基于数据挖掘的重症肌无力病征判断的可行性探索
2018-12-13姚其超熊科宇
姚其超,熊科宇,李 睿
(重庆市巴蜀中学校,重庆 400013)
1 重症肌无力基本病理与临床表现
重症肌无力是一种神经-肌肉接头传递障碍的自身免疫性疾病。病理为受累骨骼肌纤维间小静脉周围有淋巴细胞浸润。急性期患者与晚期患者分别有特殊病变。75%至85%的重症肌无力患者同时伴随胸腺异常,60%至70%为胸腺增生,10%为胸腺瘤。
同时重症肌无力的发病与临床类型与年龄与性别呈统计相关。女性患病率略高于男性,且胸腺异常的具体发展概率分布也有区别。在临床上,重症肌无力也因为患病者年龄分为:成人重症肌无力、儿童重症肌无力与新生儿重症肌无力。不同年龄患者在症状和病情发展上也有明显不同。[1]基于重症肌无力的基本病理可知,重症肌无力的具体受累肌肉部分与病情发展有着本质性的联系,胸腺异常和患者性别与重症肌无力存在一定的联系,且重症肌无力的发病年龄与病情发展有着直接或间接的联系。
重症肌无力危象,是指由于疾病的发展,药物应用不当、感染、分娩、手术等诸多因素所致的呼吸肌无力而不能维持正常通气功能的危急状态。[1]也就是说,重症肌无力的危象,严重关系者患者的生命体征。而重症肌无力发展到危象的时间,严重影响着患者的康复、存活过程。且重症肌无力治疗,仍然受患者病情发展因素的制约。
同时,重症肌无力作为一种罕见病,在地方缺乏专业有效的诊断,且重症肌无力的病情发展多由经验与统计得出。关于重症肌无力的治疗方法的统计学意义与重症肌无力危象预测模型的构建上,吉林大学的田升军医生和广州中医药大学的刘琴医生做了极有意义的研究和创新探索,他们证明了重症肌无力的若干因素与肌无力危象的发生具有统计学关系。[2][3]但是重症肌无力虽然是目前病理理解最为清楚的自身免疫病之一,仍然缺乏实用的病情预测机制和更好的治疗策略。此时,在关联患者病情症状与病情发展之间,作为新兴技术的大数据分析,便是一个重要的解决思路。
2 基于统计数据的假设
目前,在中央政府的大力倡导下,中国开始发展多个医疗大数据数据库,其中本文使用国家人口与健康科学数据共享服务平台的重症肌无力诊疗数据库。[4]截止本文写作,数据库更新数据96条,大多有效。导出数据进行分析制表,可发现发病自危象时间与发病年龄的点状图分布呈三角形分布,即中间高,左右低。因至危象受各种随机因素的影响,故使用假说演绎法,大胆预测至危象时间与发病年龄呈正态分布的加权关系,并以此建模,验证此假说是否具有合理性。同时,提取数据库有效数据,病症大多为是或否,其余病症出现太过分散,无法验证其统计学意义。本探索作为重症肌无力危象时间预测的可行性研究,将病症的出现与至危象时间假设为简单线形关系进行研究。

3 重症肌无力发展至危象时间的简单模型
首先,模型架构如下:
其中设定患者有关变量为性别、发病年龄(age)、是否受累眼肌、是否受累颈肌、是否受累肢肌、是否受累呼吸肌。各变量各设置权重值pi(i=1,2,3…),又以发病年龄的正态分布的期望值为l,为方便计算使用发病年龄的加权期望值的减半周期为r来近似计算l。
设权重计算函数:f(r,l)
该函数自动就加权数计算结果

(该病人pi为出现病症的对应权重)对比真实至危象时长,对于权重值进行修正。自优化函数自动调整(r,l)参数重复触发权重计算函数,并分别记录下允许一年误差的正确率、允许半年误差的正确率、允许两月误差的正确率与其权重与参数变化情况。最末为精度最高时的参数。将其代入
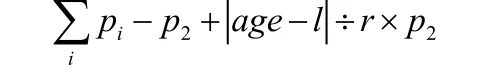
(该病人pi为出现病症的对应权重),即为重症肌无力的简单预测模型。

4 重症肌无力的数据结果及分析
最终经过约75000组有效的训练与优化,选出测试组综合正确率最高的一组模型,最终得到的重症肌无力据最终病情症状进行发病至危象的时间预测计算模型如下:
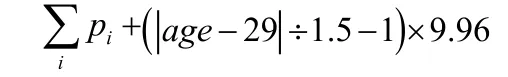
(p1=0.931,p2=9.96,p3=0.469,p4=-6.317,p5=8.801,p6=2.616)(该病人pi为出现病症的对应权重)
同时本模型训练组和测试组相互独立互不重合。进行交叉检验很能说明所构建模型的普适性。由测试组得出的正确率相较训练组的正确率虽然有一定的下滑,但是测试组六月正确率仍然为50.0%。说明大数据数据挖掘在肌无力危象预测中具有研究价值和实用意义。初步探索了数据挖掘在重症肌无力甚至是罕见病诊断治疗中的巨大实用价值。

同时,对具体数据进行分析,我们发现重症肌无力至危象时间多为0至48月之间。模型所有正确数据均取于此中。也就是说,如果将排除超过48月的为异常样本,本模型的正确率将提高更多,这样的排除在如安排手术治疗等实践中仍然有应用价值。
5 基于简单模型的重症肌无力病症诊断的局限与展望
5.1 正确预测对象集中
经过统计,我们发现无论是在测试组还是训练组,误差六月内正确样本与误差二月内正确样本大多集中于18个月内出现重症肌无力危象的样本。训练组中24月内危象样本的一年正确率为100%,六月正确率为75.6%。且在测试组中24月内危象样本的预测六月正确率也高于平均水平,为66.7%。同时,样本病情至危象时间一旦超过24月,预测正确率就急剧降低。
根据危象时间超过24月的样本修正参数与权重之后,在超过24月危象样本的预测正确率将提高,超过100月发生危象的样本虽然少有一年正确者,但预测值误差相比其发生危象时间减少很多。但是值得注意的是这样的修正明显降低了24月内危象样本的正确率。
5.2 研究的数据对象太少
以上的实际问题有一个重要的解决思路:引入新变量。
本文使用患者数据因为数据处理与数据库局限原因,种类较少,样本数量较少。如果借助引入新变量,如:胸腺异常情况、激素水平等,有希望能统一各种时长危象样本的预测模型。
5.3 模型有待引入更高级的神经网络等算法
本模型以各变量间存在线形关系或正态分布作为假设,目的是为此领域提供可行性探索。在实际使用方面,应当使用更加精密的算法以进一步增强模型的普适性和准确性。
5.4 罕见病数据库运营的相关建议
值得注意的是,目前公开可靠的临床数据较少,不利于进行大数据研究。本次使用的数据虽然得到了数据主管单位,北京协和医院数据中心的大力支持,但是数据中仍有不少缺失数据与无效数据。要尽快发展大数据医疗,就应当注意数据的收集与保存。对于罕见病的病情应当分阶段,分别进行具体的统计,才能使中国尽快拥有大量珍贵的罕见病数据进行科学研究。
5.5 注意对于建模结果进行逆向的科学分析
建模得到的相关数据和算法在大量样本验证的情况下会存在其内部的科学联系,并且这样的具体联系在模型中会有提示。如该症状加重或是减轻了病情或其他症状。重症肌无力乃至罕见病作为科研难关的攻克,不仅需要大数据支撑,焚膏继晷的科研攻关,同时也需要一些诸如数据挖掘模型带来的提示。利用这样的提示进行科学的假设,将会较之漫无目的的统计与猜测更加接近真理。
5.6 模型构建应注意病理内在联系
本文在选取研究对象时着重注意了研究数据在病理学上是否有明显的相关性,并在此基础上进行了大胆的数学假设。这应当为后来研究者所注意:大数据在研究相关数据时往往更能发现其中规律,也能使大数据结论除了统计学依据以外增加更多的可解释、可研究的科学的内在联系。
5.7 跨学科医疗合作需要更多制度性保障
大数据医疗,往往需要跨学科的医疗合作。往往医疗、生物科研从业者无法拥有专业大数据从业人员的数学、大数据技术水平。同样,大数据工程师也往往无法在生物科研与医疗领域做到精通。要充分发挥社会科研资源,使大数据医疗科研项目能够保证准确性的同时又保证专业性,就需要更多制度性的保障来促进科研信息的充分交流,充分利用。
