基于CNN卷积神经网络的企业电子档案分类法研究
2018-09-10
随着大数据﹑云计算等现代信息技术的发展,传统的纸质档案快速向电子化﹑数字化档案进行转变,档案管理模式出现了深刻的变化。档案管理的分类﹑检索等基本方法也随之产生了变化。本文参考Kim提出的神经网络模型,自动提取档案文本的特征集合,使用Word2vec进行词向量训练,旨在进一步提高电子档案的分类准确率。
一、CNN卷积神经网络
(一)神经网络
神经网络是一些具有适应性的神经元组成的集合。神经元是神经网络的最小组成单位,是一种二元线性分类器感知机制。
输入x1和x2分别和各自的权重w1和w2相乘﹑求和,所以函数f=x1*w1+x2*w2+b=f(∑2i=1Wi+b)(偏置项,可以选择性地添加)。函数f 可以是任意的运算,但是对于感知机而言通常是求和。函数f 随后会通过一个激活函数来进行评估,该激活函数能够实现期望分类。
把多个神经单元堆叠在一起,并组成分层结构。前面一层的神经单元(隐藏层)通过f函数的输出结果作为下一层的输入,再通过f函数和激活函数得到最终的分类,这就形成全连接的神经网络。
(二)词向量
词向量也叫词嵌入,是通过神经网络来训练语言模型,在训练过程中生成一组向量,这组向量将每个词表示为n维向量,可理解为文本的数学化表示。一种最简单的词向量方式是One-Hot Representation,就是用与词典等长的向量来表示一个词,该词所在词典的索引对应分量1,其余分量全为0,例如“工程师”表示为[0 0 0 1 0 0 0 ...]。One-Hot方式非常简洁,仅需为每个词分配一个数字编号即可,但该方式容易出现维度灾难,不能较好地刻画各词语之间的相似性。另一种是Hinton在1986年提出的Distributed Representation 向量方式,很好地克服了One-Hot方式的缺点。该方式通过语言模型的训练,用固定长度的短向量来表示词语;将所有的词向量放在一起,形成向量空间。在该空间上不同词语之间的距离,就是该词语法﹑语义之间的相似性。而Word2vecs是谷歌Tomas-Mikolvd团队研发的一款开源的词向量产生工具,本文即利用Word2vecs来训练职员电子档案的语言模型,获取相应的词向量集合。
(三)卷积神经网络
CNN卷积神经网络是深度学习技术中极具代表的网络结构之一,在图像处理领域取得了很大的成功。在国际标准的ImageNet数据集上,许多成功的模型都是基于CNN的。近年来,该技术在自然语言处理﹑语音识别等方面均有突破性应用。下文基于CNN卷积神经对职员档案进行分类搜索,即是基于CNN在自然语言处理中的应用。
不同于普通网络神经算法,CNN卷积神经网络的特征抽取器由卷积层和子采样层构成。卷积层中存在着若干个特征平面,每个平面由一些矩形排列的神经元组成(神经元只与部分邻层神经元相连接),这些神经元共享权值,称为卷积核。先用随机小数矩阵的形式对卷积核进行初始化操作,再通过语料训练过程得到合理的权值。卷积核的应用减少了神经网络各层之间的连接,降低了拟合风险。子采样也称为池化层,具有最大值子采样和均值子采样两种形式。子采样的过程就是一种特殊的共享权值的过程。卷积和子采样的引入精简了神经模型的参数,简化了它的复杂程度。
二、模型结构
Kim对基于自然语言文本处理的CNN卷积神经网络作了详细的阐述。其结构包含输入层﹑卷积层﹑池化层﹑全连接及SOFTMAX层[1]。根据CNN卷积神经网络的定义和模型结构,具体建模流程如下:
(一)数据预处理
以企业人才简历档案分类为例,抽取人才档案库中名称为软件工程师的档案10000份,其中8000份作为训练集,2000份作为验证集,并计算各档案的特征矩阵。具体步骤如下:
1.首先用分词工具对训练集中的每个档案T进行分词处理,并进行去重﹑剔除无用词语﹑删除标点符号﹑删除空格等处理得到档案T的词典TD。用Word-2Vecotr对TD进行向量初始化,并将初始化的结果合并到词向量空间R中;
2.然后将每条档案T进行分词处理,得到词序列wi(i)。将wi带入向量空间R中,得到对应的词向量vi(i);
3.再将T的词向量序列vi作链接操作,得到档案T的特征矩阵。
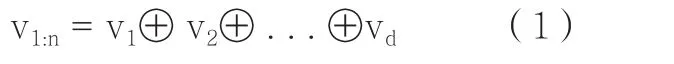
4.最后将词向量序列vi按照先后顺序,从上到下排列。公式(1)的结果档案T的特征矩阵则转换为词向量空间Rd:n的特征矩阵

接下来,将特征矩阵T作为输入参数,通过卷积﹑池化操作获得档案的句子向量。
(二)卷积操作
卷积操作的本质是对档案序列进行特征抽取的过程。具体流程如下:
1.设定卷积核WRdn,则卷积核W所围的单词个数即卷积核的尺寸,称为hn(h为W的行数)。在档案的文本中,单词语义只存在竖向相关性,故卷积核只作步长为1的竖向卷积操作;
2.将档案矩阵T的子矩阵Xi,XiRd:n,i分别与卷积核序列W进行如下运算:

bRn是对矩阵T进行调整的偏差值,f是双曲正切激励函数。将卷积核与Xi进行d-h+1次卷积运算,得到卷积矩阵C。
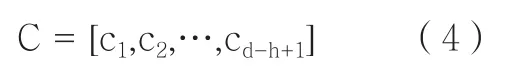
为了更全面﹑准确地获取每个职员档案的特征值,提高数据平滑性,本文分析中通过在卷积层中设置m个卷积核,将X与m个卷积核进行卷积运算,得到m个卷积矩阵Cm,并投入到池化层中进行降维处理。
(三)池化操作
档案T的句子经过m个卷积核进行卷积运算以后,生成m个R(d-h+1)x1空间的句子向量C,将C做池化运算:
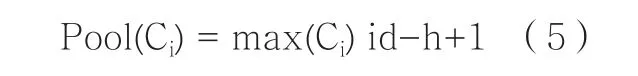
将m个卷积矩阵C进行以上运算,得到一个Rmx1空间的句子特征向量P:

然后再将向量P作为分类的输入参数,最终得到分类结果。
三、分类器
经过前述操作步骤,已将建立档案T转换为T所包含全部词向量的特征矩阵,并通过卷积﹑池化操作得到T的特征向量P。接下来,将通过全链接方式链接Softmax多分类的分类器。
分类器的作用,是对特征向量P进行计算,分别得出各个分类的概率,取概率最大的分类作为该档案T的分类。
分类器处理过程如下:
1.整理出数据集D = {x(i),y(i)},i∈[1,n]。其中y(i)是y(i)[1,k]的整数,表示该样本所属的分类,SoftMax函数为:

这里的x(i)仍然是增广向量形式:[1,x1,x,…,xk]。对于样本x(i)使用上述公式计算,得出该样本属于j类的概率δj
(i)。计算样本属于各个分类的k个概率,并选取概率最大的类作为样本的最终分类。
2.令I×为指示函数,即I{值为真}=1,I{值为假}=0。再令 qj
j=I{y(i)=j},利用对数最大化似然估计得到损失函数:
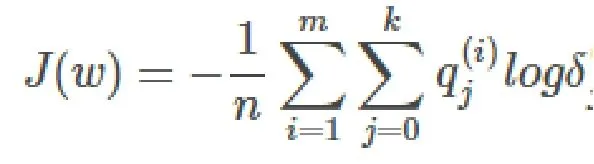
3.利用梯度下降法最小化误差函数J(w),对其求w的偏导数,得到结果:
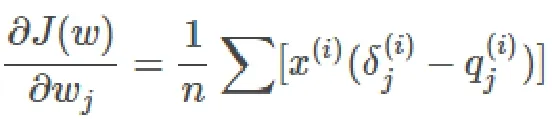
迭代公式为:

四、模型试验
为更直观地分析CNN神经网络与其它分类算法在电子档案分类识别上准确率和效率的差异,本文用TensorFlow 编程实现了上述模型处理过程,进行对比试验。
(一)数据集
从档案库中抽取10000份名称为工程师的电子档案数据,随机抽样取 8000份档案作为训练样本,其余的作为验证测试数据。
(二)实验效果
通过对比试验,发现使用机器学习的几种算法都能实现对测试电子档案的有效识别和准确分类,从而大大降了用于人工搜索与阅读判断其所属分类的时间成本。
对比以上结果,由Facebook开发的快速文本分类器FastText提供了简单﹑高效的文本分类和表征方法,但在电子档案区分度不大的情况下,分类准确率有待进一步提高。TextGrocery则是一个基于SVM算法的短文本分类工具,内置结巴分词,但是从时间和准确率来看,综合效果并不十分突出。而基于卷积神经网络CNN的档案分类算法,特征学习力能力优异,特征对数据本质的刻画最为准确﹑深刻,更有利于档案的分类和区分;虽然耗时达1360秒,但与人工区分筛选耗时相比,该运行时间完全可以接受。
五、总结
本文提出基于卷积神经网络CNN的电子档案分类模型。该模型充分考虑了中文档案文本特征稀疏﹑含有大量专业词汇等特点。试验表明,CNN卷积神经网络分类模型相比TextGrocery﹑FastText等经典分类器准确率大大提高。Word2vec训练模型的引入,极大地提高了在充分考虑语义特征情况下的中文单词训练和向量词典初始化的效率。在试验过程中,还发现不同的卷积核数量和初始化方法对分类的结果具有一定的影响。未来的研究重点是如何优化选取卷积核数量和分类的方法,更好地提高档案分类的准确率。
