基于深度迁移学习的视频描述方法研究*
2018-10-11张丽红曹刘彬
张丽红, 曹刘彬
(山西大学 物理电子工程学院, 山西 太原 030006)
0 引 言
视频描述与图像描述有很大的不同, 视频描述不仅要理解每一帧中的物体, 而且要理解物体在多帧之间的运动. 现有的视频描述方法主要有4类: ① 将视觉内容中检测到的单词分配给每个句子片段, 然后利用预定义的语言模板去生成视频描述. 这类方法非常依赖句子模板, 生成的句子的句法结构比较固定[1]; ② 学习视觉内容与文本句子构成的联合空间的概率分布, 生成的句子具有更加灵活的句法结构[2]; ③ 利用多示例学习去训练属性探测器, 然后通过一个基于属性探测器输出的最大熵语言模型去生成视频描述[3]; ④ 以卷积神经网络与循环神经网络为中心, 通过一个简单的线性迁移单元, 把从图像与帧流中挖掘到的语义特征整合在一起, 生成视频描述[4]. 前两类方法在视频描述过程中并未利用语义特征; 后两类方法虽然在输入端均考虑到了语义特征, 但并未将不同域中的语义特征进行深度融合. 因此, 本文利用迁移学习中的深度域适应方法, 更好地融合图像与帧流两个域中的语义特征, 进而提高视频描述性能.
1 视频表示
构建视频描述模型, 首先要将输入视频表示为固定维度的向量. 为此, 本文采用VGG19模型[5]完成视频表示的任务. VGG19模型共有19层, 其中, 卷积层为16层, 全连接层为3层, 中间部分为池化层, 最后一层为softmax层. 对于视频中的一组采样帧, 将每一帧均输入到VGG19中, 提取第二个全连接层(fc7层)的输出. 然后, 在所有的采样帧上执行均值池化, 这样就把一段视频表示为一个4096维向量. 这一过程的具体模型结构如图 1 所示.

图 1 视频表示模型结构Fig.1 The model structure of video representation
2 融合语义特征
语义特征对视频描述起着非常重要的作用, 图像中的语义特征描述静态目标与场景, 帧流中的语义特征则表达了更多的时间动态. 因此, 提高视频描述准确率的关键在于如何将这两个域中的语义特征进行融合, 并将之用于增强视频描述. 本文将图像与帧流中挖掘到的互补的语义特征进行深度融合, 提升视频描述模型的性能.
2.1 图像语义特征
为了提取图像域中的语义特征, 本文在图像描述标准数据库上采用多示例学习[6]去训练语义特征检测模型, 具体模型结构如图 2 所示.
图 2 中模型的具体工作过程为: 对于一个语义特征wa, 如果wa存在于图像I的标注文本描述中, 那么图像I将被视为一个正包; 否则, 图像I将被视为一个负包. 首先将每个包输入到图 2 所示的模型中, 然后根据包中所有区域(示例)的概率来计算包含语义特征wa的包bI的概率, 如式(1)所示
(1)
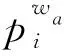

图 2 图像语义特征检测模型Fig.2 Image semantic feature detection model
2.2 帧流语义特征
目前存在的提取帧流语义特征的方法主要有: ① 直接将帧流进行分解, 把其中的每一帧作为训练样本, 训练图像语义特征检测模型. 考虑到帧流由一系列变化很大的视频帧构成, 因此这样简单地为帧流中的采样帧分配视频级的描述将会导致语义转换问题, 并且会在语义特征学习过程中出现明显的噪声; ② 在图像语义特征检测模型的基础上, 并行设计一个帧流语义特征检测模型去学习帧流中的语义特征[4]. 这种方法的缺点是: 对于图像与帧流两个域中语义特征的融合效果不理想. 因此, 本文利用迁移学习中的深度域适应[8]方法, 将图 2 中训练好的模型迁移到帧流数据集上, 提取帧流语义特征, 同时实现两个域中语义特征的深度融合, 得到新的语义特征检测模型, 具体结构如图 3 所示.

图 3 改进的语义特征检测模型Fig.3 Improved semantic feature detection model
在此模型中, 图像样本构成的域称为源域, 帧流样本构成的域称为目标域. 该模型的最终目标是: 对于目标域的分布, 给定输入x, 能够预测语义特征y. 此外, 在训练过程中, 对于每个输入x, 除了要预测语义特征外, 还需预测域标签d. 若d=0, 则x来自源域; 若d=1, 则x来自目标域. 图 3 中的模型可以分解为3个部分, 具体工作过程为: 首先, 通过映射Gf将输入x映射为一个D维特征向量f∈RD, 映射的参数向量为θf; 然后, 通过映射Gf将特征向量f映射为语义特征y, 映射的参数向量为θy; 最后, 通过映射Gd将特征向量f映射为域标签d, 映射的参数向量为θd.
在训练阶段, 模型的第一个目标是在源域上最小化特征预测损失, 确保语义特征检测模型在源域上不失真. 然后, 在此基础上使得特征f保持域不变, 即使得在源域上通过映射Gf提取的特征Sf与目标域上提取的特征Tf相似, 进而使得在目标域上的语义特征预测像源域上一样准确. 解决这个问题的关键是度量分布Sf与Tf的相似性, 深度域适应方法通过观察域分类器Gd的损失来估计相似性. 具体来说, 通过寻找合适的特征映射参数θf, 获得域不变的特征, 使得这两个特征分布尽可能相似, 以此来最大化域分类器的损失. 同时, 寻找域分类器的参数θd, 使域分类器的损失最小化. 这里利用了对抗式网络的思想[9]. 另外, 寻找合适的参数θy, 使语义特征预测器的损失最小化. 满足要求的3个参数构成一个点(θf,θy,θd), 称为鞍点. 整个训练过程可以表示为

(2)

(3)

(4)
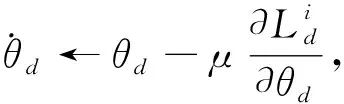
(5)
式中:μ是学习率, 更新过程式(3)~式(5)与随机梯度下降(Stochastic gradient descent, 简称SGD)的更新过程相似, 不同点在于式(3)中的λ因子. 引入λ因子是为了得到域不变的特征. 因此式(3)~式(5)无法像SGD那样直接执行, 需要将式(3)~式(5)简化为某种形式的SGD. 本文通过引入一个梯度反向层(Gradient reversal layer, 简称GRL)来完成这样的简化. 在反向传播期间, GRL从下一层取得梯度, 将这个梯度乘以-λ, 并将其传递到前一层. 将GRL插入到特征提取器和域分类器之间, 构成图 3 所示的模型结构. 因此, 在得到的模型中运行SGD实现了式(3)~式(5)的更新过程, 并且收敛到式(2)的一个鞍点, 得到域不变的特征向量. 训练完成之后, 利用语义特征预测器去预测来自目标域以及源域样本的语义特征. 由于Sf与Tf为两个域不变的特征向量, 因此由它们映射得到的图像域与帧流域上的语义特征也保留了域不变的特性, 即两个域上提取到的语义特征实现了深度融合. 因此, 利用改进的语义特征检测模型得到的语义特征可直接作为视频描述框架的输入, 并将该语义特征记为Aiv.
3 视频描述框架
图 4 即为本文设计的深度迁移学习视频描述框架, 整个框架的工作流程包括:
1) 利用图 1 所示模型得到给定视频的向量表示, 仅在初始时刻将其输入到递归神经网络(Long Short Term Mermory network, 简称LSTM)的第一层;
2) 在图像数据集上训练图 2 所示的模型;
3) 将给定的视频帧拆分为单独的图像, 依次输入到改进的语义特征检测模型中(图3);
4) 将给定的视频帧视为帧流, 并行输入到改进的语义特征检测模型中;
5) 利用改进的语义特征检测模型得到融合语义特征, 如“Man”, “Person”等的向量表示, 并将其输入到LSTM的第二层;
6) 将给定视频的英文描述逐词输入到LSTM的第一层, 结合上述4个步骤中的输入, 利用当前时刻以及之前时刻的输入单词去预测下一时刻的输出单词, 以此来训练视频描述框架.

图 4 视频描述框架结构Fig.4 Video description framework structure
整个框架的参数化表示如式(6), 式(7)所示.
E(v,Aiv,S)=-logP(S|v,Aiv),
(6)
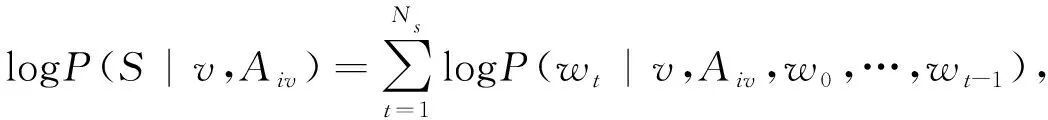
(7)
式中:v为输入视频;Aiv为融合语义特征;S为句子描述;E为能量损失函数;wt为单词表示;Ns为句子中单词的数量. 最终的目标是最小化能量损失函数, 保留句子中单词之间的上下文关系.
框架中, 仅在t=-1时刻将视频v输入到第一层LSTM单元中, 然后将Aiv作为额外的输入, 在每次迭代中均输入到第二层LSTM单元, 以此来强化语义信息. 如式(8)~式(10)所示,t从0到Ns-1进行迭代.
x-1=f1(Tvv)+Aiv,
(8)
xt=f1(Tswt)+Aiv,
(9)
ht=f2(xt),
(10)
式中:Tv∈RDe×Dv与Ts∈RDe×Dw分别是视频v的变换矩阵与wt的变换矩阵;De是LSTM输入的维度;Dv是视频v的维度;Dw是wt的维度.xt与ht分别是第二层LSTM单元的输入与输出,f1与f2分别是第一层与第二层LSTM单元内的映射函数.
4 实验及结果分析
4.1 数据集
为了评价本文设计的视频描述模型, 选用YouTube上最流行的微软视频描述数据集(Microsoft Video Description Dataset, MSVD). MSVD包含从YouTube上收集到的1 970个视频片段. 每个视频约有40个可用的英语描述. 在实验中, 采用1 200个视频进行训练, 100个视频进行验证, 670个视频进行测试[10]. 此外, 还用到了图像数据集COCO.
4.2 评价指标
为了定量评价提出的视频描述框架, 本文采用了视频描述任务中常用的3个指标: BLEU@N(BiLingual Evaluation Understudy), METEOR以及CIDEr-D(Consensus-based Image Description Evaluation). 对于BLEU@N指标, N取3, 4. 利用由微软Coco评价服务发布的代码来计算所有的指标[11]. 这3种指标的计算结果均为百分数, 得分越高表示生成的视频描述越接近参考描述.
4.3 实验设置
本文对每个视频均匀取样25帧, 并且将句子中每个单词表示为“one-hot”向量; 对于视频表示, 在Imagenet ILSVRC12数据集上对VGG19进行预训练, 然后在MSVD上对图 1 所示的模型进行微调; 为了表示从两个域中提取到的融合语义特征, 分别在COCO图像数据集以及MSVD视频数据集上挑选1 000个最常用的单词作为两个域的标注语义特征[4], 即为图 2 与图 3 两个模型的训练数据集. 首先在COCO训练集上对图2模型进行训练, 然后在COCO与MSVD两个训练集上对图 3 模型进行训练, 产生最终的1000维概率向量; 在LSTM中, 输入以及隐含层的维度均设置为1 024. 在测试阶段, 采用Beam Search搜索策略[12], 利用图 4 中训练好的模型生成新的视频句子描述, 并且将beam size设置为4.
4.4 结果分析
4.4.1 定量分析
表 1 展示了在MSVD测试数据集上, 本文提出的视频描述模型与现有的7种模型在各个评价指标上的得分对比情况. 不同配置的机器所得仿真结果均不相同, 表 1 中所列数据均以同一台机器为参考.

表 1 各个模型的得分对比
表 1 中模型1-4利用了基于注意力的方法, 未引入语义特征; 模型5, 6仅利用了单一域的语义特征; 模型7利用了两个域的语义特征, 并将其进行了简单的线性融合. 对比分析表 1 中数据可以看到: 在4项评价指标上, 本文提出的视频描述模型均获得了更高的分数, 由此得出结论: ① 在视频描述框架中, 利用高级语义特征可以增强视觉表示, 有利于模型学习视频描述; ② 仅利用单一域(图像域或帧流域)的语义特征, 对视频的描述性能没有明显提高; ③ 仅对两个域中语义特征进行简单线性融合, 虽然提升了视频描述的各项指标, 但仍存在不足, 需要改进; ④ 利用迁移学习中的深度域适应方法得到的融合语义特征显著提高了视频描述性能, 即本文方法在语义特征融合方面具有更好的效果.
4.4.2 定性分析
图 5 展示了本文提出的视频描述模型在测试数据集上的部分结果.

图 5 MSVD测试数据集上的视频描述结果Fig.5 Video description results on MSVD test data set
图 5 中示例的样本帧均为每个测试视频的部分帧, 通过这些示例可以看出: 与性能较好的LSTM-TSAIV模型相比较, 本文提出的视频描述框架能够更加准确地生成测试视频的英文描述.
5 结束语
本文以现有的视频描述框架为基础, 构建了一个新的视频描述模型. 此模型利用迁移学习中的深度域适应方法, 对输入端不同域中的语义特征进行深度融合, 以提高生成视频描述的准确率. 在MSVD视频数据集上进行实验, 验证了本文方法的可行性与有效性, 并表明利用深度域适应方法能够更好地实现不同域中语义特征的融合, 进一步提高了视频描述的准确率, 提高了网络的泛化能力.
