基于Capped L1罚函数的组稀疏模型
2018-12-19崔立鹏于玲范平平吴宝杰翟永君
崔立鹏,于玲,范平平,吴宝杰,翟永君
(天津轻工职业技术学院电子信息与自动化学院,天津 300350)
1 研究背景
在大数据时代,人们面对各种各样的高维数据,如何从高维数据中挖掘出有用的信息是人工智能技术面临的一个重要问题。在现代机器学习、数据挖掘与生物信息学等领域,很多分类和回归问题的解释变量空间往往维数很高,甚至是超高维的。然而,高维数据会导致机器学习中的过拟合现象出现,从而使得统计模型的泛化性能变差。因此,变量空间降维与变量选择问题亟待解决。变量选择的目的在于两个方面:一是实现精确的预测和分类;二是使得模型具有更好的可解释性,降低统计模型的复杂度。所谓可解释性指的是模型的简洁度,显然,变量空间维数越低的统计模型可解释性越好。总之,人们总是期望尽可能利用较少的变量实现更高的预测准确性。如何实现统计模型的变量空间降维?很多统计学家针对变量空间降维的问题展开了研究,从而提出了一系列的稀疏模型,最著名的当属Tibishirani提出的Lasso[1]。考虑线性回归模型b,其中X∈RN×P为全部解释变量(自变量)的观测值所构成的矩阵,β∈RP称作模型向量或回归系数向量,y∈RN称作响应向量、因变量向量或输出向量,ε∈RN为噪声向量且λ1>0为样本数,a>1为变量数。由Tibshirani提出的著名的 Lasso 的形式为λ∙‖β‖1,其中 λ>0 为调节参数(Tuning Parameter),‖β‖1为L1范数罚。L1范数罚由于在零点处不可导从而可产生稀疏解,利用子梯度(Subgradient)可得单变量时其解的形式,其中为最小二乘解。显然,此时其解为软阈值算子(Soft-Threshold Operator)形式,从而将绝对值小于λ的回归系数置零,实现变量选择与统计模型的稀疏化。
Lasso在统计学中的变量选择领域具有极其重要的地位。然而,学者们通过实验与理论分析发现,Lasso也存在各种各样的缺点,很多学者针对Lasso的这些缺点进行了更深入的研究,其中之一就是Lasso对重要变量的系数也进行压缩,Zhao等人指出其只在非常强的附加条件下才具有Oracle性质[2],SCAD模型[3]、MC模型[4]和自适应Lasso[5,6]等统计模型克服了Lasso的这一缺点,与Lasso相比,它们显著减小了对重要变量的回归系数的压缩程度,因而这些模型具有所谓的Oracle性质。另外,Lasso在面对一组彼此之间存在高度相关性的解释变量时,往往只能选择出其中的一小部分,克服了这一缺点的稀疏模型为Elastic Net[7],其往往能够将一组彼此间存在高度相关性的变量中的大部分选择出来。Lasso只能实现分散的变量选择,很多情形下变量之间存在某种结构,例如在基因微阵列分析中,某基因上往往会有多个变异点,在识别究竟是哪个基因发生的变异与所发生疾病存在关联关系时将属于同一个基因的变异点分为一个组是更加合理的,因此有学者考虑将变量之间存在的结构作为先验信息再进行变量选择,Group Lasso[8-10]就是将变量的组结构作为先验信息的稀疏模型,其具有变量组选择功能。除了应用于统计学上的变量选择问题,Lasso等稀疏模型还被应用到了压缩感知、信号重构和图像重构等诸多领域,在生物统计、机器学习、数据挖掘、图像处理和信号处理等领域有着越来越广泛的应用。
基于上述思想,将Capped L1罚[11]推广到变量组选择的情况下,提出了一种新的组稀疏模型:Group Capped L1模型,其具有变量组选择能力。最后,通过人工数据集实验验证了其在变量选择和预测等方面的有效性。
2 Group Capped L1模型
2.1 Capppeedd .1罚
Capped L1罚的形式为:
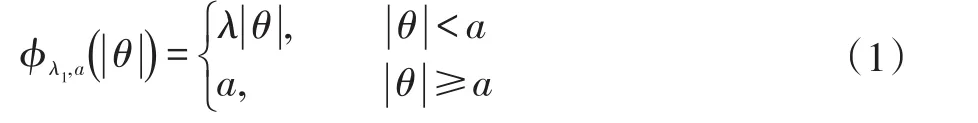
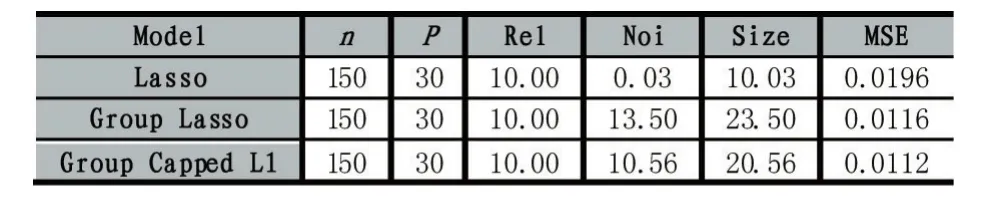
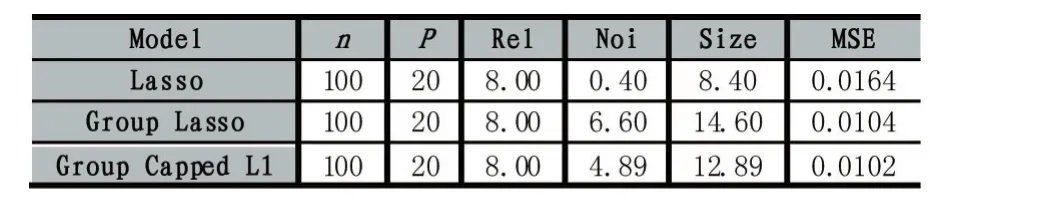
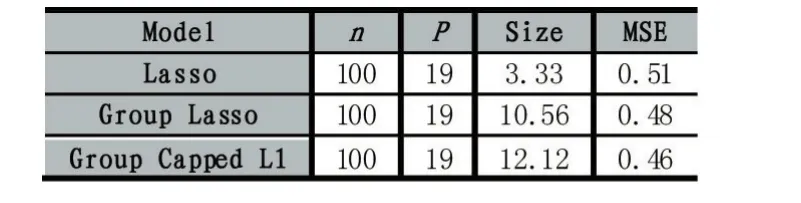
其中λ和a均为可调参数,λ>0且a>0。显然,Capped L1罚由两部分构成,||θ 图1 Capped L1罚的图像 Capped L1模型在回归系数小于等于a时表现出与Lasso一致的变量选择特性,而在回归系数大于a时不对回归系数进行压缩,其克服了Lasso对所有回归系数均进行压缩的缺点,但其仍然只能实现变量水平上的稀疏性,不能实现变量组水平上的稀疏性。下面将Capped L1罚推广到变量组选择情形,构成具有组稀疏性的Group Capped L1模型。 已知如下的线性回归模型: 其中 β为P×1维的系数向量,X为n×P阶的设计矩阵,y为n×1维的输出向量,且噪声服从高斯分布: 事先将P个变量划分为J个组,利用 βj代表第 j个变量组对应的系数向量,Xj代表第 j个变量组对应的子设计矩阵,dj表示第 j个变量组中的变量数,不妨假设任意的子设计矩阵Xj均满足正交条件XjTXj=Idj,其中dj阶的单位方阵,j∈{1 ,2,…,J} ,不妨假设xijp表示对第 j个变量组中的第p个变量的观测值,则Group Capped L1模型为: 其中 φλ1,a(∙)为Capped L1罚,λ1和a均为可调参数。 下面利用块坐标下降算法求解Group Capped L1模型。块坐标下降算法在求解稀疏模型时需要该模型关于单变量组的显式解,然后不断迭代直到满足收敛条件。块坐标下降算法是坐标下降算法的推广,坐标下降算法最初用来求解Lasso问题,其思想为在求解优化问题时每次迭代中只关于一个变量进行优化,同时固定其余所有变量的值不变,这样就将复杂的多维优化问题转化为一系列的单维优化问题,大大降低了计算的复杂度。块坐标下降算法在求解优化问题时每次迭代中只关于一个变量组进行优化,同时固定其余所有变量组的值不变,经过若干次迭代得到模型的解。由于Capped L1罚是一个分段函数,因此讨论Group Capped L1模型关于单变量组的显式解时需要分情况进行讨论。Group Capped L1模型关于第 j个变量组的解可被表示为: 在Group Capped L1模型关于单变量组的显式解的基础上,可利用块坐标下降算法求解Group Capped L1模型。求解Group Capped L1模型的块坐标下降算法为: (1)输入响应向量y、设计矩阵X、回归系数向量的初始值β。 (2)当1≤j≤J时重复执行下列步骤: ②利用公式(5)求解 βj。 ③更新 β中的第 j个子系数向量 βj。 ④令 j=j+1。 (3)得到遍历一次全部分组后的回归系数向量β,判断是否满足预先设定的收敛条件或迭代次数,若不满足则跳转到第(2)步;否则,结束算法。 (4)输出回归系数向量β。 下面利用人工生成的数据集进行实验验证Lasso、Group Lasso、Group Capped L1等稀疏模型在线性回归模型下的变量选择能力。在生成的全部人工数据集的实验中,对每个数据集中的变量都随机划分成两个样本数相同的子数据集,其中一份作为训练数据集,另一份作为测试数据集,上述划分过程重复30次,得到30个实验结果,取30次实验结果的均值作为最终的实验结果,将实验结果列入各个表中,表中n表示训练样本数,P表示变量总数,Size表示选出的变量总数,Rel表示识别出的目标变量数,Noi表示剔除的冗余变量数,MSE 表示预测均方误差(Mean Square Error),Error表示错误分类率。 生成如下两种不同类型的数据集:人工数据集1和人工数据集2,其中人工数据集1中每个变量组所含的变量数相等,而人工数据集2中各变量组所含的变量数不相等。人工数据集1和人工数据集2均基于线性回归模型y=Xβ+ε生成。 人工数据集1:该数据集包含2n=300个样本和P=30个变量,这30个变量被划分为6个变量组。人工数据集2:该数据集包含2n=200个样本和P=20个变量,这20个变量被划分为4个变量组。实验结果如表1和表2所示,从实验结果可以看出,对于人工数据集1来说,Group Capped L1模型具有明显的稀疏性,能够实现变量组选择,并且其预测均方误差最小。 表1 人工数据集1的实验结果 表2 人工数据集2的实验结果 选取来自Hosmer与Lemeshow收集的新生儿体重数据集(Birthweight Dataset)来对 Lasso、Group Lasso以及Group Capped L1这几种组稀疏模型进行实验。该数据集包含189个新生儿的体重以及可能与新生儿体重有关的8个解释变量,该8个变量分别为:母体年龄、母体体重、种族(白人或黑人)、吸烟史(吸烟或不吸烟)、早产史(早产过一次或早产过两次)、高血压史(有高血压史或无高血压史)、子宫刺激性史(有子宫刺激性史或无子宫刺激性史)、怀孕期间的物理检查次数(一次、两次或三次),其中母体年龄和母体体重为用三次多项式表示的连续变量,而其余六个解释变量均为分类变量。对于母体年龄和母体体重,其可被视为用属于同一个组的三个变量来表示。对于分类变量,其所对应的多个水平可被视为多个变量,这些变量属于分类变量这个组。因此,该数据集可被视为含有19个变量和189个样本,并且这19个变量被分为8个变量组。另外,该数据集还包含两个输出变量bwt和low,其中输出变量bwt为连续变量,表示新生儿的体重值;变量low为二值变量,表示新生儿的体重值是大于2.5kg还是小于2.5kg。当以变量bwt为输出变量时,为线性回归模型问题;当以变量low为输出变量时,为二分类问题。 将189个变量随机划分成两个分别含有100个样本和89个样本的子数据集,其中含有100个样本的子数据集作为训练数据集,另一份含有89个样本的子数据集作为测试数据集,上述划分过程重复100次,得到100个实验结果,取100次实验结果的均值作为最终的实验结果。实验结果如表3所示,表3是以bwt为输出变量的实验结果,表中n表示训练样本数,P表示变量总数,Size表示选出的变量总数,MSE表示预测均方误差。从表3中的实验结果可以看出,在回归问题下,Group Capped L1的预测均方误差最小,而且其得到的模型稀疏性也较好,与Lasso和Group Lasso相比,是一种更好的变量选择模型。 表3 新生儿体重数据集的实验结果 在机器学习和生物信息学中,有时变量之间存在一定的组结构,忽略这种组结构是不恰当的。本文将组结构作为先验信息,把Capped L1罚推广到变量组选择的情形下,基于Capped L1罚提出了一种新的组稀疏模型,其能够实现变量组选择,通过人工数据集实验和真实数据集实比较了其与Lasso、Group Lasso在变量选择方面、预测准确性和分类错误率等方面的性能,实验结果说明了提出的基于Capped L1罚的组稀疏模型在变量选择方面和预测方面的有效性。本文只是在线性回归模型下研究了其变量选择等性能,后续将其推广到逻辑斯蒂回归模型下的情况值得进一步探索。当前,稀疏模型仍然是机器学习领域的研究热点,其有意义的研究方向有如下几个方面:第一,将稀疏模型向除线性回归模型以外的其它统计模型进行拓展。当前,由于线性回归模型的简洁性,大多稀疏模型均基于线性回归模型提出,但线性回归模型的应用场景有限,将这些稀疏模型向COX比例风险回归模型、Tobit模型和Probit模型等其它统计模型推广是必要的,现在该方向仍然有大量工作需要进一步完成。第二,对稀疏模型统计性质的理论分析。很多稀疏模型通过实验验证了其变量选择的准确性,但尚缺乏变量选择一致性和参数估计一致性等理论分析方面的支撑,例如PEN SVM的变量选择一致性和参数估计一致性尚未被研究。另外,已有学者给出了Group Lasso等稀疏模型实现一致性等统计性质需要的假设条件,但这些已知条件较为复杂,如何对其进行简化值得探究。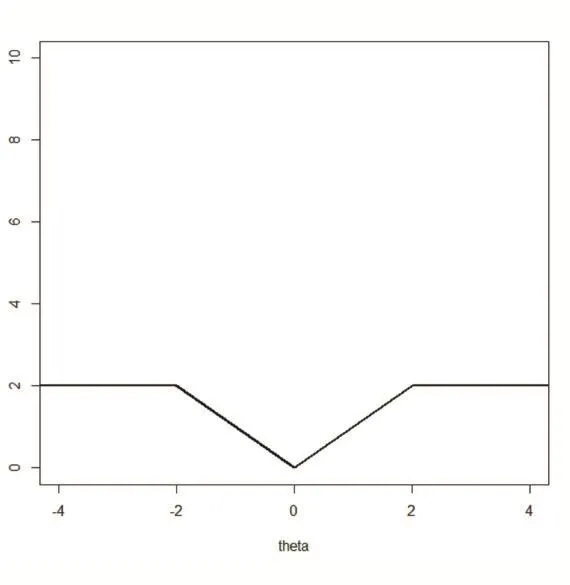
2.2 Group Cappeed L 1模型的形式


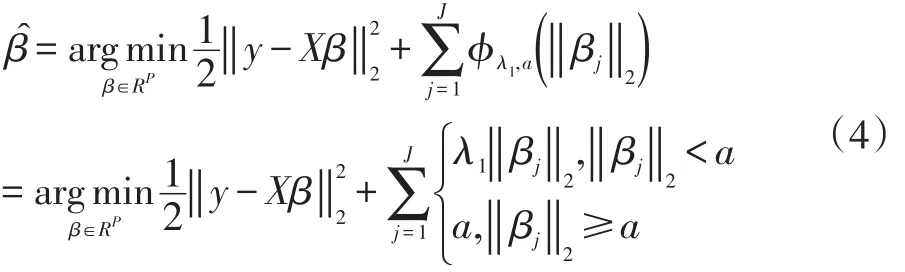
2.3 Group Cappeed L 1模型的求解算法
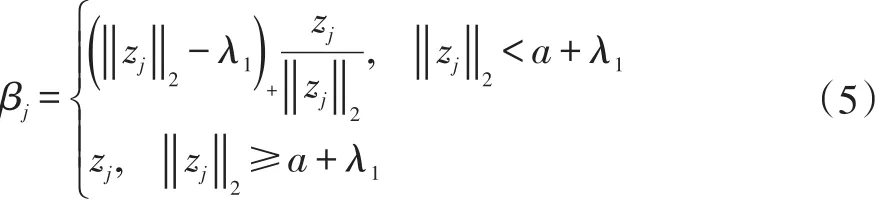
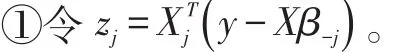
3 实验
3.1 人工数据集实验
3.2 真实数据集实验
4 结语
