风机叶片结冰故障预测模型及其实现方法
2018-09-04杨志和
杨志和, 向 哲
(上海电机学院 电子信息学院,上海 201306)
随着风机的设计功率不断提升,风机塔筒高度也在不断增长,冬季在北部沿海和山区有大量风机会触碰到较低的云层,在低温和潮湿环境下风机的叶片非常容易结冰[1],对风机的发电性能和安全运行造成较大威胁。目前,风机运行的实时数据主要由数据采集与监控(Supervisory Control and Data Acquisition,SCADA)系统存储。对叶片结冰故障的监测手段主要是比较风机实际功率与理论功率之间的偏差,当偏差达到一定值后会触发风机报警,并停机。然而,触发报警往往发生在叶片大面积结冰后,从而增加了叶片折断、损坏的风险[2]。虽然目前许多新型风机都设计了自动除冰系统,但在实际应用中的难题是对结冰的早期过程进行精确预测,在正确的时机开启除冰系统。因此,提高自动除冰系统对叶片结冰预测的准确性是亟待解决的问题[3]。
国内外在故障预测与诊断方面的研究已经比较成熟。例如,Ahmad等[4]在新开发的故障检测系统中对不同的基于数据流的线性回归预测方法进行了测试和比较。结果表明,线性回归方法在短期数据预测方面具有良好的性能。最好的性能是平均绝对误差(MAE)在0.4左右,表示预测精度为87.5%。文献[5]中采用最小量化误差的神经网络法,对飓风引起的停电持续时间进行预测,达到较好的效果。在国内,郭宇等[6]提出一种基于灰色粗糙集与BP神经网络的设备故障预测模型。用灰色关联分析、粗糙集理论分别对二维故障决策表进行横向和纵向两个维度的约简,将冗余的数据和属性去掉,并将约简后的数据输入到BP神经网络,预测设备故障;文献[7]中利用SCADA系统的监测大数据作为特征集,经SVM验证具有较高分类精度,降低了单参数特征集对于分类的误报率。但是,上述方法存在故障点判定的准确率不高的问题。文献[8-9]中分别将自回归积分滑动平均模型(Auto Regressive Integrated Moving Average Model,ARIMA)与BP神经网络模型相结合,建立的模型分别用于季节性时间预测和碳排放强度预测,取得了较好的效果。受此启发,本文将ARIMA模型和非线性自回归神经网络(Nonlinear Auto?Regressive Neural Network,NARNN)模型相组合,建立了NARNN-ARIMA模型(简称NARIMA),对SCADA系统产生的大数据进行分析;先建立ARIMA模型来预测数据的线性成分,再用NARNN模型预测相应的残差部分,然后对风机叶片结冰故障的时间序列进行拟合。仿真结果表明:NARIMA模型用于风机叶片结冰预测具有可行性,且在短期内预测较为准确。
1 NARIMA模型建立
本文提出了基于NARIMA(NARNN-ARIMA组合模型,NARIMA)模型设备故障预测模型,即新型ARIMA模型。该模型以ARIMA模型为基础,有效结合了差分平稳处理方法、游程平稳检验方法、线性最小方差预测模型等,解决了传统统计预测方法中多步预测误差较大、非平稳序列分析效果差、缺乏系统的软件实现等问题[10]。NARIMA模型中使用自回归项(Auto Regressive,AR)、单整项(Integration,I)和移动平均项(Moving Average,MA)3种形式对扰动项进行建模分析,使模型同时综合考虑了预测变量的过去值、当前值和误差值,将非平稳时间序列转化为平稳时间序列,然后将结果变量做自回归和自平移,从而有效地提高了模型的预测精度[11]。
风机叶片结冰故障预测NARIMA模型实质是先对非平稳的SCADA历史数据Yt进行d(d=0,1,dots,n)次差分处理得到新的平稳的数据序列Xt,将Xt拟合ARMA模型,然后再将原d次差分还原,便可以得到Yt的预测数据。其中,ARMA模型的一般表达式为
yt=c1yt - 1+c2yt - 2+…+cpyt - p+
nt+d1nt - 1+…+dqnt - q
(1)
式中:c1yt-1+c2yt-2+…+cpyt-p为自回归部分;非负整数p为自回归阶数;c1,c2…cp为自回归系数;nt+d1nt-1+…+dqnt-q为滑动平均部分;非负整数q为滑动平均阶数;d1,d2,…,dq为滑动平均系数。
用NARIMA模型来进行基于时间序列分析与预测时, 设p为自回归项,q为移动平均项数,d为时间序列成为平稳时所做的差分次数,AR是自回归,MA为移动平均,当时间序列呈季节性趋势时,要用乘积季节模型NARIMA×(P,D,Q)12来预测未来值。其中D为季节性差分次数,P,Q分别为季节性自回归和移动平均阶数。通过建立ARIMA模型进行风机叶片结冰故障预测的基本流程,如图1所示。

图1 NARIMA分析流程图
应用NARIMA模型进行基于时间序列分析与预测的应用过程主要分为3个步骤,具体描述如下:
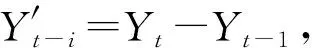
(4)
(5)
(6)
(7)
检验所建立模型是否能满足平稳性和可逆性。
残差序列可由估计出来的模型计算得到,如果残差序列的自相关函数不显著非零,可以认为是独立的。若这两项验证通过,则认为该模型是合理的,否则,应重新选取模型,重复上述步骤,直到选出有效的模型,然后应用该模型进行预测[14]。
(2) 用NARNN模型预测由ARIMA模型预测产生的残差部分,即εt=Zt-Lt。其中,εt为由ARIMA模型预测产生的随时间t变化的残差部分;Zt和Lt分别为实际故障率和由ARIMA模型预测的故障率。
(3) 分析预测,即利用已通过检验的模型进行预测分析。通过上述步骤得出预测模型
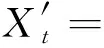
Φ(L)Δdxt=δ+Θ(L)ut
(8)
将被预测对象随时间推移而形成的数据序列视为一个随机序列,用式(8)的数学模型来近似描述这个序列。这个模型一旦被识别后就可以从时间序列的过去值及现在值来预测未来值。
2 大数据预处理
数据采集与监视控制(SCADA)系统是风场设备管理、监测和控制的重要系统,通过实时收集风机运行的环境参数、工况参数、状态参数和控制参数使风场管理者能够实时了解风电装备资产的运行和健康状态。SCADA系统每天产生大量的数据,而且数据通常有上百个变量,当前可用数据经过筛选保留了其中28个连续数值型变量,涵盖了风机的工况参数、环境参数和状态参数等多个维度,总计202 328条原始数据作为样本数据。当前可用数据分为两组,一组是带有故障标签的训练数据train,另外一组是测试数据test。
由于采集到的约20万条原始数据存在数据质量较低,含噪声、数值差异较大或不一致,数据混杂严重甚至重复及维度高等问题,本文综合采用数据清洗、数据集成、数据变换和数据归约等几种数据预处理方法,实现了原始数据的标准化、归一化、零均值化、白化和正则化,经过预处理后干净的规则的数据有利于提高模型的训练效果和效率,也可去除数据中存在的异常点,为下一步的特征提取和分析做好准备工作[14]。
“train”数据集中包括2个风机的数据,存在2个以风机编号命名的文件夹中。每个文件夹中的数据包括3个文件:
(1) 编号_data.csv。风机连续时间内的SCADA原始数据(详细内容见表1)。
(2) 编号_normalinfo.csv。风机正常状态的时间段,第1列为起始时间,第2列为结束时间。
(3) 编号_failureinfo.csv。风机结冰故障的时间段,第1列为起始时间,第2列为结束时间。
风机正常时间区间和风机结冰时间区间均不覆盖的数据视为无效数据。
“test”测试数据集和“final”最终数据集中有若干个以风机编号为命名的文件夹,每个文件夹中包括一个编号为_data.csv为文件,储存风机连续时间内的SCADA原始数据。
3 模型的实现方法
本文获得了Vestas V80-1.8MW风机上多个传感器2016年度的历史数据和实时数据,利用获知的设备故障时间为传感器数据标注,并使用分布式改进的NACNN模型将标注数据训练形成设备故障特征模型,准确率均值为95%;采用NARIMA模型预测单个传感器未来时刻的数值;利用多个传感器的预测数值和设备故障特征模型判断设备未来故障发生概率。具体实施过程如下:
(1) 提取传感器数据。利用现场网关提取传感器OT数据,并导入分布式数据库(使用MongoDB)。
(2) 传感器数据的标注。利用已知的设备故障时间为传感器数据打上标注,设置新字段isNormal,在设备故障时间内,则isNormal为1。
(3) 利用NACNN训练模型。对原始数据进行平稳性和随机性检验。一个平稳的随机过程应符合以下要求:期望值不随时间的变化而变化;方差不随时间变化;自相关系数只与时间间隔相关,和所处的时间无关。使用分布式改进的NACNN模型将标注数据训练形成设备故障特征模型。准确率为95%,计算效率大大提高。分布式改进部分在于对计算信息熵部分的重写(使用spark技术),信息熵计算公式为
(9)
式中:P(xi)为概率分布函数;lbP(xi)可分散到不同计算节点求解,随后可将结果汇集到一台计算节点求和。
令某1台计算节点上分配的数据集为Dj,某字段为Pi+1(xi+1),其中,j表示第j台计算节点。信息熵计算的分布式求解的原理如图2所示。

图2信息熵计算的分布式求解
由于使用了分布式计算信息熵的方式(编程基于python使用了Spark内存计算组件),计算效率大大提高。图3为传统NACNN模型和分布式NACNN模型的效率比较,数据集单位以万计,时间单位为s,可看出随着训练数据集的不断增大,传统算法开销呈指数上升,而分布式改进算法则仅仅是线性上升。

图3 传统算法和改进算法的效率比较
(4) 利用NARIMA模型计算未来一段时间内单个传感器的数值。使用NARIMA模型可预测某一个传感器,需提取出传感器历史数据的周期性和趋势性,并计算NARIMA模型的d值。图4为某传感器历史数据的周期性和趋势性的拆分。
在获取周期数据之后计算其自相关系数和偏相关系数,以确定NARIMA模型中AR模型中p和MA模型中的q。NARIMA模型的建模方法是以序列的平稳性为前提的,因此要把非平稳序列转换为平稳序列。对时间序列数据进行平稳化处理,首先需要通过对原始数据的ACF和PACF计算,正确地确定相应的模型和适当的阶数[15]。因为原序列呈现出近似线性的趋势,经过检验,1阶差分后序列依然为非平稳序列,而2阶差分之后序列为平稳序列,故选择2阶差分。图5所示为某传感器ACF和PACF。
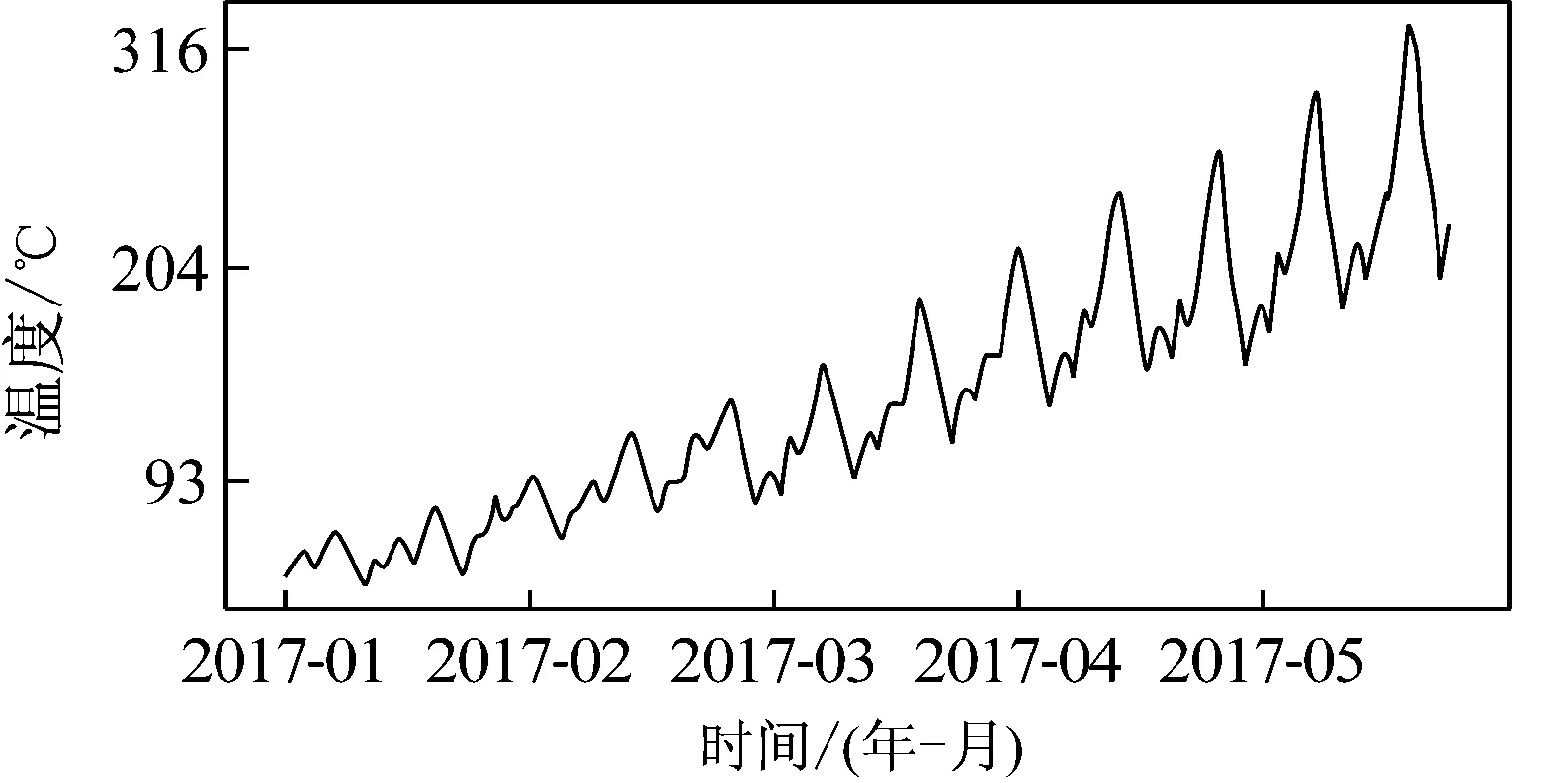
(a) 原始数据曲线

(b) 趋势曲线

(c) 周期曲线
最终利用已获取的d,p和q预测未来一段时间的数值。图6(a)~(c)分别为某传感器的历史数据和使用长短期记忆模型(Long Short Term Memory,LTSM)、支持向量回归(Support Vector Regression,SVR)、NARIMA模型预测的数据的比较示意图。由图6可见,NARIMA模型在较长时间维度上预测的准确性较其他算法更为优秀。

(a) ACF

(b) PACF

(a) LTSM算法

(b) SVR算法
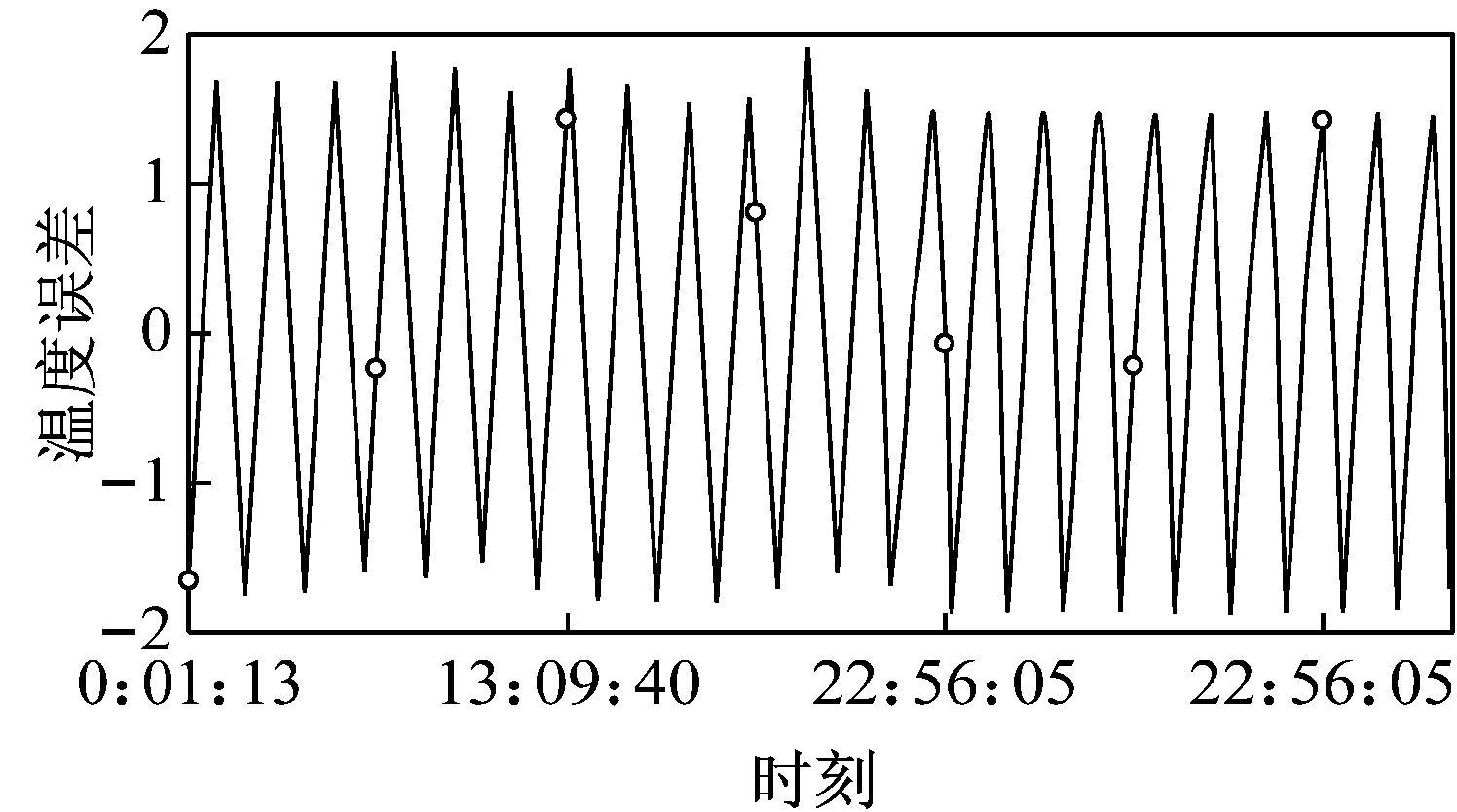
(c) NARIMA算法
(5) 利用多个传感器的预测数值和设备故障特征模型判断设备未来故障发生概率。NARIMA模型能预测某一个传感器未来一段时间的运行数据,启动多个线程同时预测某设备所有传感器未来一段时间的运行数据,结合已获取的NACNN训练模型预测设备是否会出现故障及故障出现的时间。
4 测试结果与分析
根据所建立的模型对一个风机叶片结冰实例的故障时机进行预测,并将得到的预测值和原始序列的实际值做对比(见表1)。

表1 实际数据与预测数据比较
通过观察分析NARIMA模型的预测结果和原始序列,很容易发现建模样本和测试样本的误差都在减小,最终预测效果良好,比单纯使用ARIMA模型和NARNN模型误差小。其中,误差的相对比例为实际值和预测值的差除以实际值。测试结果显示,绝大部分数据的预测值的误差都在10%以内,没有出现预测值与实际值相差悬殊的情况。而且,绝大部分序列的实际值都落在预测值的95%预测区间内。模型预测值的动态趋势与实际情况基本一致,模型对未来的情况进行了很好地跟踪。结合实验分析结果:风机叶片的运行状态与结冰故障之间的时间序列关系受误差自相关图、时间序列响应图、拟合模型数据和预测数据的均方误差、平均绝对误差和平均绝对百分比误差等因素的影响。因此,可以判定该模型是有效且有意义的。人工神经网络误差小,则泛化能力好,但是,由于NARIMA模型的误差太小,可能导致过度拟合,泛化能力反而不佳。在后期的训练中,需要掌握好隐含层神经元数量、学习率、训练时间、样本量等因素。特定风机2016年度结冰故障率时间序列图如图7所示。

图7 特定风机2016年度结冰故障率时间序列图
NARIMA模型在短期内预测比较准确,随着预测时间的延长,预测的误差会逐渐地增大,这是NARIMA模型的缺陷。但是与其他的预测方法相比较,其预测的准确度还是比较高的,在低维度数据(5维内)上,NARIMA非常有效。
5 结 语
本文通过研究风机结冰的故障预测模型,利用多种类型的数据,包括设备运行时间、温度、能源利用、产出及其他数据来改善决策的制定和运行,实现了准确预测故障发生时机,及时人工干预和检修,减少设备故障状态下的运行,从而减少了停机时间,提高了设备的服役时间周期和服务可靠性,提升了风电生产效率,具有较好的实践意义。
