基于多约束信息融合的特定网络检测方法设计
2018-09-19覃俊
覃 俊
(南京理工大学,南京 210094)
0 引言
特定网络指的是专门针对一个应用或者一个区域的流量。特定网络异常检测方法通常能够分为两类:滥用检测与异常检测[1]。其中的滥用检测一般是依据专家的所学知识和经验来判别异常的产生,这导致了该方法对新入侵模式以及伪装之后入侵模式的检测率低。由此,研究人员试着通过异常检测解决该问题[2]。在进行异常检测时,和正常的行为有出入的行为就会被检测出,同时生成入侵警报。
为提高检测的整体性能,引入了大规模的人工智能技术,用于滥用检测与异常检测。在网络异常检测的领域中,应用的比较早的就是专家系统[3]。随之机器学习技术以及神经网络技术等也被陆续应用于网络异常检测中,但在实际应用中发现,由于审计数据规则限制,有些入侵模式稍离审计数据就很难被检测出来,有些正常运行中具有较小变动的行为又可能致使虚假的警报[4]。由此提出一种基于多约束信息融合的特定网络检测方法。
1 特定网络数据获取
基于多约束信息融合的特定网络检测中,应对特定网络数据进行获取,再对其进行后续处理。采用WinPcap对特定网络数据进行获取,通过WinPcap对网络数据进行获取不仅能够利用调用Packet.dll中的API实现,也能够通过调用Wpcap.dll中的 API完成[5]。利用 Windows中的 Wpcap.dll实现特定网络数据的获取。特定网络数据获取的过程为:获取特定网络中NIC相关信息;构建特定网络侦听;制定过滤条件;循环获取。过程如图1所示。
1)获取特定网络中NIC相关信息。这里有两种方法可以获取NIC信息:用户自己选定;将Pcap接口函数进行调用,自动检索可用的网络接口。则获取的NIC有关信息函数为:Pcap-lookupdev以及 Pcap-lookupnet。其中,Pcaplookupdev作用是表示本地的网络接口;而Pcap-lookupnet是为了得到本地的IP地址与子网掩码。如果函数调用失败,则返回-1;
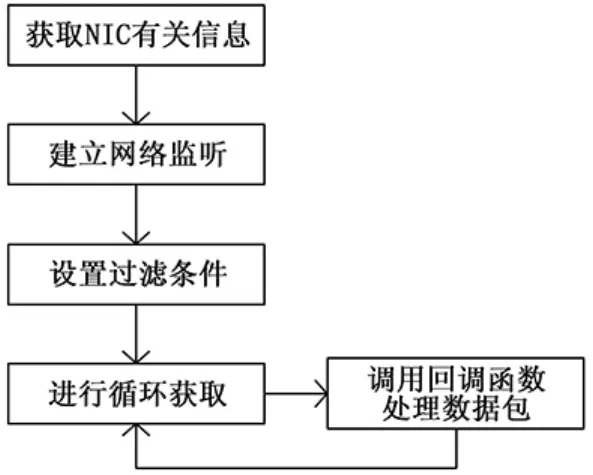
图1 特定网络数据获取流程
2)网络侦听的启动。上述中得到了网络的接口,用到的函数是Pcap-open-live,其责任为按指定的参数初始化Wpcap。其返回值类型是Pcap-t型指针,该指针就是侦听句柄[6]。
3)对于数据过滤条件的设置。详细步骤为:将用户所输入字符类型定义的过滤条件,转变为系统所认可的bpfprogram类型,然后把转换之后的过滤条件发送到侦听句柄。
4)循环获取。以上步骤均为对NPF(数据包过滤器)的初始化,实现初始化后,对特定网络数据进行循环获取。Pcap库中有两个函数能够实现该功能:Pcap-loop与Pcapdispath,它们功能大致相同,另外在调用成功的时候,将会返回获取到的字节数,相反,返回的则为0。其中最大的区别就在于Pcap-loop获取超时,不会返回,Pcap-dispath获取超时会返回0。数据包所有操作均在回调函数内完成,将回调函数定义为全局函数,针对每个循环中获取的数据包,均按特定网络数据获取的定义操作。
2 特定网络数据预处理
数据粒度也可以叫作信息粒度,是指信息单元的粗糙程度[7]。在特定网络检测中,如果数据粒度过于粗糙,会降低网络检测效率。特定网络数据的预处理中,以降低数据粒度粗糙程度为目标,利用Rough集理论对特定网络数据粒度进行过滤,减小信息粒度的粗糙程度,以达到提高网络检测效率的目的。通常在进行网络检测时,会利用一个规则对信息粒度进行预测,当排列分布为1时,则预测是正确的。不过,一个正确的高质量规则不能够保证预测的准确性。举例说明:假设通过Rough集法于少量对象信息系统内,发现了规则,就算其近似质量很高,不过因为支持的对象少,该种近似质量有可能是因为偶然的因素引起的,致使其在分类新的对象时,预测能力比较低[8]。由此规则预测的高效性需要通过统计意义实现测试。
如果信息系统内的信息粒度比较高,规则的统计价值T通常很高。所以提出利用Rough集法对数据的粒度进行过滤。其基本思想为:通过决策属性值D确定无差别关系θQ等价类的合并来提升规则统计意义,进而降低信息粒度,也就是数据粒度的粗糙程度。也就是减少等价类数量,同时保持数据不受损失。信息粒度粗糙程度过滤的详细步骤为:
输入: 数据集I=[U,K,Vq,fq]q∈K,其中K=C∪D且C∩D=ɸ,U代表一组对象的非空且有限的集合,K代表有限个属性非空有限集合,fq代表信息函数,Vq代表属性q值域,C代表条件属性值;
1)对于每个q∈K,对其等价类集合P{q}进行计算;
2)对于每个q∈C,将会执行下列步骤:
(1)对上述数据按照其属性值排序;
(2)对任意的两个相邻属性值qi与qj进行分析,并假设它们所对应的对象是ui、uj:
假设[ui]q、[ui]q是D确定的,且有Yi0∈ P(D)存在[ui]q⊆ Yi0、[uj]q⊆ Yi0,那么:
(a)把属性值qi、qj进行合并,且记为qij,代表取值为qi或者qj;
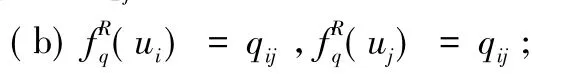
(3)经上述处理之后的数据系统上,假设存在不同属性值qi或者 qj,并假设两者对应对象为 ui、uj,[uj]q和[ui]q为D确定的,且有Yi0∈P(D) 存在[ui]q⊆Yi0、[uj]q⊆Yi0,那么:
(a)把属性值qi、qj进行合并,并记为qij,代表qi或者qj;

3)结束过滤。
3 特定网络数据检测模型
通过2中的数据粒度粗糙度过滤操作,使基于多约束信息融合的特定网络检测变得更加快速,之后文章基于多约束信息融合的网络检测则利用构建SVM融合检测的模型。特定网络检测模型如图2所示。
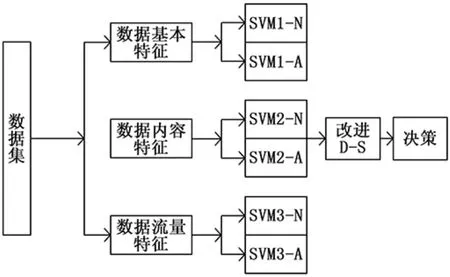
图2 SVM融合模型
根据上图显示,模型实现的步骤如下。
1)训练SVM分类器:
地下水水质修复主要应考虑地下水污染成因、污染物成分、污染范围和经济技术条件等因素。可以优先考虑饮用水水源地的地下水水质修复,先易后难、先试点后推广,分清轻重缓急,逐步展开。
把训练数据集按照其特征划分为3类,实现SVM的训练。则按照图中显示先把训练数据集和预测数据集内的特定网络数据,按照数据的特征属性将数据集中的数据划分成3个类别:基本特征、内容特征和流量特征。将分别代表异常类型数据、和正常类型数据的标签,加在各类数据集属性的后面,设置正常数据的标签是1,而异常数据的标签是-1。
依据同类数据间距离小于异类数据间距离理论,那么在特定网络数据的检测中,正常数据之间的距离要小于正常数据至异常数据间距离。在融合模型中通过一对SVM-N与SVM-A分类器,实现此类数据特征的回归,则在模型的模块中,共用到了6个基本分类器,将分类器划分为两类:A分类器、N分类器。其中,N分类器提供了该特征下,数据正常行为可信程度,A分类器则提供了于该特征下异常数据行为可行程度。由此先分别对正常数据行为聚类的中心DN以及异常数据行为聚类中心DA进行计算。训练N分类器过程中,对正常数据行为至正常数据行为的聚类中心DN间的距离DN~N进行计算,并取其正值,其次对异常数据行为至正常数据行为的聚类中心DN间的距离进行计算DN~A并取负值,均存储于N~L,并在[0,1]间进行归一化,当作分类器N训练的标签。
相同的道理,在训练分类器A的过程中对异常数据行为至异常数据行为聚类中心DA间的距离DA~A进行计算并取负值,再对正常数据行为至异常数据行为的聚类中心DA间距离进行计算,取正值,均存储于A~L内,并在[0,1]间进行归一化,当作分类器A训练标签。
综上所述,对分类器N和A相应的标签进行了回归训练,并将已经划分的3类特征进行训练,分别为SVM1-N和 SVM1-A,SVM3-N 和 SVM3-A,SVM2-N 和 SVM2-A,由此SVM各模块训练结束,得到各类数据特征中的N类分类器以及A类分类器训练标签。
以上述为基础,利用D-S完成融合决策。把获取的各个数据特征属性训练标签,当作各类数据特征属性预测时所需要的标签,并加上已经分好类别的预测数据集完成预测,这样就能够获得,测试数据集中的各类测试数据的标签类型[9]。
2)关于SVM的融合实现:
SVM的融合实现中,要完成基本置信分配函数的确定:通过D-S理论,设置出识别的框架Θ为{N,A}。其中N是正常数据行为,A是异常数据行为,N∩A=ɸ。将基本置信分配函数定义为:

其中,m({N,A})+m(N)+m(A)=1,式中m(N)代表当前情况下特征支持正常数据行为的可信度,m(A)代表当前情况下特征支持异常数据行为的可信度,m({N,A})代表无法确定当前数据行为,是否为正常的可信度。
把分类器训练好,然后对分类器的回归功能,进行评估。而基本置信值的预测是利用 SVM1-N和 SVM1-A,SVM3-N和SVM3-A,SVM2-N 和SVM2-A对测试数据集的预测得到的。把结果存储至 m1(N)、m1(A)、m2(A)、m2(N)、m3(N)、m3(A), 然 后 将 m1(N)、m2(N)、m3(N)组成个新的正常行为置信分配值,再将m1(A)、m2(A)、m3(A)组成个新异常行为置信分配值。利用计算的形式获取数据无法确定的行为分配值,设某个数据x,对于正常行为的置信分配值是mx(N),异常行为置信分配值是mx(A),假设mx(N)+mx(A)<1,那么该数据对行为无法确定的置信函数值是mx(NA)=1-mx(N)-mx(A)。反之,该数据对行为无法确定的置信函数值是mx(NA)=0,且把mx(A)和mx(N)进行归一化处理。综上就能够获得整体的N、A、{N,A}的置信函数分配值。也能够获得各SVM分类器对N和A、{N,A}可信度,同样确定m函数内的置信函数值以及权重,接着代入D-S的合成公式,就能够获得检测结果。
最终的检测判定结果如下所示:

4 特定网络数据过滤
当前的特定网络数据检测方法中仅进行一次检测,内部异常数据可能存在剩余[10],为此在本节将对第3节检测结果利用群体信任法再次进行过滤,实现网络异常数据的彻底检测和清除。具体过程如下所示:
1)将检测结果收集起来,经过一段时间之后,所汇聚的节点构建基准数据特征云BC;
2)确定可疑数据门限和异常数据门限,其中可疑数据门限ST和异常数据门限AT的确定取决于特定网络,汇聚节点把BC、ST和AT广播到全部簇头上;
3)簇头对异常数据的门限AT进行初始化,转换为接收到的AT值。且将BC和ST广播到簇内节点上;
4)普通的数据节点按预设的频率进行存储,记为SV,比较SV和基本数据特征集内ex的数值之间的差值,将该差值和可疑的数据门限ST进行比较,假设小于ST,则将可疑的数据标记为0,假设大于ST,则将可疑数据标记为1,并发送数据到簇头。
5)当簇头接收了正常数据,正常将数据上传,当收到可疑的数据,通过群体信任法计算该数据群体信任度CT;
6)如果CT比门限AT低,在判断数据为不可信时,把该数据清除,如果CT比门限AT高,则判断数据为可信,把数据发送到汇聚节点,或者上级簇头节点进行利用。
综上所述,对检测后的结果进一步过滤,正常数据会被正常传输利用,该步骤提高了网络检测的准确性,降低了误报率,同时特定网络节点的正常工作并不会被影响。
5 实验结果与分析
实验环境为:实验平台在matlab2017a上建立,实验的硬件环境为acer双核笔记本,实验数据取自于DARPA数据集kdd99。
检测准确性是验证检测方法的重要指标之一,下图为不同方法检测准确性,其中图中的圆圈代表特定网络异常数据点,被黑色圆点覆盖的就是已经检测出的异常点。
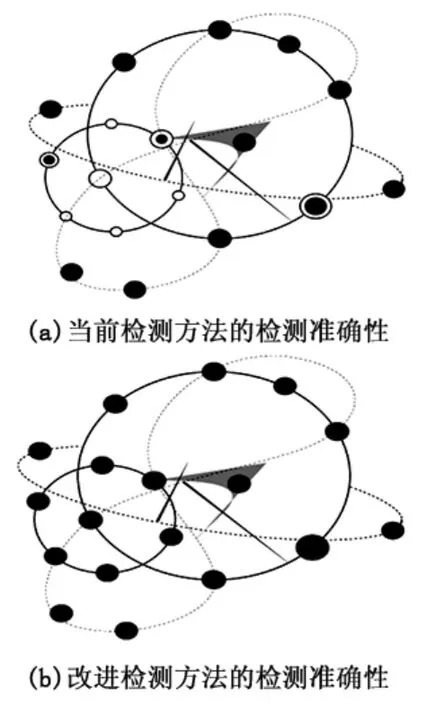
图3 不同检测方法的检测准确性
检测的误报率同样是验证检测方法的关键因素,表1为不同方法检测的误报率。

表1 不同方法误报率
分析图3和表1可知,改进方法的检测准确性比当前方法的检测准确性要高。改进方法基于多约束信息融合的网络检测通过构建SVM融合检测模型实现,其中利用D-S进行融合决策,设置异常数据识别框架,并设置基本置信分配函数,确定函数权重,代入D-S理论中,获得检测结果。又利用群体信任法实现检测结果的进一步过滤,实现了异常数据的彻底清除,提高了特定网络检测的准确性,降低了检测的误报率。
下图为在一定时间和一定的数据量下,数据运行时的波形,波形中带有星星的点即为异常点,经统计异常点共有8个,下面利用下图对不同方法的检测效率进行验证。
分析表2,改进特定网络检测效率优于当前网络检测方法。数据粒度的粗糙程度在一定程度上决定了网络检测效率,改进方法在特定网络数据的预处理中,以降低数据粒度粗糙程度为目标,利用Rough集理论对特定网络数据进行过滤,并以此来提高网络检测效率。

表2 不同方法网络检测效率对比

_______1 3___________________1_________________2 5___________________2_________________3 8 3_________________4 12 5_________________5 15 6_________________6 19 7_________________7 23 8______________________________________828______________________________________8
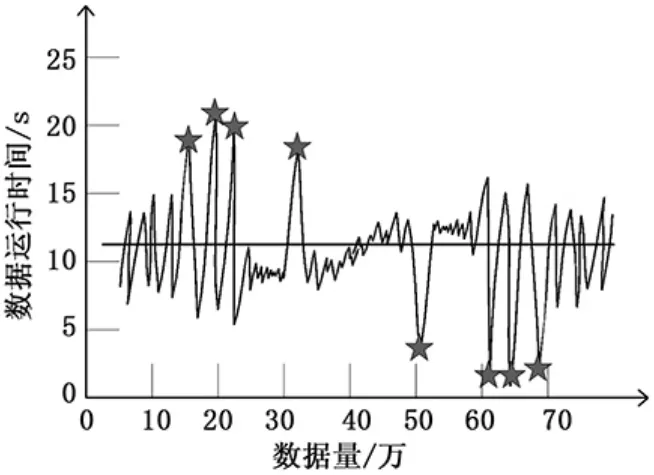
图4 数据运行波形
6 结束语
网络的异常检测是网络安全防御中不可缺少的构成部分,不过单一的方法很难得到比较好的检测结果,这限制了异常检测方法在大规模网络中的应用。分析了特定网络异常的检测,提出基于多约束信息融合的特定网络检测方法。利用支持向量机以及D-S证据理论多项方法的结合,以及信息融合等相关技术,将结合的结果应用在网络入侵的检测中,并利用实验证明了所提方法具有一定的可行性。
