基于铁路安全管理信息报告的文本挖掘技术研究
2018-09-11张磊,王喆
张 磊,王 喆
(1.中国铁路广州局集团有限公司,广州 510088;2.中国铁道科学研究院集团有限公司 铁路大数据研究与应用创新中心,北京 100081)
近年来,中国铁路快速发展,铁路运营里程不断增加,行车速度大幅提高,为整个社会的快速发展以及国民经济的高速增长做出了巨大贡献[1]。为确保铁路运输生产安全持续稳定,铁路运输部门不断创新安全管理思路及方法,如将风险管控与干部履职考核挂钩,促进风险管控措施落实[2]。但此过程中产生了大量安全管理信息报告,这些信息对于开展铁路安全大数据研究、查找事故发生规律有着重要的价值。
高速铁路运营和科研单位已经就铁路文档报告数据开展了很多探索和分析。如文献[3]采用主题模型对高铁车载设备故障追踪表进行分析和特征提取,并根据车载设备的特点与领域专家知识对车载设备故障进行诊断。文献[4]对地铁施工事故报告进行分词处理、特征项选择、规律识别,并利用词云和网络结构图等方法可视化文本挖掘结果。文献[5]采用TF-IDF模型实现铁路信号设备故障文本的特征提取,并基于Voting的方式实现故障的智能分类。文献[6]采用基于层叠隐马尔科夫的分词算法对铁路基础设施设备质量问题数据进行分词处理并统计词频,利用词云图展示结果。现阶段的各项研究中,对铁路安全管理报告型文档的分析挖掘研究尚不成熟,尤其是对安全风险库、干部履职、安监报和铁路交通事故故障等信息的特征词提取研究不多,导致难以查找各安全管理信息报告之间的相关性。因此,如何分析和利用此类报告文档丰富安全管理专业词库,并结合事故致因论查找事故发生规律有着重要意义。
文章采用卡方检验提取文本特征词,并用朴素贝叶斯算法对文本进行分类,提取铁路安全管理信息报告文档的特征词,为丰富铁路安全专业分词库提供一种思路。
1 思路及步骤
文本挖掘技术本身涉及统计学、自然语言学、机器学习等多个领域的知识,为研究各类事物及现象提供了新的可能。具体的文本挖掘任务则包括将文本集分成几个主题领域(分类或有监督学习),依据样本间相似度将文本集分成几组(聚类或无监督学习),依照一些搜索准则搜索合适的文本(文本检索)[7]。
文本挖掘步骤:(1)从文本集中提取特征,以便研究人员使用统计方法来计算文本。(2)构建公式化度量文本间的距离以便显示文本间的相似度。(3)可使用分类、聚类及多公式化等方法降低编码特征的维数。在低维数空间中可重新考虑聚类等问题。
2 常用文本挖掘算法
2.1 卡方检验
卡方检验的最基本思想是通过观察实际值与理论值之间的偏差来确定理论的正确与否[8]。通常假设这两个变量确实是独立的,观察实际值A与理论值E之间的偏差程度X2(理论值是“假如两者独立”时应有的值)。若偏差X2足够小,则认为误差是自然的样本误差,此时就接受原假设;如果偏差足够大,则认为这两者实际上是相关的,此时就接受备择假设。卡方检验的基本公式为:

在文本分类的特征选择阶段,主要关注单词t(随机变量)和类别c(另一个随机变量)是否相互独立。公式中A表示单词t属于类别c的文档频数,E表示假设单词t与类别c无关情况下的文档频数。用该方法可以得出单词同文档之间的相关性排序,计算值越大相关性越高。
2.2 朴素贝叶斯
朴素贝叶斯分类属于一种简单的分类算法,其思路是对于给出的待分类项,求解在此项出现的条件下各个类别出现的概率,概率最大的就认为此待分类属于哪个类别[9]。正式定义如下:
(1)设x={a1, a2,…,am}为一个待分类项,而每个a为x的一个特征属性;有类别集合C={y1, y2,…,yn}。
(2)计算 P(y1|x),P(y2|x)…, P(yn|x)。
(3)如果 P(yk|x) =max{P(y1|x), P(y2|x),…, P(yn|x)},则 x∈ yk。
条件概率计算可以按照如下步骤进行:
(1)找到一个已知分类的待分类项集合,即训练样本集。
(2)统计获得在各类别下各个特征属性的条件概率估计,即:
P(a1|y1), P(a2|y1),…, P(am|y1), P(a1|y2), P(a2|y2),…,P(am|y2),…, P(a1|yn), P(a2|yn),…, P(am|yn),…。
(3)如果每个特征属性都是条件独立的,则贝叶斯定理具有以下推导:

由于分母对于所有类别都是不变的,因此只需要最大化分子。 又因为各特征属性是独立的,所以有:
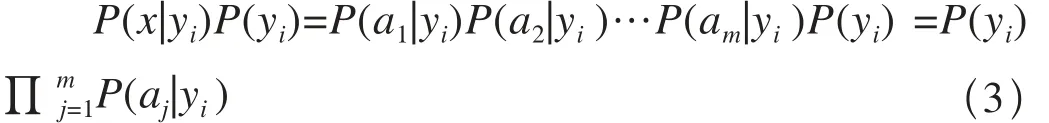
朴素贝叶斯可以分为形成训练样本集合、生成分类器和使用分类器3个阶段。在处理文本分类问题时,x是待分类文档,ai是文档的特征词,C是文档类别集合。朴素贝叶斯通过计算文档中每个特征词属于不同分类的概率,从而得到整篇文档的分类结果。
3 文本挖掘技术方案
3.1 文档预处理
目前,安全管理信息报告多以Word、Excel格式存储,Word格式文档又具体分为doc后缀和docx后缀两种,Excel格式文档又具体分为xls后缀和xlsx后缀。为便于后续分词操作,需要先将两种文档转换成TXT文本,字符集编码采用UTF-8格式。另外,还需要对转换后的文本进行无效词去除,比如特殊字符、原文档中页眉页脚等内容。
3.2 分词
对铁路专业的文档分词关键是构建能够理解铁路专业术语的铁路专业分词库。目前,社会上公开发布的专业分词库多为通用领域的,铁路行业本身并没有发布满足铁路文本挖掘需求的分词库。基于现状,本文采用基于搜狗提供的交通专业词库结合铁路领域专家确认后得到的铁路专业词库,综合常用词库作为分词的依据。
文章采用分词工具ICTCLAS对文档进行预处理,获得文本资料。分词后得到的词组中包含了许多对分析挖掘无效的词汇,比如标点符号、“但是”、“可以”等。本研究选取了较常见的1 893个词汇和符号构成的停用词表作为去除无效词的依据。
3.3 样本训练
分词结束后的文档集形成了M • N矩阵,其中,M表示文档集合中文档的数量,N表示文档中包含的词汇数量。另外,算法还生成了词汇编号表(对文档中所有出现的词汇进行顺序编号,矩阵中记录编号值)、词汇文档频次表(记录某一词汇出现在文档集中多少个文档中)以及文档分类信息表等。生成的矩阵以及信息表是后续的特征选择算法和分类算法操作的基础。本文使用python语言实现了卡方检验和朴素贝叶斯算法,采用卡方检验作为文本特征词提取的算法,文本分类算法选用的是朴素贝叶斯算法。
3.4 应用模型挖掘文本
某铁路局集团公司积累了2 480份铁路交通安全事故故障报告以及安监报信息。我们对上述报告文档进行了特征词提取,并去除“构成”、“故障”、“司机”、“调度员”等卡方检验值较高但对安全管理信息报告文档分析无意义的特征词,得到了对应该文档的特征词及卡方检验结果值,示例如表1所示。
卡方检验值越大则表明该词汇对当前文档分类的效果越明显。在此示例中,我们选取了卡方检验值最大的前20个词汇作为本文档的特征词。
安全管理信息报告主要分为安监报、设备故障调查报告和铁路交通事故调查报告等3类,本文选取了上述文档中安监报信息报告70份、设备故障调查报告50份、铁路交通事故调查报告30份,共计150份文档进行了人工分类,可以计算得出统计表1中特征词在各分类中出现的频率,如表2所示。
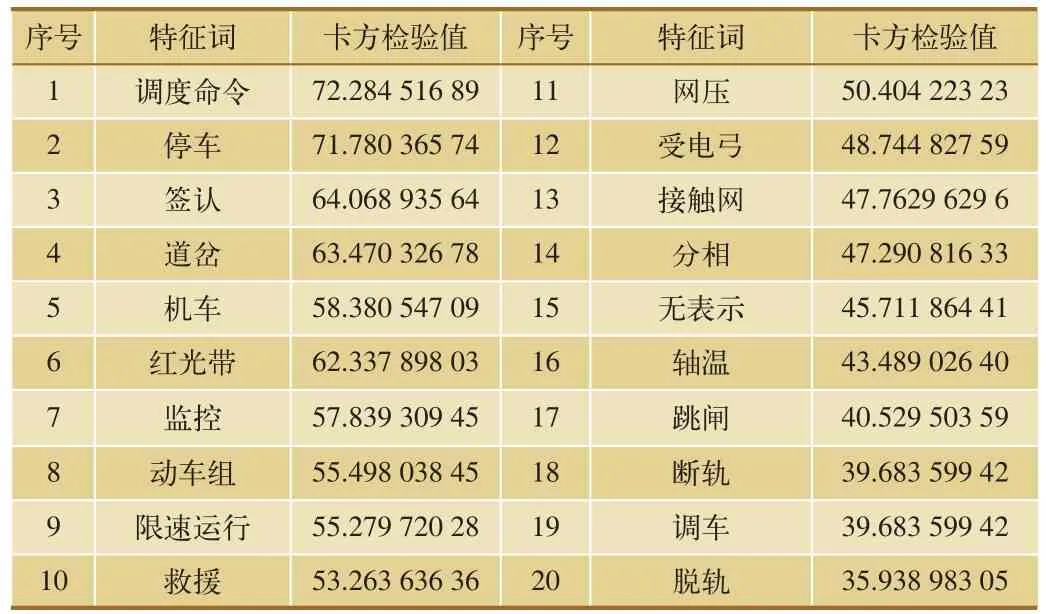
表1 卡方检验结果值
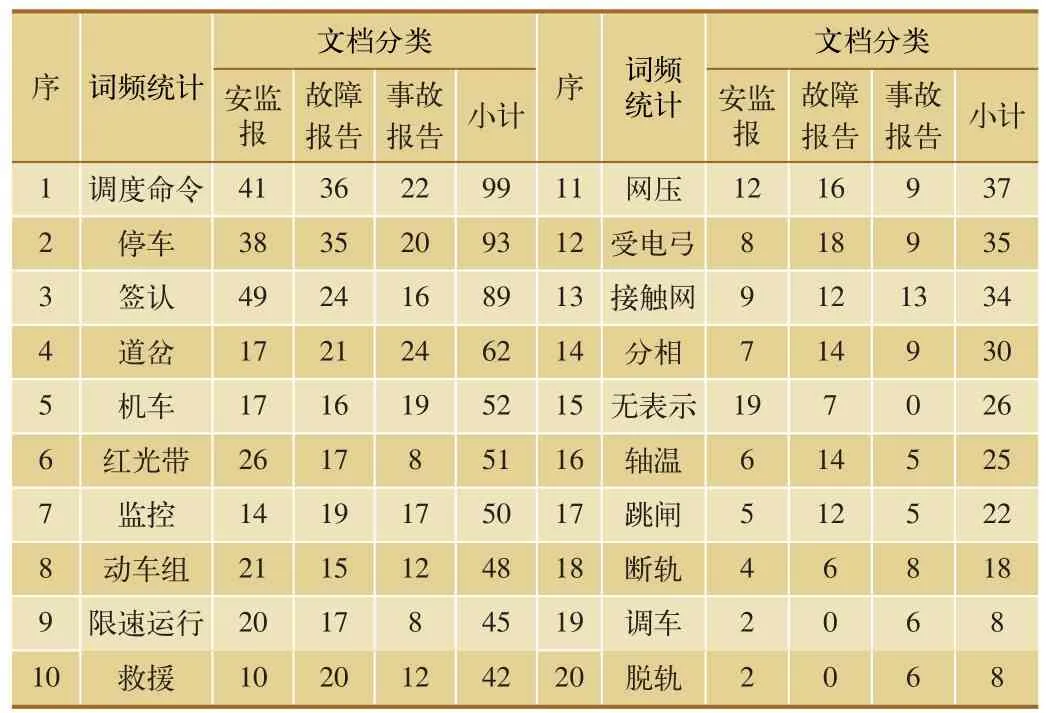
表2 文档分类及词频统计
基于上述特征词在分类中出现的词频及概率,可以通过朴素贝叶斯算法对剩余文档进行分类计算。经过验证,2 330份文档分类正确为2 003份,准确率达到了86%。
4 结束语
本文采用卡方检验和朴素贝叶斯算法对铁路安全管理信息报告文档的特征提取,可以较为准确地获取文档的关键词。但由于训练样本不足,同时文本录入者对关键词的习惯用法略有差别,准确率有待进一步提升。下一步将继续优化铁路安全管理信息文档的挖掘、检索和应用,最大限度地提取非结构化文档中的重要信息,并充分利用系统工程、事故致因等理论开展安全大数据应用研究。
