改进哈希编码加权排序的图像检索算法*
2018-09-11郭呈呈于凤芹
郭呈呈, 于凤芹, 陈 莹
(江南大学 物联网工程学院,江苏 无锡 214122)
0 引 言
为了提高局部敏感哈希[1,2](locality sensitive Hashing,LSH)编码效率,提出了许多生成紧凑哈希编码的方法[3~7],但由于哈希编码是离散的且受编码长度的限制,因此,在检索时查询图像与许多图像数据间的汉明距离是相同的,难以根据距离排序来判断这些图像与查询图像间的相似性。为了解决该问题,可以对各个哈希比特位进行加权处理,Zhang X等人[8]没有将查询数据压缩到二值哈希编码,从而减少了信息的损失。Jiang Y G等人[9]根据预定义的类别标签,为不同类别图像学习不同的比特位权重,但算法受类别标签数量限制,适用性较差。Zhang L等人[10]提出了加权汉明距离排序(weighted Hamming distance ranking, WHRank)算法,但该方法十分依赖数据分布假设。Liu X L等人[11,12]提出了哈希编码加权排序(query-adaptive Hash code ranking,QRank)算法,克服了上述加权方法适用性差的问题,然而由于QRank在计算比特位权重时利用随机采样的方法选取采样子集,导致数据分布特性丢失,权重分配不符合实际情况,检索精度下降。
针对上述问题,本文提出了一种改进的哈希编码加权排序图像检索算法,与现有的比特位加权算法相比,本文主要有两点改进:1)利用数据依赖差异[13]的思想对图像数据集采样,得到一个保留数据分布特性的采样子集,利用该采样子集计算各个比特位权重,提高检索精度;2)提出了一种由粗到细的图像最近邻检索策略:采用哈希方法将图像特征映射成二值哈希编码;计算哈希比特位权重,对哈希编码进行加权汉明距离排序,返回一个查询图像的候选最近邻集合;对候选最近邻集合中的图像数据进行主成分分析(principal component analysis,PCA)映射,计算每幅候选图像的排序得分,根据得分重新排序来进一步提高检索精度,完成查询图像的最近邻检索。
1 改进哈希编码排序图像检索的基本原理
1.1 数据依赖差异的基本原理
基本思想是两个数据在样本密集区域的差异性较大,在样本稀疏区域的差异性较小,也就是数据依赖差异与数据的分布有关。定义一个能同时覆盖样本数据x和y的最小区域
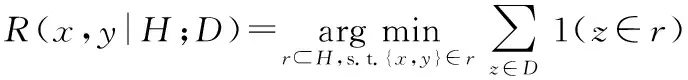
(1)
式中 1(·)为指示函数,D为样本数据,H∈H(D)为一个分割模型,将空间分割成若干个不重叠且非空的区域。
1)构造一个包含t个随机树的随机森林作为分割结构R,每个随机树都根据数据集D的一个子集构建得到,通过遍历树的方式记录数据的分布信息;
2)找到包含数据x,y的所有t个分割R(x,y|Hi),计算数据依赖差异
(2)
3)利用数据依赖差异代替基本的欧氏距离度量对数据集进行聚类,根据每个类别数据的数量占总数的比重,对其进行采样,共取ns个数据作为采样子集。
1.2 由粗到细的图像最近邻检索算法
1.2.1 生成短哈希编码
采用哈希方法生成较短的哈希码,假设给定一个包含n个d维数据点的数据集X={xi∈Rd,i=1,…,n)和m个哈希函数H(·)={h1(·),…,hm(·)},每个样本数据xi均被第k个哈希函数编码成哈希比特yik=hk(xi)∈{-1,1},其中哈希编码函数定义为
hk(x)=thr(wkx)
(3)
式中wk为超平面参数的列向量。二值编码通过符号函数y(x)=sgn(f)(如果f>0,那么y=1;否则,y=-1)获得,数据的编码过程为Y=sgn(WX)。
1.2.2 改进的加权汉明距离排序方法
对于一个查询数据q,若一个哈希函数可以较好的保存其最近邻集NN(q),则该函数对应的哈希比特位在加权汉明距离中应体现出更重要的作用,应赋予其更大的权重。基于哈希函数的近邻保存能力,可以根据谱嵌入损失[4]定义权重
(4)
1)找到查询的最近邻集NN(q)。针对文献[12]利用随机采样的方法,获取的数据不稳定,不能保留数据的分布特性,本文利用数据依赖差异的思想来获取符合数据分布特性的采样子集。
2)计算相似性s(p,q)。为了度量查询与数据集间的全局相似性,采用锚图[14]的方法来近似数据的邻居结构,利用K-means对数据进行聚类,取c个聚类中心作为锚点,基于数据和锚点间的近邻关系,可以用区分力更强的非线性特征z(x)表示样本数据x,最终两个数据间的相似性为
s(p,q)=exp(-‖z(p)-z(q)‖2/σ2)
(5)
式中σ为z(p)和z(q)间的最大距离。
此外,通过计算两个哈希函数的互信息判断独立性。
综合考虑以上两点,计算哈希比特位权重需要同时最大化哈希函数的近邻保存能力和独立性,这个问题可以看作一个二次规划问题求解。
1.2.3 计算排序得分
计算排序得分时将查询数据的近邻半径ε和原始特征作为输入,在哈希编码空间对查询的ε近邻进行统计特性的建模分,并利用PCA对候选最近邻集数据进行降维压缩,利用PCA方法一方面可以将数据特征信息尽可能的压缩,减少编码长度,提高计算效率,另一方面PCA映射是正交的且能够保存L2距离,因此,查询数据的ε近邻在经过PCA映射后仍保留其近邻关系。
为了计算方便,可以将排序得分近似为
(6)
式中q为查询图像,h为哈希编码,k为编码长度,ωj为排序得分的单个比特输出
(7)
式中yj为pj(yj)生成的随机数。本文假设pj(yi)为均匀分布。式中只要有任意一个ωj(qj,hj,ε)为0,最终的排序得分即为0,哈希编码为h的数据则不会返回,可大幅提高计算效率。
2 算法流程
本文算法流程如图1所示。
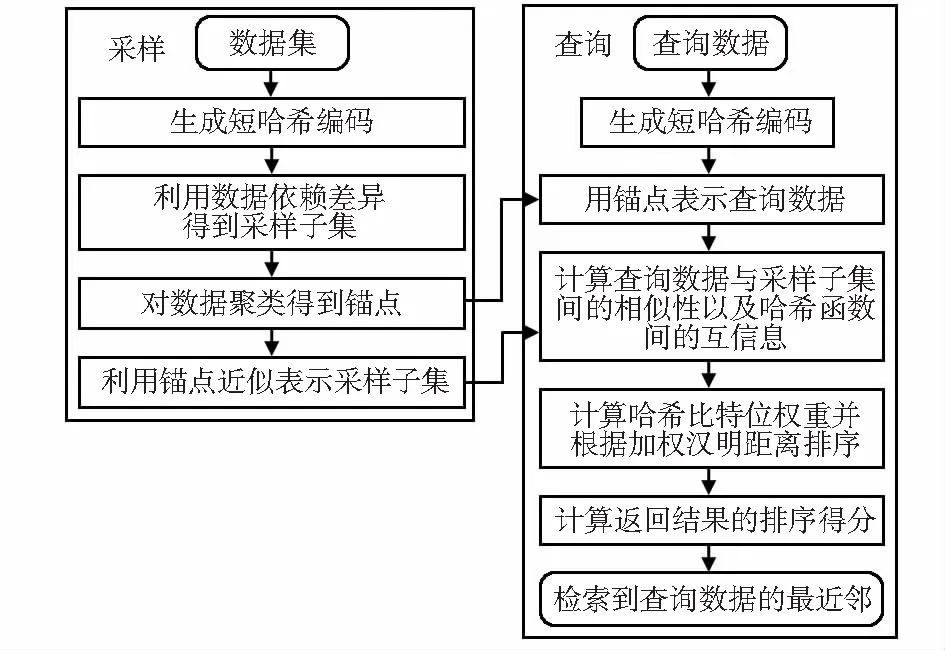
图1 改进哈希编码加权排序的图像检索算法流程
3 仿真实验与结果分析
3.1 实验环境与参数设置
仿真实验采用图像哈希检索常用的手写数字数据库MNIST[15]和自然图像数据库CIFAR—10,本文随机选取数据库中的1 000幅作为测试用的查询图像,其余的作为数据集输入。实验硬件环境为Intel Core i5—6200U处理器、8 GB内存,软件环境为Windows10,编程环境采用MATLAB R2016a。
为了验证所提算法的有效性,选择文献[2]提出的基本的哈希编码方法,即LSH,以及两种哈希编码加权排序方法,文献[10]的WhRank算法和文献[12]的QRank算法进行对比实验,同时为了验证本文算法的适用性,对比了文献[3]PCA哈希(PCAH)和文献[5]递归量化哈希(ITQ),共进行了3组仿真实验,并对结果进行比较分析。本文采用精度(precision),召回率(recall)和平均准确率(mean average precision,MAP)作为算法的评价指标。精度为返回的前K个结果中最近邻所占的比率;召回率为前K个结果中最近邻占所有最近邻的比率,K值相同的条件下精度和召回率越高,检索性能越好;平均准确率的大小对应着precision-recall曲线下区域面积的大小,MAP值越大,检索性能越好。由于查询图像是随机选取的,因此每个实验重复3次,每次选取5 000幅图像作为训练数据,1 000幅图像作为测试数据,取结果的平均值作为最终结果。数据库中与查询图像标签相同的图像即为查询图像的真实近邻。
3.2 结果分析
图2为CIFAR—10数据库上查询图像返回的部分检索结果,根据图2(a)可以看出,经过加权排序粗检索后得到的候选最近邻集合中虽然大部分检索结果是正确的,但仍有错误的匹配,影响检索质量,经过图2(b)计算排序得分的细检索后,去除了大部分的错误匹配,提高了检索精度。

图2 飞机查询图像的部分检索结果
表1中具体列出了MNIST数据库中编码长度分别为48 bit和96 bit时几种算法的MAP,相比于基本的LSH图像检索算法,本文算法在检索精度上有明显的提升,并且本文算法的MAP也优于WHRank和QRank两种哈希比特位加权排序算法,在编码长度为96 bit时,本文算法的MAP分别提高11.61 %,8.42 %和1.86 %。
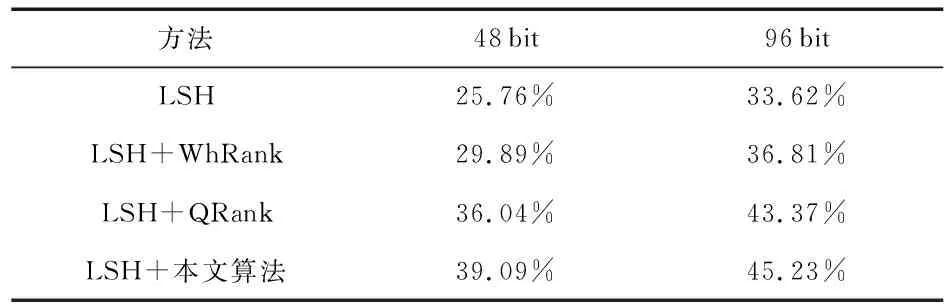
表1 MNIST数据库上二种编码长度下各算法的MAP
图3为MNIST数据库上各算法的性能对比,图3(c)给出了编码长度为48 bit时的检索精度曲线,可以看出,通过对哈希编码进行加权排序,提升了基本哈希方法的搜索性能,对于每种哈希方法,使用本文的加权排序算法后检索精度平均提升了约14 %,对于LSH算法,精度提升的更多(约19 %)。图3(d)给出了增加编码长度的检索精度曲线,可以看出,本文算法提升了基本哈希方法的检索精度,与其他加权排序方法相比,检索精度更高。对比图3(c)、图3(d)可以发现,LSH和PCAH哈希算法在编码长度为96 bit时的检索精度仍然要低于编码长度为48 bit时使用本文排序算法的检索精度,说明了本文算法能够用更短的哈希编码达到更高的检索精度,有效提升编码效率,节省存储空间。图3(a)、图3(b)给出了在数据集MNIST上编码长度分别为48 bit和96 bit的召回率曲线,可以发现,本文算法有效地提升了召回率,且在性能上优于其他2种排序算法,较QRank算法在召回率上提升了约7.47 %。

图3 MNIST数据库上二种编码长度下各算法的性能对比
4 结 论
提出了一种由粗到细的检索策略查找查询图像的最近邻,仿真实验结果表明:本文算法的检索性能优于其他算法,但在计算排序得分时依赖基于PCA的哈希编码技术,因此,编码长度不能超过输入特征的维数,对此,需要进一步研究更优的量化方案。
