数据卸载和微服务实现BSS信控轨迹管理系统
2018-12-13李峰
李 峰
(中国联合网络通信有限公司济南软件研究院,济南 250100)
1 引言
电信BSS系统中,信用控制作为高客户感知模块,面临大量客服问题的定位、解释。客服问题的定位、解释,需要大量数据做支撑,尤其是信控关键要素的变化轨迹数据(如余额、欠费、信用度、流量等要素的变化轨迹),以及信控动作发生时刻的快照信息(如停开机时的余额及欠费情况、是否有逾期欠费等)。在4G时代,用户每天会产生大量的电信消费行为(以流量为主),导致信控要素变化频繁,而核心系统的数据库存储空间有限,无法容纳每天将近百亿级的轨迹数据。为解决轨迹数据记录需求和核心数据库存储能力不足的矛盾,为信控问题定位、客服解释留存高价值数据,本文给出了可行且经过实践验证的技术方案:通过数据卸载(涉及技术包括:数据复制如Oracle GoldenGate,简称OGG;消息中间件如Kafka;海量数据平台如HBase),借助海量数据平台存放关键要素及快照数据,借助微服务提供数据访问接入能力,构建完整的信控轨迹管理系统。
2 技术概述
数据复制,是将核心数据库的数据通过日志抽取方式,复原数据操作步骤,实现数据拷贝。电信行业常用的数据复制技术包括Oracle的OGG、DRDS(阿里云基于MySQL的分布式数据库)的DTS等。其中OGG的应用最为广泛,本文提及的技术方案基于OGG技术。OGG是一种基于日志的结构化数据复制软件,通过捕获源数据库online redo log(在线重做日志)或archive log(归档日志)获得数据变化,形成tail(队列文件),再将这些tail通过网络协议,传输到目标数据库,目标端通过解析,插入至目标端数据库,从而实现源端与目标端数据同步。
消息中间件也是电信行业常用技术解决方案,当前常用的中间件包括Kafka、MQ。本文技术方案采用Kafka。Kafka是一种高吞吐量的分布式发布订阅消息系统,由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。
微服务最早由Martin Fowler与James Lewis于2014年共同提出,微服务架构风格是一种使用一套小服务来开发单个应用的方式途径,每个服务运行在自己的进程中,并使用轻量级机制通信,通常是HTTP API,这些服务基于业务能力构建,并能够通过自动化部署机制来独立部署,这些服务使用不同的编程语言实现,以及不同数据存储技术,并保持最低限度的集中式管理。本文技术方案,微服务实现基于spring cloud实现,通过marathon_lb实现服务发现和负载均衡、采用kong作为API网关,redis作为缓存服务器。
3 技术原理及应用
第一步,核心系统收集关键数据到Oracle。规划需要记录的要素以及动作快照数据。针对每类数据设计对应的数据表。修改业务逻辑,收集关键数据,写入Oracle对应表中。需要收集的数据分为两类,一类是关键要素数据(余额、欠费、信用度、流量),这些数据是业务判断的核心维度,这些数据的特点是随着业务触发会不断更新,且一个用户一条数据。第二类是动作快照类数据,当信控动作(如停开机、封顶限速、短信提醒等)发生时,记录此类数据,作为信控动作解释依据,每发生一次信控动作,记录一条数据。快照数据在oracle记录的特点是日志类特性,只新增不修改,历史数据按月清理,对于一个用户,随着对其信控动作的不断增多,记录的快照类数据也会不断增加。
第二步,配置核心数据表的OGG同步,解析OGG数据到Kafka。针对要素表和快照表,配置OGG同步规则。增加数据抽取进程(extract),处理trail文件并按约定格式将消息写入目标Kafka。根据要卸载的数据量的多少,可以一个表对应一个topic,也可以是多表共用一个topic,为保证数据被消费后,仍然可以还原Oracle中的数据操作,建议一个topic只有一个分区,后端只有一个消费进程或线程消费。
第三步,增加Kafka消费进程,卸载数据到HBase。增加Kafka消费进程,每个进程并行启动多个消费线程,每个线程对应一个表的topic。识别Kafka消息的操作标识(insert、update、delete),并对选择对HBase的响应操作。
需要注意的点:
(1)两类表的消息类型和HBase操作对应关系不同。要素类表,需记录每次要素变化,所以update消息对应到HBase表的insert操作。快照类表,是原表数据的拷贝复制,消息类型即是需要对HBase做的操作类型。
(2)需要同时维护HBase数据表和索引表,支持非主键查询。HBase数据的快速查询,只支持基于rowkey的单条查询或者根据rowkey范围做scan查询。且一个表只能有一个rowkey。如果想多维度查询HBase表,只能借助于异构索引。异构索引表,是将索引字段作为rowkey,比如用户标识user_id,而将该用户标识对应的索引原表记录的rowkey作为索引记录的不同列(HBase理论上支持百万级的列,是列式存储,不同记录的列可以不同)。在Kafka消费进程操作HBase时,需要同时维护HBase数据表和索引记录表。
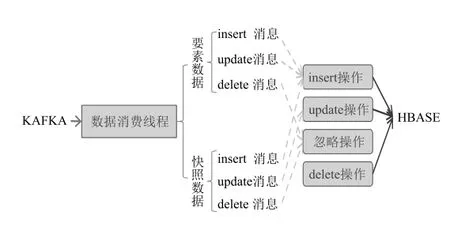
图2 消息类型与HBase操作对应
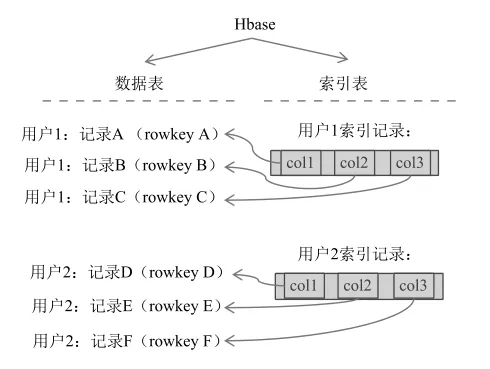
图3 消息类型与HBase操作对应
第四步,借助微服务,实现数据能力开放。按照微服务的定义,微服务接口遵循http的restful,json格式报文。服务应用基于spring cloud开发,但在整体架构上,并未完全采用spring cloud的组件。考虑到项目基于DCOS,所有应用容器化,在Docker容器中运行,而容器化配套技术方案中的marathon_lb本身具备服务注册、服务发现、负载均衡的功能,故采用marathon_lb服务替换spring cloud的eureka。另外鉴于kong是基于ngix实现,使用kong作为api网关,替换了spring cloud中的zuul。每一个微服务,支持两种查询方式,即基于rowkey的直接查询(单条或scan),以及基于异构索引的查询。针对不同表数据量、数据特性、使用方式的不同,可以选择不同的查询方式。
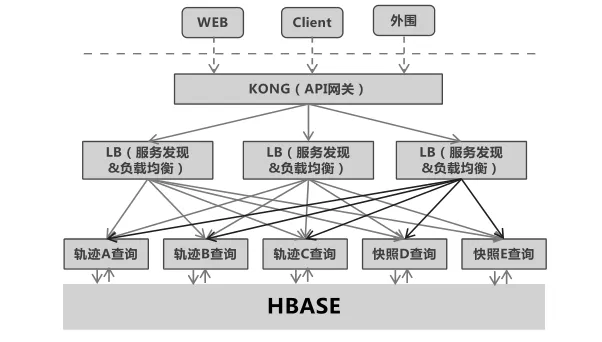
图4 微服务技术架构
4 结束语
以上技术方案的部分技术选型,受限于所处BSS系统的整体技术架构。单就要素轨迹管理系统的实现而言,还有其他可选技术方案。通过要素轨迹的记录及管理,将信用控制的核心要素数据变化及快照数据变化完整的记录下来,通过微服务实现数据开放,不论对研发、运维定位问题,还是外围自定义查询,都更为方便、直接。也极大提升了客服人员的问题解释、数据查找的工作效率。
