基于统计调和平均值的特征加权关联分类算法
2018-12-24郭叔瑾吴辰文
郭叔瑾,吴辰文
(兰州交通大学 电子与信息工程学院, 甘肃 兰州 730070)
乳腺癌是第二大常见的人类肿瘤,约占女性所有癌症的四分之一[1-5]。在大多数国家,乳腺癌被认为是女性死亡的主要原因,因此应尽力减少这种慢性疾病[2-3]。研究人员使用数据挖掘技术来加强人们对该疾病的认识,数据挖掘是数据库知识发现的主要阶段,其中包括一系列针对不同目标的方法,如分类、聚类,关联规则和AC[6-8]。本文将重点介绍AC技术,并展示如何使用它来加强乳腺癌领域的决策过程。
分类技术旨在预测任何给定实例的类标签,而关联技术旨在发现大型数据库中项目之间的关系。近年来,为了提高分类准确度,为乳腺癌等许多关键领域提供服务,研究人员在分类过程中采用了关联规则技术,探索了一种称为关联分类(AC)的新技术[6,9-10]。AC技术在分类过程中采用关联规则来增强隐藏模式,提高分类准确性,在许多应用领域的决策过程中起着主要作用。AC技术是第二代关联规则技术,已经实现了查找项目和类之间的相关性。例如规则R:Item1,Item2→Class1,被解释为:如果项目值Item1和Item2针对特定对象O在任何情况下一起出现,则O被归类为Class1[6,9-10]。
大多数AC算法使用支持度和置信度产生关联规则,而不关注具体应用领域。此外,不使用任何技术来区分给定数据集中属性的重要性。为了避免当前AC算法的不足,本文提出了一种基于统计调和平均值的特征加权关联分类算法(Feature weighted association classification algorithm based on statistical harmonic mean, FWAC)。FWAC算法的基本思想是用加权模型代替传统关联规则挖掘模型的支持度置信度结构,确定对乳腺癌疾病有重大影响的属性,并由相关专家赋予其最高优先级。本文还使用统计调和平均值(Harmonic mean, HM)在剪枝和规则生成阶段对关联规则进行排序,从规则剪枝阶段产生的强规则中排除了具有弱属性的规则。实验结果表明,数据集中属性的权重对分类规则有很大的影响。通过文中的实例展示了如何将FWAC算法应用于实际领域。为了测试FWAC算法的性能,将FWAC算法与一组著名的AC算法进行了比较,在大多数情况下,FWAC算法在精度方面优于其他AC算法。此外,在运用FWAC算法之前,领域专家需给每个属性分配权重。要想对算法进行推广,还必须对其他领域进行研究,并将其与AC算法进行比较。最后,使用Python3.0工具来探索并将结果可视化。
1 关联分类的背景
AC技术是关联规则和分类技术的组合。关联规则技术的目的是发现属性之间的关联,而分类技术负责预测类别标签。文献[11]对AC问题进行了描述。我们使用表1所示的数据集T来解释AC的概念和定义。

表1 5个训练对象的数据集实例TTab.1 Dataset sample T with five training objects
在AC问题中,关联规则被用于分类过程。训练数据集T具有n个不同的属性(A1,A2,…,An),C是类别列表。属性可以是分类的也可以是连续的。分类属性的所有可能值被映射到一组正整数,而连续属性使用某种离散化方法对其进行离散化。T中的行或者训练对象可被描述为属性名称Ai,值vi和类别Ci的组合,并且该项目可被描述为属性名称Ai和值vi的组合。如表1所示(A1,v1)是一个项目,项目集是训练对象中包含一组项目,如(A1,v1)(A2,v3)是一个项目集。项集规则r的形式是
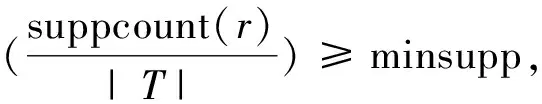
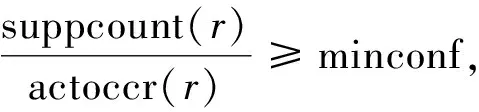
任何符合最小支持度阈值的项集规则r都被认为是一个频繁项集规则,而实际的类关联规则则表示为(A1,v1)∧(A2,v2)∧…∧(Am,vm)→Cj,规则的前件是一个项目集,后件是一个类。
2 5个关联分类算法
Liu等人[9]研发了一种基于关联分类技术的算法,称之为基于关联规则的分类(Classification based on association rules, CBA)。CBA算法有3个阶段:第一阶段是规则生成阶段,使用Apriori算法发现类关联规则(Class association rules, CARs)的频繁模式;第二阶段是剪枝阶段,负责从生成的规则中选择最佳规则;第三阶段是预测阶段,负责预测未知实例。该算法应用于UCI机器学习库中的许多数据集上。
Yusof等人[12]提出了一种基于关联规则的修改的多类分类算法(Modified multi-class classification based on association rule, MMCAR)。MMCAR算法采用新的规则产生函数,只使用相关规则进行预测。该算法使用基于Tid-list的方法来计算项目值的支持度和置信度。MMCAR与RIPPER,C4.5和MCAR就分类准确度和生成的规则数进行比较。实验结果表明,MMCAR的分类准确度高于RIPPER和C4.5,MCAR算法的平均准确度略高于MMCAR算法,但是MMCAR产生的规则数少于MCAR产生的规则数。
Wu等人[13]基于浓缩的概念提出了一种用于分类的浓缩关联规则(Condensed association rules for classification, CARC)。CARC算法使用改进的Apriori算法来生成关联规则,并开发了新的规则推理策略。利用浓缩度量和规则推理策略可以生成更多有用的关联规则,并改进了关联分类算法的效率。实验结果表明,CARC减少了设置过高或过低最小支持度所带来的问题,在分类准确度方面具有较好的性能。
Hadi等人[14]提出了一种新的快速关联分类算法(Fast association classification algorithm, FACA)。规则生成过程中使用了Diffset方法来提高构建模型的速度。此外,根据前件数最少、置信度、支持度和首次生成的规则等作为评价标准,对挖掘出的规则进行排序。FACA还提出了预测阶段的多规则方法来提高分类过程的准确性。具体来说,该算法将匹配的规则划分为基于其标签的类,然后选择规则数最多的类标签。为了评估算法的性能,作者将他们的工作与文献[15]中描述的CBA,CMAR,MCAR和增强型关联规(Enhanced class association rule, ECAR)进行了比较。
增强型CBA(Enhanced CBA, ECBA)算法是基于Apriori优化和Alwidian等人[16]提出的统计排序方法。将该算法与CBA,CMAR和MCAR算法进行比较,评估其准确性。实验结果表明,与其他算法相比,ECBA在准确度方面表现得更好。
表2比较了FWAC算法和以上5种AC算法。他们的主要区别是FWAC算法使用了主题专家分配的属性权重和统计调和平均值来确定生成规则的优先级。其他AC技术可能会由于用户给出的有问题的估计方法而提早删除一些好的关联规则,但FWAC算法将好的规则保持到最后,从而提高了准确性。
许多研究人员使用关联规则挖掘乳腺癌数据集并预测。 Shrivastava等人[3]介绍了用于乳腺癌数据集的数据挖掘技术,在包含699个样本和两个分类的乳腺癌数据集上使用了一组分类器。实验结果表明,该技术在未知实例的预测过程中有良好的性能,也展示了在这个研究领域中使用数据挖掘技术的潜力。Majali等[5]应用关联分类技术对癌症的诊断和预后进行了研究。采用FP-Growth算法生成关联规则,发现良恶性患者的隐藏模式,提高分类准确度。Bhagwat等人[17]研究了许多分类器来预测患者是否会面临复发。Shrivastava等人[3]和Majali等人[5]开发的算法的缺点之一是都使用了由用户估计的支持度和置信度阈值,因此排序过程总是受这些值的影响。此外,Bhagwat等人[17]的研究使用黑箱分类器,这些分类器不能产生用户可以解释和理解的规则。为了避免这些缺陷,本文提出了FWAC算法,并将其应用于乳腺癌预测问题。
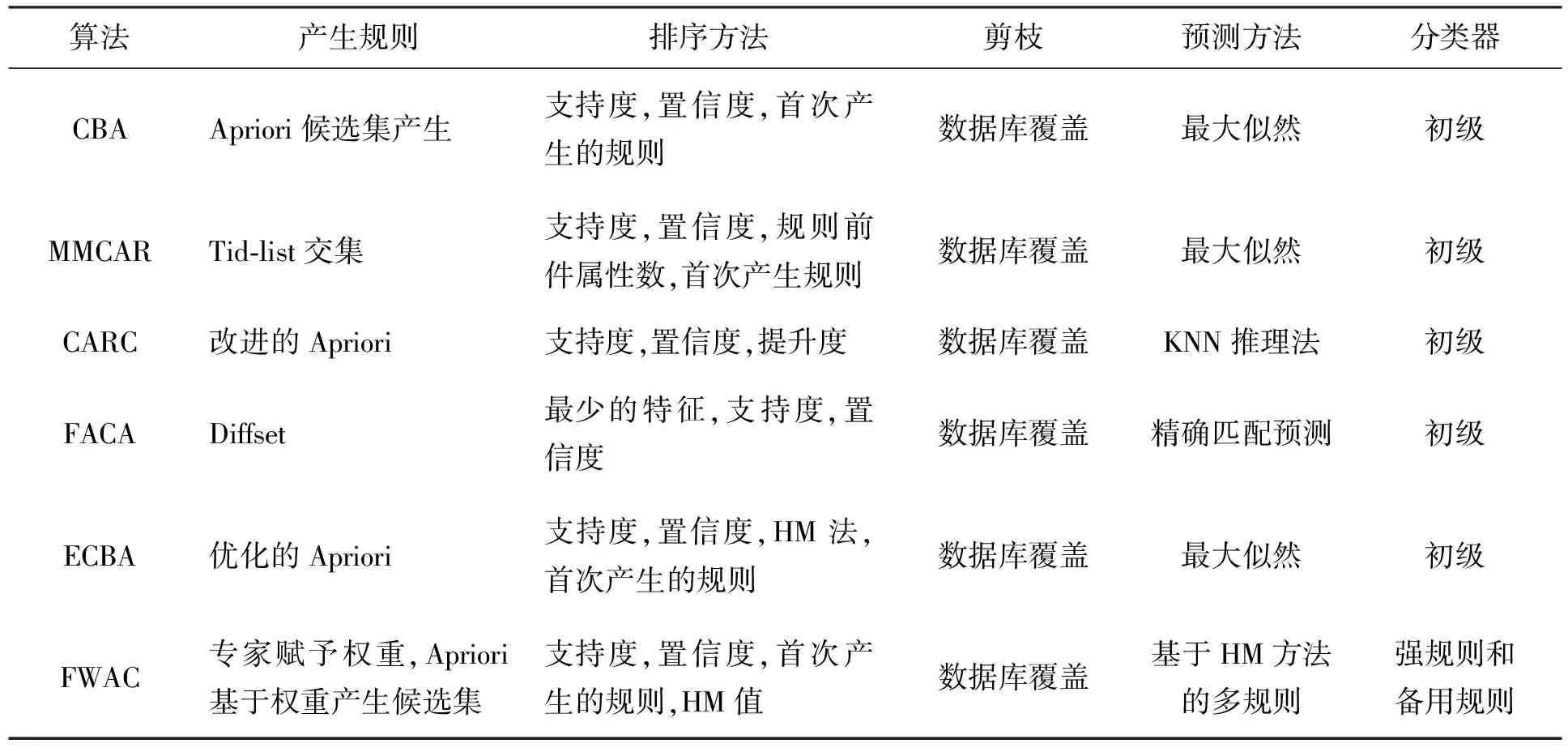
表2 6种算法的比较Tab.2 Comparison of six algorithm
3 特征加权关联分类算法
3.1 特征加权关联规则介绍
在传统的规则挖掘中,规则是否重要取决于数据库中项目集的数量。传统的规则挖掘考虑支持度和置信度,以找出频繁项集,并假定所有项目都具有同等重要性。Wang等人[18]提出了加权关联规则挖掘方法(Weighted association rule mining, WARM)。它通过为数据库中的项目分配权重来推广传统的关联规则挖掘算法。权重用来反映数据库中项目的重要性。在该算法中,使用领域知识为数据集内的项目分配权重,数据集经过权重生成算法,将权重作为WARM算法的输入,并使用加权支持度来生成有趣的规则列表。目的是引导挖掘过程中具有重要权重的项目进行有意义的关联,并使用加权支持度来生成有趣的规则列表[19]。大多数数据项没有预先分配的权重[20],权重由该领域的专家调整,由于专家可以分配不同的权重,从而产生不同的规则。在某些情况下,使用领域知识来确定所有项目的准确权重可能是不切实际的,特别是当数据集具有大量项集时。在这种情况下,可以使用半自动化或自动化方法[21-22]。基于这些原因,本文提出了一种新的加权算法FWAC。
3.2 提出的FWAC算法
FWAC算法旨在基于高效的规则加权技术来提高关联分类器的准确性。它被用于解决在生成类关联规则时需要估计支持度和置信度的问题。算法1显示了FWAC算法的工作流程,涉及3个阶段:规则产生;规则剪枝;分类预测。
算法1FWAC算法
1)拥有n个训练对象的数据集T
2)FWAC(T,n) {将数据集T分为训练集和测试集
3)S=∅
4)S=产生的规则(训练集,最小支持度,n)
5)规则剪枝(最小置信度,S)→
(强规则,备用规则)
6)预测(强规则,备用规则,测试集)}
算法2规则产生
1)规则产生(训练集,最小支持度,n)
2){S′=∅ ,k=1
3) while(Sk-1!=∅){
4)Sk=生成的所有候选k-项集
5)forSk中的每一个项集规则r
7)Weight(r)=
8)Weighted support(r)=Weight(r)×
Support(r)
9)if Weighted support(r)>=最小支持度
10)S′=S′+r
11)End if
12)End for
13)k=k+1}
14)ReturnS′}
第1步:规则产生。与其他AC算法不同,FWAC算法在生成关联规则之前,需要领域专家为数据集中的属性分配权重。属性权重可以根据3种不同的度量(高、低、中)来分配从1到10的值。1到3代表低,4到7代表中,8到10代表高。我们将展示如何使用这些方法来处理乳腺癌复发数据和诊断数据。算法2展示了FWAC算法如何从加权数据集中生成规则。基于算法2,规则生成算法的主要输入是训练集、最小支持度和n,其中n是训练数据的大小。
首先,FWAC从训练数据中生成所有候选单项集。然后,计算每个项集的支持度和加权支持度。算法为重要的特征分配高优先级,以使它们出现在较好的规则中。最后,FWAC找到频繁的单项目集规则。那些加权支持度大于或等于给定的最小支持度的规则,被插入到S′中,而其他规则将被消除。这一步将重复从Sk中找到候选的和频繁的项集规则,其中k是规则中的项集数。
第2步:规则剪枝。首先,计算每个频繁规则的置信度。其次,消除每个置信度值小于最小置信度的规则,其余的成功规则将被添加到类关联规则中。然后,找出每个频繁规则的HM。使用HM度量克服了其他AC算法通常使用估计的最小支持度和最小置信度的问题。其他AC算法在最终规则集中不会生成支持度或置信度低于估计的最小支持度和最小置信度的规则。例如,最小置信度是0.6,最小支持度是0.2,则不会产生置信度为0.59,支持度为0.6的规则。因此,FWAC算法使用在支持度和置信度之间产生的HM值。为了得到强规则,所有生成的规则都基于它们的HM度量值进行排序。对于具有相同HM值的规则,将根据他们的置信度、支持度和第一次出现的顺序进行排序,这种情况下的首次出现是指首先生成的规则。这一阶段的最后一步是应用M1方法进行数据覆盖,将规则分成两组:强规则和备用规则[9]。
第3步:分类预测。对于任何给定的实例i,FWAC检查强规则集合中可以分类i的规则。接下来,将规则分成基于类标签的组。然后,计算每个类的平均HM值,并将实例归类为HM最大的那一类。如果FWAC在强规则集中找不到匹配规则,则继续搜索备用规则集。否则,给定实例将被预测为默认类,其中默认类是具有最大频率的类。如果不止一个类具有相同的频率,则将选择具有首次出现的类。FWAC忽略任何测试实例的缺失值。
3.3 应用FWAC算法的例子
以下示例说明了FWAC算法的工作原理。假设我们有如表3所示的买房数据集T,最小支持度为5/6,最小置信度为0.5。

表3 数据集TTab.3 Dataset T
我们想要预测实例[junior, middle, N]的类别值。对于这个例子,表3中分配给Buy类的是"no"标签。现在,我们想知道FWAC算法预测的结果是否和表3中的结果一致。在房地产行业,分析师可能希望根据相关数据集中属性的重要性来挖掘规则,因此,他们对包含"Income"属性的规则比包含"Age"属性的规则更感兴趣,这两者都与购买更多的房屋有关。在这个数据集中,"Income"属性应该得到比"Age"属性更高的权重以反映其重要性。权重可以让用户方便地了解属性的重要性,并获得更有趣的规则。基于此,表4显示了根据数据集T中属性的重要性为各个属性分配的权重。

表4 数据集T中各个属性对应的权重Tab.4 Weight of each attribute in dataset T
关于FWAC算法如何工作的分步说明如下:
第1步:通过计算每个规则的支持度和加权支持度生成所有候选单项集规则。规则r=(senior→yes),分配权重给属性"Age"=2,根据算法2的第6,7,8行,有Support=1/3,Weighted support(senior→yes)=2/3。
第2步:找出频繁单项集规则,其中频繁单项集规则的加权支持度大于或等于给定的最小支持度。再根据支持度和加权支持度来找到候选2-项集规则。根据候选2-项集规则找到频繁2-项集规则,依次类推,直到找不到频繁k-项集规则,算法结束并停止生成规则。保持满足CAR中最小置信度的所有规则,并消除其他规则。以下示例展示了如何计算特定规则r的置信度值。规则r=(senior→yes),supportcount(senior→yes)=2,actoccr(senior)=2,则根据置信度计算公式得到Confidence(senior→yes)=2/2=1。
第3步:基于HM值对CAR中的规则进行排序,如表5所示。如果多个规则具有相同的HM度量值,则将分别基于置信度、支持度和规则优先次序对规则进行排序。以下示例显示如何计算特定规则r的调和平均值HM。规则r=(low→no),Weighted support(r)=9×1/6=1.5,Confidence(r)=1,由于
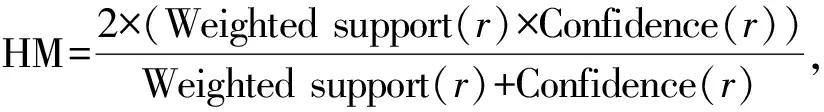
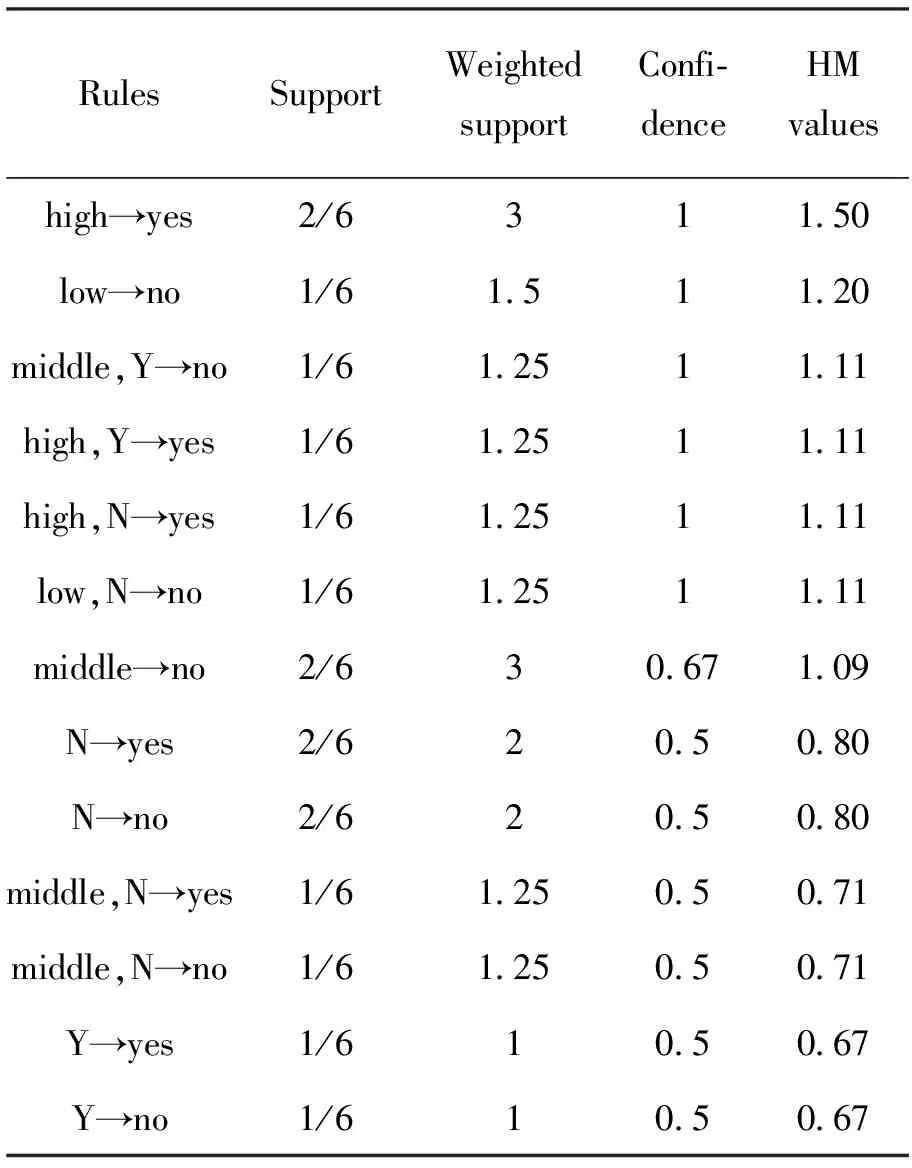
表5 基于HM值的规则排序Tab.5 Rule sorting based on HM value
第4步:使用M1方法进行数据覆盖,将规则分成两组,强规则和备用规则,如表6和表7所示。
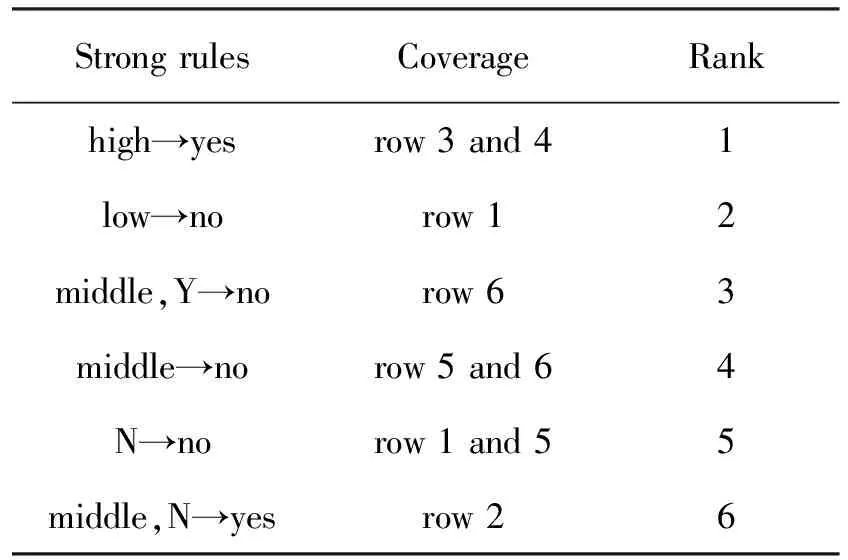
表6 强规则集合Tab.6 The set of strong rules
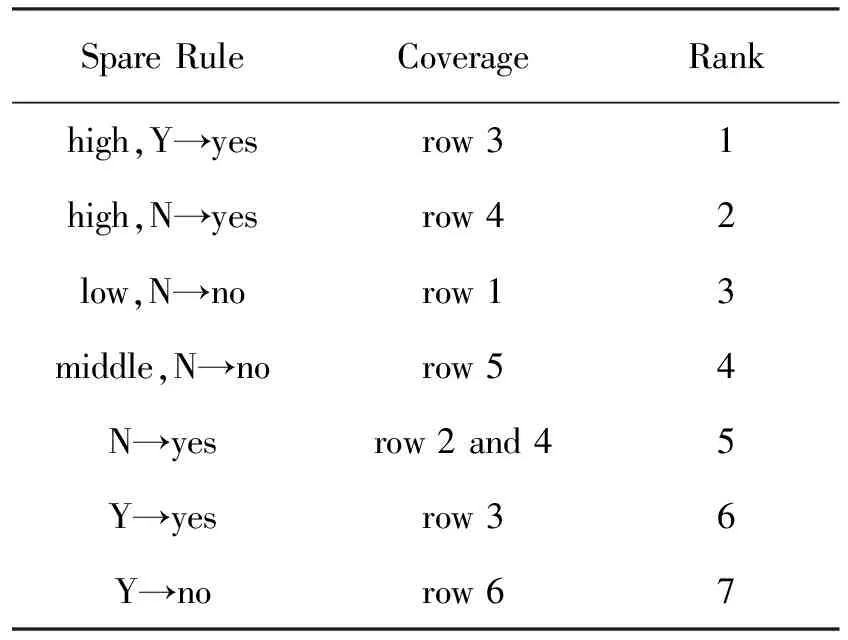
表7 备用规则集Tab.7 The set of spare rules
假设需要预测[junior, middle, N]实例的类别。该算法检查可以匹配此实例的强规则集。最后,发现了以下两条规则:middle,N→yes,N→no。然后根据目标类"Buy"的类型将这两个规则分为两组,如下所示:Cluster(yes) has the rule: middle,N→yes和Cluster(no) has the rule: N→no。计算类Buy="yes"的HM值为0.71,而类Buy="no"的HM值为0.80。 因此,该实例的类值为"no"。 所以,FWAC算法计算出的值符合表3的实际值。
为了说明备用规则集的有用性,下面举例来解释:假设需要预测一个未知实例[?, high, Y]的类,其中"?"表示缺失值。首先,FWAC算法忽略缺失值,继续检查强规则的集合以找到一些匹配规则。由于没有在强规则集中找到匹配规则,它试图在备用规则集中找到一些匹配的规则。发现只有一个匹配规则:high, Y→yes。则该实例的类值为Buy="yes"。因此,预测值符合表3的实际值。
4 在乳腺癌数据集上进行实验
实验平台采用64位的Windows7操作系统,处理器为Intel(R) Core(TM) i5,内存为4GB。实验数据来自UCI机器学习库,FWAC是用python3.0实现。
4.1 乳腺癌数据集
为了测试FWAC算法,使用了来自UCI机器学习库的两个乳腺癌数据集:乳腺癌诊断数据集和乳腺癌复发数据集。乳腺癌诊断数据集包含10个属性和699个实例,如表8所示。乳腺癌复发数据集包含10个属性和286个实例,如表9所示。
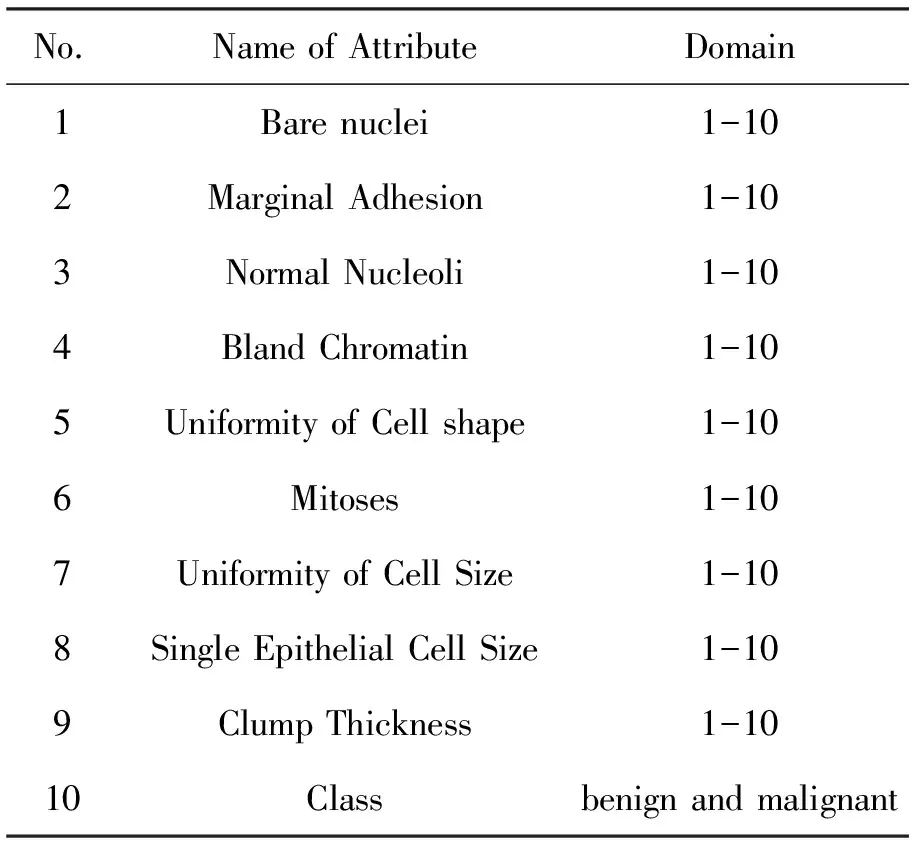
表8 乳腺癌诊断数据集Tab.8 Breast cancer diagnosis dataset
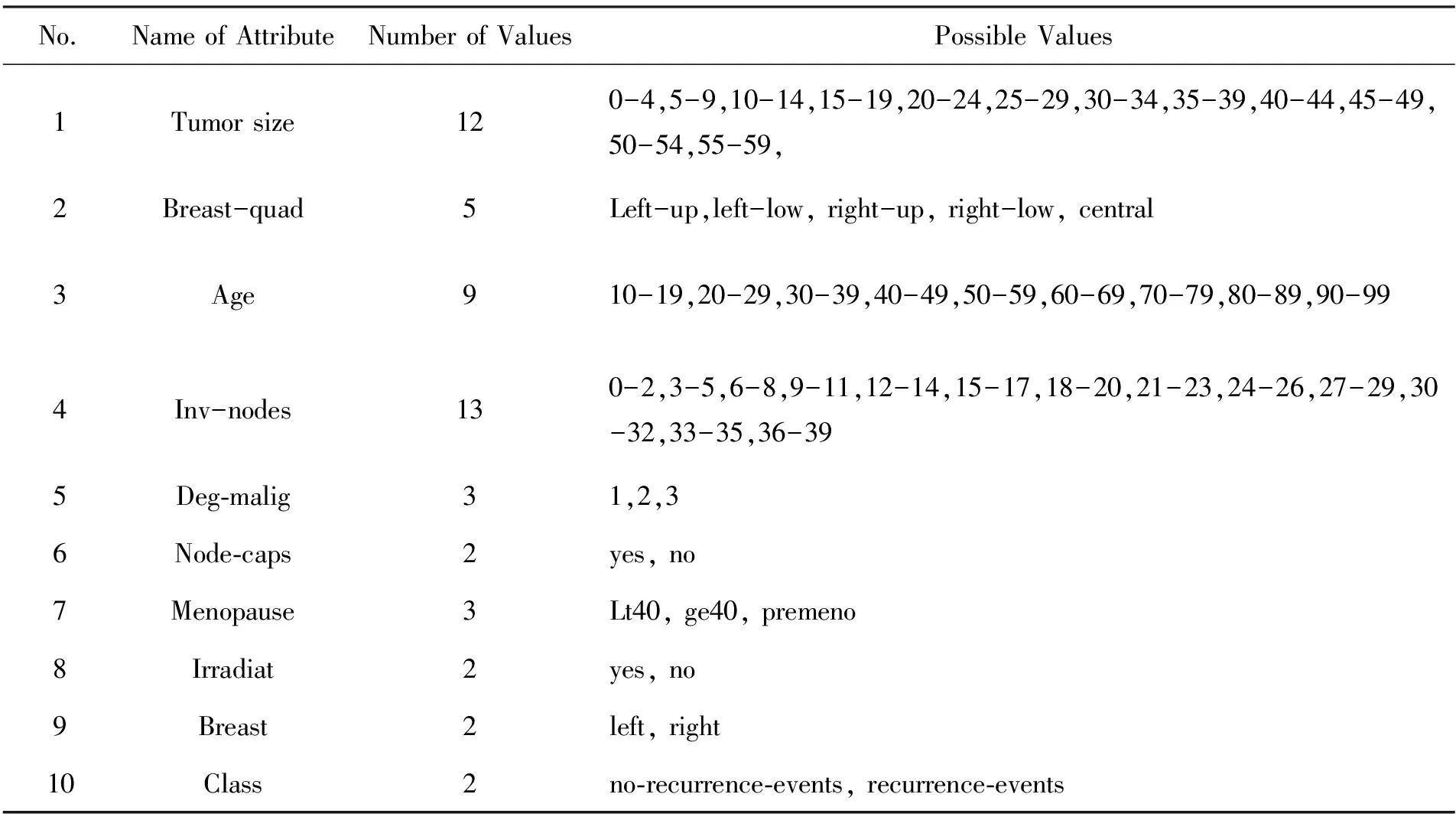
表9 乳腺癌复发数据集Tab.9 Breast cancer recurrences dataset
为了明确乳腺癌数据集中属性的重要性,并帮助我们为每个属性分配准确的权重,我们向甘肃省肿瘤医院的主题专家寻求帮助。甘肃省肿瘤医院是面向西北地区最大的医学科研及肿瘤专业防治机构。我们与专家讨论了UCI数据集,并根据这些属性在预测乳腺癌复发和诊断过程中的重要性,使用如前所述的低,中,高3种方法对属性进行分类。结果如表10和表11所示。
4.2 实验结果分析
借鉴前人的研究,最低支持度设定为10%至30%[6,13-14],且建议置信度固定为50%。表12为两个乳腺癌数据集在FWAC算法以及5种AC算法上运行结果的准确率。从表12可以看出,对于3次运行,FWAC算法在乳腺癌复发数据集上运行时的表现优于其他5种AC算法,准确率分别为69.78%,73.64%和70.94%。同时,对于乳腺癌诊断数据集,FWAC算法也优于其他5种AC算法,准确率分别为97.3%,97.6%和96.9%。此外,在对乳腺癌复发数据集进行实验时,FACA和ECBA算法在第一次运行中排在第二位,准确率为67.43%。 第二次运行中FACA算法排在第二位,准确率分别为68.62%。在第三次运行中,CARC算法排在第二位,准确率为66.48%。此外,在对乳腺癌诊断数据集进行实验时,CARC算法在第一次运行中排在第二位,准确率为96.8%。 在第二次运行中CBA算法排在第二位,准确率为94.6%。 在第三次运行中,FACA算法排在第二位,准确率为94.1%。FWAC在准确性方面优于其他AC算法,由于它对乳腺癌疾病具有最高影响的属性赋予最高的优先级,同时,消除了在规则修剪过程中产生的最高规则列表中的弱属性。当最小支持度为0.2,最小置信度为0.5时,FWAC算法在乳腺癌复发数据集和乳腺癌诊断数据集上生成的前5条规则如图1和图2所示。在图1中,由FWAC算法产生的前5条规则包含对乳腺癌影响最大的属性。这些规则在准确的类别预测中起着重要作用,提高了分类的准确性。图1也显示了与我们的预期相一致的地方,在生成的规则中排除弱属性"Breast"和"Breast-quad"。与FWAC不同的是,其他AC算法生成的最高规则与乳腺癌复发数据集的"Breast"和"Breast-quad"等弱属性相关联,这是降低其分类精度的原因。可以注意到,在图1中,由FWAC生成的前两个规则被其他AC算法所忽略,这主要是因为常用的AC算法使用估计的最小支持度和最小置信度值。此外,本文的分类器使用HM度量排序生成的规则,以加强剪枝过程。最后,FWAC算法没有消除未通过数据库覆盖方法生成的规则。当强规则不能预测新实例时,这些规则被存储在用于分类过程的备用规则集中。

表10 乳腺癌复发属性的权重Tab.10 Weights of breast cancer recurrence attributes
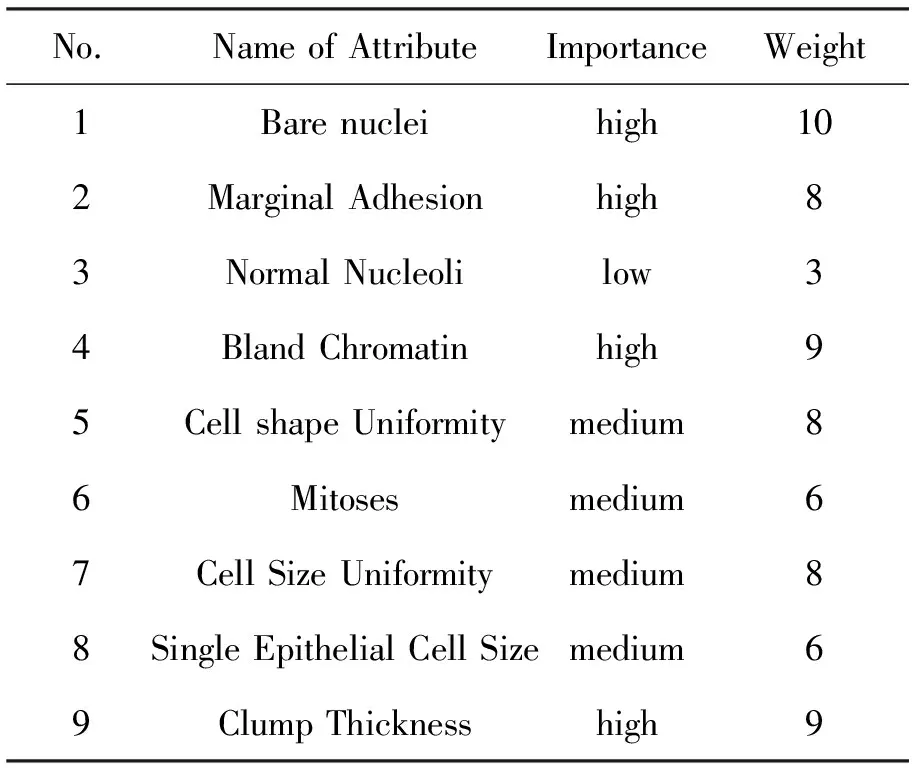
表11 乳腺癌诊断属性的权重Tab.11 Weights of breast cancer diagnosis attributes
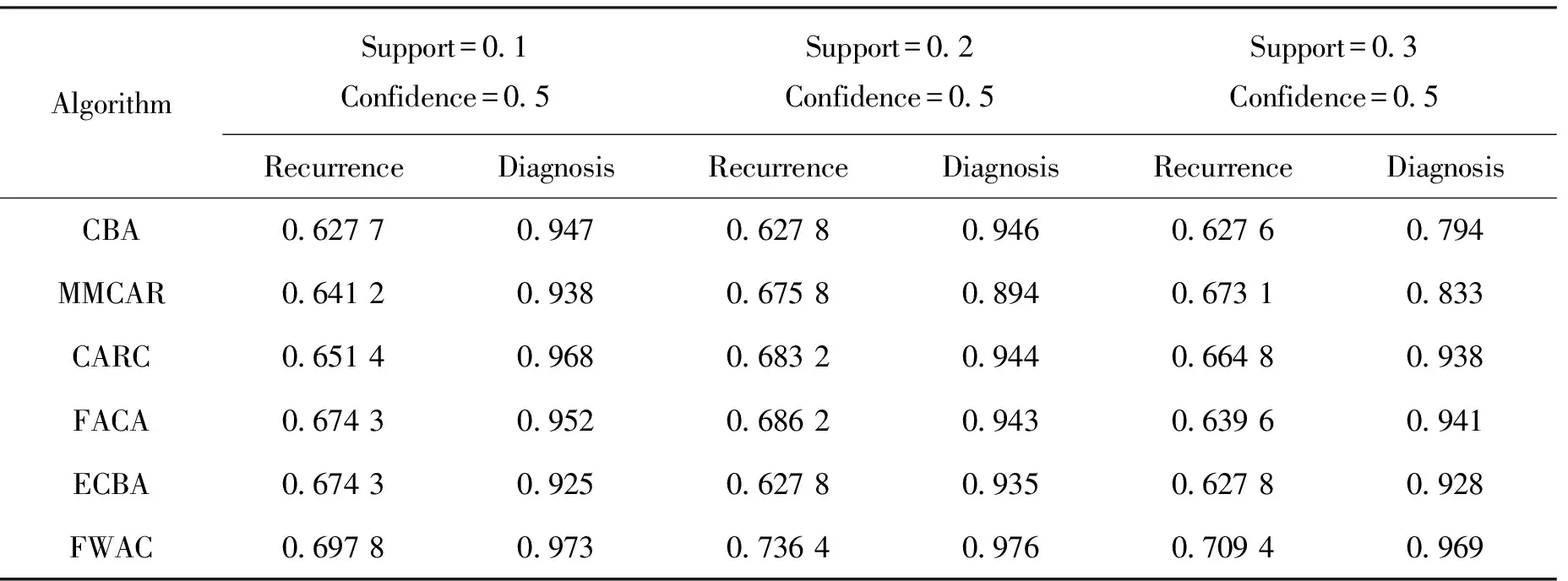
表12 两个乳腺癌数据集在所有算法上运行的准确率Tab.12 Accuracy of two breast cancer dataset running on all algorithms

图1 FWAC算法在乳腺癌复发数据集上生成的前5条规则Fig.1 The first five rules generated by FWAC algorithm on breast cancer recurrence dataset
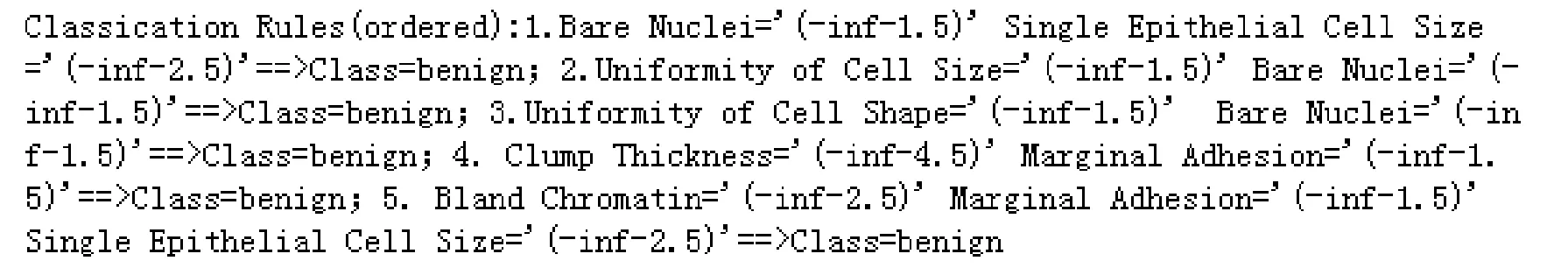
图2 FWAC算法在乳腺癌诊断数据集上生成的前5条规则Fig.2 The first five rules generated by FWAC algorithm on breast cancer diagnosis dataset
5 结 语
本文研究了一种新的关联分类算法FWAC。FWAC技术旨在提高基于有效规则加权技术的关联分类器的准确性。它解决了常用AC算法在生成类关联规则时,使用估计的支持度和置信度值的缺点。FWAC算法基于加权方法选择更有用的关联规则,并使用统计度量来对规则进行修剪,所有这些特性都有助于提高FWAC算法在精度方面的性能。作为研究案例,已经在乳腺癌数据集上测试了5种常见AC算法和FWAC算法。在所有的实验中,FWAC都优于其他AC算法。从实验结果可以得出以下结论:
1) FWAC算法应用属性加权方案对重要属性和不重要的属性进行排序。由领域内的主题专家来分配权重。实验结果表明,加权方案可以有效提高AC算法的精度。
2) FWAC算法应用了两个分类器:一个是针对包含最重要属性的强规则分类器,另一个是针对包含不重要属性的备用规则分类器。这种方法限制了默认类规则的使用,该规则通常具有不可接受的错误率。
3) FWAC算法使用统计HM方法来解决估计的最小支持度和最小置信度度量问题,使得FWAC可以使用多个规则来预测未知的实例。
本文只针对UCI上的乳腺癌数据集进行了实验,故还存在局限性。对于未来的工作,需要在不同领域测试FWAC算法,首先从甘肃省肿瘤医院的实际乳腺癌数据集开始。此外,我们还计划研究不同的加权、修剪和预测技术的使用情况,并考察它们对不同领域的影响。
