基于校园社交网络数据的情绪分析及可视化
2018-12-22窦亚玲郭文静周武彬
窦亚玲 郭文静 周武彬
摘要:以社交网络中活跃的大学生用户群的QQ空间、说说等文本数据为对象,依据四类基础词库(积极、消极、否定词、程度词),结合Python第三方库Pandas库和matplotlib库,给出了5-LevelEA情绪分析算法。该算法能计算出社交网络文本数据中的多项情绪指标,再通过可视化图表呈现所采集数据中的个人情绪变化趋势以及性别、就业情况等要素作用下的情绪分类数据,具有实用价值。
关键词: 社交网络;情绪分析; 数据可视化; Python
中图分类号:TP311 文献标识码:A 文章编号:1009-3044(2018)32-0003-04
Abstract:Based on the QQ space, speaking text data of the active college student user groups in the social network, according to the four basic lexicons (positive, negative, negative, degree words), combined with the Python third-party library Pandas library and matplotlib library, A 5-levelEA emotional analysis algorithm is given. The algorithm can calculate a number of emotional indicators in the social network text data, and display the emotional classification trends in the collected data and the emotional classification data under the influence of gender and employment conditions through the visualization chart.The test data shows that the algorithm has certain effectiveness.
Key words: social network;emotional analysis;data visualization;python
1 引 言
社交网络[1]蓬勃发展直接促成了网络大数据时代的到来[2]。大数据给科学技术、商业、教育等不同生态环境和产业格局带来全新的思维理念与机会。大学生作为社交网络的活跃人群,网络已经成为他们信息获取、情绪表达、人际交往、自我展示以及社会参与的舞台,对其认知、情感、意志品质、行为习惯等人格要素产生了不可忽视的影响。大学生社交网络数据分析研究具有一定的社会意义。本研究以某高校毕业季学生在QQ空间、说说等社交网络数据为对象,进行文本数据情绪分析,从发布频率、性别差异、情绪变化等多方面给出可视化数据图表,为高校大学生就业升学的情绪状况提供数据参考,服务于高校学生工作。
2 社交网络文本数据情绪分析算法设计
2.1分词处理与创建情绪词典
通过爬虫程序获取所需的文本数据,首先需要对文本进行预处理:分词。分词将一连串字符转换成相互分离、容易识别的词语。算法中选择sunjunyi开发的具有强大的中文分词能力的python分词组件“结巴jieba”,并在三种模式:全模式、精确模式、搜索引擎模式中选择精确模式,将文本句子精确分开,随后扫描出句子中所有可以成词的词语。
import jieba
seg_list = jieba.cut('我今天来到了长沙,很开心。',cut_all=False)
print('/'.join(seg_list))
输出:我/今天/来到/了/长沙/,/很/开心/。
情绪词典是分析社交网络中情绪文本的情感和倾向的基础[3-6]。本文采用的四类情绪词,包括积极词库、消极词库、否定词库和程度词库。这些自定义的词库,存放在.txt文件中,在程序中通过open()函数进行读取,实现添加或修改。
(1)积极词:积极的含义是指肯定的、正面的、促进发展的、努力的、热心的。本词库中含有18964个字符的积极词。
(2)消极词:消极与积极相对,含义是否定的、消极的、反面的、不思進取的。本词库中含有34416个字符的消极词。
(3)否定词:否定词用来把字面上的意思与要表达的意思变成不一致,可以是动词,也可以是副词。本词库含有20个字符的否定词。
(4)程度词:在程度上对一个形容词或者副词进行限定或修饰的词语。程度词位置一般在被修饰的形容词或者副词之前。在算法中程度词被分为四个不同程度等级,赋给不同的权值,通过index()函数找到标识隔开。本词库中含有431个字符的程度词。
在此基础上,完成情绪分析算法的设计。
2.2 5-LevelEA情绪分析算法设计
算法中将情绪量化成5个层级,分别为非常积极(很高兴)、积极(高兴)、无情绪波动(中)、消极(忧伤)、非常消极(很忧伤)。
算法中变量做如下定义:
(1) Posa和Posi用来记录扫描到词的位置,初始值为0;
(2) n是用来作为记录情绪词前面的否定词个数的变量,初始值为0;
(3) Poscount, Poscount2, Poscount3和Negcount,Negcount2,Negcount3分别记录积极情绪和消极情绪的第一次分值,反转后的分值和最后的分值,初始值都为0;
(4) Midcount用来累计感叹号的分值,初始值为0。
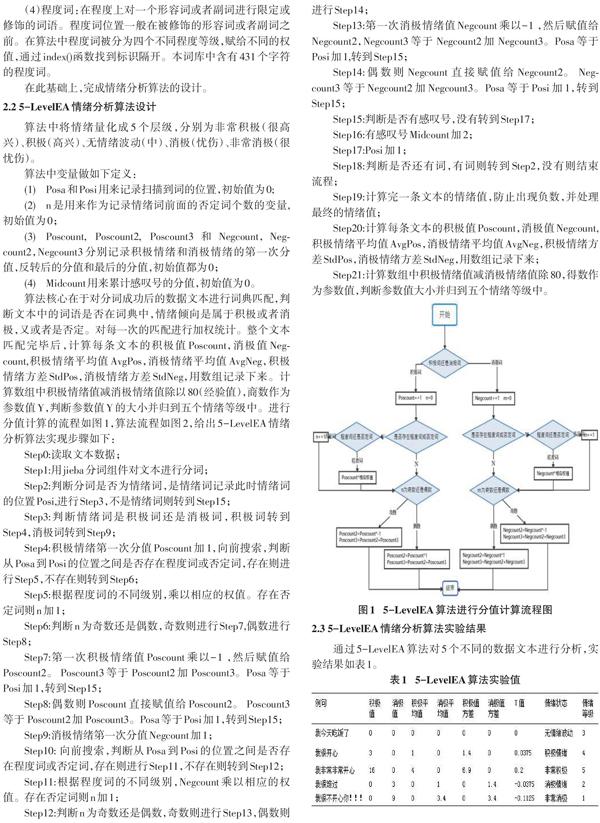
算法核心在于对分词成功后的数据文本进行词典匹配,判断文本中的词语是否在词典中,情绪倾向是属于积极或者消极,又或者是否定。对每一次的匹配进行加权统计。整个文本匹配完毕后,计算每条文本的积极值Poscount,消极值Negcount,积极情绪平均值AvgPos,消极情绪平均值AvgNeg,积极情绪方差StdPos,消极情绪方差StdNeg,用数组记录下来。计算数组中积极情绪值减消极情绪值除以80(经验值),商数作为参数值Y,判断参数值Y的大小并归到五个情绪等级中。进行分值计算的流程如图1,算法流程如图2,给出5-LevelEA情绪分析算法实现步骤如下:
Step0:读取文本数据;
Step1:用jieba分词组件对文本进行分词;
Step2:判断分词是否为情绪词,是情绪词记录此时情绪词的位置Posi,进行Step3,不是情绪词则转到Step15;
Step3:判断情绪词是积极词还是消极词,积极词转到Step4,消极词转到Step9;
Step4:积极情绪第一次分值Poscount加1,向前搜索,判断从Posa到Posi的位置之间是否存在程度词或否定词,存在则进行Step5,不存在则转到Step6;
Step5:根据程度词的不同级别,乘以相应的权值。存在否定词则n加1;
Step6:判断n为奇数还是偶数,奇数则进行Step7,偶数进行Step8;
Step7:第一次积极情绪值Poscount乘以-1 ,然后赋值给Poscount2。 Poscount3等于 Poscount2加 Poscount3。Posa等于Posi加1,转到Step15;
Step8:偶数则Poscount直接赋值给Poscount2。 Poscount3等于 Poscount2加 Poscount3。Posa等于Posi加1,转到Step15;
Step9:消极情绪第一次分值Negcount加1;
Step10: 向前搜索,判断从Posa到Posi的位置之间是否存在程度词或否定词,存在则进行Step11,不存在则转到Step12;
Step11:根据程度词的不同级别,Negcount乘以相应的权值。存在否定词则n加1;
Step12:判断n为奇数还是偶数,奇数则进行Step13,偶数则进行Step14;
Step13:第一次消极情绪值Negcount乘以-1 ,然后赋值给Negcount2,Negcount3等于 Negcount2加 Negcount3。Posa等于Posi加1,转到Step15;
Step14:偶数则Negcount直接赋值给Negcount2。 Negcount3等于Negcount2加Negcount3。Posa等于Posi加1,转到Step15;
Step15:判断是否有感叹号,没有转到Step17;
Step16:有感叹号Midcount加2;
Step17:Posi加1;
Step18:判断是否还有词,有词则转到Step2,没有则结束流程;
Step19:计算完一条文本的情绪值,防止出现负数,并处理最终的情绪值;
Step20:计算每条文本的积极值Poscount,消极值Negcount,积极情绪平均值AvgPos,消极情绪平均值AvgNeg,积极情绪方差StdPos,消极情绪方差StdNeg,用数组记录下来;
Step21:计算数组中积极情绪值减消极情绪值除80,得数作为参数值,判断参数值大小并归到五个情绪等级中。
2.3 5-LevelEA情绪分析算法实验结果
通过5-LevelEA算法对5个不同的数据文本进行分析,实验结果如表1。
3 社交网络情绪数据可视化程序设计
数据可视化技术将数据转换成图形图表,为决策提供依据[7]。数据可视化技术的研究已得到了快速发展并取得相应的成就[8]。
3.1数据可视化程序设计要点
实验数据来自爬虫抓取的2018届计算机专业75人1-4月QQ空间动态与说说,数据真实,共计有效数据218条。可视化程序的开发集成环境为Python的PyCharm,文本数据存储在MySQL数据库中,通过.csv文件导出。程序功能框架如图3所示。
数据可视化展示模块调用Python中pandas库和matplotlib库进行饼状图、柱状以及折现图的数据呈现。QQ文本情绪感分析可视化是通过Python中matplotlib库进行绘图呈现,设计中通过figure函数创建主窗口,横坐标表示发布日期,纵坐标表示情绪值,分别以5类情绪图片标注。
3.2数据可视化程序测试
对数据的可视化测试包括两类:一是对单一的情绪文本进行算法参数测试,另一类是对抓取的文本数据进行情绪算法分析后,从不同角度统计数据并进行可视化测试。
3.2.1算法参数测试
在窗口中点击算法测试按钮,进入5-LevelEA算法测试界面,本测试文本:“我的手机掉水里,现在它真不好用!我非常生气,非常郁闷!”程序输出结果如图4,左侧为各项参数值,右侧为非常忧伤的情绪图。
3.2.2统计数据可视化展示模块测试
本测试围绕对QQ空间数据分析的展示模块进行。每位同学的发布频率比对如图5。从图5中可以看出,部分同学在每个月发布动态数量持续高于其他同学,这说明他们的个性特征趋于热衷在社交网络上和身边人分享自己的生活。图6中四个月发布数量表明:一月、三月更多,四月最少。一月时值寒假,空闲时间多直接增加发布数;三月考研揭晓、春招开始情绪波动增加发布数;四月份临近毕业,工作、毕业论文等线下事情增多发布量明显减少。通过图7发现,计算机系同学毕业后选择工作的人数发布动态相较于继续读研深造的同学更为积极,占百分之八十的绝对优势,目前计算机系学生在毕业后选择就业的人数更多。男生相比于女生发布次数更多。图8-图11给出每月数据发布频率比对情况。对比近四个月数据发布频率发现,四月份发帖总体数量少于其他月份,发帖人数较其他月份增多,这与临近毕业情绪波动范围明显增加有关。
3.2.3个人情绪变化趋势数据测试
列表中选择同学姓名,弹出该同学在1-4月份个人情绪变化趋势图如图12,其中横坐标表示发布日期,纵坐标表示情绪值,分别以5類情绪图片标注。
列表中选择日期,弹出在指定日期发布动态的同学名字(横坐标)及当天情绪状态(纵坐标)如图13所示。
4 结语
通过5-LevelEA情绪分析算法对数据文本进行情绪分析,计算得到情绪分值,对应到消极——积极5类情绪等级。进一步,调用Python中第三方库进行文本情绪分析和统计数据分析的可视化,为2018毕业季的学生心理工作室提供了一定的有效的数据参考。本文对一些网络符号和其他的火星文字的情绪判断状况不能准确的处理,在今后的研究过程中,将对算法中的情绪词典进行网络在线扩展,以期待达到更精准匹配的效果。
参考文献:
[1] 吴信东,李毅,李磊.在线社交网络影响力分析[J].计算机学报,2014,37(4):735-752.
[2] 唐杰,陈文光.面向大社交数据的深度分析与挖掘[J].科学通报,2015,60(Z1):509-519.
[3] 赵妍妍,秦兵,刘挺.文本情感分析[J].软件学报,2010,21(8):1834-1848.
[4] ]徐小龙.中文文本情感分析方法研究[J].电脑知识与技术,2018,14(2):149-151.
[5] 王勇,吕学强,姬连春,等.基于极性词典的中文微博客情感分类[J].计算机应用与软件,2014,31(01):34-37+126.
[6] 罗玉萍,潘庆先,刘丽娜,等.基于情感挖掘的学生评教系统设计及其应用[J].中国电化教育,2018(4):91-95.
[7] 曾悠. 大数据时代背景下的数据可视化概念研究[D].浙江大学,2014.
[8] 任磊,杜一,马帅,张小龙,等.大数据可视分析综述[J].软件学报,2014,25(9):1909-1936.
【通联编辑:唐一东】
