海事事故的聚类与关联规则
2018-10-16杨柏丞马建斌王哲凯陈红玉
杨柏丞, 马建斌, 王哲凯, 陈红玉
(大连海事大学 航海学院, 辽宁 大连 116026)
在船舶导航系统的智能化、船舶驾驶员的高素质化及各国海事主管机关的努力下,我国沿海海事事故整体呈逐年下降趋势。但部分海域由于航路复杂、船舶密集及自然环境恶劣等原因,保障海上航行安全仍是当前研究的热点问题。鉴于此,为找出海事事故的主要致因,减少船舶航行风险,国内外专家学者从不同角度对不同海域的交通事故进行了广泛研究,且取得的成果颇丰。当前主要的研究方法是对复杂海域进行安全评估,从人-船与货物-环境-管理等方面建立指标体系,并采用模糊理论、灰色关联及神经网络等算法,确定不同海域的风险等级,并识别出目标海域的主要风险,为驾驶员在操纵船舶过程中提供一定的指导和借鉴作用;但该类方法在指标体系的建立过程中由于存在较多的主观因素,且没有事故数据作为支撑,在精度和航海实践验证方面尚有不足[1-5]。
为更加全面寻找事故的潜在致因,验证海事事故信息与各致因之间的关联性,GOERLANDT等[6]对2007—2013年间冬季北波罗的海海域的自然环境与船舶事故进行数据可视化挖掘,分析船舶交通事故与海冰、气象及人为操作之间的关系,对冬季北波罗的海船舶航行安全风险进行识别。与国外相比,我国在海事事故信息统计方面起步较晚,刘正江等[7]调查国外近百起船舶碰撞事故报告,并提取各事故的致因,对人为因素及其诱发因素与碰撞事故进行关联挖掘,确定了船舶碰撞过程中人为失误与诱发因素之间的对应关系。张晓辉等[8-9]对中国沿海各辖区水上交通事故进行全因素关联挖掘试验,识别出碰撞风险是长三角水域最突出的风险。黄常海等[10]建立了关联规则模型和事故因素网络,在支持度为10%、置信度为70%的条件下提取了15条强关联规则,对轻微事故的关联因素进行详尽的分析。
在上述研究成果的基础上,考虑到各水域自然环境和交通环境都不尽相同,进一步有针对性地对特定海域的海事事故进行分析,同时,为了防止对事故数据进行全因素关联挖掘,导致弱化其他风险因子,影响挖掘精度,本文提出一种聚类分析与关联规则组合挖掘方法,以浙江海域的海事事故作为挖掘对象,通过对2008—2014年间824起海事事故进行分析,首先将事故进行聚类,然后对聚类完的数据进行深度挖掘试验,去除负关联规则并以提升度为规则再强化标准,提取出碰撞类事故8条强关联规则、非碰撞类事故12条强关联规则,以特定海域的丰富事故数据为素材,以更加严谨的算法试验和阈值设定,确保在自然环境相同的条件下对海事事故进行深度挖掘,进一步提升挖掘试验的精度。
1 海事事故挖掘流程
1.1 数据准备
数据准备主要包含数据收集、数据预处理、数据清洗以及数据变换等4个过程[11-12]。
1)在数据收集过程中采用调研方法来获取我国沿海各辖区海事事故数据。
2)对收集到的数据进行预处理是数据挖掘中的关键步骤,数据的质量也决定了挖掘的精度。以数据的质量和数量为参考,对各辖区事故数据进行整理和对比,最终筛选浙江辖区的事故数据作为挖掘试验的对象。
3)数据清洗主要指的是将事故数据进行统一化、标准化描述,清理残缺数据和无效数据,以便于机器识别并处理有效信息。
4)最终将描述性语言转化为数字或者字母,即可进行聚类与挖掘处理。
1.2 k-medoids聚类
为了实现对数据的深层次挖掘,首先对事故数据库进行聚类。从全局性和系统性出发,本数据库为完整封闭式数据库,因此采用基于划分的k-medoids聚类算法。k-medoids算法的聚类流程:
1)从n条事故数据中任选k个对象作为初始聚类中心。
2)根据每个聚类对象的均值(中心对象),计算每个对象到这些中心对象的距离;并根据最小距离重新对相应对象进行划分。
3)重新计算每个(有变化)聚类的均值(中心对象)。
4)算标准测度函数。当满足一定条件,如函数收敛时,则算法终止;如条件不满足则回到步骤2)。
k-medoids聚类通常采用误差平方和准则函数来评价聚类性能。
假定有混合样本X={X1,X2,…,Xn},采用某种相似性度量,X被聚类合成k个分离开的子集X1,X2,…,Xk,每个子集是一个类型,他们分别包含n1,n2,…,nk个样本。为了衡量聚类的质量,采用误差平方和Jk聚类准则函数,定义为
(1)

以事故数据库作为聚类对象,利用R语言进行k-medoids聚类,并以事故类型和事故致因作为聚类中心,引入PAM函数,对事故全集进行聚类。
1.3 关联规则
关联规则算法是对数据库中不同的事务集之间隐含的规律性进行识别和分析的方法,通常分为简单关联、时序关联和因果关联。
将聚类完成之后的数据库作为挖掘的基础数据库进行挖掘,定义事故数据库D={t1,t2,…,tk}和数据库中项集I={i1,i2,…,ik},那么关联规则是
A⟹B
(2)
式(2)中:A⊂I,B⊂I且A∩B=φ。
项集A′的支持度表示项集A在所有项集I中出现的次数为
Supp(A)=A/I=P(A)
(3)
那么关联规则A⟹B的置信度为
conf(A→B)=Supp(A∪B)/Supp(A)=P(B|A)
(4)
同理,关联规则A⟹B的提升度为
lift(A→B)=conf(A→B)/Supp(B)=
P(A∪B)/P(A)P(B)
(5)
式(5)中:提升度lift(A→B)=lift(B→A)。提升度的值反映了关联规则中A与B的相关性为
1)提升度>1且越高,表示正相关性越高。
2)提升度<1且越低,表示负相关性越高。
3)提升度=1,表示没有相关性。
由于关联规则的Apriori算法在设定支持度和置信度阈值时,往往与研究对象的数据样本大小和质量有关,国内外相关学者均通过不断探索支持度和置信度的阈值,最终获得合理且有效的关联规则,对算法结果的分析追求较高的支持度和置信度,却忽略提升度对规则的有效性衡量。因此,本文在分析取得的关联规则结果中,首先通过探索合适的支持度和置信度阈值,取得合理的强关联规则条数,再通过去除冗余规则以及负关联规则,最终获得有效的强关联规则。R语言相较于其他算法内置的软件在处理固定算法的细节上具有很大的灵活性,因此,通过R语言进行编程,可找出存在数据库中的频繁项集,此时通过设置最小支持度阈值和置信度阈值,执行剪枝过程,得到所需要的强关联规则。其流程见图1。
2 浙江水域海事事故挖掘
2.1 事故聚类分析
针对辖区的事故特征,以船舶吨位和事故类型为聚类中心,利用R语言实现对数据库的动态聚类。聚类结果显示:以事故类型进行聚类,该数据库被聚为两类,分别为碰撞类事故和非碰撞类事故。将事故聚类完成后,通过对各类之间进行关联,将聚类与关联进行可视化,生成以事故类型为导向的网络图和关联规则分布散点图。考虑到事故数据库样本容量以及挖掘试验的精度,将事故全集聚成两类,并得到两组聚类簇(见图2)。
2.2 海事事故信息网络分析
通过对浙江辖区海事事故数据库进行k-medoids聚类,最终获得碰撞事故有效数据179条。以事故类型为导向生成船舶碰撞事故信息属性网络见图3。考虑到事故的节点、链接数量以及图形的尺寸限制,最终根据支持度阈值与总数据样本的积作为链接阈值,既保留了频繁候选集,同时又能准确和直观地表达出各关联规则的强弱程度。
对数据库中碰撞类事故进行分析,取支持度阈值为20%,对生成的碰撞事故导向网络图进行分析可看出:导致碰撞类事故产生的一级致因中的人为因素与碰撞事故的关联性较强;人为因素中的二级致因中出现频率较高的因素有瞭望疏忽、未使用安全航速、能见度不良和避让行为不当等。
1)从事故发生海域来看,碰撞事故主要发生在沿海海域。
2)从事故船舶类型来看,渔船、砂石船和干杂货船是发生碰撞事故的主要船型。
3)从船舶吨位来看,小于3 000总吨的船舶更容易发生碰撞事故。
4)从时间序列进行分析,2000—2400时段是浙江辖区水域碰撞事故的多发时段。
5)从季节性规律进行分析,春季是发生碰撞事故的主要季节,占比达到40%以上,其次是夏季。
6)从碰撞事故导致的损失来看,大部分碰撞事故导致的经济损失均在100万元人民币以下。
3 挖掘试验与结果分析
3.1 挖掘试验
在对浙江辖区水域船舶交通事故关联规则进行分类挖掘中,生成了碰撞类事故关联规则474条、非碰撞类事故关联规则304条。以碰撞类事故为例,其全部关联规则分布散点见图4。
对支持度阈值和置信度阈值的调整,最终设定碰撞类事故的支持度阈值20%、置信度阈值50%的条件下,根据提升度进行排序,筛选出8条提升度>1.4的碰撞类事故关联规则。同理,按照提升度排序,在支持度阈值10%、置信度阈值50%的条件下提取出提升度>2.0的非碰撞类事故关联规则12条。鉴于篇幅限制,选取其中的13条关联规则进行分析(见表1)。
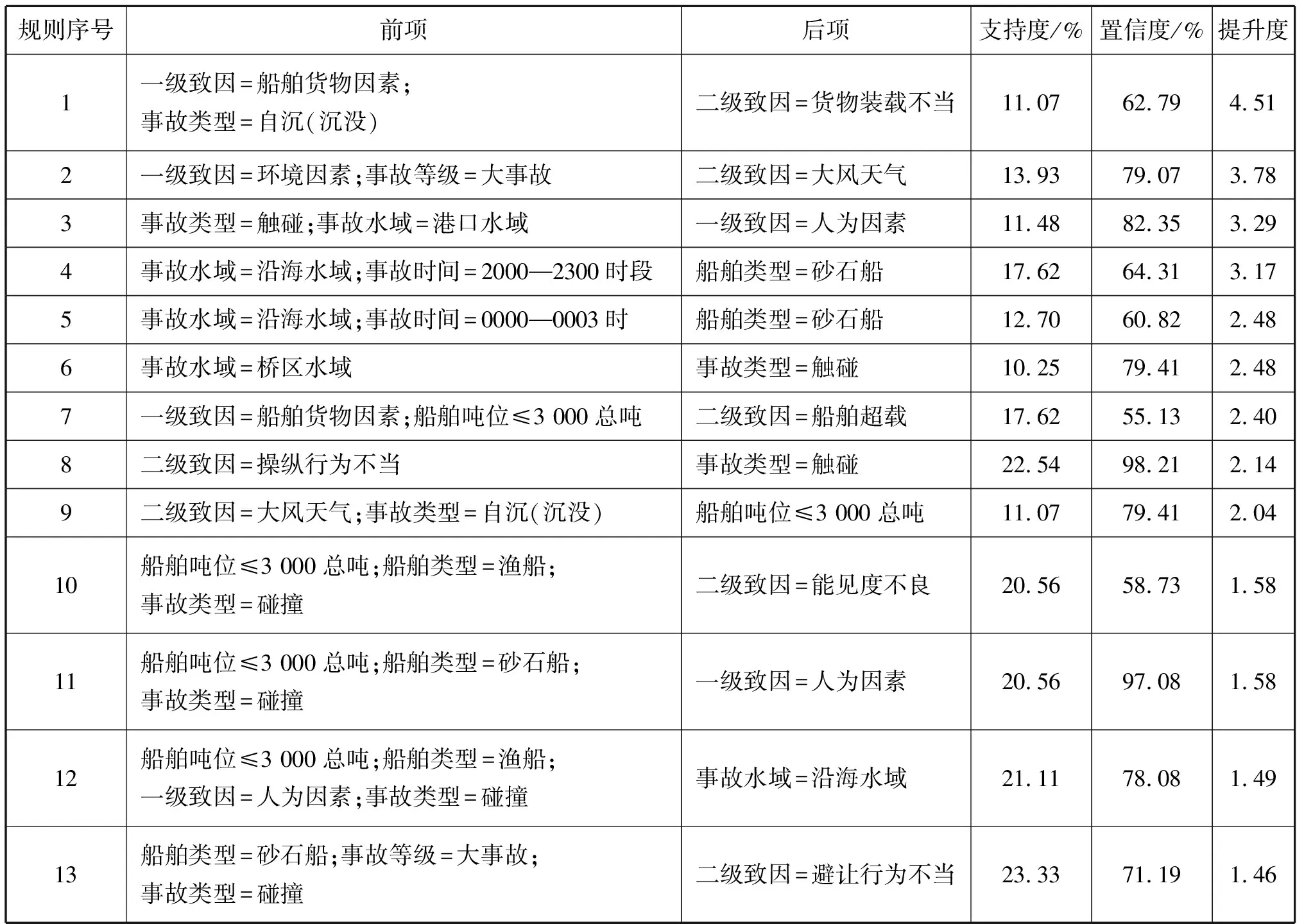
表1 浙江辖区海事事故关联规则
3.2 结果分析
在聚类基础上通过对浙江辖区海事事故进行分类和深度挖掘,不仅挖掘出了单一事故特征之间的映射关系,而且对多因素之间的潜在规律的识别也有较好的效果。通过此次挖掘试验得出的关联规则结果,可以得出:
1)浙江水域发生海事事故的主要船型为3 000总吨以下的船舶,且船舶超载、大风天气、能见度不良及人为因素是影响该类船舶发生海事事故的主要致因。
2)导致船舶发生自沉事故的船舶货物因素主要是由于货物装载不当引起的;当船舶吨位≤3 000总吨时,船舶有可能存在超载行为。
3)桥区水域和港口水域是碰撞事故的多发水域,该类事故发生的致因主要是操纵行为不当。
4)夜间2000—0400时段是砂石船事故的多发时间段,且事故主要发生在沿海水域。
5)大风天气下,辖区内≤3 000吨的船舶易发生沉没事故,且可能会导致大事故的发生。
3.3 建议与措施
根据以上交通事故的潜在规律,可对事故的属性、时间序列、事故致因和船舶类型等相互之间的关联性进行识别。对此,根据以上挖掘试验的结果分析,为进一步提高海上交通安全水平,对该海事及渔政部门提出建议如下:
1)鉴于沿海砂石船和渔船是该海域的高风险船舶,且由于渔船和部分私有船舶缺乏相应的检查监管,而导致部分船舶配员不足或船舶存在缺陷等安全隐患。因此,加强沿海小型船舶与渔船的监管、完善海上交通监督机制可有效减少事故的发生。
2)加强对沿海干杂货船、渔船、砂石船等小于3 000总吨的船舶进行监督,对部分船舶配员不足、存在缺陷、船舶老龄化以及船舶货物装载和超载等问题进行隐患排查,降低事故率。
3)雾季是全年事故的高发期,船舶驾驶员经常由于疏于瞭望导致事故发生。因此,督促航运公司制定相关的安全管理体系,并严格宣贯执行,提高船舶驾驶员雾航安全意识,可降低船舶在雾航中的碰撞风险。
4)加大夜间巡查力度,加重对于砂石运输船舶夜间非法运输的处罚力度,降低内河沿海干杂货船、渔船、砂石船的事故率。
5)加强大风天气和能见度不良环境下的船舶管控,合理对船舶进行组织与疏散,并在雾季和台风季节来临前,对船舶缺陷进行集中检查。
4 结束语
海事事故数据是海上交通安全与规划的重要资料,本文以数据挖掘中的关联规则算法为基础,结合聚类算法对浙江海域事故数据库分类挖掘,不仅掌握事故特征以及其潜在致因及时间地点的分布规律,还对海事主管机关在船舶监控与航道规划上具有借鉴作用,也为海事事故的预防提供指导性建议。本次挖掘使用的关联规则算法与聚类算法相结合,以浙江海域实际事故数据为研究对象,在研究中取得支持度与置信度阈值条件下,提高了关联规则算法的提升度,增强了算法的关联性和应用价值。
由于本次挖掘使用的数据库为调研所得的2008—2014年的事故数据,且仅以事故类型为聚类中心进行分析,给本次挖掘试验在普遍适用性上带来一定影响。在后续研究中可通过以事故致因作为聚类中心进行分析,并进行深度挖掘;同时建议建立互联网模式下的船舶交通事故标准化备案系统,对事故的自然环境、交通环境、事故特征、事故基础信息及事故致因信息等进行统一描述,以便对我国沿海海域海上交通安全重点水域及风险进行识别,对事故数据库进行标准化,为交通标准化提供参考,并提高后续的挖掘精度。
