基于局部近邻标准化和动态主元分析的故障检测策略
2018-10-16郭青秀冯立伟
张 成,郭青秀,冯立伟,李 元
(1.沈阳化工大学 数理系,沈阳 110142; 2.沈阳化工大学 技术过程故障诊断与安全性研究中心,沈阳 110142)
0 引言
随着现代工业技术的发展,工业过程规模不断扩大、复杂度逐渐提升。为保证生产安全及产品质量,故障检测技术在工业生产过程中变得尤为重要。
主元分析(Principal Component Analysis, PCA)作为一种多元统计故障检测方法已被广泛应用于工业过程监控中[1-4]。PCA通过线性变换将原始空间分为主元子空间和残差子空间,分别应用统计量Hotelling’s T2和平方预测误差(Square Prediction Error, SPE)对上述空间进行监控。由于其统计量T2和SPE计算时假设数据服从单模态的多元高斯分布,且PCA忽略了变量沿时间序列上的相关性,所以其使用范围受到了一定的限制。针对非线性问题,核主元分析(kernel Principal Component Analysis, kPCA)方法被引入到过程监控中[5],其基本思想是通过非线性映射将数据映射到高维特征空间,然后在高维的特征空间上进行主元分析[6]。与传统的PCA相比,kPCA具有主成份特征明显、贡献率集中等优点,其性能优于PCA。由于kPCA仍然使用T2和SPE两个统计量进行过程监视,因此它在多模态过程故障检测中同样具有相应的局限性[7]。针对非线性和多工况等特征,He等[8]提出了基于K近邻的故障检测(Fault Detection based onKNearest Neighbors, FD-KNN)方法,利用局部距离之和D2进行检测,提高了非线性和多模态中大尺度故障的检测能力;但当数据为多模态且方差差异较大时,该方法的故障检测能力降低。针对工业过程的动态特性,Ku等[9]提出动态主元分析(Dynamic Principal Component Analysis, DPCA)方法,通过引入延时测量值构成增广矩阵,再对其进行PCA建模。DPCA消除了样本自相关性导致的统计量不平稳现象,但没有考虑多模态数据模态切换时过程变量在时间上存在的自相关特性[10],同时DPCA的统计量T2和SPE同样需要数据满足多元高斯分布。
针对数据为多模态且时序相关的过程监控问题,本文提出了局部近邻标准化(Local Neighborhood Standardized, LNS)和DPCA相结合的故障检测方法LNS-DPCA。首先对数据进行局部近邻标准化处理,对每个样本采用其局部近邻均值和标准差进行标准化处理以消除多模态特征;接下来对标准化后的数据应用DPCA建立模型和进行故障检测。LNS-DPCA不仅具备DPCA处理样本自相关性的能力,还继承了LNS能够将多模态数据融合为单模态数据的优势,可以有效地对具有多模态和相关性特征的工业过程进行故障检测,提高生产过程的可靠性。
1 DPCA
在DPCA中,通常认为当前时刻样本与过去时刻样本相关,因此可以构造当前时刻样本X(k)增广向量如下:
Xk(l)=[X(k),X(k-1),…,X(k-l)]
(1)
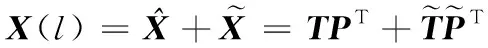
(2)
其中:P∈Rm×A是主元负载矩阵,由X(l)协方差矩阵的前A个特征向量构成,A为主元的个数;T∈Rm×A是得分矩阵。在主元空间和残差子空间分别使用Hotelling’s T2和平方预测误差SPE进行故障检测。
T2=tΛ-1tT
(3)
SPE=[X(l)-X(l)PPT]2
(4)
其中:t=X(l)P为当前时刻样本得分向量;Λ为X(l)协方差矩阵的前A个特征值构成的对角阵。记:xi(i=1,2,…,n)为训练增广矩阵X(l)中的第i个变量,当变量xi服从多元高斯分布时,T2和SPE统计指标的控制限可以由式(5)、(6)确定[11]。
(5)
(6)
其中:T2近似服从自由度为A和m-A的F分布;SPE近似服从自由度为h的χ2分布;如果将训练数据SPE统计指标的均值和方差分别记为a和b,那么参数g=b/(2a),同时h=2a2/b;α为置信水平,通常选取为0.99或0.95。
首先,在主题上存在问题。通过研究可以看出,在一些微课教学中存在着主题不明确的问题。究其原因就是教师在教学中并没有对微课教育产生正确的认识,这样也就使得微课教育的正常开展开受到了影响。其次,教学目标不准确。一般来说微课的教学目标大多是从知识技能目标上提出来的,主要是因为这一环节是学生最容易产生疑问的地方。但是从实际上来说,由于一些目标在设计上以情感目标为主,这样也就使得在有限的时间里难以让学生所理解,而影响到了教学的开展效果[1]。
2 基于LNS-DPCA的故障检测策略
DPCA虽然可以获取数据的动态联系信息,但它也如同PCA一样使用T2和SPE两个统计量实现过程监控。工业过程数据的多模态、动态性特征将影响DPCA方法中T2和SPE的过程故障检测性能。
在进行故障检测之前,通常应用Z-score标准化方法对采样数据进行预处理。Z-score方法能够将数据的中心平移到坐标系原点且消除变量量纲不同的影响。由于Z-score标准化计算时使用的是全局的均值和标准差,所以在处理模态方差显著不同的多模态数据时,达不到消除多模态特征的目的。为了降低多模态结构对故障检测结果的影响,可以使用样本所在模态的均值和标准差进行数据标准化,但实际中很难确定数据集的模态信息,故文献[12-13]提出了局部近邻标准化的方法。
LNS方法首先确定原始数据训练集X中每个样本Xi的K近邻集n(Xi);接下来计算此近邻集的均值m(n(Xi))和标准差s(n(Xi));最后应用式(7)对样本Xi进行局部近邻标准化处理。
(7)
LNS方法在消除多模态数据中心差异的同时可以将数据处理为近似服从单模态多元高斯分布,这为后续的数据分析奠定了良好的基础。
为了提高DPCA方法对多模态、动态性过程的监控能力,本文提出一种LNS和DPCA相结合的故障检测方法LNS-DPCA,主要包含两个阶段:模型建立和在线检测。
2.1 模型建立
1)在训练集X中,查找每个样本Xi的K近邻集n(Xi),同时应用式(7)进行标准化处理;
2)在已标准化数据集X中,应用式(1)确定增广矩阵X(l);
3)应用式(2)将X(l)分解为主元子空间和残差子空间,并根据式(3)、(4)计算T2和SPE统计值;

2.2 在线监测
对于一个测试样本X*:
1)在训练集X中,查找X*的K近邻集n(X*),同时应用式(7)进行标准化处理;
2)应用式(1)确定X*增广向量X*(l);
3 数值例子
本章引用文献[9]中一个具有动态特性的数值例子对本文方法进行分析,同时与相关传统方法进行比较,以验证本文方法的有效性。主要模型如下:

(8)
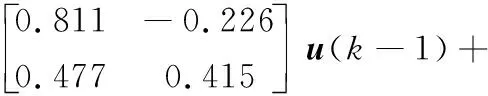

(9)
其中:u(k)为相关变量;o(k)为均值为0、方差为0.1的随机噪声;w(k)为引入的随机噪声。本例中通过上述模型产生两个模态数据,其中模态1的w(k)服从均值为[0,0]、方差为[1,1]的二元高斯分布;模态2的w(k)服从均值为[5,5]、方差为[6,6]的二元高斯分布。在本例中,两个模态各有1 000个训练样本用于模型建立,同时只有变量u和y用于过程监视。故障共有两类:故障1按模态1运行,从第500时刻起将w1设置为5;故障2按模态2运行,从第500时刻起将w1设置为-5。
本例中分别使用PCA、DPCA、KNN、LNS-DPCA进行故障检测。根据累计贡献率方法[14],确定PCA中主元数为2,DPCA和LNS-DPCA中主元数为7;由交叉验证方法[15],确定DPCA和LNS-DPCA中l为2;通过寻优测试,确定KNN中近邻K为3,LNS-DPCA中局部近邻K为30。以上方法均采用99%控制限对过程进行监控。
本例四种方法检测如图1~4所示。本实例数据为两个模态数据,不满足PCA中统计量T2和SPE的数据分布假设,因此检测率较低,如图1。图5为训练样本与故障1的前两个主元散点图,其中,PC表示主元。由图5(a)可以看出,在经过Z-score标准化处理后,DPCA得分在主元空间仍然具有多模态结构,这会影响传统DPCA的故障检测性能,因此如图2所示,DPCA在本例中的故障检测率较低。图3给出了KNN方法的检测结果,可以看出在KNN方法中两个正常模态样本D2统计值差异明显,统计量控制限完全由模态2决定,湮灭了模态1的数据特征,因此KNN方法对于本例来说故障检测率也不高。LNS-DPCA故障检测率远高于对比方法,与KNN算法相比,故障检测率提升了约70个百分点。由图4和图5(b)可知,LNS-DPCA的控制限由两个模态共同决定。本质上来说,LNS-DPCA具有较高故障检测率的原因是采用LNS方法消除了数据的多中心结构和模态方差差异较大的影响,将多模态数据转换为近似服从单一模态高斯分布数据,提高了DPCA对多模态、动态过程的故障检测性能。
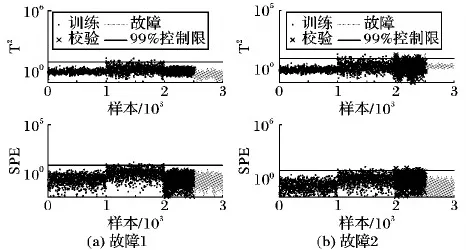
图1 PCA检测结果(数值模拟实例)

图2 DPCA检测结果(数值模拟实例)
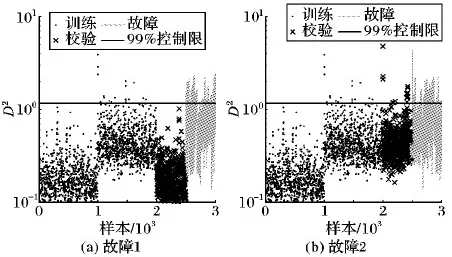
图3 KNN检测结果(数值模拟实例)

图4 LNS-DPCA检测结果(数值模拟实例)

图5 训练样本与故障1的前两个主元散点图
4 LNS-DPCA在青霉素发酵工业过程的应用
青霉素发酵过程是具有非线性、动态性、时序性的多阶段间歇工业过程,已经在故障检测与诊断领域被重点研究[16]。本章应用Pensim软件模拟生成训练数据和故障数据。此软件产生的青霉素数据共有17个变量,如表1。Pensim仿真平台可以在通风率、搅拌功率和底物流加速率上设置故障,故障扰动的类型有斜坡和阶跃两种,并可进一步设定两种扰动的幅度、扰动的引入时间和终止时间[17-18]。
建模过程中监测12个主要变量,分别是:通风率、搅拌功率、底物流加速率、底物流温度、底物浓度、溶解氧浓度、菌体浓度、青霉素浓度、二氧化碳浓度、pH 值、反应器温度、反应热。设定发酵时间为400 h,每隔0.5 h进行采样。在正常工况下使用系统默认参数生成1个批次作为训练样本进行建模。为验证本文方法有效性,在系统正常运行时引入两种不同类型故障,见图6。其中:故障1为在30~200 h,在变量通风率上引入0.2%的阶跃故障;故障2为在100~400 h,在变量底物流加速率引入幅度为0.01(单位为l/h)的斜坡故障。

表1 变量名称
本例中分别使用PCA、DPCA、KNN、LNS-DPCA进行故障检测。根据累计贡献率方法, PCA中主元数确定为2,DPCA和LNS-DPCA中主元数为7;由交叉验证方法,DPCA和LNS-DPCA中l为2;通过寻优测试,KNN中近邻K为3,LNS-DPCA中局部近邻K为10。以上方法均采用99%控制限对过程进行监控。

图6 故障散点图
由图7可以看出,LNS方法可以将多模态数据转化为单模态数据。由于PCA是一种线性建模方法且只适合单模态故障检测,而青霉素数据具有的多阶段特性不满足PCA中统计量T2和SPE的单模态高斯分布的假设,故检测率最低,见图8。DPCA虽然能够捕获样本的自相关性,但不能消除数据的多模态结构,因此在本例中的故障检测率较低。在模态过渡时变量间的相关关系不同,历时也不相同,这种不稳定性影响了最终检测结果。从图9(b)可知,SPE检测图从第1 500个样本开始检测到故障,比故障发生约延迟了250 h,这种延迟是由于溶解氧浓度、反应器体积和冷水流量对葡萄糖基质进料速率的影响,从而导致其缓慢传播。由图10所示的KNN方法检测结果可知,控制限由前100个样本决定,对于密集模态的小尺度故障检测困难,并且图10(b)显示故障2的检测也具有延时性,延时约200 h,故KNN的故障检测率也较低。由图7(b)可知,样本经过LNS处理后已成为近似服从高斯分布的单模态结构,为DPCA的检测奠定了基础,并且对于故障2的检测没有延迟,检测效果表现最优,如图11,表现出比对比方法更好的性能,进一步验证了本文方法的有效性。

图7 变量矩阵图

图8 PCA检测结果(工业模拟实例)

图9 DPCA检测结果(工业模拟实例)
5 结语
本文针对工业过程的多模态和动态特征提出了LNS和DPCA相结合的方法。首先使用局部近邻集的信息对数据进行标准化处理,有效消除数据多中心和方差差异显著的影响;再结合DPCA消除不同时刻样本的相关性,使得LNS-DPCA具有较高的故障检测率。
本文方法中的近邻数K是根据多次实验寻优测试确定的,因此K的确定方法是接下来的研究方向。

图10 KNN检测结果(工业模拟实例)
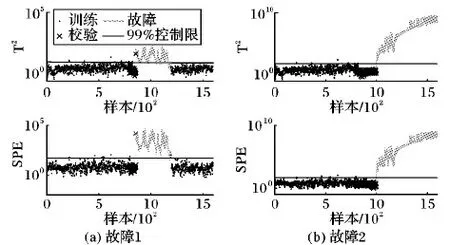
图11 LNS-DPCA检测结果(工业模拟实例)
