基于AFC数据和RF模型的城轨车站服务功能分类
2018-09-10王子甲刘海旭TAKUFujiyama
王子甲,刘海旭,TAKU Fujiyama
(1.北京交通大学土木建筑与工程学院道路与铁道工程系,北京100044;2.伦敦大学学院土木、环境与测绘学院交通研究中心,伦敦WC1E6BT,英国)
0 引言
随着我国城市轨道交通建设的快速推进,多个城市逐步形成了较为完善的轨道交通线网,然而当前缺乏从较长时间跨度内量化分析城市轨道交通与城市结构之间的互动关系.而自动售检票系统(AFC)的广泛使用,使得运营单位采集到了海量的城市出行时空信息.这为车站服务的乘客类型及其时空演变挖掘与分析提供了丰富的数据资源,使得量化分析轨道交通线网与城市结构互动关系成为可能.
利用AFC刷卡数据进行交通系统的分析与研究是近年来的热点主题[1],既有研究的一个方向是以乘客为研究对象,基于刷卡数据识别乘客的出行模式,这些研究为理解乘客出行行为提供了新视角[2-3];而以车站为研究对象,利用刷卡数据对车站进行分类,从而针对不同种类的车站制定不同的运营政策,用以提高轨道交通的效率是当前AFC数据挖掘的另一个方向[4-5],但不同于乘客出行模式的识别,现有的车站分类算法较为简单,可靠性较差,制约了车站分类结果的应用范围和成效.
随机森林算法(RF)[6]经过多年的发展,现已成为机器学习领域应用最为广泛的算法之一.国内外的大量研究均显示了RF应用灵活,准确高效的特点[7-9],然而目前在轨道交通数据挖掘领域,利用该算法的研究仍较少.为了从车站服务乘客类型的角度揭示轨道交通线网视角下的城市结构特征,本文利用RF模型进行车站服务功能分类.
1 车站功能分类的有监督RF模型构建
RF是集成学习的一种.在训练过程开始时,每一颗决策树均利用bootstrap重抽样方法从原始样本抽样,随机选取原始训练集中的部分指标,分别独立进行建模.训练过程中,RF利用bootstrap重抽样方法剩余的袋外(Out-Of-Bag,OOB)数据计算模型准确率,从而评估模型的准确程度.模型构建完成后,对于新的记录,RF组合所有决策树的预测结果,通过投票得到最终的预测结果.
本节采用了北京地铁2017年3月13~17日连续5个工作日刷卡数据,选取了8个指标来表征每个地铁车站服务客流的属性,其标记及定义如下:
(1)早高峰进站客流量/全天进站客流量(F1),晚高峰进站客流量/全天进站客流量(F2),早高峰出站客流量/全天出站客流量(F3),晚高峰出站客流量/全天出站客流量(F4).早高峰取6:30-9:30,晚高峰取17:00-20:00.
(2)ABBA_A客流量/全天刷卡客流量(F5),ABBA_B客流量/全天刷卡客流量(F6).ABBA_A客流量表示满足1天中从A站进B站出再从B站进A站出的乘客在A站的进站量,ABBA_B则为此类客流的B站出站量.
(3)一票通比例(F7),表示使用临时卡进出站客流量占全天客流量的比例.
(4)单次进站与单次出站客流量之和/全天刷卡客流量(F8),表示1天内在某车站内仅进站1次或出站1次的客流量与全天客流量的关系.
其中F1~F4表征了车站早晚高峰特征,F5和F6刻画了具有严格通勤特性的客流比重,F7和F8用以衡量乘客的无规律出行.
截止2017年3月,北京市共有288个城轨车站(换乘站不重复统计),综合已有的研究及北京市第5次交通大调查[10-11],选取28个典型车站组成训练集,占车站总数的9.7%.利用车站主要服务的客流类型来确定车站的分类,将这28个车站分为4类,包括:以北京西站、天安门东站为代表的服务交通枢纽及旅游商业类客流的车站;以天通苑站、沙河站为代表的服务居住类客流的车站;以中关村站、国家图书馆站为代表的服务工作类客流的车站;以及以望京站、太阳宫站为代表的服务居住及工作混合类客流的车站,其各指标如表1所示.
对训练集进行RF建模,OOB错误率为3.57%达到最小,利用此模型进行车站分类,结果如图1所示.
如图1所示,RF识别出了T2、T3航站楼、北京南站等典型的交通枢纽类车站,以及南锣鼓巷、什刹海、王府井等典型的旅游商业类车站;对于工作类的车站,其主要为以中关村为核心的车站群及以国贸为核心的车站群;位于工作类车站周边的大多为居住与工作混合类车站,这些车站处于工作区与居住区的交界位置,具有工作类车站及居住类车站的双重特征;而位于城市外围的车站大部分均为居住类的车站,其附近及接驳服务范围内大多为居民区.上述结果与北京交通调查数据吻合较好[11].

表1 训练集部分车站指标Table 1 The index of training dataset
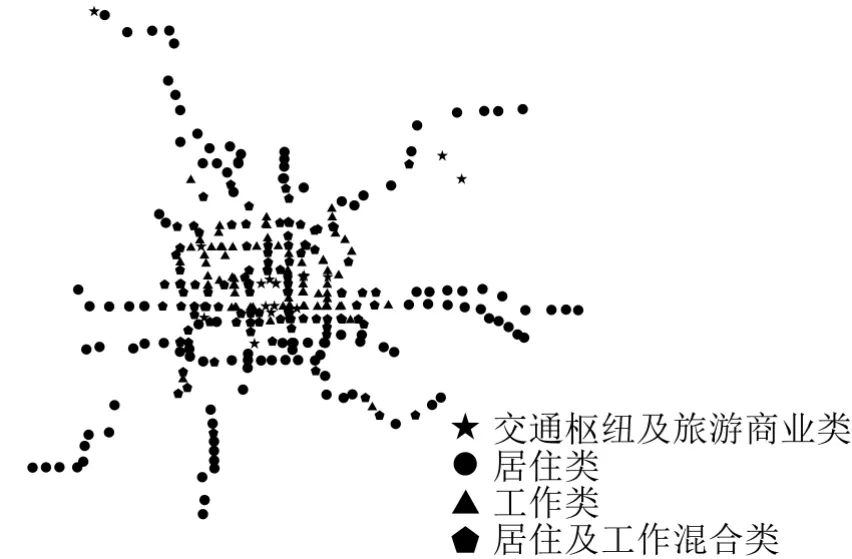
图1 有监督RF法的2017年车站分类结果Fig.1 2017 station classification based on supervised RF method
RF利用少量的样本相对准确地识别出了北京市现有车站客流属性.然而由于RF属于典型的监督学习算法,即需要指定训练集.训练集的选择在较大程度上依赖于研究人员的主观经验,可能会导致训练集缺少典型车站或者对车站的分类存在错误等问题.
2 车站功能分类的无监督RF模型
2.1 方法原理
在RF训练过程中,当2个样本出现在同一节点时,即表明这2个样本被分到了同一类.在模型训练结束后,可以得到任意2个样本出现在同一节点的次数与总结点数的商,其大小可以用来表征2个样本之间的相似程度,即模型训练结束后可以返回表征任意2个样本之间相似性的矩阵.周绮凤对相似性矩阵研究后证明,RF的这种相似性度量方式能够有效地使样本在相似度空间的差异变大,可以更有效地区分样本[12].
由于RF建模过程中训练集数据必须有相应的分类,为了完成RF建模过程,将真实的数据标记为一类,之后基于真实数据,利用不同的抽样方式生成和真实数据相同数据量的伪造数据,将其标记为相应的类别,然后将得到的所有不同类数错误率最低时,完成模型的构建,返回上述相似性矩阵,删除矩阵中伪造数据对应的项目,得到真实数据中任意2个样本之间的相似程度[13].基于这个相似性矩阵,采用PAM方法进行聚类,利用每一类中的典型车站识别车站分类类别,得到最终的车站分类结果.
2.2 方法实现
Shi对于不同分布的伪造数据对于分类结果的影响进行了研究[14],本文在此基础上,采用了两种方法来制造伪造数据.对于真实数据,将其标定为“class1”,作为第1类数据;第2类数据标定为“class2”,为伪造数据,生成方法是对真实数据集中相应指标所有可能的取值进行随机有放回抽样,因此此类数据的值均来自于真实数据集.给出生成过程的伪代码如下.


其中,UniformRandom函数表示在index[j]的数据中进行有放回随机抽样.
为了使伪造数据与真实数据集的差别更大,假设真实数据集中的每个指标服从正态分布,采用极大似然估计方法求得相应分布,以此为基础进行新数据的抽样,制造第2类伪造数据,将其标定为“class3”,此类数据中含有大量真实数据集中不存在的值.给出生成过程的伪代码如下.


其中,NormalRandom函数表示在index[j]的最大值及最小值区间内抽样,且其分布服从于以index[j]的均值和方差为参数的正态分布.
以2017年的数据为例,图2显示了3类数据的各指标分布箱型图.由图2可知,在这8个指标当中,真实数据(class1)与第1类伪造数据(class2)总有类似的分布,而第3类数据(class3)的部分指标分布则与前2类数据有显著不同.

图2 3类数据不同指标的分布图Fig.2 Distribution of different indicators of three types of data
利用上述3类数据进行建模,OOB错误率最小值为15.00%时完成模型训练,返回相似性矩阵.图3展示了日客流量排名前15的车站之间的相似度.
此相似性矩阵为实对称矩阵,其对角线处的值均为1.矩阵为稀疏矩阵,这表明客流量大的车站均位于不同的分类之中,其属性较为分散.
采用PAM算法,利用2个数据之间的相似性进行聚类,得到图4的结果.
与传统RF结果比对,2种方法中92%的车站具有相同的分类,这表明无监督RF在很大程度上与经验吻合,但避免了主观判断.分别采用相似性矩阵度量及传统聚类评价指标DB指数[15]两种方式评估两种聚类方法.通过将一类中的每一个车站与其他车站的相似性求和,再将每一类总的相似性相加,从而得到分类结果的总相似性,其值越大,则表明总的划分结果越准确.通过计算,有监督RF总相似性为6 009.76,无监督RF的总相似性为6 024.76;DB指数在聚类结果评价领域运用广泛,其值越小表示聚类结果越好,经计算有监督RF为1.00,无监督RF为0.94.两种方式均表明无监督RF的分类结果更好.
图3 日客流量前15的车站之间的相似度Fig.3 Similarity between stations in the top 15 passenger traffic
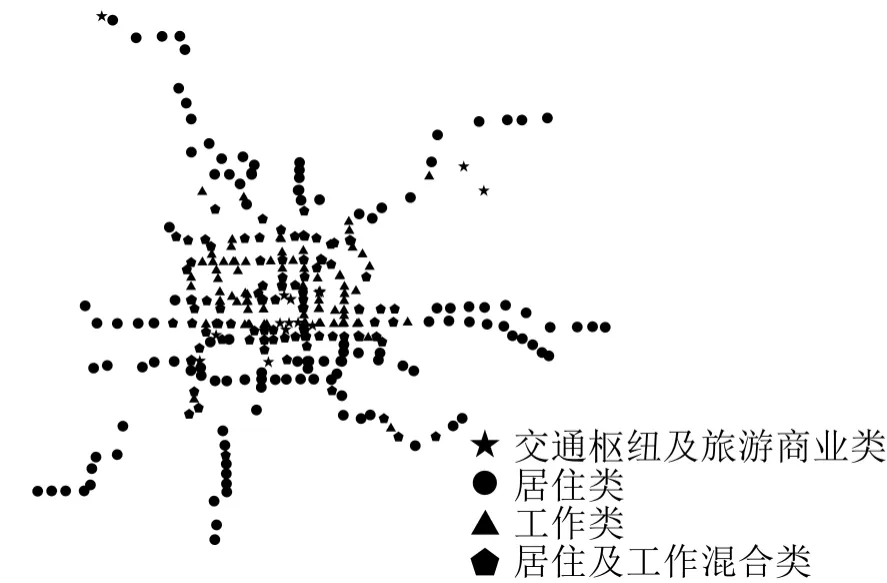
图4 无监督RF法的2017年车站分类Fig.4 2017 station classification based on unsupervised RF method
3 车站服务功能时空演变
基于北京轨道交通2014年以来的刷卡数据积累,在每一年中均选取数据进行分类,首先通过GIS展示多年来不同种类车站的空间分布,即车站服务功能的空间演变,其结果如图5所示.
由图5可知2014—2016年,北京市轨道交通的线网规模不断扩大,线路不断向外部延伸,但各类车站的空间分布格局基本保持不变.
利用桑基图表示4年来不同车站类别之间的转换关系,展示车站服务类型随时间的变化过程,如图6所示,由图6中可知:

图5 北京市2014—2016年城轨车站服务客流类型Fig.5 Types of passenger flows urban rail stations serve for in Beijingin 2014,2015 and 2016
(1)服务于居住类客流的车站是主体.结合图5,在大的空间尺度上,北京市依然具有明显的圈层结构,其职住分离现象较为明显,轨道交通承担着沟通城市内部工作与城市郊区居住的功能,这种基本情况在短时间内并未发生改变.
(2)服务于工作类客流的车站数量呈上升趋势.该类车站分布中心不变,分布范围有扩张趋势.这表明在城市核心区的岗位密度在加强,并不断向外部扩张,这些车站的客流规律性会更强化.
(3)同时服务居住与工作的混合类客流的车站数量逐年上升.这与上述的城市工作区的向外拓展相适应.但一方面,由图5所示,这类车站大量分布于城市的主城区,说明在城市中心区仍然存在大量需要乘坐地铁去工作的人,显示出城市内部职住分离现象也较为严重;另一方面这类车站的来源可能是其他3类车站,而其发展方向也有可能是其他3类车站,说明这些车站所在的地区是城市变化较为激烈的地区,其并未形成稳定的属性,较易受到后续社会经济发展的影响.
(4)服务于交通枢纽及旅游商业的车站数量逐年下降,且其范围不断缩小.至2017年该类车站大多分布于天安门附近,原有的此类车站部分转变为工作客流服务的车站.其原因主要是北京市枢纽规划调整与落实,造成部分该类车站失去服务对象,通勤特性凸显.
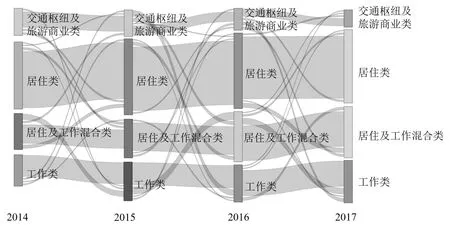
图6 车站服务客流类型演变Fig.6 Evolution of station service flow types
综上,只服务于居住类及工作类客流的车站数量基本保持稳定,这表明现有的城市功能区中的居住区及工作区将在现有的基础上保持稳定,短期内并未有明显的改变趋势,而随着北京轨道交通线网不断向外部延伸,服务居住类客流的车站数量将会有少量增加;服务交通枢纽及旅游商业类客流车站由于自身功能被分散到其他类型的车站,其数量在4年中逐渐下降,但此类车站的剩余部分,其不可替代性较高,因而今后一段时间,其数量将保持基本稳定;由于服务居住区与工作区的混合类车站具有较强的不确定性,其发展方向将受到之后一段时间内社会经济政策的影响,其所在的区域将是城市变化最为激烈的地区,加强对这些地区的调查研究,制定相应的规划方案,对其进行科学的规划和管理,将是未来城市发展的关键.
4 结论
本文提出了一种无监督RF方法,在保证精度的前提下,有效的避免了传统RF在本领域训练集选择上依赖主观经验的弊端,并且以北京轨道交通AFC数据为基础,分析了2014—2017年车站服务客流性质的变化过程,反映出轨道交通线网对职住分布及城市结构的塑造作用.这为进一步认识城市轨道交通网与城市结构的互动关系提供了借鉴.
然而本文尚有不足,一方面针对于反映车站属性的指标的选择,本文只选取了AFC数据中能提取的指标,对于乘客个人社会经济属性等能反映乘客类型的指标未涉及,不同经济属性的乘客出行规律性程度不同,对于交通政策变化的敏感程度也不一样,这意味着对同一类车站的政策调整会对客流造成不同程度的影响;而另一方面,本文将车站分为4类,其中交通枢纽将旅游商业类归为一类,并没有精确地将其区分开来,针对这个问题,后续的研究中应尝试采用不同的指标来表征车站属性,并且对分类的数量进行研究,以期进一步提高分类精度.
