面向NSM的高速公路大区段事故风险预测方法*
2018-10-12吴佩洁孟祥海崔洪海
吴佩洁 孟祥海▲ 崔洪海
(1.哈尔滨工业大学交通科学与工程学院 哈尔滨 150090;2.吉林省交通规划设计院 长春 130021)
0 引 言
针对高速公路上的交通事故,世界各国于20世纪90年代起便开始研究事故影响因素并建立事故预测模型[1-4],而后聚焦于事故风险预测模型[5-8]。事故预测模型侧重于研究事故发生频率,主要采用历史交通事故数据[9-11],而事故风险预测模型侧重于研究事故发生的可能性,主要采用实时交通流数据[12-15]。目前,事故风险预测方法主要有Logit模型[6,16]、贝叶斯网络模型[17-18]、Logistic回归模型[19-20]、支持向量机[21-22]等。
随着近年来中国高速公路事故黑点治理工作的不断加强与重视,高速公路基本路段上的事故数量明显下降,交通事故不再集中地分布于某一点,而是较均匀地分布于整个大区段的路段上。针对该现象,路网交通安全管理技术(network safety management, NSM)提供了有效的交通安全改善方法,以进一步减少大区段上交通事故的数量和严重性,从而提高整体道路网的交通安全性能。路网交通安全管理起源于欧洲,芬兰、瑞典等国早在20世纪60年代就用路网安全管理来代替传统的事故多发点安全管理(black spot management,BSM)[23]。2007年,挪威交通研究中心的Rune Elvik公布了2份研究报告,详细介绍了路网安全管理的最先进方法和最佳实践指南[24-25]。
路网交通安全管理的关注重点是长度为2~10 km的路段,属于中观层面的交通安全管理。与传统的交通事故黑点安全管理相比,路网交通安全管理具有预防性和主动性,评价的路段单元长度更长,且开展安全评价的工作周期一般为2~4年[23]。路网交通安全管理技术的实施步骤如下:对公路网进行大区段路段进行划分;对“同质性路段”(具有大致相似的交通量和其他特征的道路段)进行聚类分析;建立“同质性路段”的交通事故预测模型;识别“同质性路段”中的事故多发路段。该技术的核心是建立“同质性路段”的事故预测模型,对未来可能发生较多事故的路段进行识别。
虽然当前国内外的交通安全学者更加关注事故风险预测模型,但是针对大区段的事故风险预测和路网交通安全管理中“同质性道路”聚类与建模的研究较少[26]。基于此,笔者以我国高速公路大区段(平均长度约为12 km)为研究对象,针对路网交通安全管理的最优聚类方法与数量、最优事故预测模型等开展了研究工作。其目的和意义在于,探索路网交通安全管理技术在中国高速公路路网上应用的可行性,从而进一步提高路网交通安全水平,实现未来路网主动安全的管理。
1 数据描述
1.1 数据来源
数据来源于2014年辽宁省交通运输厅科技项目“高速公路运行安全研究”。结合上述科研课题,共收集到了辽宁省境内4条高速公路上2009—2013年5年的事故数据(共11 758起,均来源于高速公路路产部门)、交通流数据和道路线形数据。其中,交通流数据包括年平均日交通量、车辆平均运行速度、重型车比例,道路线形数据包括车道数、累积曲率和累积坡度。其中,累积曲率和累积坡度的计算公式见文献[26]。
1.2 数据组织
最初,共收集了辽宁省境内4条高速公路上71个大区段基本路段的各项指标数据。但由于沈大高速的4个路段和沈康高速的3个路段缺乏历年来的事故数据,因此将该7个路段剔除,对剩余的64个基本路段进行研究。笔者的研究对象为高速公路基本路段,因此,在数据使用时剔除了互通式立体交叉、服务区、收费站等的事故数据。另外,由于少部分路段缺少1年或2年的事故数据,因此,采用其余年份的事故平均值对空缺数据进行填补。所用到的事故数据、事故关联因素指标数据的数据汇总表,见表1。

表1 数据汇总表
注:表格中除事故总数的数据以外,其余的均表示各个指标的统计均值,其中,年平均日交通量表示的是2009—2013年5年的年均日交通量的平均值。
1.3 路段划分方法
根据我国高速公路上的天然节点,如收费站、互通式立交、服务区等,将高速公路网划分为平均长度为10~20 km的大区段路段。该种路段划分方法(又称“面向天然节点法”)属于静态划分法[26]。采用该方法得到辽宁省高速公路大区段划分的结果:将辽宁省境内4条总长度为853.27 km的高速公路划分为了64个路段,最小路段长度为0.82 km,最大路段长度为30.05 km,平均划分路段长度为12.02 km,标准方差为7.47。
2 基于二阶聚类方法同质性路段划分
2.1 二阶聚类方法
相较于常用的系统聚类和动态聚类,二阶聚类具有同时对类别变量和连续变量进行聚类的优点,并将整个聚类过程先后分为前后2个阶段完成。其主要思想是:对所有样本进行距离考察,构建CF分类特征数,同1个树节点内的样本相似度高,相似度差的样本则会生成新的节点,然后在分类数的基础上,使用凝聚法对节点进行分类,每个聚类结果使用贝叶斯信息量(BIC)或赤池信息量(AIC)进行判断,最终得出二阶聚类结果。本文采用二阶聚类,第一阶段采用高速公路的类别分类变量(沈大高速、沈山高速、沈康高速、沈丹高速),第二阶段采用年平均日交通量、车道数、累积曲率、累积坡度4项指标作为聚类指标。先对收集的数据进行标准化处理,然后得到二阶聚类分别聚类为2类、3类和4类的聚类结果。
2.2 同质性路段划分结果
本文的1个重要任务是确定“同质性路段”最优的聚类方法和聚类数量,因此,首先采用了系统聚类、k-means聚类和二阶聚类3种方法分别对64个大区段路段聚类为2类、3类和4类,得到这3种方法的“同质性路段”划分结果,见表2。
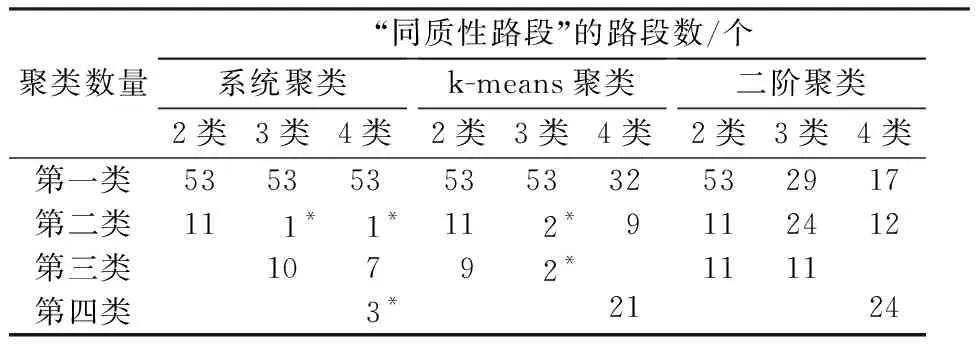
表2 3种聚类方法的“同质性路段”划分结果
注:带*的数字表示由于聚类路段数太少而不能建模,须排除该种聚类方法和聚类数量。
由表2可见,在该路段样本中,相较于系统聚类和k-means聚类,二阶聚类表现出更加优良的分类效果,能保证每个“同质性路段”拥有较多的路段样本数,而不会出现少量路段聚类的特殊情况。
2.3 最优聚类方法和最优聚类数量的选择
针对如何确定“同质性路段”最优聚类方法和最优聚类数量的问题,本文采用传统的负二项回归模型对不同聚类方法和不同聚类数量下的“同质性路段”建模。解释变量为车辆平均运行速度、重型车比例、车道数、累积曲率和累积坡度5个指标,事故暴露值取年平均日交通量与路段长度的乘积(见式2),分别对2009—2011年每年的事故数据进行拟合,采用3年平均模型拟合精度的赤池信息量(AIC)、贝叶斯信息量(BIC)和均方误差(MSE)3个指标进行评价,得到3种聚类方法分别聚类为2类、3类和4类的“同质性路段”模型拟合精度对比,模型精度最高的聚类方法和聚类数量则为最优聚类结果,见图1。

图1 “同质性路段”的负二项回归模型精度对比Fig.1 Contrast between negative binomial model ofhomogeneous road segments
由图1可见,当聚类数量为1(未聚类)和聚类数量为2时,3种聚类方法的聚类结果相同,模型拟合精度相同,但随着聚类数量的增大,3种聚类方法的模型拟合精度开始出现差异;当采用二阶聚类法划分为3类“同质性路段”时,负二项回归的模型精度最高,其模型的AIC值为464.79,BIC值为476.98,均方方差MSE值为99.22,因此,在该数据集中,采用二阶聚类方法,聚类数量为3时达到最优聚类质量。以2009年为例,采用二阶聚类的第一类“同质性路段” 负二项分布参数λ=40.06,α=0.05,第二类“同质性路段”负二项分布参数λ=41.56,α=0.10,第三类“同质性路段” 负二项分布参数λ=26.79,α=0.04,且均通过卡方拟合优度检验。相较于未对路段进行聚类的情况,选择最优聚类方法和最优聚类数量将降低其AIC值的8.45%,BIC值的8.76%和MSE值的64.00 %。
3 同质性路段的的交通事故预测模型
3.1 传统的负二项回归
目前,世界各国普遍采用负二项模型来构建事故预测模型,因为事故数据往往具有方差远大于均值的特点。假设每个大区段路段的事故数量符合负二项分布,则发生事故的概率为
P(Yi=yi)=Negbin(λ,α)=
(1)
式中:yi为路段i上发生的事故起数,Γ(·)为伽马函数;λ,α为负二项分布的参数,其中,λ也就是平均事故起数,α是事故数据的过度离散参数。笔者所用的负二项分布变形后的函数形式为
λ=(AADTi·Li)·exp(β0+β1vi+
β2ri+β3ni+β4Cumci+β5Cumsi)
(2)
式中:AADTi为路段i上的年平均日交通量;vi为路段i上的车辆平均运行速度;ri为路段i上的重型车比例;ni为路段i上的车道数;Cumci为路段i上的累积曲率;Cumsi为路段i上的累积坡度;β0,β1,β2,β3,β4,β5为负二项模型拟合的参数。通过采用STATA软件进行参数拟合和模型求解,采用最大似然法估计参数,得到在最优聚类方法和最优聚类数量(二阶聚类,聚类数量为3)下的模型拟合参数和拟合优度检验结果。
3.2 贝叶斯负二项回归
贝叶斯负二项是指在负二项回归的基础上,加上贝叶斯参数估计的方法。相较于传统的负二项回归模型,贝叶斯负二项回归将模型拟合参数β0,β1,β2,β3,β4,β5,α不再视为固定值,而是将其视为具有某种先验分布的随机变量。
本文采用MCMC法中的Metropolis-Hastings算法对贝叶斯负二项回归的参数进行抽样,分别采用3种不同的先验分布进行贝叶斯建模。这3种不同的先验假设为:①假设负二项回归参数服从正态分布;②负二项回归参数服从均匀分布;③负二项回归参数服从拉普拉斯分布(在这3种先验分布中,同时假设过离散参数的对数服从正态分布)。通过采用STATA软件进行参数拟合和模型求解,得到的3种先验分布情况下的最优聚类结果下(二阶聚类,聚类数量为3类)的参数估计与模型拟合优度检验结果。由于传统的AIC和BIC指标会忽略先验分布或认为先验分布为无信息先验,因此推荐使用DIC准则作为贝叶斯模型之间的评价指标,从而本文采用DIC和MSE来评估贝叶斯模型拟合精度的高低。
3.3 具有随机或固定效应的负二项回归
所用的数据同时具有截面(路段编号)和时间(年份)2个维度,因此,属于面板数据。通常情况下,面板数据可以采用固定效应模型或随机效应模型进行分析,以解决遗漏变量的常见问题。遗漏变量是由于不可观测的个体差异所造成的,当路段个体特征与解释变量相关时,被称为“固定效应模型”,当路段个体特征与所有解释变量都不相关时,被称为“随机效应模型”(随机效应负二项的模型见式(3)~(5))。
yi|λ=Poisson(λ)
(3)
λ|α~Gamma(γ,α)
(4)
(5)
式中:λ为平均事故数;γ,α为伽马分布的参数;r,s为贝塔分布的参数。
采用STATA软件对最优聚类结果下(二阶聚类,聚类数量为3)的具有随机效应模型和固定效应(假设随机效应服从Beta(r,s)分布,原有的解释变量上再增加年份指标)的负二项回归模型进行参数拟合,得到随机效应和固定效应的负二项回归结果。
3.4 多层混合效应负二项回归
对于具有结构层次分明、随机与固定影响因素不明确的数据,可以采用多层负二项回归混合效应模型进行建模。前半部分讨论了最优聚类方法和最优聚类数量的选择,得到了二阶聚类法的“同质性路段”的划分结果,因此,聚类后的数据具有结构化的特点,适用于多层混合效应负二项回归的前提条件。在多层混合效应负二项回归中,考虑了不同类别数据之间的随机变量因素和固定变量因素对模型结果的影响,该模型的公式为
yij|λij~Poisson(λij)
(6)
λij|uj~Gamma(rij,pij)
(7)
uj~N(0,∑)
(8)
式中:yij为第j类的i个事故数,i=1,2,…,nj;j=1,2,…,M;uj为随机效应;λij为平均事故数;rij,pij为伽马分布的参数;∑为均值为0,方差为q×q的矩阵。
采用STATA软件对最优聚类结果下的多层混合效应负二项回归进行建模,分别采用2层混合效应负二项回归和3层混合效应负二项回归的方法。在前者中仅考虑不同聚类路段之间存在正态分布的随机效应,在后者中同时考虑了不同年份和不同聚类路段之间同时存在正态分布的随机效应,得到2层混合效应负2项回归模型和3层混合效应负二项回归模型的拟合结果和拟合优度结果。
3.5 最优交通事故预测模型的选择
分别采用负二项回归、贝叶斯负二项回归、具有随机或固定效应的负二项回归、多层混合效应负二项回归4种不同的模型对最优聚类结果下(二阶聚类,聚类数量为3)的“同质性路段”进行建模,得到3年平均的模型拟合优度对比,见表3。
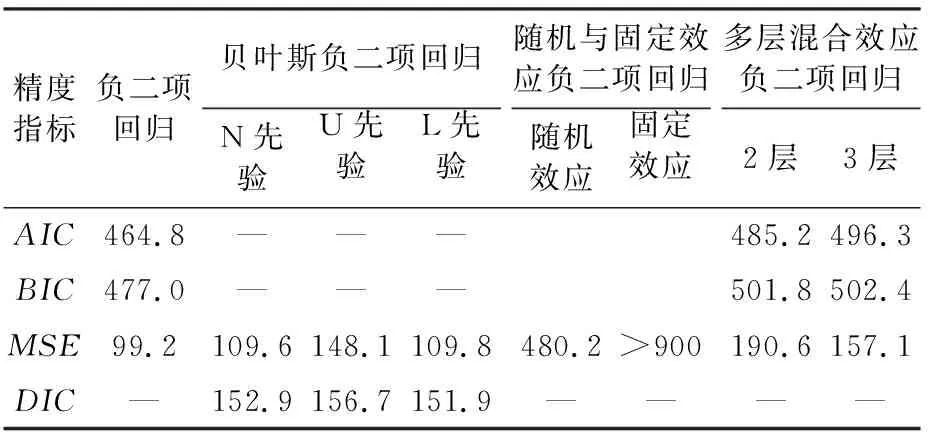
表3 4种不同拟合模型的3年平均拟合优度对比
注:表中“—”表示空缺值,因为贝叶斯模型不能采用AIC和BIC准则进行评价,而采用DIC准则进行评价。N先验表示具有正态分布的先验概率,U先验表示具有均匀分布的先验概率,L先验表示具有拉普拉斯分布的先验概率。
由表3可见,传统的负二项回归模型AIC值、BIC值和MSE值均最低,分别为464.8,477.0和99.2,这意味着该模型的拟合效果最优,其次是具有正态先验和拉普拉斯先验的贝叶斯负二项回归模型。而在3种贝叶斯负二项模型中,具有正态先验的贝叶斯模型比均匀先验分布的模型拟合精度更高。多层混合效应负二项回归中的3层模型比2层模型的拟合精度更高,随机与固定效应负二项回归的拟合精度最低。总体而言:在“同质性路段”的事故预测拟合精度上,传统的负二项回归最优,其次分别是贝叶斯负二项回归、多层混合效应负二项回归和随机与固定效应负二项回归。
3.6 最优拟合模型的预测精度检验
为进一步验证传统的负二项回归预测性能的优劣,采用该模型分别对2012和2013年的事故进行预测,见图2。
由图2可见,传统的负二项回归模型在2012年和2013年的预测精度均较高,但2012年的模型预测精度较2013年模型预测精度更高一些。在最优聚类情况(二阶聚类,聚类数量为3)下,2012年负二项回归模型的MSE值为104.54,平均误差为26.81%;2013年负二项回归模型的MSE值为108.64,平均误差为27.47%。另外,某些路段的预测值与实际值相差较大,其原因可能是来自于驾驶员危险行为、异常天气状况等其他因素和随机事件导致的,因此建议管理部门需对这些路段进行实地考察与事故原因分析。
4 未来交通事故多发路段的识别与风险预测
由于“路网交通安全管理”的最终目的是识别未来年份的事故多发路段,因此可考虑从统计学的角度出发,计算每一类“同质性路段”交通事故多发路段的上限值,计算公式为
(9)

通过采用该种识别未来交通事故多发路段的方法,得到辽宁省境内64个大区段路段中的22个事故多发路段结果,并采用事故风险理论的公式(见式(10))预测2013年事故多发路段的事故风险大小,最终识别结果和事故风险计算结果见表4。
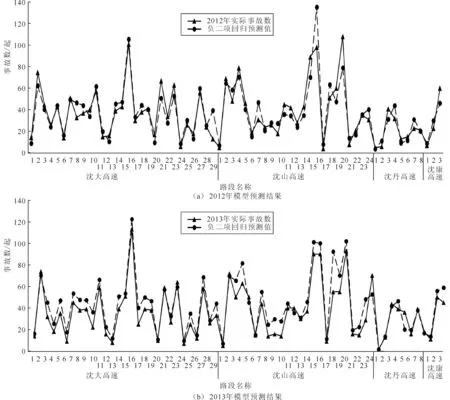
图2 负二项回归预测事故数与实际事故数对比Fig.2 Comparison between predicted crash number of binomialnegative regression and actual crash number
(10)
式中:Risk为路段事故风险值;N为预测事故数;O为事故机会数;当在基本路段上时,事故机会数为通过路段的交通量;AADT为年平均日交通量。
由4表可知,第1类“同质性路段”的2013年事故多发路段有9个,第2类“同质性路段”的2013年事故多发路段有8个,第3类“同质性路段”的2013年事故多发路段有5个,事故多发路段占总路段数的34.37%。其中,第1类和第2类中的事故多发路段的事故风险普遍较低,平均值为3.729和3.326,而第3类中的事故多发路段的事故风险最高,平均值为22.694,说明第3类“同质性路段”的未来安全状况需要引起交通管理部门的重视。由于第3类“同质性路段”的负二项回归模型中重型车比例和累积坡度2项指标的系数较为显著,说明该类路段的重型车比例偏高和连续坡度的变化导致路段事故隐患增大,相关部门须对这些事故多发路段实施交通安全改善措施,如增加避险车道、实施区段限速和增加交通安全诱导标志等。

表4 辽宁省路网中未来事故多发路段汇总表
注:带*表示采用2013年的年均日交通量AADT。
5 结 论
1) 在高速公路基本路段上按照“面向天然节点法”划分的平均长度在12 km的大区段,每年发生的事故起数服从负二项分布或泊松分布。
2) 对“同质性路段”进行划分时,采用不同的聚类方法和聚类数量将会对后面事故预测模型的精度产生较大的影响。在本文的64个大区段路段中,相较于系统聚类和k-means动态聚类,二阶聚类的聚类质量更好,且当聚类数量为3类时,“同质性路段”聚类质量最优。
3) “同质性路段”的4种事故预测模型中,传统的负二项回归模型拟合精度最高,其次分别是贝叶斯负二项、多层混合效应负二项回归和随机与固定效应负二项回归,并且传统的负二项回归模型预测精度最高。
4) 识别路网中的事故多发路段时,宜在同一类“同质性路段”中识别出统计学上显著的路段作为未来事故多发路段。
5) 由于收集的数据有限,因此,未考虑路网交通安全管理中事故严重程度对路段事故风险的影响,另外高速公路大区段数量较少,未来研究可从这2个方面进行进一步的完善。
