基于Faster R-CNN及数据增广的满文文档印章检测
2018-11-21卢海涛周建云郑蕊蕊贺建军
卢海涛,吴 磊,周建云,郑蕊蕊,贺建军
(大连民族大学 信息与通信工程学院 ,辽宁 大连116605)
满文档案是满族社会历史最真实、可靠的原始记录。它真实反映了清入关前和清代的社会状况,这其中蕴藏着丰富的历史文化资源、知识信息资源和满文宗教资源,是祖先留下的优秀民族文化遗产[1]。大部分满文档案都是单份、孤本或稀本,如果长时间、高频率的使用必然会对档案原件造成一定损害,为了使珍贵的满文档案能够永久保存下去,对满文古籍档案的电子化是一种趋势[2],即满文档案会以图像的方式保存下来,因此对满文档案图像的研究与利用迫在眉睫。
研究满文档案最重要的一部分是对文档中的印章进行研究,印章可以反映文档的作者或者归属等重要信息,满文古籍中的印章也是鉴定该档案的价值以及分析研究满文档案中内容的重要依据。因此,从满文文档图像中自动检测并识别印章相关信息,对于满文文档的研究分析与利用很有必要性。
国内学者们对印章的研究主要集中在商业印章的防伪研究以及古画的印章定位识别研究等。在文献[3]中,牟加俊等提出了一种中国古画印章自动定位算法,该方法利用传统的特征方法对印章进行定位。该方法的局限性是仅着重对红色印章检测较为有效。唐嘉等在文献[4]中提出两层定位模型,先利用人工构建印章浅层特征进行粗定位,再通过卷积神经网络进行检测。在第一步利用颜色等人工构建特征,并不适用于复印版古籍文档中,此方法人工构建特征较繁琐且将整个过程分俩步独立进行,效率不高。
分析国内学者们对印章检测相关文献,总结出已有方法存在以下两个问题:一是没有专门针对古籍文档(特别是满文档案)的印章区域自动检测的研究,古籍文档中通篇有大量文字出现,且印章中也会出现文字,这样就大大增加了印章的准确检测难度;二是大多使用传统的人工构建特征方法,传统方法效率不高,由于没有挖掘印章的深层特征且对印章情况复杂现象处理不佳,没有利用高性能的深度学习算法对印章检测。
深度学习算法不仅可以自动提取出简单的低层特征还可以提取一些人工无法构建的更深层次的特征,因此深度学习算法有好的准确率和高效性。满文文档的印章检测的本质是目标检测,而Faster R-CNN算法是一种现阶段最成熟、应用最广泛的目标检测与识别的深度学框架[5]。深度学习算法的一个缺点是需要大量的数据才可达到可观的结果,但由于满文档案数据采集存在现实的困难,因此研究对满文印章数据可以自动扩充的方法很重要。
本文利用Faster R-CNN深度学习框架建立了满文文档的印章检测模型,并为解决满文印章数据少的问题而提出了一种满文印章数据集自动扩充的方法,通过对印章进行旋转、像素增强减弱等九种变换模拟真实文档印章存在的现象,再通过将模拟的印章融合到原始满文文档中的方法扩充带印章的满文文档数据。目的是提高Faster R-CNN对满文文档印章的检测性能,并且为后续的满文印章识别以及满文文档内容的研究做好准备。
1 Faster R-CNN算法描述
Girshick R等人在深度学习的热潮下提出了一种基于深度学习模型的目标检测与识别方法R-CNN[6],将整个目标检测的任务分为候选区域提取与分类两步,检测性能较传统目标检测方法显著提升。随后又在R-CNN的基础上提出Fast-RCNN[7],该算法中提出了RoIs策略,将候选区域映射到CNN特征图上,将特征提取、分类和边界回归都整理成一个部分,提高了效率。

Xpart1=ConvNet(part1)(x,θpart1)∈Ru×v@r
,
(1)
(2)
Xpart2=ConvNet(part2)(Xpart1,θpart2),
(3)
Xpart3=ROI(part3)(Xpart2,RPx),
(4)
y=[RPx,Lablex]
=FC(Xpart3,θpart3,C,Refine(RPx))。
(5)
如公式(1)、(3)、(4)、(5)构成Fast R-CNN的网络输入输出关系,将初步得到的特征图Xpart1输入特有卷积神经网络得到输出Xpart2特征图,式(4)为将RPNet输出的建议区域RPx通过ROI策略映射到Xpart2后得到Xpart3,式(5)为将对应的目标区域进行位置精修后通过全连接层预测输出得到y,包括精修后的目标区域的位置RPx和类别Lablex[5]。本文使用的卷积神经网络结构为VGG-16[9],RPNet网络结构及参数设定见文献[8]。
RPN的训练过程是端到端的,即直接从输入原始图片到输出结果,使用的优化方法是反向传播和随机梯度下降,损失函数是分类误差和回归误差的联合损失。Faster R-CNN以满文文档印章检测为例的网络结果图如图1。输入为一张任意大小满文文档的图像,输出为检测到满文印章的图像。
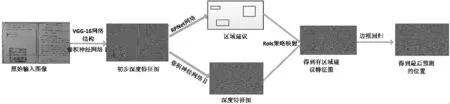
图1 Faster rcnn用于印章检测的网络结构图
2 数据增广
2.1 原始数据集
《清代新疆满文档案汇编》系列丛书共计293册,从中采集204张带印章的正样本,共500张不带印章的文档图像。其中每张图像中印章数量包含一个两个以及大于两个等情况,且印章存在交叠的情况;图像中印章区域为尺寸不固定的矩形区域。采用人工标记印章区域的方法对数据集进行标注。将原始数据集的70%作为训练集,30%作为测试集。
2.2 数据增广方法
由于满文古籍多为珍藏的书,特别是系列丛书,因此在数据采集过程存在很多困难,加上并不是每页都带有印章,一本档案中仅几页带有印章,且若采集大量原始图像需要大量的人工标注,非常耗时的工作。为解决此问题提出满文印章数据集的自动增广方法。
本文采用扩充数据的方法是将原始训练集扣取其中的印章区域,为保证印章的字样特性不变性,可变的因素有印章大小、盖印章的角度、由于墨迹导致的印章深浅等因素,选择变化形式也很重要。本文将扣取印章进行变大、变小、左右镜像、上下翻转、旋转90°、顺时针随机旋转1~10°、逆时针随机旋转1~10°、像素点增强、像素点减弱九种变化。
(1)缩放变化。对印章区域图像采用最近邻插值法进行缩放,设原图为m0×n0的矩阵X,缩放后为m1×n1的矩阵X1,(xsrc,ysrc)为原图像X坐标点,(xdst,ydst)为目标图像X1对应坐标点,由式(6)、(7)可由原图像坐标点求得对应目标点,目标图像点的像素值为对应原图像的像素点。t为缩放倍数,t∈[0.5,1.5],当t∈[0.5,1)为图像的缩小,t∈(1,1.5]为图像的放大。
xsrc=xdstt,
(6)
ysrc=ydstt。
(7)
(2)镜像变化。图像镜像变化也是一种重要的数据扩充方法,设原图像某一像素点的坐标为(x0,y0),Width、Height分别为原图像的宽与高。如下式(8)为图像左右镜像变换,其中(x1,y1)为经过左 右镜像变化后的对应点坐标。式(9)为图像上下镜像变化,其中(x2,y2)为经过上下镜像变化后的对应点坐标。
(x1,y1)=(Width-x0,y0),
(8)
(x2,y2)=(x0,Height-y0)。
(9)
(3)旋转变化。由于盖印章时会存在人为的倾斜现象,将印章进行旋转变化模拟该现象。设原印章第i行第j列像素的原坐标为(x,y),根据式(10)、(11)可得到该点像素对应变化后的坐标为(x',y')。其中θ为旋转角度,角度θ∈[-10,10],当θ∈[-10,0)为顺时针旋转,当θ∈(0,10]时为顺时针变化。经旋转变化,图像大小会变化,超过原图范围就填为白色。原始图像的像素坐标为整数,由于有浮点运算,变换后的目标图像的坐标位置可能不是整数,使用文献[10]方法处理。
x'=xcosθ-ysinθ。
(10)
y'=xsinθ+ycosθ
(11)
(4)点像素变化。点像素的变化分为增强与减弱,是在模拟印章由于人为用力大小以及墨迹深浅产生的效果。原图像为矩阵M∈Rm×n,则点像素变化如下式(12) ,M1为变化后印章,k为变化系数,k的取值范围[0.5,1.5],当k∈[0.5,1)为点像素减弱,模拟的是墨迹变浅;k∈(1,1.5]时为点像素增强,模拟墨迹变深的现象。
M1=kM。
(12)
设变化后的印章为m×n阶矩阵Ib,其中第i行第j列处点的值bij(i≤m,j≤n);从完整满文文档图像中随机产生一个与印章大小相同的文档区域Is,其中第i行第j列处点的值sij(i≤m,j≤n),则印章与相应文档背景融合的图像Im可以由矩阵Ib与矩阵Is求哈达玛乘积[11](hadamard product)所得,即Im=IbIs其中表示hadamard product,mij=bij×sij。经过变换后的印章构成印章集,从印章集中随机抽取n个(n<5)印章,再将抽取的印章进行与背景融合,将融合后的图像再融合到文档的原位置上。并且考虑真实档案存在印章交叠的情况,因此在扩充数据时要越接近真实情况。通过本文扩充方法共生成4 800张扩充的满文文档印章图像集,当n=2的数据扩充过程如图2。

图2 数据扩充过程图
3 实验与分析
实验采取mAP(mean average precision)作为印章检测性能的精度评价指标,计算公式如式(13)(14)所示。其中,P为查准率,在该实验中表示检测显示的区域有多少是真正准确的印章区域;R为召回率,在该实验中表示有多少真印章被检测出来。AP即为RP曲线的面积值;N为测试集分类数,mAP为反映全局性能指标。

(13)
(14)
本次实验将深度学习算法Faster R-CNN应用于满文文档数据集进行印章检测,部分测试结果图如图3,可以看到对于图3(a)中印章附于文字表面的情况可以检测出印章的位置,对于图3(a)及(b)中的浅墨迹印章,图3(c)中的多印章交叠等情况都可以检测出来,Faster R-CNN对于满文文档这样的非场景图像的目标检测仍然是有效的。但会出现少许边框不准确的情况。
为验证本文的解决满文文档数据采集困难导致的数据少的问题而提出的数据增广方法的有效性,进行对比实验,实验结果见表1,其中Data1为原始采集数据集,Data2为使用增广方法扩充的数据。用Data1作为训练集迭代5 000次训练的模型对测试集测试,mAP为0.904。而用Data2作为训练集迭代5 000次训练的模型对测试集测试mAP提高到0.996。同样在迭代10 000次的情况下,也是使用增广方法的Data2训练的模型效果将mAP从0.902 9提升到0.993。同时,分析结果,两组数据都是在5 000次迭代达到的效果比10 000次迭代效果好,并且该实验在Ubuntu系统GPU下每张图片平均处理速度仅为0.33 s。

(a)检测结果例1 (b)检测结果例2 (c)检测结果例3

表1 Faster R-CNN对测试集的mAP结果统计
为两个模型效果对比图如图4,图4(a)为未使用增广方法测试结果,图4(b)为使用增广方法测试结果,图4(a)(b)对比中可以看到两个模型都定位到了印章的位置,(b)中定位印章的下边比(a)更贴合,效果更好,说明本文提到的增广满文印章的方法对提升印章检测效果是有效的。

(a)原始检测结果 (b)增广后的检测结果
4 总 结
利用Faster R-CNN模型对满文文档中印章进行自动检测。实验表明,基于Faster R-CNN的方法对于浅墨迹的印章、多印章交叠以及带有噪音的印章等都能进行很好的检测。为了解决带印章的满文文档数据收集较为困难的问题,从而提出了对数据进行自动扩充的方法,并通过对比实验证明,通过数据增广的方法提高了印章检测的准确率。在未来的工作中,会在此基础上继续对满文文档中的印章进行识别。
