基于长短期记忆神经网络的可用停车位预测
2018-11-29李慧云
孙 敏 彭 磊 李慧云
1(中国科学院深圳先进技术研究院 深圳 518055)
2(南昌航空大学 南昌 330063)
1 引 言
近年来,随着经济的快速发展,市民使用小汽车的数量也快速上升,这使得大城市停车难的问题越来越严重,同时也加剧了城市交通的拥堵。研究报告显示,拥挤交通中有 30% 是由寻找停车位的汽车造成[1]。而在寻找车位的同时,也增加了不必要的尾气排放。因此,当前全国各地都在积极开展城市级停车诱导系统的建设工作。
停车诱导系统通过给车辆提供停车场位置和可用车位数量等相关信息,帮助车辆快速停车,缓解停车难问题[2-4]。在停车诱导系统中,可用车位预测是非常重要的一部分,车辆需要在距离目的地一定距离时知道:当他到达目的地时,周边停车场可用的车位数量。可用车位预测技术可以避免出现车辆到达停车场入口时才发现满位而无法停放的情况,同时起到引导车辆停往车位更宽松的停车场的作用。显然,可用车位预测是一个典型的时间序列预测问题。当前可以采用自回归积分移动平均模型(Autoregressive Integrated Moving Average Model,ARIMA)、小波神经网络等实现精准的短时预测。但需要指出的是,该类方法的高精度是建立在一个基本条件上,即预测步数量足够少,一般是 1~3 个预测步长。如果预测步数量增加,那么预测精度将出现大幅下降。
由于城市交通环境的复杂性,往往在车辆启动时就需要了解目的地周边当前停车场的可用车位情况,并预测当车辆到达时的可用车位情况。这个时间长度一般会超过 30 min。如果直接使用当前的预测技术,一般是将预测步的时间周期调整变长,如 10 min 为一个预测步。这样虽然可将30 min 调整成 3 个预测步,但由于每 10 min 给出一个预测值,实际上 30 min 仅能给出 3 个预测值。显然,这个结果严重丢失了该时间区间内更为详细的车位变化特征,对停车诱导系统的诱导精度带来很大的负面影响。
目前对可用停车位的实时预测,常见的方法主要分为两类:一类是以 ARIMA 为代表的传统时间预测模型[5],另一类是神经网络预测方法[6,7]。其中,传统时间序列预测模型主要通过将时间序列数据分解,对于不平稳序列则还需要通过差分等手段将非平稳时间序列转换为平稳时间序列,从而实现预测[8,9]。这种预测容易受模型参数的影响,有效性会逐渐降低。神经网络方法主要通过先对海量数据进行迭代训练,再拟合数据特征,进而实现预测。相关研究中,Sun 等[10]和 Yong等[11]研究通过误差逆向传播算法训练的多层前馈神经网络模型来预测车位占有率,虽然实现了停车位预测,但鲁棒性差,而且计算时需消耗大量的时间;后来有研究人员[12-14]利用小波神经网络能很好地拟合非线性复杂系统特性,虽对可用停车位进行短期预测,预测速度和稳定性也都得到了很大的提高,但也只是单点预测;Zheng 等[15]通过使用回归树、神经网络和支持向量机建立组合模型,实现停车位连续变化状态的预测,但随着实时数据的增加,动态组合模型切换运算所付出的时间成本也很昂贵。
以上所提到的方法均不能很好地解决可用停车位波动区间预测的问题。其中,大部分方法侧重于点的预测,虽有少部分方法考虑区间范围内的变化与趋势,但计算时间成本也很高。
针对这一问题,本文提出了一种预测方法——模糊长短期记忆神经网络(Fuzzy Long Short-Term Memory Network Prediction On Parking Spaces,FLOPS),可以在较长预测时间周期内保持数据变化特征,并适用于较大时间跨度(>30 min)条件下的高精度预测。该方法由 3 个主要步骤构成:(1)基于模糊信息粒化(Fuzzy Information Granulation,FIG)方法对停车场历史数据进行海量关键信息提取[16],构造预设预测周期的特征集;(2)构造特征集的长短期记忆神经网络(Long Short-Term Memory Network,LSTM),并对未来 1~3 个预测步进行特征集预测;(3)基于 3 次样条插值对得到的特征集预测结果进行插值重构,由此得到预测时间周期内的停车位连续变化结果。
2 研究方法
对可用停车位的连续变化状态预测,包括可用停车位数目变化预测和停车高峰的时间预测。本文主要分为 3 个部分:(1)基于模糊信息粒化的数据变换,获取时间序列数据对应的特征数据集;(2)基于 LSTM 神经网络的区间预测模型,预测可用停车位数目的变化特征;(3)基于 3 次样条插值的重构算法,获得可用泊位的连续变化状态。
2.1 基于模糊信息粒化的数据变换
可用泊位是一个随时间变化而不断变化的数据。面对一个如此巨大的非线性时间序列数据,本文通过做压缩将关键信息提取出来,获得对应的特征数据集合。在本文中,使用基于模糊信息粒化(FIG)方法对可用停车位的时间序列重构及粒化。其中,模糊信息粒化是对海量数据进行关键信息提取的有效方法。对时间序列进行模糊信息粒化主要分为 2 个过程:
(1)将时间序列分割成若干个小子序列,作为操作窗口;
(2)对产生的每一个窗口进行模糊化,生成一个个模糊集,即模糊信息粒。
处理后的数据样本能够保持原样本数据特征,得到一系列更小的样本区间,便于后续进行数据的计算。
停车场的时间序列数据X,如公式(1)所示。
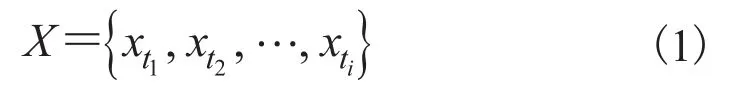
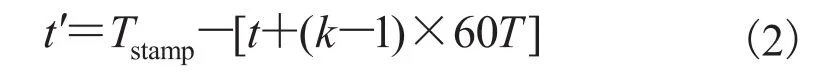
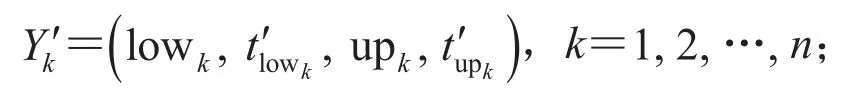

2.2 基于长短期记忆神经网络的预测模型
数据变换得到具有模糊信息的特征矩阵,用于预测可用停车位数目变化特征,本文考虑有记忆模式的预测模型,这能将之前时刻的数据关联起来具有更好的效果。
长短期记忆神经网络(LSTM)是一种特殊的循环神经网络,是做时间序列分析的常用方法。它能够克服传统循环神经网络在反向传播中遇到的梯度爆炸和衰减的缺点,并通过在隐藏层加入记忆单元,将时间序列的短长期相互关联起来,控制有关信息的删除与存储,以此构成记忆网络。本文的记忆单元结构如图 1 所示,主要由输入门、输出门、遗忘门和存储单元组成。其中,门是一种让信息选择式通过的方法,其含有sigmoid 函数,以决定存储单元状态中哪些部分需要输出,并经过 tanh 函数得到想要输出的数据。
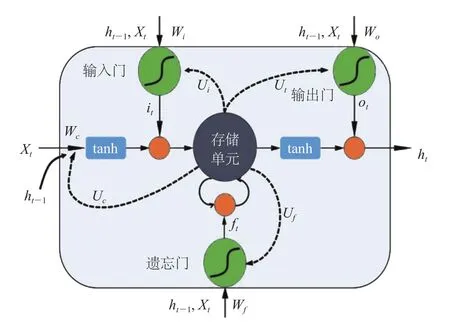
图1 长短期记忆神经网络记忆单元Fig. 1 Structure of memory unit of long short-term memory network
在本文中,LSTM 预测模型包含多个 LSTM记忆单元。其中,选择“Min-Max Normalization”进行数据归一化处理;选择“adam”作为优化器;选择“mean squared error” 作为损失函数。特征矩阵X和为模型输入,其中可用泊位数量变化的预测由矩阵X来实现,而峰值时间的预测由矩阵来实现。利用 LSTM 隐藏层迭代计算得到,未来第k+1 个粒化窗口的可用泊位数量变化Pk+1=(startk+1, lowk+1, upk+1, endk+1)和对应的峰值时刻算法流程如下:

?
2.3 样条插值重构
LSTM 神经网络模型预测得到 startk+1、lowk+1、upk+1、endk+1和(其中 startk+1和endk+1是第k+1 个粒化窗口内的起始点和终止点对应的可用停车位数量,对应的=60T)预测特征数据之后,便得到可用停车位数目的变化特征。这些特征数据在数值分布上是离散的,插值就是通过这些离散的数据,去确定某一类已知函数的参数或寻找某个近似函数,使得到的近似函数与已知数据有较高的拟合程度,最后求取“断链”处的模拟值,实现曲线重构。
因此,为将这些特征数据重构得到预测区间内可用停车位数目的连续变化状态,本文采用 3次样条插值进行相应数据处理。这是因为,与更高次样条相比,它只需较少的计算和存储,且较稳定,在灵活性和计算速度之间进行了合理的折中。插值重构过程具体如下:
(1)对第k+1 个粒子窗口内的时间进行升序排列、划分区间,并确定对应时刻的可用停车位数值。


其中,



3 可用停车位预测实验及结果分析
3.1 数据变换
本文选择广东省深圳市罗湖区宝琳珠宝中心地上停车场的停车数据作为实验数据,统计时间为 2016年7月3日至7月5日,原始可用停车位数据如图 2 所示。其中,数据的采样频率为每分钟记录一次未占用停车位的数据,因此每天会有 1 440 个数据点。

图2 2016.07.03—2016.07.05 停车曲线Fig. 2 Sample parking curve from 3 to 5 July 2016
根据 FIG 理论,本文将时间粒度T设定为30 min,即选择每 30 个点作为一个粒化窗口,则每天对应 48 个粒化窗口。在每个粒化窗口内建立模糊集,模糊粒化后的结果如图 3 所示。其中,图中每条柱体都是由特征数据 start、low、up 和 end 四个值构成;空心柱体表示在这个时间段内,可用停车位数量是增加的;实心柱体则表示在这个时间段内可用停车位减少。在每一个粒化窗口中,可用泊位数都是在最大值 up 和最小值 low 之间波动,同时数据量也由每天的 1 440个降低到 192(48×4)个。由此,便获得可用停车位的模糊特征数据,用于预测可用停车位数目变化特征。
3.2 基于长短期记忆神经网络的预测结果
预测可用停车位数目变化特征数据是建立在LSTM 神经网络的模型基础上。神经网络有很多参数需要设置,如何调整模型的超参数以及如何设置模型的结构以聚合最佳参数是非常重要的。本文分两次实现对未来停车位的数目变化预测和峰值时间预测。其中,用于停车位数目变化预测的网络,输入层和输出层的神经元个数都为 4,隐藏层LSTM 的神经元个数为 10。而用于峰值时间预测的网络,输出层神经元个数为 2,其他层不变。首先,利用 2016.07.03—2016.07.05 的停车特征数据训练 LSTM 神经网络,也就是经过 FIG 变化后的X、矩阵,网络训练次数为 100 次,当超过训练次数则终止训练;然后,将训练好的网络模型保存,并利用该模型对可用停车位变化特征数据预测。
本文使用 2016.07.06 的数据进行测试,把前3 个时刻的特征数据,即可用停车位数目变化以及峰值时间数据作为输入,迭代预测下一个时刻的特征数据,实验结果如图 4 所示。图 4 中,曲线反映了实际停车位数目变化与预测值的对比情况,start、up、low、end 整体预测的平均绝对误差为 2.26。
3.3 实验结果对比分析
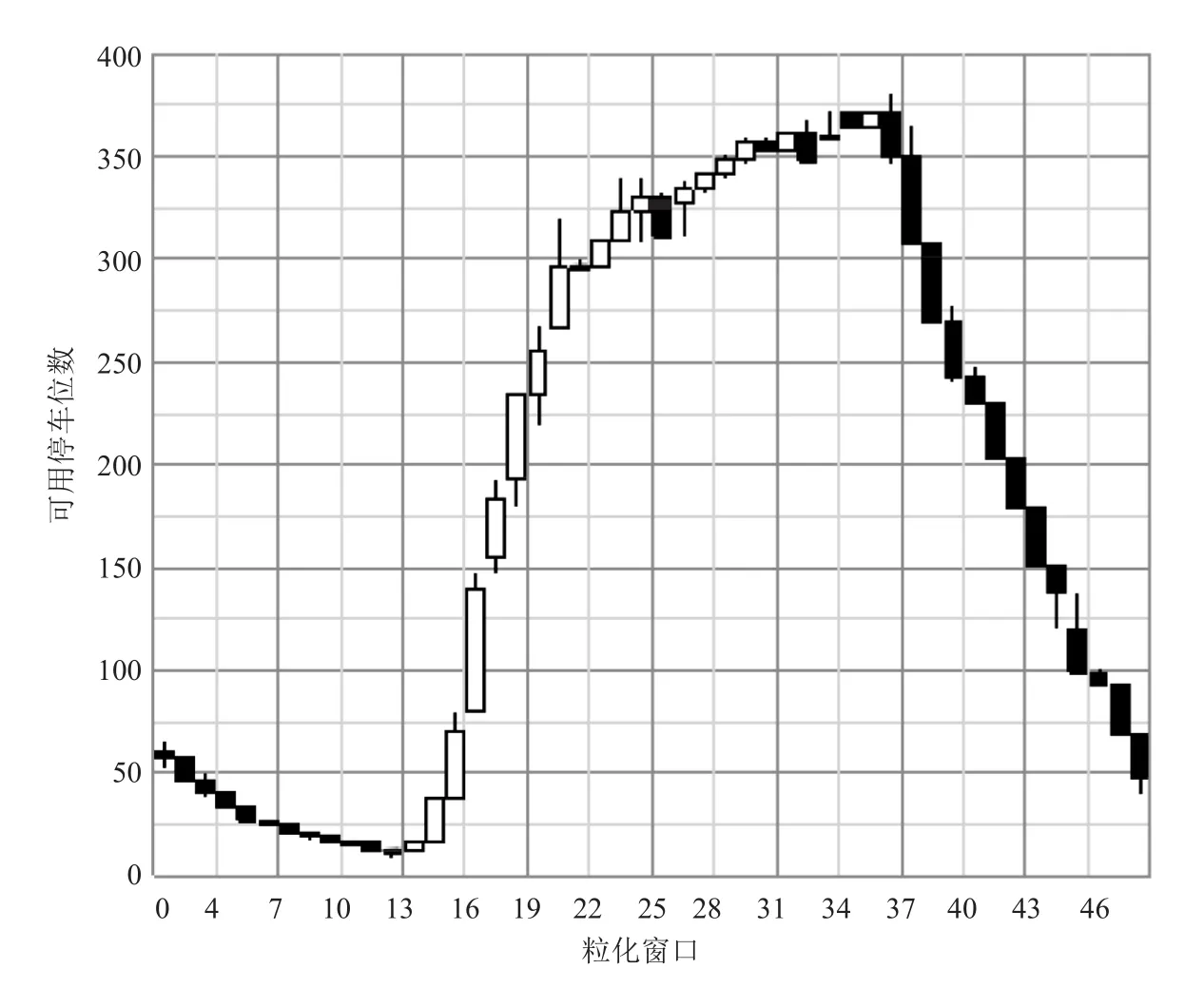
图3 2016 年7月6号模糊粒化结果图Fig. 3 Fuzzy information granulation result picture in July 6th 2016
预测得到下一时刻可用停车位的特征数据,这只是其中 4 个点对应的可用停车位和出现的时间。为了让用户清楚地知道未来 10 min 内目标停车场可用停车位的连续变化,本文用 3 次样条插值算法,重构出可用停车位的连续变化状态曲线。如图 5 所示,每 10 min 是一个预测区间,在 17:00—17:30 共有三个区间,每个区间插值得到预测时间段内可用停车位的连续变化状态。

图4 特征数据集的预测结果Fig. 4 Prediction result on feature data
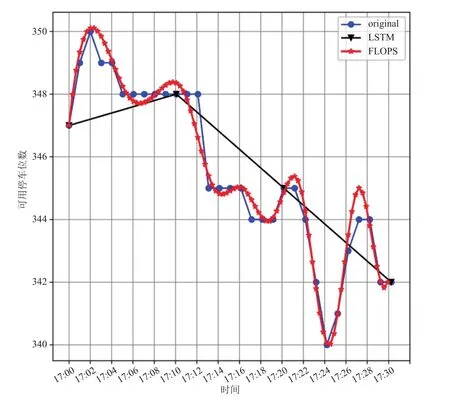
图5 特征数据集重构Fig. 5 Feature data reconstruction
图5 中曲线“original”为真实的可用停车位情况。从图 5 对比可以看到,当时间步长都为10 min 时,使用 LSTM 神经网络预测只能得到一个点,且区间的变化趋势只能把各点直接相连;而本文提出的区间变化趋势预测模型 FLOPS,不仅能知道区间内每个点的可用停车位信息情况,而且精确度比 LSTM 好,同时还能知道区间内何时出现停车高峰,能够让用户掌握更多的停车信息。接下来,对二者进行均方根误差对比,结果如图 6 所示。结合特征数据重构对比图(图 5)和误差分析图(图 6)不难发现,FLOPS 和 LSTM 对区间端点的预测都比较准确,但在时间步长相同时,LSTM 网络对区间内的值的预测效果明显不足,均方根误差波动很大,单独使用 LSTM 网络的平均均方根误差(RMSE)为 6.57,而 FLOPS 的平均均方根误差为 2.86。
同样地,LSTM 网络要实现区间趋势的预测,需要付出更多预测步的代价,预测结果如图7 所示。从图 7 可以看到,在预测周期为 10 min时,FLOPS 方法与 LSTM 的预测准确度近似,但 FLOPS 只需 1 步就可以预测区间趋势,计算消耗 0.054 s;而 LSTM 需要 10 步才能完成区间预测,且需要 1 min 才给出一个预测值,计算消耗 0.56 s,具体的计算代价如图 8 所示。因此,在预测准确度相近的情况下,本文所提出的FLOPS 具有更好的计算性能优势。
4 与国内外相似研究的对比分析
现阶段对停车场泊位预测的研究,主要集中在传统的时间序列预测方法和神经网络模型。在 Yu 等[9]研究中,ARIMA 模型对可用停车位的预测,均方根误差为 4.47,本文提出的方法FLOPS 均方根误差为 2.86;Sharma 等[13]用小波神经网络做可用停车位的预测,系统均方根误差为 3.08;且小波神经网络模型完成一天的预测计算消耗 13.3 s,而本方法 FLOPS 计算消耗时间为 8.9 s。因此,本文提出的将 LSTM 网络应用于可用泊车位的预测方法,不仅提高了预测的精度,还提高了计算速度,具有较大的实际应用价值。本文的不足之处是,未根据不同用车时间对停车数据进行更细的划分,如工作日和非工作日时市民用车情况大不同,可针对二者细分预测模型,这样应该可以进一步提高模型的预测准确度。
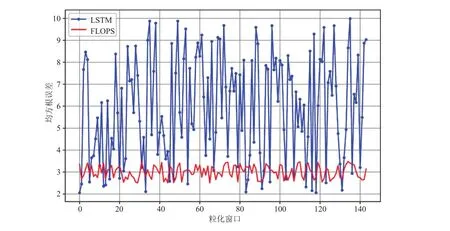
图6 LSTM 和 FLOPS 误差结果对比Fig. 6 RMSE comparison of LSTM and FLOPS

图7 重构结果对比Fig. 7 Comparison of reconstructed results

图8 计算时间代价Fig. 8 Computer overhead comparison
5 总 结
本文提出了一种可以在较长预测时间周期内保持数据变化特征的预测方法,适用于较大时间跨度(>30 min)条件下的高精度预测。该方法使用模糊信息粒化的思想获取特征数据集,通过 LSTM 网络对特征数据集进行预测,而后再结合 3 次样条插值将特征数据集重构整个预测区间停车位的连续变化状态。从仿真结果可以看出,该方法在相同预测时间步的可用车位预测上,比传统预测方法具有更高的精度;在保持相近预测精度的条件下,比传统预测方法具有更高的计算效率。在未来的工作中,我们会考虑更多维度因素,如天气、大型活动等突变因素对停车带来的影响,以进一步提高预测准确度。
