基于深度学习改善英文写作
2018-11-05蔡畅之
蔡畅之

摘要: 近些年,人工智能和深度学习蓬勃发展,但在帮助学习者提高英语写作方面应用十分有限。本文首先介绍深度学习,自然语言处理以及机器翻译的相关背景和发展情况;接着介绍如何搭建递归神经网络的框架,获取训练相关数据,通过选择序列到序列模型,得出可靠的结果,以增强英语写作能力;最后讨论本文中选择数据以及搭建模型的优点和缺点以及未来的研究改进方向。
【关键词】深度学习 自然语言
1 简介
随着当今国际间交流更加频繁和深入,作为世界上应用最广泛的语言,英语已经渗入到生活的方方面面,学习英语对于绝大部分非英语母语的学生们来说都是必要的。而这其中,在英语学习以及国际性英语考试(如IELTS,TOEFL)中,写作均占了很大的比例,达到考试总成绩的25% - 35%。同时,写作和阅读是息息相关的,在提高学生写作水平的同时,也会相应地提高他们的阅读水平。但当今传统的写作批改和提高反馈大多是书面形式,一方面,由于繁重的教学任务,很多英语教师对学生的反馈十分有限,另一方面,学生对老师给予的写作反馈也马虎对待,敷衍了事。所以开发帮助提高写作水平的软件就显得十分必要。
对于非英语母语学生英语写作的评改,在中国比较流行的为批改网( www.pigai.org),它是基于语料库和云计算的英语作文自动批改的在线服务。但该网站对于使用者输入的英文语句目前仅限于指出作者的一些”语法错误”或“词汇,时态错误”的问题,并不能判断写作水平的高低,以及给出修改句子的合理化建议,使表达更加地道,接近于母语表达者的习惯。
本设计基于深度学习(Deep Leaming),通过构建递归神经网络( Recurrent NeuralNetwork)中的编码器(Encoder)和译码器( Decoder),以及序列到序列(Sequence-to-Sequence)模型,使用Python语言和PyTorch工具,训练大量的英语母语者的写作文本( txt),以及英语学习者的写作文本,使机器可以判断出英语学习者的写作习惯以及英语母语表达者的习惯。这样机器可以了解写作者的常用错误表达习惯,并且给出相应的修改建议。使用者通过输入自己写作的的英文语句,同时收到更加地道的表达方式输出反馈,通过这种方法,提高使用者的英文写作水平。
2 背景
2.1 语言学背景
早在上世纪60年代末,Harris,D.P就曾提到过:书面练习的要点,灵活性,表达方式主要体现在词汇量的积累,以及阅读量的大小,以及实践练习的情况,是从依赖到独立的过程。Kroll,B也提到过写作可以提高阅读和应用水平,增强语言的综合能力。写作对于语言的综合应用能力检测起着至关重要的作用,既可以体现学生的词汇积累量,也可以体现学生的表达能力。
2.2 自然语言处理
自然语言处理(NLP)是计算机科学的一个领域,它是人工智能的一个分支,帮助计算机理解人类语言的写作和口语,特别是如何对计算机进行编程以成功处理大量自然语言数据。自然语言处理中的应用方向通常涉及语音识别,自然语言理解和自然语言生成。
2.3 朴素贝叶斯( Nalve Bayes)
自然语言处理中,朴素贝叶斯被广泛应用在句子分类、词汇频率检测等问题中。该方法基于贝叶斯原理(Bayes Theorem),特征条件相互独立的模型。
根据贝叶斯原理,对一个分类问题,给定样本特征x,样本属于类别y的概率是:
在这里,x是一个特征向量,将设x维度为M。因为假设特征条件独立,根据全概率公式展开,上述公式可以表达为:
如上式所示,只要分别估计出x^i在每一类的条件概率就可以。通过该式我们可以得出对应的每一类上的,条件独立的特征对应的条件概率。朴素贝叶斯在自然语言处理中常被用于改正语法错误之中。
以现代出版书籍作为语料库,使用“furthervs farther”方法,围绕关键词的词标记,对朴素贝叶斯公式进行处理,使每个单词在主关键字的左右1-2位[16]。借此发现,单词”furrher”和“farther”的使用均达到了较高的正确率,表1举例说明朴素贝叶斯概率结果。
如表1所示,朴素贝叶斯模型可以很好地纠正这些句子的语法。Tory等人以此統计学模型遍历关键词列表来完善功能更加齐全的语法检查器,找出不易察觉的语法错误,由此来改善语法。
2.4 RNN
与传统的朴素贝叶斯模型及其它基于统计学的模型不同,递归神经网络(RNN)是一类人工神经网络,单元之间的连接形成沿着序列的有向图。这使得它可以表现时间序列的动态时间行为。与前馈神经网络不同,RNN可以使用其内部状态(内存)来处理输入序列。这使它们适用于诸如未分割,连接手写识别[4]或语音识别等任务。
递归神经网络有时不加区分地用于两类具有类似结构的网络,其中一个是有限冲动,另一个是无限冲动。这两类网络都表现出时间动态行为。有限脉冲递归网络是一个有向无环图,可以展开并用严格前馈神经网络代替,而无限脉冲递归网络是一个不能展开的有向循环图。
有限脉冲和无限脉冲周期性网络都可以有额外的存储状态,并且存储可以由神经网络直接控制。如果存储时间延迟或有反馈循环,则存储也可以由另一个网络或图形取代。这种受控状态被称为门控状态或门控记忆,并且是长期短期记忆(LSTM)和门控循环单元(GRU)的一部分。
2.5 序列到序列模型( Sequence to sequencemodel)
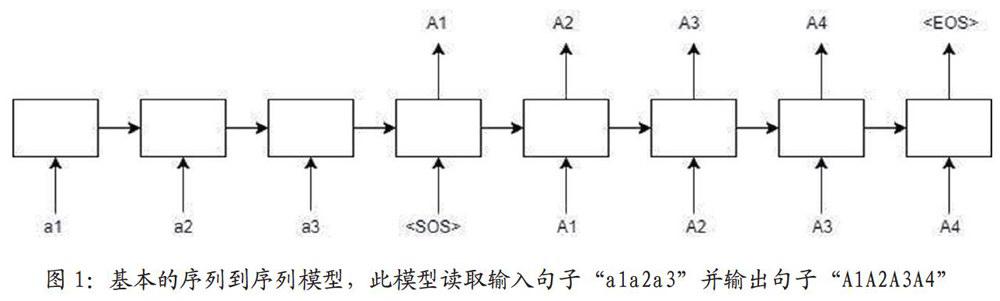
递归神经网络(RNN)有许多的变形,例如基本的序列到序列模型由两个递归神经网络组成:处理输入的编码器和生成输出的解码器,图1描述了这个基本架构:
图1中的每个框表示RNN的小区(cell),最常见的是GRU小区或LSTM小区。编码器和解码器可以共享权重,或者更加常见的是,它们使用不同的参数集。
该模型的工作原理是通过多层LSTM将输入序列映射为固定维度的向量,然后使用另一个深度LSTM从向量中解码目标序列。
序列到序列模型有很多应用,比如说谷歌公司将其应用在改正外语语法方面。除此之外,序列到序列模型还有许多其他应用,例如机器翻译。
2.6 机器翻译( Machine Translation)
机器翻译是计算语言学的一个子领域,它主要研究使用软件翻译文本或从一种语言到另一种语言的转化。
机器翻译旨在将源语言句子找到最有可能的目标语言句子,这些句子匹配到最相似的意思。实质上,机器翻译是序列到序列模型的预测任务。
神经机器翻译(NMT)如今常被作为一种先进的方法,其潜力可以解决传统机器翻译系统的许多缺点。NMT的优势在于它能够以端到端的方式直接学习从输入文本到输出文本的相关映射。其架构通常由两个递归神经网络( RNN)组成,一个用于消耗输入文本序列,另一个用于生成翻译的输出文本。NMT通常伴随着注意机制,这有助于它有效处理长输入序列。
Google公司对NMT技术进行了相关改进,形成了GNMT系统,它由一个深度的LSTM网络组成,该系统有效改正了原来NMT对罕见词语准确性差,反应慢的缺点。
3 方法
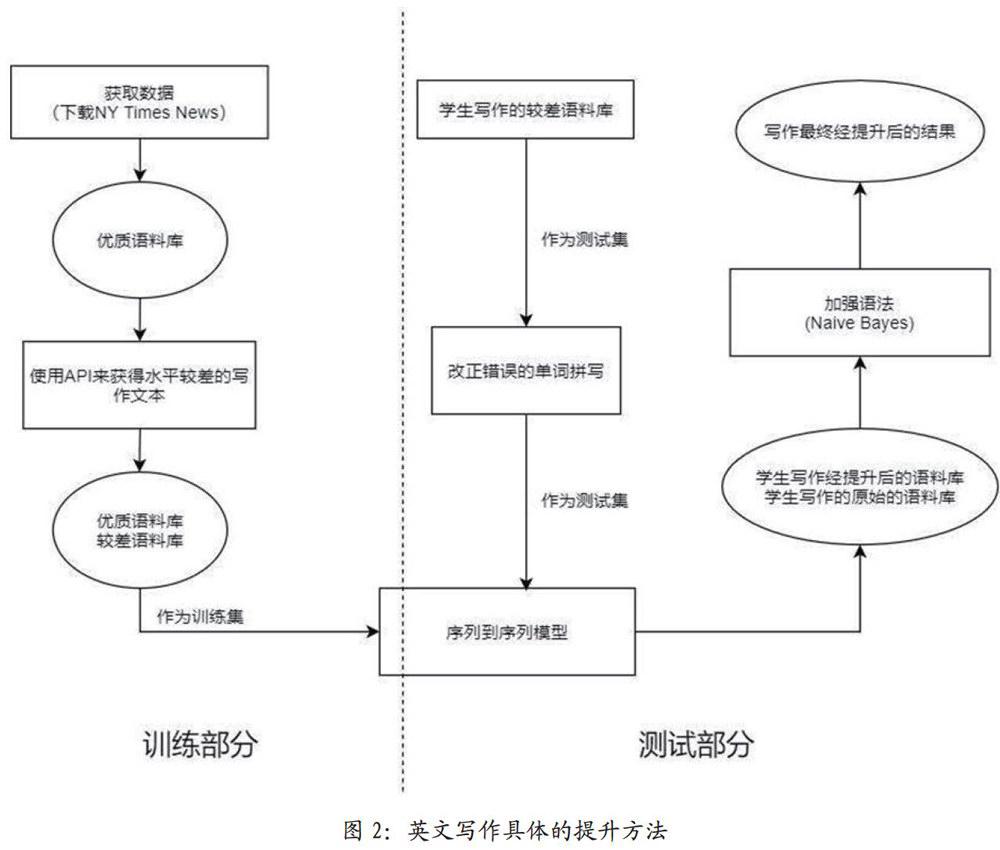
3.1 提升过程
如图2所示,完成上部分流程,即得到数据并完成清理之后,我们将所整理好的的优质语料库和较差语料库放入写好的序列到序列模型中,进行训练,可以得到一定量的数据来进行测试。在模型建立好同时训练集进行相关训练得到数据之后,学生就可以进行相应的使用了:将自己的写作语句进行输入,在此模型中即为测试集。
提升之后,我们获得了提升后的结果,但受到模型和数据限制,其中可能包含一些语法错误。所以相应结果要对语法进行改正,此处使用朴素贝叶斯公式进行语法的相关改正。在进行了一系列的修改和提高之后,我们就得到了最终的提升结果。
3.2 模型
本实验采用三层神经网络作为词嵌入模型( Word Embedding)。因为语料包中共有67055个词类,词嵌入模型的神经网络中输入层有67055个神经元,而神经网络中隐藏层每层均有1024个神经元。
词嵌入模型的输出层即为序列到序列模型的输入层。因为语料库中大部分语料在20单词以下,训练过程只考虑小于20字的预料。在本文序列到序列模型中,编码器和解码器皆使用门控循环单元(GRU)。然而,编码器使用了双向循环结构,解码器使用了注意力机制( Attention Mechanism),为防止深度模型过度拟合,在训练阶段中解码器使用dropout方法,其中dropout概率为0.5。测试阶段时,dropout方法被禁用。
本实验使用随机梯度下降训练此深度模型。为防止梯度下降算法卡在局部最小值,随机梯度下降的动量设为0.9。训练起始时,学习率设为0.001;算法每训练语料库10次,自动把学习率减半;共训练语料库20次。
每次随机梯度下降中,解码器会随机采用或不采用导师驱动过程( teacher forcing)进行训练。使用导师驱动过程时,模型将目标序列转变成相同的序列,但会偏移一个步长;不使用导师驱动过程时,解码器只在生成
3.3 拼写改正
拼写改正的原理:使用编辑距离,测量两个字符串的差异长度,看至少需要多少次的处理才能将一个字符串变成另一个字符串。在拼写检查中可以根据一个拼错的字和其他正确的字的编辑距离,判断哪一个(或哪几个)是比较可能的字。
此处用来改正拼写错误的是莱温斯坦距离,也是编辑距离的一种。例如,“kitten”和“sitting”之间的莱温斯坦距离是3,因此以下三次编辑为将一次编辑后的结果再次编辑,并且此处编辑的次数不可能小于三次:
kitten—sirtenf用‘s取代'k')
sitten—sittin(用'i'取代‘e)
sittin—sitting(在最后加入‘g')
4 討论
4.1 优势
作为训练集的优质语料库,使用去年的《纽约时报》(New York Times)新闻。这些文章发表日期距现在最近,而且内容均为当今人们比较关注的话题,于此同时,也是英文学习者写作过程中可能遇到的话题,在当下写作中词句出现的频次相对而言更高,相关语料库也更加有针对性。
同时,在遣词造句方面,新闻文章运用了当下比较常见的英文写作习惯和单词,段落较小,简单易懂,层次分明,避免了很多过时的拼写和表达方式,同时减少了生僻词出现的概率,训练也更加具有针对性。
在训练集的训练过程中,排除了标点符号可能带来的影响,以及其他错误的单词带来的结果,使训练效果更好。
在提升的过程中,不仅考虑到了语言使用的提升,还对其他问题进行了考虑,例如拼写错误的修改和语法错误的修改,这些基础性的改正可以使程序可以更好地运行,避免因拼写和语法错误影响到最终的改进结果。
与传统写作修改网站或软件不同,该模型可以进行全方位的提升,不仅限于修改语法错误和拼写错误,更可以提升表达方式,使英语写作更加接近母语表达者的习惯,而不仅仅停留在写作没有错误的层面上。
4.2 缺点
受设备限制,本实验无法训练所有语料库数据,仅仅训练了其中的一小部分,对于学生来说数据量可能无法满足使用的需求。但我们已经找到了正确的训练方向,若花费更多时间,使用性能更佳的设备来训练,必能使该模型达到可以实际应用的水准。
在数据处理上,没有区分大小写,可能出现一些因为大小写原因产生的歧义。但本模型仅仅是实验所用,提供了一种方法,若要投入学生正常使用,可作进一步改进。同时,特殊标点符号(比如破折号,下划线,星号,等)并未被考虑进模型,然而只需拥有足够的训练集,本文提供的方法能夠轻易的把这些特殊符号收录进模型中。
5 总结
本文使用纽约时报数据以及谷歌翻译软件获得训练数据,并训练序列到序列模型帮助非英语为母语的学生修改写作中出现的语法错误。本实验为概念验证实验,人工评判显示序列到序列模型可以有效提升英文句子,然而模型结果仍然无法与人工修改结果媲美。本文给深度学习与自然语言处理指明了写作提升算法的未来研究方向。当训练样本不足时,研究人员可以考虑使用传统自然语言处理方法;在二十一世纪,人工智能与大数据时代,获得训练样本的难度显著降低,在此基础之上,序列到序列模型与递归神经网络能够有效自动提升英文写作。可以预见在不久将来,随着深度学习的模型改进,自然语言处理算法的发展,与大量训练数据的获得,全自动的英文写作提升算法能获得快速的发展,而本文提供了未来研究的思路与方向。
参考文献
[1]石晓玲,在线写作自动评改系统在大学英语写作教学中的应用研究以句酷批改网为例[J],现代教育技术,2012: 22 (10): 67-71.
[2]张琪,基于句酷批改网的“英语基础写作”教学模式改革研究[J].当代教育理论与实践,2015 (12):122-124.
[3] Machiraju,S.,&Modi;,R.(2018). Na turalLanguage Proces sing. In DevelopingBots with Microsoft Bots Framework(pp. 203-232). Apress, Berkeley, CA.
[4] Graves,A.;Liwicki,M.;Fernandez,S. Bertolami,R.;Bunke,H.;Schmidhuber,J.(2009). "A NovelConnectionist System for ImprovedUnconstrained HandwritingRecognition" .IEEE Transactionson Pattern Analysis and MachineIntelligence. 31 (05).
[5]Sak, Ha s im; Senior, Andrew; Beaufays,Francoise (2014). "Long Short-TermMemory recurrent neural networkarchitectures for large scaleacoustic modeling".
[6] Miljanovic, Milos
(Feb-Mar 2012)."Comparative analysis of' Recurrentand Finite Impulse Response NeuralNetworks in Time Series Prediction".Indian Journal of Computer andEngineering.3 (01).
[7] Sutskever,I.,Vinyals,0.,& Le,Q.V. (2014). Sequence to sequencelearning with neural networks.In Advances in neural informationprocessing sys tems (pp. 3104-3112).
