分子量分解问题优化设计模型
2018-09-10胡雨雯张嘉杨鑫
胡雨雯 张嘉 杨鑫


摘 要:本文首先研究了氨基酸合成蛋白质的规律,对于题目所给数据进行数据预处理,由于蛋白质合成方式复杂,我们假定了本题中只研究单链式合成而不考虑R基脱水缩合的问题。在此基础上,本文建立穷举模型,利用Fortran语言对算法进行实现,使用循环语句嵌套编写出能够给出确定蛋白质分子量下的氨基酸组合全部情况及计算机运行时间,由1000带入时运算结果为28268种,用时0.828秒。在此基础上,本文根据蛋白质中氮含量稳定为14%-18%这一约束条件,对所给出的程序进行优化,剔除与实际不相符的情况,蛋白质分子量为1000时有效结果为10954组,用时0.391秒。在实际情况中,蛋白质分子量远大于1000,使用优化后的模型能够推广到分子量更大的蛋白质成分分析中。此外,本文还讨论了质谱仪使用使得各类元素成分已知条件下如何进行分子量分解以及实验室不具备计算机时的利用质谱仪情况下蛋白质分子量分解的可行性。
关键词:分子量分解;优化模型设计;可行性分析;Fortran
一、问题重述
生命蛋白质是由若干种氨基酸经不同的方式组合而成。在实验中,为了分析某个生命蛋白质的分子组成,通常用质谱实验测定其分子量x(正整数),然后将分子量x分解为n个已知分子量a[i](i=1,.......,n)氨基酸的和的形式。某实验室所研究的问题中:
n=18,x1000
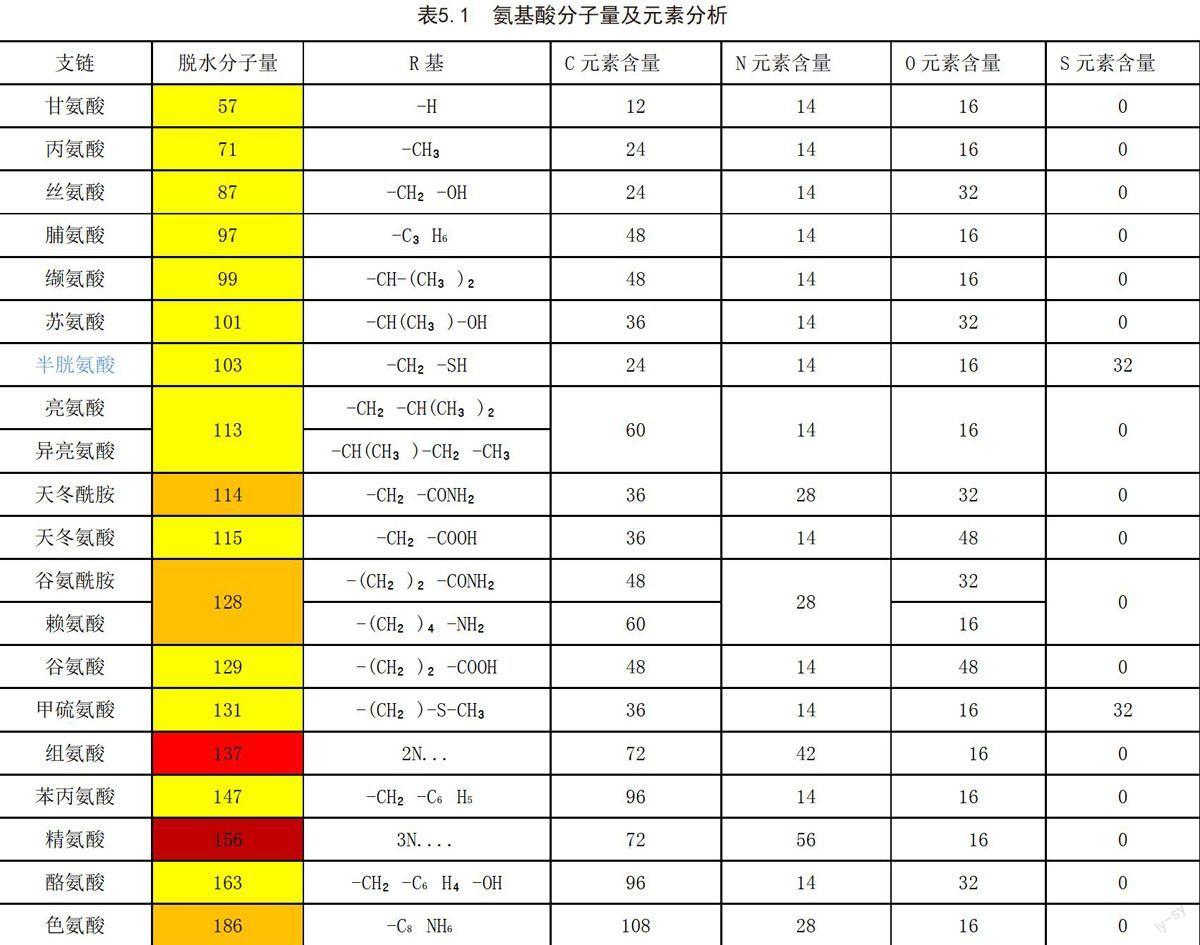
a[i](i=1,.......,18)分别为57,71,87,97,99,101,103,113,114,115,128,129,131,137,147,156,163,186
要求针对该实验室拥有或不拥有计算机的情况,对如何分解分子量x作出解答,即针对任意一个分子量x具体给出由哪些a[i](i=1,.......,n)氨基酸组成。
二、问题分析
(1)对于数据的分析
通过大量资料的查阅以及比对,我们发现了题目中所给出额的已知氨基酸分子量数值均为羟基和羧基脱水之后的分子量,所以按照题意分析,题目应仅考虑羟基羧基脱水缩合形成肽链的情况而不考虑R基可能发生的脱水缩合等复杂情况。
(2)有计算机情况下的分析
①初步分析:题目要求在已知蛋白质分子总量的情况下,使用计算机给出组成蛋白质的氨基酸种类及个数。题目条件中没有明确的对各个氨基酸或者各个元素给出明确的约束,在仅知道蛋白质总分子量以及各氨基酸脱水后的分子量的条件下,为了求得所有氨基酸组合,只能运用计算机语言编写穷举法运算程序,理论上能够实现输入给定蛋白质的分子量即可给出全部的氨基酸组成。但所得结果的数量过于庞大,对于蛋白质组成的分析意义不大。
②进一步分析:在没有约束的条件下,计算机的运算量过大,计算时间过长,所以在原先程序的基础上需要进行优化。在资料的查阅后,我们发现,在实际情况中,所有蛋白质中的氮含量基本稳定在14%-18%[1]之间。所以在加入蛋白质中氮含量约束后能够提高计算速度,减少解的数量,使得得到的结果更符合实际情况。
③再进一步分析:由于题目中说明实验室将采用质谱仪来對蛋白质进行成分分析,根据资料表明,在蛋白质含量测定实验中,质谱仪不仅能够测定出蛋白质的分子量,还能够给出每种元素占总分量的比例[2]。据此可以添加多个约束,从而更快速的得到更为准确的结果,所得结果对于蛋白质组成分析有重要意义。
(3)没有计算机情况下的分析
在没有计算机的情况下,我们首先可以知道蛋白质的分子量与氨基酸的分子量为一个线性组合,即假设已知蛋白质分子量的情况下,可以将题目转化为一个线性规划问题进行求解。此情况下,蛋白质分子量较小时,通过人工计算也可以较为简单地得到蛋白质中各氨基酸的数目,但当分子量数值较大时,人工计算量急剧增大,没有可行性。
三、模型假设
(1)在氨基酸合成蛋白质时不考虑R基脱水缩合的情况,仅考虑氨基与羧基脱水缩合;
(2)蛋白质中氮元素含量在14%-18%之间;
(3)实验室所用质谱仪能够准确测定出蛋白质分子量以及各元素所占比例,不存在误差;
(4)不考虑氨基酸排列的先后方式,仅考虑不同氨基酸的组合方式;
(5)所得蛋白质均为环状,即蛋白质的分子量=各氨基酸脱水后的分子量之和。
四、符号系统
五、模型建立
(1)对题目所给数据进行预处理
题目中仅仅给出了18种氨基酸的分子量,根据资料的查找并利用数学软件进行分析,分析结果如下表:
表5.1 氨基酸分子量及元素分析
(2)蛋白质中氮含量约束模型建立
根据本题的初步条件分析,蛋白质的分子总量等于氨基酸缩
水之后分子量的总和,由此我们可以得到下式:,且Xi必为非负的整数,即:
由此,我们可以得到初步模型:
在此模型的基础上,我们利用Fortran语言针对穷举模型进行了程序的编写,即输入实验室测得的蛋白质分子量,计算机即会给出所有符合条件的氨基酸排列组合。在模型的实现过程中,我们采用了18重循环语句的嵌套。考虑到减少重复运算,我们在每一步循环语句的处理中减去了上一步的假定值,这使得我们的程序得到了优化,大大减少了计算机的运行时间,能够更加快捷的得出所需的结果。
(3)多重元素约束模型建立
虽然能够得出已知蛋白质分子量条件下较为优化的结果,但随着分子量的增大,氨基酸可能的组合种类的数据非常庞大,据此数据,实验室无法进一步得出最符合被测蛋白质真实氨基酸组合的情况。根据资料的查阅和分析,运用现有质谱仪技术不仅能够准确给出蛋白质的分子量,同时也能够给出各个元素占总分子量的比例。
根据此模型,我们对程序进行了进一步的修改。具体程序将在附录中一并给出。利用本程序,输入氨基酸分子量及C、N、O、S四中元素所占比例,程序即可给出所有满足约束条件的组合情况。
(4)无计算机条件下的求解
题目是典型的多元一次不定方程的求解问题,在此证明无计算机情况下,手动求解理论上可以得到答案,但无实际的可操作性。
本题是求解一个十八元一次不定方程的非负整数解,即求方程的非负整数解。由线性代数的相关知识知,方程有整数解的充分必要条件为,其相关证明可由辗转相除法给出,在此不作证明,有需要可查阅相关资料。
对于本题而言,而对任意正整数成立,则对于任意分子量X,…,必然存在整数解,使得满足方程。在此可以用辗转相除法来求得各的具体取值,但解中需要排除负整数解,对于X的值较小时,人工求解的方法可行,但随着X数值的增大,计算量上升,人工求解相当困难,所以不建议采用该方法。
六、模型分析
在我们模型的建立中,随着约束一步步的增加,使得程序运算更加具有高效性和准确性,能够有效的剔除与实际情况相差甚远的氨基酸组合种类,在众多可能性组合中能够选取出与蛋白质实际组成方式相近的氨基酸组合方式。
对于没有计算机的情况,我们能够给出證明,在理论上验证所得十八元一次不定方程存在非负整数解,对于较小的X值可以实现人工求解。
七、模型推广
现实情况中,蛋白质的分子量均远大于1000。我们优化后的模型能够很好的推广至求解大分子量蛋白质的氨基酸组成问题,能够保证准确性的基础上高效的解决问题。此外,对于化学、生物等领域类似脱水缩合而成的高分子化合物的成分分析等问题,均可以将我们的模型进行一定的修改后使用。
八、结论
本文通过初步建立穷举模型,并根据题目所给条件一步步增加约束,对模型进行优化,给出了能够求解问题的最优化模型。该模型操作简便,只需输入实验所测得数据即可得到所有符合条件的组合结果,符合实验室使用要求,并且能够大大缩短计算机运行时间,并且能够剔除与实际情况相差很大的组合方式,满足了建模要求的准确性、高效性。
参考文献
[1]百度百科,词条:蛋白质
[2]方慧生,相秉仁与安登魁,质谱在蛋白质及多肽氨基酸序列分析中的应用. 药学进展,1993(04):第196-201页
