基于Python Beautiful Soup的多线程数据获取
2018-10-24薛晓军薛涛邓仕宏
薛晓军 薛涛 邓仕宏

摘 要:利用Python BeautifulSoup模块,抓取环境监测网站的数据,并对数据进行处理后存储。爬虫程序在服务器上持续运行。当网络不稳定时,爬取失败后仍会继续自动重试。该程序对网页数据不断爬取,保证数据的连续性价值。通过多线程爬虫程序提高数据获取的效率。通过对共同访问的数据进行加锁,防止出现资源访问的错误,进行线程的同步。使用百度地图web服务API中的地理编码服务,对监测地点进行经纬度的确定。
关键词:数据获取;多线程程序;线程同步
1.项目研究背景及意义
随着工业化和城市化进程的推进,城市的空气污染状况日趋严重,中国目前已经成为全球PM2.5污染最为严重的地区之一[1-3]。“雾霾”出现频率的增加,范围扩大,严重影响到我们的生活质量和身体健康。
北京地区雾霾污染严重,区域传输影响较大,北京雾霾的成因中,传输型的污染占比约30%(全年平均),在传输型污染中,区域传输所占的比例高于50%。从雾霾成因全年平均来看,区域传输占比约20%。2016年环保部专家们会商认定黑龙江秸秆焚烧造成几乎从整个东北到华北甚至山东江苏雾霾,但此认定缺少示踪监测、模型分析的过程,缺少相关的科学依据,也没有向民众展示雾霾传输的方式和轨迹,并没有得到广大群众的认可。而在目前公布的数据中,只给出区域传输所占比例,没有给出雾霾区域传输的来源,即传输来源于哪些地区及其所占的比例并不明确。
2.1获取数据
2.1.1数据来源背景
本项目的数据主要来源是Pm25.in网站,数据来源丰富,该网站共包括375座城市,1600个数据点。每个点包含AQI、空气质量指数类别、首要污染物、PM2.5细颗粒物、PM10可吸入颗粒物等重要污染物,符合本项目对雾霾区域传输研究数据的要求。
数据来源可靠、真实。Pm25.in网站是一个为广大应用开发者免费提供空气质量数据的一个公益性网站,Pm25.in的数据全部来源于网友提供的国家环保网站公开数据,网站会根据国家环保网站的实时数据进行二次核实。
2.1.2获取数据方式的选择
运用python的Beautiful Soup库对Pm25.in網站进行数据爬取。Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库,它是一个灵活又方便的网页解析库,处理高效,支持多种解析器。它能够通过转换器实现惯用的文档导航,查找,修改文档的方式,Beautiful Soup具有高效性,会帮本项目在爬取节省很多工作时间。
2.1.3获取数据的步骤
1)获取网页源码
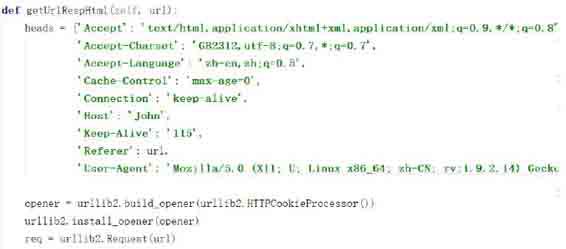
采用python的urllib2模块对Pm25.in网站数据进行爬取。利用urllib2库的HTTPCookieProcessor对象来创建cookie处理器,让HTTPCookieProcessor作为build_opener()函数的参数来创建自定义Opener对象。将urllib2.Request()实例化,需要访问的url地址连同headers则作为Request实例的参数,返回获取网页的源码。
获取网页源码的python程序设计如下图获取网页源码程序图所示:
2)处理网页源码
运用Beautiful Soup库的find() split()方法遍历源码,找到所需要的数据。利用python对文件的处理,将这些需要的原始数据写入记事本当中,以便以后处理使用。
处理源码的python程序设计如下图处理网页源码图所示:
3)需要注意的问题
●连续性
当出现网络不稳定或网络断开导致爬取数据失败时,爬虫程序自动重试对网页源码的读取,重试失败次数达到10次后放弃爬取,输出错误日志。等待人工处理错误。这样设计python程序可以保证该程序对Pm25.in网站的数据不断的爬取,尽量使得获取的数据是连续的,更有利用价值。
●实时性
Pm25.in网站的数据是一个小时更新一次,为确保数据的实时性,爬虫程序便每一小时对监测点数据进行抓取。确保获取数据的有效性和实时性。对这些实效性数据进行清洗后,用于雾霾区域传输相关性研究,可以确保研究的正确性和时效性。
●高效性
使用多线程对网站数据进行抓取。多线程之间可以快速切换,提高效率,缩短爬取大量数据所需的时间。最初实现爬虫程序时,使用单线程进行数据抓取,抓取效率很低,单次执行需要等待较长时间,测试时效率也很低。对程序进行完善,使用多线程实现效率的提升。定义MultiThread类实现多线程的抓取,在该类的构造函数中有两个参数,一个是并发线程的总数,一个是任务个数。通过调整并发线程的总数实现不同效率的数据抓取。MultiThread类的具体实现如图所示。
通过对共同访问的数据进行加锁,进行线程的同步,防止出现资源访问的错误。刚开始使用多线程程序对文件进行读写操作时,最终存入文件的数据总是错误的,有的是多行数据混在一行,有的是数据编号不正确,出现了很多问题,发现问题是多个线程同时对文件进行读写,出现了读写错误。解决方法是对共同访问的文件进行加锁,当有进程在对文件进行操作时,其他进程进行等待,进行线程的同步。加锁的位置也十分关键,共同使用的文件、变量都需要进行加锁。
2.2数据处理
地点与对应经纬度转化:对于爬取的数据进行经纬度的转换,在这里使用的是百度地图web服务API中的地理编码服务。
获取密钥:注册百度账号,申请成为百度开发者之后,获得服务密钥(ak)。然后便可以运用拿到的ak来使用地理编码服务,使得本项目数据点的具体地址转化为需要的经纬度。
调用服务:本项目对地理编码服务的请求,具体是对http://api.map.baidu.com/geocoder/v2/?address=北京市海淀区上地十街&output;=json&ak;=ak&callback;=showLocation网址进行GET请求。
参考文献:
[1]孟伟,高庆先,张志刚等. 北京及周边地区大气污染数值模拟研究[ J ]. 环境科学研究. 2006,19(5):11-18.
[2]安静宇. 长三角地区冬季大气细颗粒物来源追踪模拟研究[D].硕士学位论文. 东华大学,2015年.
[3] Wang YueSi, Yao Li, Wang LiLi , et al .Mechanism for the formation of the January 2013 heavy haze pollution episode over central and eastern China[ J ]. Science China Earth Sciences,January 2014 ,Vol.57 No.1: 14–25.
