基于PCA、 LDA和DLDA算法的人脸识别
2018-09-14武汉理工大学信息工程学院申俊杰
武汉理工大学信息工程学院 申俊杰
1.PCA 算法原理与实现
人脸识别中主要分量分析(PCA)是一个普遍使用的技术,首先它将一张图像的每一列的向量首尾相连,构成一个维列向量,然后转置。将L个图像的维列向量组成人脸样本矩阵,表示为:

训练样本的协方差矩阵为:

式中mf是所有训练样本的平均值向量(所有样本的平均脸)
式可进一步化简为:
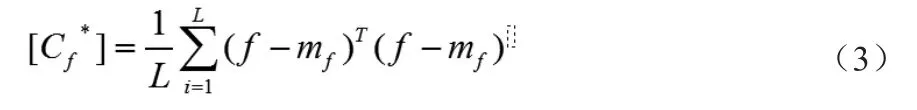
对(3)式中的矩阵进行特征值和特征向量的求解,并SVD奇异值分解,构造出最终的人脸投影空间:

将Vi化为矩阵,则可以得到特征脸。
2.LDA算法原理及实现
LDA的核心思想之一是在平面内找一个合适的向量,将所有的数据投影到这个向量而且不同类间合理的分开。因为图片的特征值有很多,相当于是多维的,所以我们需要增加投影向量w的个数,设w为:

w1、w2等是n维的列向量,所以w是个n行k列的矩阵,这里的k其实可以按照需要随意选取,只要能合理表征原数据即可。x在w上的投影可以表示为:

所以这里的y是k维的列向量。这样我们就可以把多维空间中的特征值降维到一维空间
从投影后的类间散列度和类内散列度来考虑最优的w,可用μi代表类别i的中心,将类间距离定义为Sb较大,类内距离定义为Sw。为了让每个类(相当于每张图片)直接的特征值尽量少的有重叠,需要让类与类之间的距离大,而一个类内部之间的距离紧凑。因此我们可以定义:

可以化简为:

因为Sw要尽量小,而Sb要尽量大,因此可以找到合适的W让J(w)尽可能大。
3.2DLDA算法原理及实现
2DLDA从人脸图像矩阵直接得到类内和类间离散度矩阵,而不必将人脸图像矩阵转化为人脸图像向量。2DLDA估计得到的离散度矩阵比LDA方法精确。另外,由于2DLDA估计得到的离散度维数等于原始人脸图像的列数,因此,相比LDA方法得到的离散度矩阵维数小的多,从而使得求解最佳投影空间时计算量大大降低。由于2DLDA的公式推导较多,本文不在此详述,直接通过实验的结果来比较2DLDA相对于LDA的优点。

图1 成功识别

图2 识别失败
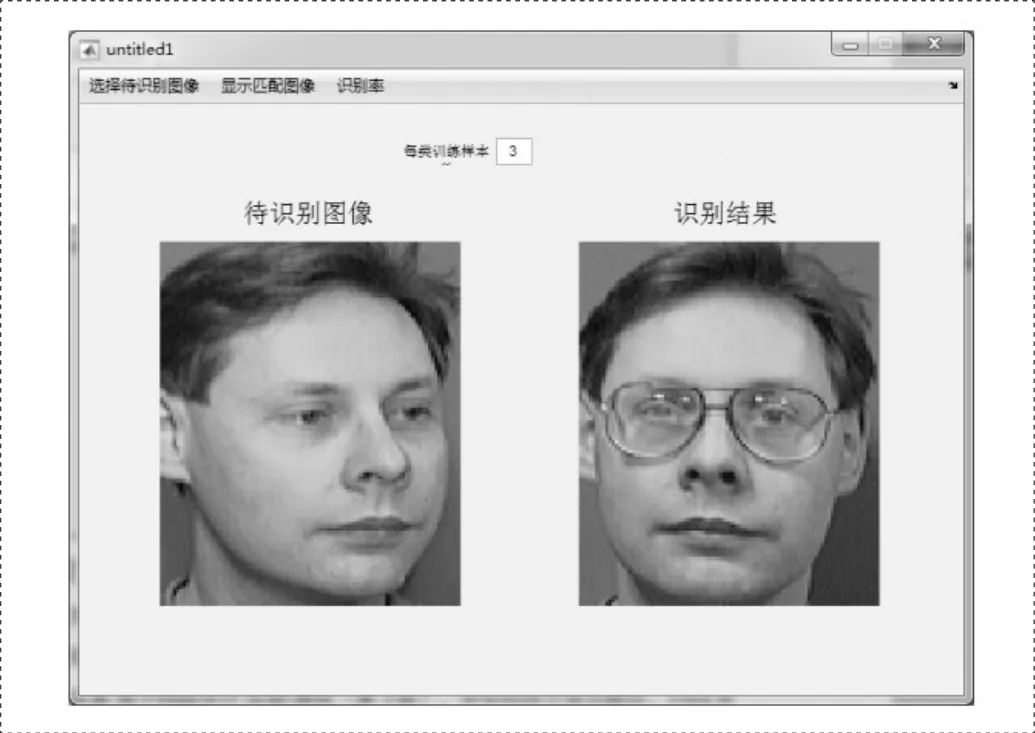
图3
4.MATLAB仿真结果分析
4.1 LDA 方法的人脸识别仿真
我们利用GUI设计可视化的界面,让实验结果更好的展示。
可以看到,当面部有偏侧的时,LDA不能很好的识别出正确的人脸,如图1、图2所示。
4.2 DLDA人脸识别实例
优化后的LDA有着更高的准确性,我们在yale的数据库中做了一下测试。在面部有偏侧和带眼镜甚至闭眼是都能准确的识别。我们还编写函数,计算了准确性,经过多次实验,准确性在97%左右,如图3所示。
4.3 基于DLDA算法的正确识别率
为了探究训练次数对DLDA准确率的影响,我们编写了相关函数,结果如表1所示:

表1
根据表1可以得到结论,当系统的训练样本个数从 5 逐步增长到9 的时候,DLDA算法的人脸识别系统的识别率也在逐渐的增大,可以得出:在设计人脸识别系统时,训练样越大,系统的正确识别率就越高,即训练样本的数量要大于每个样本的空间维数,但是这一点在实际的应用时是比较难做到的。在系统样本维数相同的前提下,基于LDA算法的人脸识别系统的正确识别率要比基于PCA 算法的正确识别率要高, 虽然PCA方法和LDA算法都可以降低原始特征空间的维数,但是PCA方法得到的特征是最佳描述特征, 而不是最佳分类特征,因此,在正确识别率方面,LDA算法要比 PCA算法优越。
