基于CPSO-LSSVM的汽轮机热耗率软测量模型
2018-09-27王莉莉陈国彬李一龙牛培峰
王莉莉, 陈国彬, 李一龙, 刘 超, 牛培峰
(1. 重庆工商大学融智学院, 大数据研究所, 重庆 400033; 2. 江西工程学院, 江西新余 338000;3. 燕山大学 工业计算机控制工程河北省重点实验室, 河北秦皇岛 066004)
我国火电机组的结构性矛盾日益突出,超临界机组被要求深度调峰,汽轮机额定运行时间越来越少,低负荷变工况运行明显降低了机组的热经济性。火电机组的优化运行、节能降耗已成为企业生存的客观需要,以汽轮机组为核心,通过降低热耗来提高机组热经济性的优化运行研究是我国火电企业面临的亟待解决的难题之一[1-2]。
热耗率是指发电机组每产生1 kW·h电量所消耗的热量,现在通常把热耗率作为研究和衡量电厂热经济性的重要指标[3]。由于汽轮机热耗率与其影响因素之间存在复杂的非线性关系,传统的建模方法无法建立起精确的数学模型,导致模型的热耗率产生偏差。目前可采用回归算法计算热耗率值。张文琴等[4]提出基于偏最小二乘算法进行热耗率回归分析,建立了热耗率预测模型。牛培峰等[5]采用磷虾群算法(OAKH)和快速学习网(FLN)进行热耗率综合建模。朱誉等[6]提出基于BP神经网络的汽轮机热耗率在线计算方法,该模型具有较高的准确性和稳定性。然而,常规的神经网络存在迭代训练时间长,计算量大,训练速度慢,泛化能力较差且易陷入局部极小点等不足。
Niu等[7]采用基于支持向量机(SVM)的汽轮机热耗率进行建模。SVM可解决样本数较少且输入空间维度较低的问题。最小二乘支持向量机(Least Square Support Vector Machine, LSSVM)[8]是支持向量机的变体,适合解决小样本、高维数复杂问题。基于此,笔者提出采用LSSVM模型预测汽轮机热耗率。由于LSSVM的预测精度和泛化能力受模型的超参数影响,因此采用混沌镜像粒子群算法(Chaos Particle Swarm Optimization, CPSO)来优化选择模型超参数,在此基础上提出了CPSO-LSSVM的热耗率软测量模型。并以某电厂600 MW机组的运行数据为基础进行热耗率仿真预测,验证该模型的有效性和优越性。
1 改进的粒子群算法
1.1 基本粒子群算法
粒子群算法(Particle Swarm Optimization, PSO)的基本思路是对飞鸟的捕食过程进行模拟,每个粒子在解空间中进行运动,记录各个粒子搜索到的最优点和所有粒子搜索到的全局最优点,粒子根据自身最优点及全局最优点不断更新自己的速度和位置[9]。
假设在D维搜索空间中,粒子群的种群大小为N,第i个粒子的位置为xi=[xi1,xi2,…,xiD],飞行的速度为vi=[vi1,vi2,…,viD]。在进行第t次迭代时,粒子自身的历史最优位置为pbest,全局粒子最优位置为gbest。PSO算法的主要步骤如下。
(1) 按式(1)随机产生初始种群:
xij=Lj+rand(0,1)(Uj-Lj)
(1)
式中:xij为第i个粒子xi的第j维元素;Uj、Lj为PSO搜索空间的上、下界。
(2) 计算各粒子的适应度值:
(2)
其中,f(xi)为粒子xi的目标函数值。
(3) 更新粒子速度和位置:
(3)
(4)
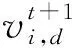
1.2 变空间Logistic混沌搜索策略
1.2.1 Logistic混沌搜索策略
PSO在处理复杂函数优化问题的后期往往容易陷入局部最优解。混沌是一种非线性映射,具有相空间的遍历性和内在的随机性,结合混沌变量进行优化搜索能有效跳出局部最优,实现全局优化。Huang等[10]利用混沌优化搜索很好地解决了CEC2013复杂函数优化问题;Zhang等[11]将逻辑自映射混沌优化搜索引入PSO算法,有效解决了算法难以跳出局部最优的问题。李方伟等[12]采用Logistic混沌搜索对每一代种群的精英个体和种群差异度中心进行混沌搜索,有效避免了差分进化算法陷入局部最优。
针对PSO处理复杂函数优化问题会陷入局部最优的不足,采用Logistic混沌搜索对PSO每一代种群的最优个体(精英个体)进行M次搜索,如果搜索到更优个体则进行取代以改善PSO的全局搜索能力。Logistic混沌映射模型定义如下:
Zt+1=μZt(1-Zt),
Zt∈(0,1),t=0,1,…,M-1
(5)
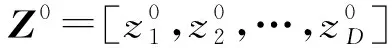
假设PSO种群中最优个体为Xi,在可行域内混沌优化过程为:
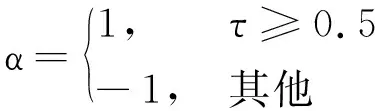
(6)

1.2.2 变空间Logistic混沌搜索策略
Logistic混沌搜索以PSO每代种群中最优解为基础产生混沌序列,搜索范围较大,当PSO算法陷入局部最优,很难搜索到更优解,或者是搜索到更优解花费的时间较长,降低了计算效率。因此,设计了一种变空间Logistic混沌搜索策略,其基本思想如下。
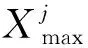
假设PSO算法第i代的精英解是Xi,xij∈[Lj,Uj],变空间Logistic混沌搜索步骤如下:
(1) 利用式(7)对Xi进行归一化。
i=1,2,…,n,j=1,2,…,D
(7)

(8)
(5) 计算μk的适应度值为f(μk),将其与Xi的适应度值f(Xi)进行比较,保留最优解。
(6) 更新混沌搜索空间(L,U)。
1.3 镜像越界处理策略
PSO迭代寻优过程中经常会出现越界这种情况,常规的处理方法是吸收边界,即将粒子越界维度位置拉回到边界上,以保证粒子始终在可行域范围内。如果越界的粒子较多,会造成边界上有较多的粒子,尤其是复杂函数优化问题往往存在较多局部最优解,如果局部最优的粒子聚集在边界附近,将导致更多粒子越界,这种处理势必造成种群多样性减弱,过多粒子聚集于边界周围,引起粒子空间位置分布不均匀,增加陷入局部最优的风险。较好的粒子越界处理策略是使越界粒子映射到可行域内的分布尽可能广泛。因此,采用镜像越界处理策略来处理越界粒子,以进一步改善PSO算法的优化性能,提高全局搜索能力。
假设粒子P第i维的位置xi越界,可行域为[L,U],式(9)是越界粒子的处理策略。重复采用式(9)更新越界粒子的位置,直到不越界为止。
(9)
1.4 CPSO算法步骤
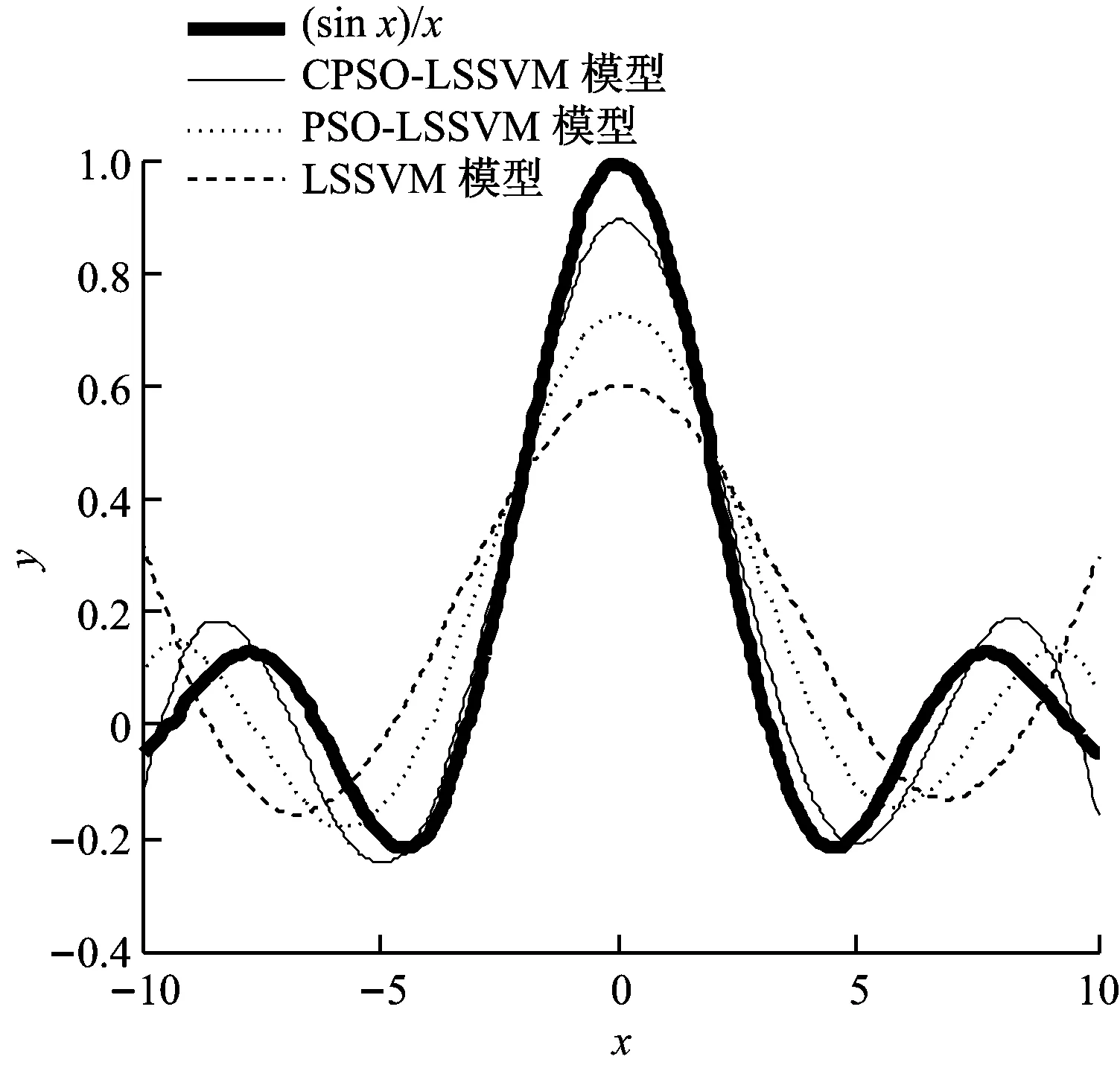
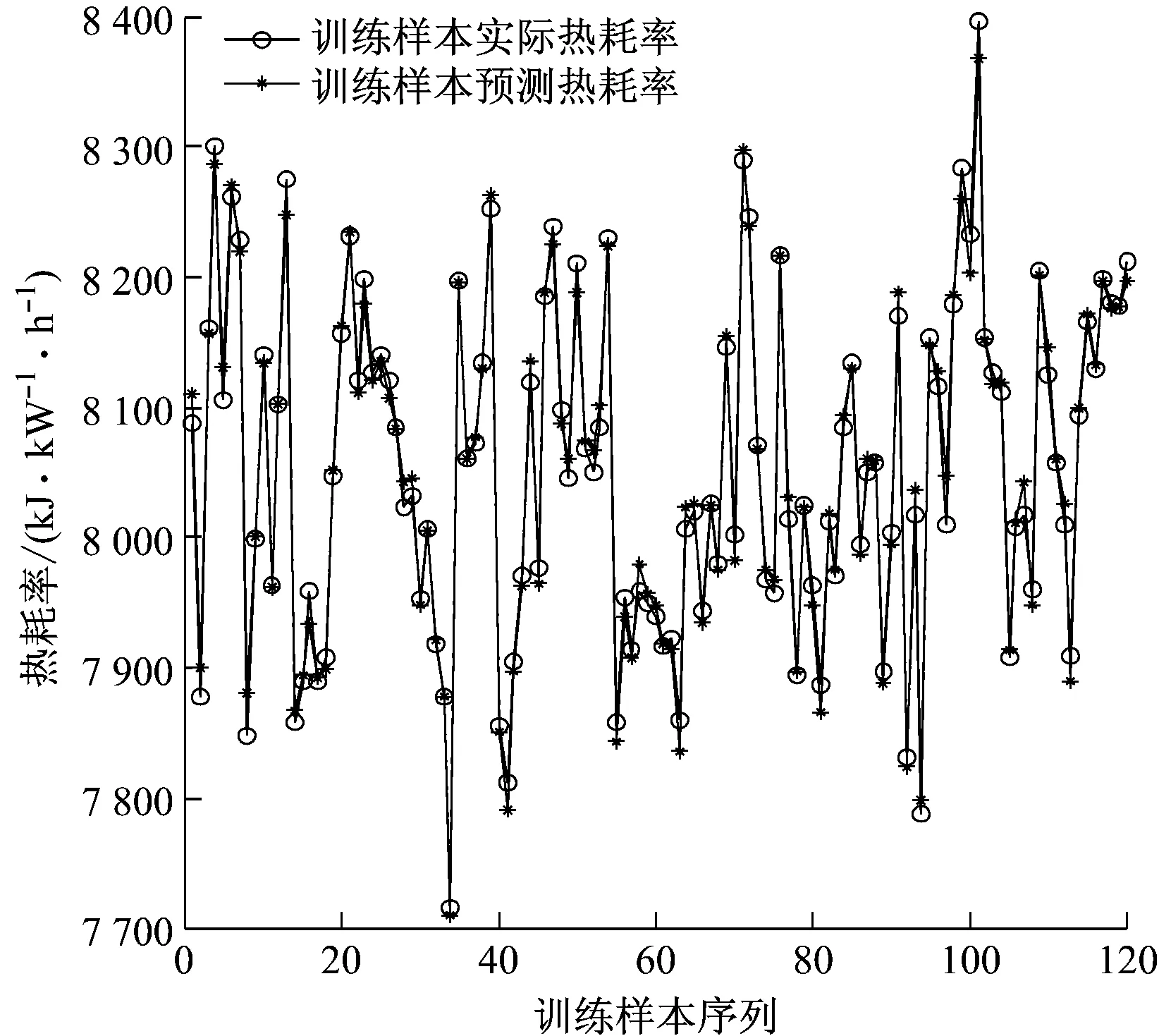
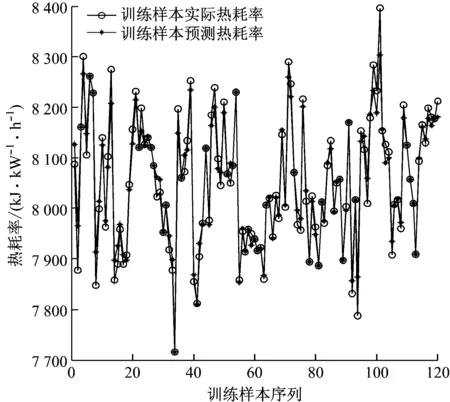
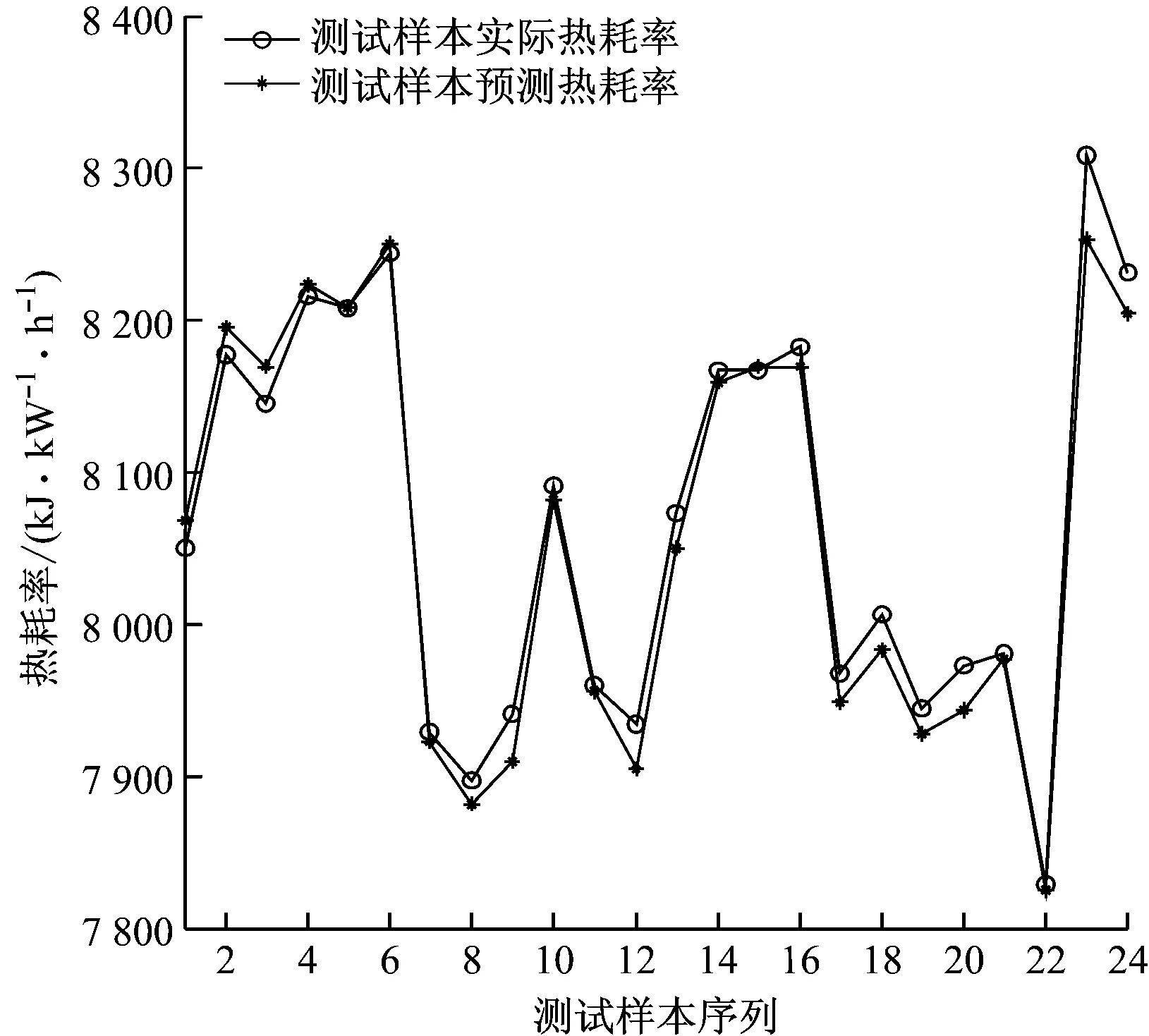
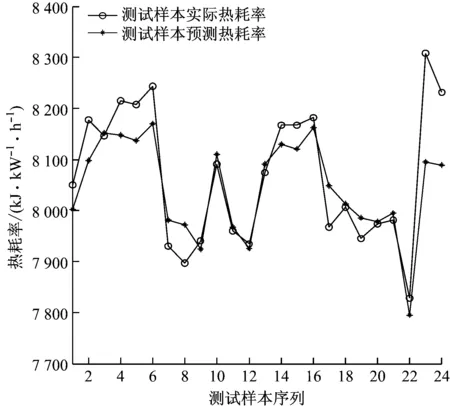
融合变空间Logistic混沌搜索策略以及粒子镜像越界处理策略,CPSO算法的优化框架如下:(1) 初始化各参数,如种群规模N、学习因子、初始速度v、维数D和当前迭代次数t等参数;(2) 根据式(1)初始化种群;(3) 根据式(2)计算粒子的适应度值,记录全局最优gbest和个体最优pbest。(4) 按照第1.2节更新精英个体(gbest)。(5) 根据式(3)更新粒子速度;(6) 根据式(4)更新粒子位置;(7) 判断粒子是否越界,若是,采用式(9)处理,否则跳转到步骤(8);(8) 若t 为了测试CPSO-LSSVM回归建模方法的有效性,采用典型的非线性sinc函数产生的人造数据进行建模和预测验证试验。sinc函数表达式为: (10) 为了可视化,利用输入x产生1 000个数据对。训练样本集:输入变量x在区间 [-10,10] 内均匀产生500个无噪声的训练数据,经式(10)计算得到其相应的输出值。测试样本集:用上述方法产生的500个数据对中,在目标值y上附加取值范围为[-0.2, 0.2]的随机噪声,得到的500对数据为测试集。仿真试验结果与PSO-LSSVM、标准LSSVM方法进行比较,结果见图1。 图1中,粗实线表示原sinc函数的特征曲线。从图1可以看出,CPSO-LSSVM模型预测值与sinc函数的运动轨迹趋于一致,且预测值非常接近sinc函数值,预测结果令人满意。标准LSSVM模型的预测误差最大,效果最差。经过PSO优化的LSSVM模型的预测效果要明显优于标准LSSVM模型,反映出PSO-LSSVM模型参数要优于标准LSSVM模型参数。通过对比可以看出,CPSO-LSSVM模型的预测效果相比PSO-LSSVM模型有了显著改善,验证了CPSO算法比PSO算法更好,能够优化出令人满意的模型参数。 图1 sinc 函数预测结果比较 最小二乘支持向量机是支持向量机的改进,标准SVM的训练需要解凸二次规划,其算法的复杂程度依赖于训练样本集的个数,样本数据越大,计算速度越慢,占用内存越大。LSSVM用等式约束代替SVM中的不等式约束,并将求解二次规划问题转化为直接求解线性方程组,提高了收敛速度。LSSVM具有泛化能力好,适合小样本学习的优点,且通过结构风险最小化原理克服了过学习问题。因此,LSSVM已成为模式识别和回归分析领域的重要工具。LSSVM回归算法描述如下。 给定训练数据集(xi,yi),i=1,2,…,l,xi∈Rn,yi∈R,利用高维特征空间里的线性函数来拟合训练样本集: y(x)=ωTφ(x)+b (11) 式中:b为常值偏置;ω为权矢量。 非线性回归时,首先数据样本通过非线性映射φ(·)将其从输入空间映射到高维特征空间,使输入空间中的非线性回归问题变成高维特征空间中的线性拟合问题。回归问题可以描述为如下约束优化问题: (12) s.t.yi=ωφ(xi)+b+ξi,i=1,2,…,l 式中:γ为正则化参数;ξi为第i个样本的拟合误差。 引入Lagrange乘子α>0,将上述优化问题转换为无约束最优化问题: (13) 由最优性Karush-Kuhn-Tucker(KKT)条件可得回归模型系数的线性方程组: (14) 其中, 式中:I为单位矩阵。 LSSVM的优化问题可转化为求解式(14)表示的线性方程组,避免了SVM中凸二次规划问题的求解。K(xi,xj)为核函数,通常采用RBF核进行高维映射: K(xi,xj)=exp[-(xi-xj)2/2δ2] (15) 式中:δ为核宽度参数。 最后可得LSSVM的数学模型: (16) 基于RBF核的LSSVM模型性能主要由正则化参数γ和核宽度δ决定[13]。正则化参数和核宽度参数对建立有效的LSSVM预测模型至关重要,正则化参数可以调节置信范围和经验风险的比例,若选择的正则化参数值越大,则对LSSVM训练的误差惩罚也越大,此时训练数据的样本点与真实值的拟合会越好,但容易使模型陷入“过拟合”,若减小该值则会降低模型的复杂性;核宽度参数主要影响样本数据在高维特征空间中的分布复杂程度,其值越大,则模型的复杂度越小,也容易出现“过拟合”现象,其值越小,则模型拟合出的曲线越光滑。因此,如何获得最优的参数对(γ,δ2)是提高热耗率模型精度的关键。事实上,LSSVM的超参数调整过程也是参数优化的过程。采用CPSO算法优化选择LSSVM的模型参数对(γ,δ2),优化的目标函数为最小化预测误差: (17) 汽轮机热工过程具有非线性、多变量及工况范围广等特性,利用LSSVM和CPSO进行联合建模的具体流程如图2所示。该模型采用CPSO算法对LSSVM模型的超参数进行优化,以目标函数适应度值最小为原则,通过判断是否满足终止条件,将优化得到的参数代入LSSVM模型,即完成PSO-LSSVM模型的建立。主要步骤如下: (1) 变量选择。在进行汽轮机热耗率建模时,选择合理的输入、输出模式。 (2) 数据采集。从热工运行系统的集散控制系统(DCS)中采集与建模相关的运行数据,并对数据进行变化,处理为可用数据,将数据随机分为训练样本集和测试样本集。 (3) 模型选择。汽轮机热耗率LSSVM模型的选择主要是选择模型的超参数。采用随机初始化方法生成初始种群(γ,δ2),根据初始种群建立热耗率预测模型并计算适应度值,如果适应度值不满足要求,则采用CPSO算法优化选择LSSVM模型超参数,模型训练过程结束后就获得了最佳的LSSVM模型参数,依据超参数建立LSSVM的热耗率预测模型。 图2 CPSO-LSSVM模型 (4) 热耗率预测。利用步骤(3)建立的模型进行汽轮机热耗率预测验证。 汽轮机热耗率建模本质上是从机组各种运行工况下的历史数据中拟合出输入参数与热耗率之间的非线性关系。热耗率预测模型的精确建立为机组初压优化奠定了基础,并通过LSSVM进行训练,建立起机组热耗率与其相关参数之间的映射关系。在CPSO-LSSVM模型中选择输入参数时,一般按照其与热耗率的关联紧密程度进行选择。根据文献[14]和文献[15],最终选定负荷(Pe)、主蒸汽压力(p0)、主蒸汽温度(T0)、再热器出口蒸汽压力(pzr)、再热器出口蒸汽温度(Tzr)、汽轮机高压排气压力(pzl)、汽轮机高压排气温度(Tzl)、再热减温水质量流量(qm,zj)、过热减温水质量流量(qm,gl)、汽轮机背压(pby)、循环水进口温度(Txc)和给水质量流量(qm,fw)12个参数作为输入参数,热耗率(Hr)作为输出参数。 汽轮机运行过程往往是周期性重复运行的,运行参数中充分包含了在不同工况范围内的动态特性信息。以某火电厂600 MW超临界汽轮机组(型号CLN600-24.2/566/566-I)为研究对象,从DCS系统中每隔1 h,每天采集24组,共采集144组数据样本,并且通过热力分析,在线计算获得模型可靠的学习目标——热耗率。选取120组数据作为训练样本,剩下的24组数据作为测试样本,具体数据见表1。建模过程中CPSO的最大迭代次数为1 000,种群规模为50。根据训练好的热耗率模型,采用测试样本对训练好的LSSVM进行校核分析,从而获得较优泛化能力的热耗率预测模型。将CPSO-LSSVM模型与PSO-LSSVM模型的预测结果进行对比。结果如图3和图4所示。 从图3和图4可以看出,针对训练样本,PSO-LSSVM模型对大部分样本的预测误差要比 CPSO-LSSVM模型的预测误差大。CPSO-LSSVM模型能更好地进行回归预测,尤其是训练样本2、样本8、样本13、样本93、样本96和样本100,CPSO-LSSVM模型表现出了更优的训练效果,说明CPSO-LSSVM模型具有很好的非线性拟合能力。为了检验模型的泛化能力,把24组预测样本分别代入2个模型进行测试,结果见图5和图6。 从图5和图6可以看出,CPSO-LSSVM模型对测试样本的预测结果要明显好于PSO-LSSVM模型,CPSO-LSSVM模型的测试误差要小于PSO-LSSVM模型,CPSO-LSSVM模型对大部分测试样本能够进行准确预测,某些测试样本点能够完全拟合,表现出了更好的泛化能力,进一步验证了CPSO能更好地优化热耗率模型参数。 表1 某600 MW汽轮机组运行数据 图3 CPSO-LSSVM模型的训练样本热耗率预测 Fig.3 Heat rate prediction curve of CPSO-LSSVM model for training set 图4 PSO-LSSVM模型的训练样本热耗率预测 Fig.4 Heat rate prediction curve of PSO-LSSVM model for training set 图5 CPSO-LSSVM模型的测试样本热耗率预测 Fig.5 Heat rate prediction curve of CPSO-LSSVM model for testing set 图6 PSO-LSSVM模型的测试样本热耗率预测 Fig.6 Heat rate prediction curve of PSO-LSSVM model for testing set 针对汽轮机热耗率难以准确计算的问题,采用最小二乘支持向量机模型对电厂汽轮机热耗率进行预测,并通过粒子群算法优化选择模型的超参数。针对典型粒子群算法寻优能力不足的问题,提出了一种改进的粒子群算法,通过对基准测试函数进行仿真测试,验证了该算法的有效性和优越性。利用CPSO算法优化LSSVM的正则化参数和核宽度参数,建立了CPSO-LSSVM模型。通过对某600 MW汽轮机组的热耗率进行仿真测试,验证了CPSO优化的LSSVM模型的优越性。CPSO-LSSVM模型的预测精度更高,泛化能力更强,为电厂汽轮机热耗率的计算提供了一种有效的方法。2 sinc函数预测
3 CPSO-LSSVM热耗率模型
3.1 最小二乘支持向量机
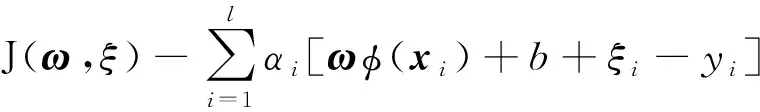
3.2 CPSO优化的LSSVM热耗率模型

4 仿真实例

5 结 论
