基于语义相关性与拓扑关系的跨媒体检索算法
2018-10-16代刚,张鸿
代 刚,张 鸿
(1.武汉科技大学 计算机科学与技术学院,武汉 430065; 2.智能信息处理与实时工业系统湖北省重点实验室(武汉科技大学),武汉 430065)
0 引言
如今,非结构化的异构多媒体内容(如图像、文本、音频、视频和3D模型)正在迅猛地涌入互联网中,有效地分析这些多媒体数据是有必要的。虽然许多研究致力于多模态数据分析[1-3],这些研究共同的策略是整合多种模态来提高学习性能。本文集中在与多模态数据分析相关的跨媒体检索。跨媒体检索指用某一种类型的媒体数据作为查询去检索其他媒体类型相关的媒体数据。例如,用户能使用一个文本去检索相关的图片或视频,或者使用一张图片去检索相关的文本描述或视频。
跨媒体检索的关键问题是如何去学习不同模态数据之间的内在相关性[4]。已经存在一些方法能解决跨媒体检索问题,例如,典型相关分析(Canonical Correlation Analysis, CCA)[5-6]已被应用于跨媒体检索作为一种自然的解决方案,是去最大化两组异构数据之间的相关性。跨模态因子分析(Cross-modal Factor Analysis, CFA)[7]评估两种不同媒体数据之间的关联,在变换域中,CFA最小化成对数据之间的Frobenius范数。联合图正则化的异构度量学习(Heterogeneous Metric Learning with Joint Graph Regularization, JGRHML)[8]学习异构度量并将不同媒体的结构整合为一个联合图正则化,进而能够测量不同媒体数据之间的内容相似度。跨模态相关传播(Cross Modality Correlation Propagation, CMCP)[9]同时处理不同模态的媒体数据之间的正相关和负相关,并且在异构的模态之间传播这种相关性。近邻的异构相似性度量(Heterogeneous Similarity measure with Nearest Neighbors, HSNN)[10]可以计算不同媒体类型的媒体对象之间的相似度,它通过计算两个媒体对象属于同一个语义类别的概率来获得异构相似度。
另外,共同的表示学习(Joint Representation Learning, JRL)[11]是一种用稀疏和半监督正则化去学习跨媒体共同的表示的方法,它能够在一个统一的优化框架中共同挖掘相关信息和语义信息。统一补丁图正则化的半监督跨媒体特征学习( Semi-Supervised cross-media feature learning with Unified Patch Graph regularization, S2UPG)[12]利用一个联合图同时对所有媒体类型进行建模,并充分利用跨媒体未标记实例及其补丁。联合特征选择和子空间学习(Joint Feature Selection and Subspace Learning, JFSSL)[13]使用了一个多模态图正则化项去保存模态之间和模态内部的相似关系。文献[14]为跨模态检索研究了一个用于构建语义相关性的语义模型。文献[15]提出了一种直推式学习方法来挖掘不同模态的媒体对象之间的语义相关性,从而实现跨媒体检索。文献[16]提出一种支持海量跨媒体检索的集成索引结构,该方法首先通过对网页的预处理,分析其中不同模态媒体对象之间的链接关系,生成交叉参照图,然后通过用户相关反馈进行调节。文献[17]提出的跨媒体检索方法分析了不同模态的内容特征之间在统计意义上的典型相关性,并通过子空间映射解决了特征向量的异构性问题。
为了去学习不同模态数据之间的内在相关性,本文提出了一种基于语义相关性与拓扑关系的跨媒体检索算法。该算法的主要流程如下:
1)提出一个需要优化的目标函数,需要优化的是为每种媒体数据投影到一个共同空间所需要的投影矩阵。
2)通过一个迭代算法求解这个目标函数,得到每种媒体类型最优化的投影矩阵。
3)通过得到的每种媒体类型的投影矩阵将各种媒体数据的特征向量投影到一个共同的空间中,然后在这个空间中计算投影后的向量之间的相似度,进行实现跨媒体检索。
1 目标函数的构建与优化
1.1 目标函数的构建
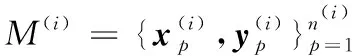
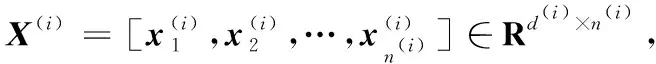
定义完这些变量之后,开始构建需要优化的目标函数。为了迫使每种媒体数据的特征向量投影后都接近其标签向量,本文定义了一个与文献[11]一样的标签损失项如下:
(1)
其中‖Z‖F表示矩阵Z的Frobenius范数。这个标签损失项仅仅考虑了每种媒体类型中有标签数据的语义信息,而没有考虑不同媒体类型和相同媒体类型中的全部有标签数据之间的语义相关性,因而本文定义了一个多媒体语义相关超图,就是将不同媒体类型和相同媒体类型中的全部有标签数据之间的语义相关性融合在一个超图中。
为了构建这个多媒体语义相关超图,本文定义了一个语义相似度矩阵如下:

(2)
其中:i=1,2,…,s;j=1,2,…,s;s表示多媒体数据集中的媒体类型种数,p=1,2,…,H;q=1,2,…,H;而H=n(1)+n(2)+…+n(s)表示多媒体数据集中所有模态中有标签数据的总个数。由于前面的语义相似度矩阵的定义,整个语义相似度矩阵W定义如下:
(3)
为了使所有模态数据中相同语义类别数据投影后的数据点之间的欧氏距离最小,定义了一个多媒体数据的语义相关超图正则化项如下:

(4)

进一步地,为了利用多媒体数据之间的近邻关系,需要构建一个多媒体近邻关系超图。为了构建这个多媒体近邻关系超图,定义一个近邻关系相似度矩阵如下:

(5)
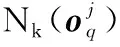
由于前面的近邻关系相似度矩阵的定义,整个近邻关系相似度矩阵U定义如下:
(6)
为了使所有模态数据投影到共同空间后的数据点的k近邻靠得近,定义了一个多媒体数据的近邻关系超图正则化项,如下:
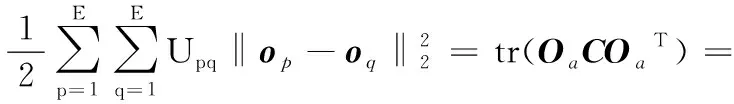
(7)
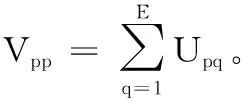
接着,为了使每个投影矩阵P(i)(i=1,2,…,s)稀疏,定义了一个稀疏正则化项,为所有投影矩阵的l2,1范数之和如下:
(8)


(9)
其中:α、β、λ1和λ2是正的参数。该目标函数的第一项是标签损失项,第二项是稀疏正则化项,第三项是多媒体数据的语义相关超图正则化项,第四项是多媒体数据的近邻关系超图正则化项。
1.2 目标函数的优化
用Φ表示式子(9),Φ对P(i)求偏导并置为0,则有:


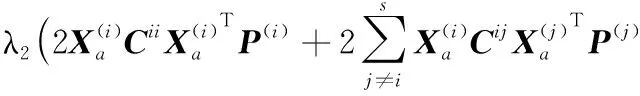
(10)
整理式(10)得:
P(i)=[αX(i)X(i)T+βR(i)+λ1X(i)LiiX(i)T+

(11)

(12)
其中ε是一个很小的正数。

算法1 基于语义相关性与拓扑关系的跨媒体检索算法。
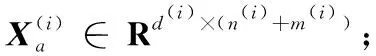
输出:s种媒体类型的s个投影矩阵P(i)∈Rd(i)×c(i=1,2,…,s)。
过程:
1)计算多媒体语义相关超图中的拉普拉斯矩阵L;
3)重复


(13)
④t=t+1;
4)直到收敛
2 跨媒体检索的相似度


(14)

(15)

3 实验分析
3.1 数据集描述
在本实验中,采用广泛使用的跨媒体数据集,分别为Wikipedia数据集和XMedia数据集。分别介绍如下。
Wikipedia[18]数据集是从2 700个“专题文章”中选出的,而这些专题文章是经过维基百科编辑自2009年以来挑选和审阅得到的。Wikipedia数据集最后由2 866个图像-文本对组成,且包含10个语义类别,这个数据集被随机分成2 173个图像-文本对的训练集和693个图像-文本对的测试集。
在本文中使用的XMedia[11-12]数据集包括5 000个文本、5 000个图像、1 140个视频、1 000个音频和500个3D模型。与在文献[11-12]中使用的XMedia数据集唯一的不同是:文献[11-12]中使用的视频个数为500,而本文中使用的视频个数是1 140,但这些视频数据都属于XMedia数据集,更多实验数据进行实验更有说服力。随机划分每种媒体类型的训练集与测试集的数据,且每种媒体类型的训练集与测试集的数据的个数之比均为4∶1。在Wikipedia和XMedia数据集中,每个图像由4 096维的卷积神经网络(Convolutional Neural Network, CNN)特征向量表示,每个文本由3 000维的词袋(Bag of Words, BOW)特征向量表示。另外,在XMedia数据集中,每个音频由29维的MFCC(Mel-Frequency Cepstral Coefficients)特征向量表示,每个视频由4 096维的CNN特征向量表示,每个三维模型由文献[19]中描述的一组光场描述符级联的4 700维的特征向量表示。
3.2 评估指标
关于跨媒体检索的评估指标,采用与文献[11-12]相同的评估方法,即使用准确率-召回率( Precision-Recall, PR)曲线和平均准确率( Mean Average Precision, MAP)来评估检索的结果。MAP在图像检索和跨媒体检索中被广泛使用。一组查询的MAP是每个查询的平均精度(Average Precision, AP)的平均值。AP定义为:
(16)
其中:n表示测试集数据的个数,R表示检索返回的相关项的个数,Rk表示在前k个返回结果中相关项的个数;并且如果排在第k位的返回结果是相关的,那么relk=1,否则relk=0。
3.3 参数设置
在式(9)中的参数α、β、λ1和λ2,和在式(5)、(15)中的参数k需要设置,对于XMedia数据集和Wikipedia数据集,实验检索结果最好(即MAP值最大)时的参数均为α=10,β=1 000,λ1=0.01,λ2=0.001,k=100。
3.4 复杂度分析
分析本文算法的时间复杂度,从算法1中可看出,此算法主要的时间复杂度在于计算多媒体数据的近邻关系超图中的拉普拉斯矩阵Ct和式(13)中的矩阵的逆。这里将一维数据之间的乘法运算作为一个基本运算单元,经分析可知,计算Ct需要执行基本运算单元O(c*E2)次,E表示多媒体数据集中所有模态中有标签数据和无标签数据的总个数,c表示多媒体数据集中语义类别的个数;计算式(13)中的矩阵的逆需要执行基本运算单元O(d3)次,d=max(d(1),d(2),…,d(s)),而其中d(i)表示第i种媒体数据的特征向量的维度,s表示多媒体数据集中的媒体类型种数。因此,算法的时间复杂度为max(O(c*E2),O(d3))。
3.5 实验结果的分析
在Wikipedia和XMedia两个数据集上进行实验,且将本文提出的算法(SCTR)与4个主流的跨媒体检索算法在跨媒体检索任务中比较MAP值和PR曲线,这4个跨媒体检索算法为JGRHML算法、CMCP算法、HSNN算法、JRL算法。在所有的检索任务中A→B表示查询例子的媒体类型为A,检索结果的媒体类型为B。表1提供了所有实验方法在Wikipedia和XMedia数据集上跨媒体检索任务中的MAP值,表1最右边一栏是本文提出方法所获得的MAP值。从表1中对应Wikipedia数据集中结果可看出,本文提出的算法将其他4种算法获得的最高的MAP的平均值从0.455 6提高到0.493 0,提高了3.74%。从表1中的对应XMedia数据集中结果可看出,本文提出的算法将其他4种算法获得的最高的MAP的平均值从0.426 2提高到0.517 3,提高了9.11%。因此从表1可看出本文提出的算法性能明显优于对比算法的性能。
实验中的所有方法在XMedia数据集中图像与文本之间获得的MAP值明显高于在Wikipedia数据集中图像与文本之间获得的MAP值,可能由于Wikipedia数据集中有许多图像是黑白图像,图像内容模糊,导致提取到的图像特征的表示能力较弱,一定程度上影响了检索的准确率。图1展示了在Wikipedia数据集上实验中各种算法在图像检索文本、文本检索图像任务中的PR曲线,可以看出本文提出的SCTR算法与其他四种算法相比,在绝大多数召回率相同时,SCTR算法的准确率要高于其他四种算法的准确率。图2展示了在XMedia数据集上实验中各种算法在图像检索文本、图像检索音频、图像检索视频、图像检索3D模型任务中的PR曲线,由于篇幅的限制,就没有给出在XMedia数据集上其他检索任务的PR曲线,但是其他检索任务的PR曲线是与图2的PR曲线类似。从图2中可以看出在XMedia数据集上,本文提出的SCTR算法与其他4种算法相比,在所有召回率相同时,SCTR算法的准确率要高于其他四种算法的准确率。从图1(a)与图2(a)对比中可看出,在图像检索文本的任务中,当召回率相同时,各种算法在XMedia数据集上的准确率要高于在Wikipedia数据集上的准确率,这与在表1中发现的关于图像与文本的MAP值的规律一致。

表1 各算法在Wikipedia和XMedia数据集中MAP值比较
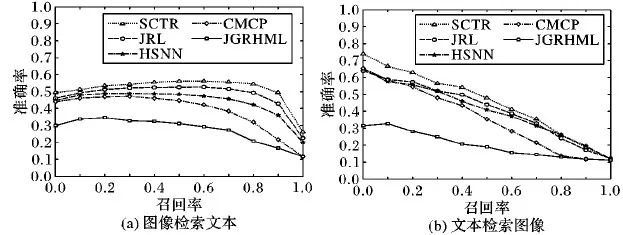
图1 Wikipedia数据集中的准确率-召回率曲线
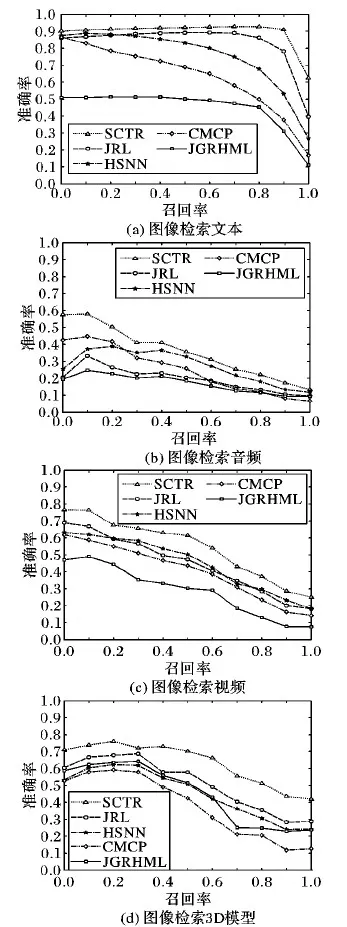
图2 XMedia数据集中的准确率-召回率曲线
实验还给出了在Wikipedia数据集中不同类别样例的MAP值。图3展示了在Wikipedia数据集中所有实验的方法在各种类别上的MAP值和在各种类别中的MAP值的平均值,对于大多数类别来说,本文提出的方法的MAP值要高于其他四种方法的MAP值,图3的(a)和(b)中的最右边那栏表示实验中的方法在各种类别中的MAP值的平均值,明显可看出本文提出的方法在各种类别中的MAP值的平均值要高于其他四种方法在各种类别中的MAP值的平均值。
4 结语
在Wikipedia和XMedia数据集上的实验结果表明本文提出的方法能有效提高跨媒体检索的准确率。本文算法利用多媒体数据语义相关超图、近邻关系超图和语义信息来学习不同媒体类型的投影矩阵,以使不同媒体类型的数据投影到一个共同的空间而获得共同的表示,进而实现跨媒体检索,但本文采用的线性投影不能捕获具有高度非线性的复杂的跨模态相关性,所以如何获取具有高度非线性的复杂的跨模态相关性还有待进一步地探索。

图3 Wikipedia中不同类别样例的平均准确率
