引号上去,而ω给定了每个索引号对应的叶子分数.
ft(x)=ωq(x),ω∈RT,q:Rd→{1,2,…,T}
(10)
ω∈RT表示叶子的向量,q为树的结构.
(6) 定义一棵树的复杂度
(11)
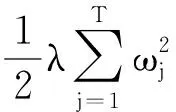
(7) 在这种新定义下,目标函数为
(12)
其中I被定义为每个叶子上面样本集合Ij={i|q(xi)=j}.这个目标包含了T个相互独立的单变量二次函数.可以定义Gj=∑i∈Ijgi,Hj=∑i∈Ijhi.那么这个目标函数可以进一步改写成如下的形式,假设已经知道树的结构q,可以通过这个目标函数来求解出最好的ω,以及最好ω对应的目标函数最大的增益.
(13)
等式的左边是最好的ω(叶子权重部分),右边是这个ω对应的目标函数的值:
(14)
(15)
(8) XGBoost算法流程
在每一次迭代中增加一个新树,对每一次迭代计算:
(16)
gi为误差函数的一阶导数,hi为误差函数的二阶导数.运用算法寻找切分点,产生每一轮新的树
(17)
增加新函数ft(x)到模型
(18)
通常加入y(t)=y(t-1)+εft(xi),ε称为缩减因子,目的是为了避免过拟合,通常设置为0.1.
2 运用XGBoost算法对葡萄酒品质进行预测
2.1 实验数据的选取
葡萄酒数据[9]来自于认证阶段的物理化学分析测试,这些来自于2004年5月至2007年2月收集到的样本数据.数据从生产需求到感官分析被一个计算机系统记录.每一个实例都是基于一次测试的结果,最终的数据集导入一个.csv文件中.在预处理阶段,数据转换为一个二维表,每一行代表一个单独的葡萄酒样本.由于红葡萄酒和白葡萄酒存在较大差异,所以,将红葡萄酒和白葡萄酒的数据分为两个.csv文件进行存放与处理.
红葡萄酒的样本数量为1 599个,白葡萄酒的样本数量为4 898个.输入变量包括客观实验测试得到的11个物理化学性质,如表1.

表1 每种类型中的葡萄酒物理化学数据属性Table 1 The physicochemical data statistics per wine type
输出变量基于感官数据,感官数据分为0(极坏)~10级(非常好),由三位品酒师通过感官评价,选取三人中评分最低一人的评分作为评估值(运用盲测方法)[2].极坏和非常好的葡萄酒样本都是少数,评价为中间等级的葡萄酒样本最多.所以将红葡萄酒分为6类,评价等级为3至8;白葡萄酒分为7类,评价等级为3至9,如图1.
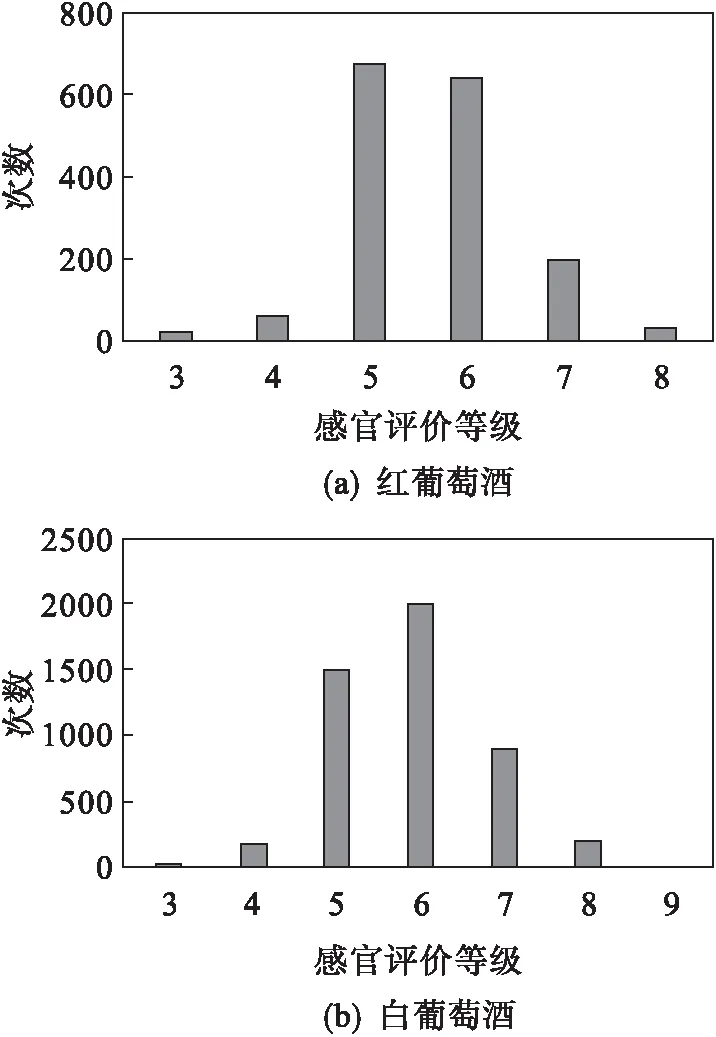
图1 对红葡萄酒和白葡萄酒的感官性能评价Fig.1 The histograms for the red and white sensory preferences
2.2 XGBoost算法在葡萄酒品质预测中的应用
2.2.1 葡萄酒品质判定的XGBoost方法和研究
在python环境下安装XGBoost的C++版本.通过预测模型准确率来判断模型的优劣.通过分类和k-Fold两种方法评估XGBoost模型.分类方法的步骤是[10]:导入葡萄酒数据,准备用于训练和评估XGBoost模型;将数据集分成输入X和输出Y两部分,将X和Y的数据分成训练集和测试集,训练集用于准备XGBoost模型,测试集用于从之前评估的模型性能中做新的预测;将67 %的数据用于训练,33 %的数据用于测试;之后运用model.fit()函数拟合模型并对XGBoost模型进行预测.k-Fold方法的步骤是[10]:运用10折交叉验证,把数据随机分成10份,然后依次取1份作为测试集,其余9份共同作为训练集,之后用XGBoost算法拟合训练集数据得到模型.首先导入葡萄酒数据,其次指定折叠的数量和数据集的大小;运用cross_val_score()函数可以运用10折交叉验证法对XGBoost 模型进行预测.
2.2.2 仿真结果与分析
运用XGBoost算法下的葡萄酒特征提取图如图2所示.图2中表示的是葡萄酒的11个输入变量,f0~f10分别代表了实验测试得到的11个物理化学性质(表1),这些物理化学性质特征从大到小顺序依次如图2所示.在获得的图形中证实了酿酒学的理论.比如f10代表酒精度越高表示葡萄酒的品质越高.当然对于不同种类的葡萄酒,变量重要性排序是不同的.几类数据在一些理化性质上相差不大,但图3中f5代表的游离二氧化硫的特征重要性大,可以说明这一理化性质大大影响口味.从图2和图3可以看出葡萄酒质量评价也是一个非常困难的工作.

图2 红葡萄酒特征重要性条形图Fig.2 The red wine input importances bar chart
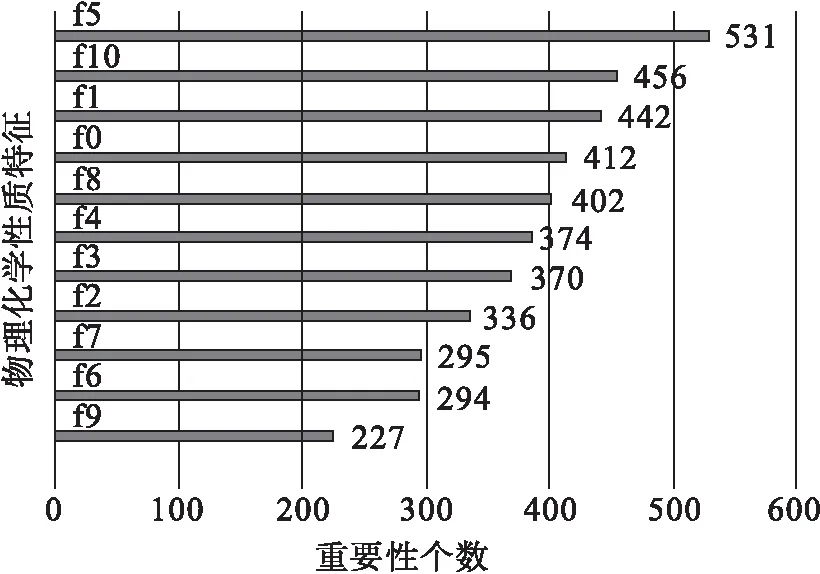
图3 白葡萄酒特征重要性条形图Fig.3 The white wine input importances bar chart
为了使葡萄酒的品级预测更加完善并提高准确率,运用XGBoost算法的分类方法和k-fold方法分别进行了仿真试验.在分类方法中将67 %的数据用于训练,33 %的数据用于测试.在k-fold方法中指标分类器错误率的估计采用10折交叉验证法.表2和表3为采用XG Boost分类方法和k-fold方法进行葡萄酒品质预测的结果,并将实验结果与Cortez等人[8]运用数据挖掘技术中的其他3个回归技术作了比较.

表2 采用XGBoost分类与k-Fold方法对红葡萄酒品质的预测结果Table 2 The XGBoost classification and k-Fold method predict the quality of red wine
表中T代表容错率,实际指绝对误差.比如实际输出y=1,模型预测的输出只要在容错率T=0.25内(y在0.75~1.25之间)就认为分类是准确的.表2中列出红葡萄酒的验证仿真数据.前3种算法是Cortez等人先前研究的结果.表格最后两列是通过XGBoost算法得出的分类准确率和k-Fold法准确率.从表2可以看出:在容错率为25 %的情况下,运用XGBoost分类算法预测的红葡萄酒准确率为61.9 %,运用XGBoost k-Fold交叉验证算法预测的准确率为58.6 %,这都明显高于线性回归算法、神经网络算法和支持向量机算法的预测准确率.在准确率为50 %的情况下,同样可以看出XGBoost分类方法的预测准确率高于线性回归算法、神经网络算法和支持向量机算法的预测准确率.从运行时长来看,XGBoost分类方法和k-Fold交叉验证算法的运行时长明显快于其他3种算法的运行时长.虽然支持向量机算法的预测准确率相对较高一些,但是通过支持向量机算法测试数据集将耗费大量的运算时间.

表3 采用XGBoost分类与k-Fold方法对白葡萄酒品质的预测结果Table 3 The XGBoost classification andk-Fold method predict the quality of white wine
表3是采用XGBoost分类方法和k-Fold交叉验证算法对白葡萄酒品质进行预测的结果.与线性回归、神经网络和支持向量机的预测结果进行比较,可以看出:在容错率25 %的情况下,通过XGBoost分类算法预测的白葡萄酒准确率为57.9 %,XGBoost k-Fold交叉验证算法预测的白葡萄酒准确率为54.8 %,这也明显高于其他算法的准确率.在容错率为50 %的前提下,可以看出:无论是XGBoost分类方法还是XGBoost k-Fold交叉验证算法,其准确率都比线性回归和神经网络的准确率高.虽然支持向量机在50 %容错率的情况下准确率比XGBoost算法准确率高,但是运行时间却是XGBoost算法运行时间的约150倍.所以,综合上述两表可以看出XGBoost算法具有运行时间短、准确率高的优点.
将XGBoost分类方法和XGBoostk-Fold交叉验证算法互相比较可以看出:XGBoost分类方法的准确率略高于XGBoost通过k-Fold交叉验证算法的准确率,但是通过k-Fold交叉验证算法的准确程度相比较分类方法更高.因为在k-Fold交叉验证运行算法过程中,每一次都运用不同的训练与测试数据进行迭代,使得计算出的准确率更加精确,但运行时长也相对较长.
3 结束语
通过化学检验的方法获取一系列参数,并采用机器学习方法进行建模、预测,可以有效地减少因品酒师个人主观因素带来的对葡萄酒品质判定的偏差,并通过改变特征重要性提高葡萄酒的品质.采用机器学习中XGBoost学习算法对葡萄酒的数据进行了学习仿真,对葡萄酒数据准确率进行评估,并与其他算法进行比较,对结果进行了分析.一旦识别出某些变量和质量评价的关系,就能够在葡萄酒生产阶段对某些变量加以控制,以使口味更好.以上分析结果可以看出:XGBoost算法在葡萄酒品质预测的应用中明显优于线性回归和神经网络算法,并优于在容错率T=0.25情况下的支持向量机算法.XGBoost算法的运行时长相对于其他3种算法相对较短.这些对于改进酿酒、品酒评价和葡萄酒的生产测定都具有重要意义.
