基于高光谱技术及SPXY和SPA的玉米毒素检测模型建立
2018-08-31于慧春刘云宏
于慧春,娄 楠,殷 勇*,刘云宏
新鲜玉米在存贮过程中,由于其胚部大、水分含量高、带菌量多,高温高湿环境下极易霉变[1],不仅给经济造成重大损失,而且霉变玉米在代谢过程中会产生多种对人体具有极强致病性、致癌性的毒素[2-3],危害人畜健康。黄曲霉毒素B1(aflatoxin B1,AFB1)和玉米赤霉烯酮(zearalenone,ZEN)是其中2 种比较稳定的代谢产物,容易在霉变玉米中积累,导致含量升高,AFB1和ZEN的多少与玉米霉变情况密切相关[4]。因此,可以通过监测玉米中AFB1和ZEN含量变化表征玉米的霉变情况,实现对玉米霉变程度的准确评价[5]。但是常规的AFB1和ZEN检测方法存在样品处理繁琐、费时、对样品有破坏性等缺点,难以实现简单、快速、无损检测,无法满足实际生产的需要[6-8]。
高光谱技术通过提取被测对象的图像和光谱信息特征并与其内外品质指标间建立联系,从而实现对其内外综合品质的评价,因而在果蔬品质[9-11]、禽肉品质[12-14]、蛋[15]和烟叶[16]等农产品检测领域获得广泛应用研究。在霉变玉米的高光谱检测方面,也有学者进行了一些探索[17-19],但目前研究主要集中在高光谱技术对不同霉变程度玉米的定性判别方面,而对霉变玉米中AFB1和ZEN等的定量检测分析方面尚鲜有报道。袁莹[20]和褚璇[21]等将不同浓度的AFB1溶液滴在玉米籽粒上,然后利用高光谱技术进行检测,但其最终的分析结果仍然只是对表面含有不同浓度AFB1的玉米样品进行分类识别,也未尝试通过高光谱技术对测试样本在特定条件下自身代谢生成的AFB1含量进行预测。此外,上述霉变玉米高光谱技术检测研究中,对所使用的校正集样本质量也未进行考察,大量的样本数据之间可能存在相同或者差异过小的情况,从而影响分析结果精度和耗费建模时间。
本研究以玉米霉变过程中产生的AFB1和ZEN 2 种代谢产物含量为玉米霉变程度的表征指标,通过测定不同霉变程度玉米样本的光谱信息和相应的AFB1和ZEN含量,建立基于较少校正集样本和特征波长光谱信息的AFB1和ZEN含量偏最小二乘回归(partial least squares regression,PLSR)预测模型,从而实现对玉米霉变程度的准确分析,以期为实现玉米霉变的在线、快速、精确检测提供借鉴。
1 材料与方法
1.1 材料
玉米来自于2016年10月在洛阳当地收获,品种为中单909,购于洛阳市中原农贸城,由实验室自行培育出不同霉变程度的玉米。
1.2 仪器与设备
LHS-HC-100恒温恒湿培养箱 上海资一仪器设备有限公司;IST 50-3810高光谱成像光谱仪 德国Inno-spec公司;康标达镜头 日本Computar公司;RK90000420108线性卤素灯(500 W) 德国Esylux公司。
高光谱图像采集系统如图1所示,该系统主要包括高光谱成像光谱仪、康标达镜头、4 个500 W线性卤素灯、实验室自制传送装置和计算机等主要部件。其中高光谱成像光谱仪由摄像机和光谱仪2 部分组成,摄像机为CCD相机,光谱摄像仪为可见-近红外光谱仪,光谱波长范围为371.05~1 023.82 nm,可采集到的光谱数据点数为1 288 个,光谱分辨率为2.8 nm,传送带移动速率1.25 mm/s,曝光时间100 ms,样本与镜头的距离为285 mm。高光谱成像仪通过USB 2.0接口数据线连接计算机,通过SICap-STVR V1.0.x软件平台驱动控制成像仪,及时记录和存贮高光谱数据。
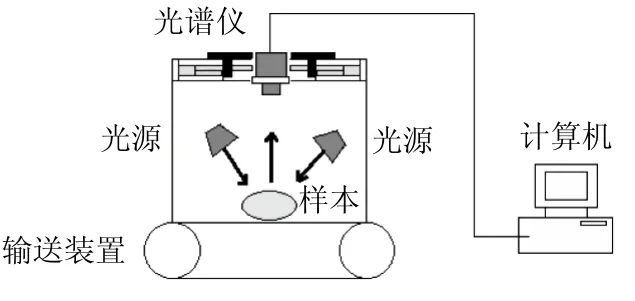
图1 高光谱图像采集系统Fig. 1 Schematic presentation of the hyperspectral image acquisition system
1.3 方法
1.3.1 玉米样本制备
将新鲜玉米放入恒温恒湿培养箱,在培养温度30 ℃、相对湿度90%[22]的条件下进行培养。培养时间不同,玉米霉变程度也不同,本实验用培养初始(新鲜玉米)、第2天、第4天、第6天、第8天标记玉米的不同霉变程度,5 个霉变程度的玉米看作5 个霉变等级,每个等级样品各取50 个测试样本,每个样本含60 g(±0.1 g)玉米。
1.3.2 AFB1和ZEN含量的测定
为了减少AFB1和ZEN的损失,制备的样本在完成光谱数据采集后立即按照GB/T 18979—2003《食品中黄曲霉毒素B1的测定》[23]和GB/T 5009.209—2008《食品中玉米赤霉烯酮的测定》[24]分别测定AFB1和ZEN含量,并将其测定结果作为建模的标准参考值。
1.3.3 高光谱图像数据采集与校正
在进行高光谱图像采集时,为了满足实际玉米霉变检测的需要,将玉米样本散乱均匀平铺在规格为10 cm×10 cm的白色载物盒中,然后将装有玉米的载物盒放置在移动载物平台上,依次对玉米样本进行高光谱图像采集,设定高光谱的扫描图像大小为550×600像素。本实验共采集到250 幅玉米样本高光谱图像。
同时,为了消除光源强度分布不均以及光谱暗电流噪声的影响,对每个样本按校正公式进行黑白校正,计算公式如下:
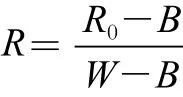
式中:R为校正后的样本高光谱图像;R0为样本原始高光谱图像;B为全黑标定图像;W为全白标定图像[25]。样本的高光谱图像采集在SICap-STVR V1.0.x软件平台上完成,实验数据分析与处理在MATLAB 2014a(美国The Math Works公司)和遥感图像处理平台ENVI5.1(美国Boulder公司)两个软件上完成。
1.4 数据处理
1.4.1 原始光谱数据进行预处理
为了减少背景噪声、杂散光等无用信息对原始光谱数据的干扰,需要对原始光谱数据进行预处理。本实验对比标准化、变量标准化、多元散射校正(multiplicative scatter correction,MSC)、标准正态变量校正(standard normal variate,SNV)和卷积平滑(Savitzky-Golay smoothing,S-G)5 种预处理方法。为保证模型校正集最大程度地表征样本均匀分布,提高模型稳定性,本实验采用光谱-理化值共生距离(sample set partitioning based on joint x-y distance,SPXY)算法[26]划分模型的初始校正集和预测集。在此基础上,为降低或者消除校正集样本间的共线性[27],简化模型运算量,采用SPXY算法结合PLSR法分析不同校正集样本子集预测AFB1和ZEN含量的差异,从而进一步对划分的初始校正集样本进行优选。在采用均匀光谱间隔(uniform spectral spacing,USS)法对原始光谱变量进行初步筛选的基础上对比连续投影算法(successive projections algorithm,SPA)[28]和竞争性自适应重加权算(competitive adaptive reweighted sampling,CARS)法[29]2 种特征波长提取方法,最大程度地剔除原始光谱矩阵中的冗余信息,提高模型精度,减少模型运算量。
1.4.2 模型建立与评价
霉变玉米的光谱信息与其AFB1和ZEN含量之间的关系属于非确定性问题,采用回归分析构造变量间的数理统计模型可用于该类问题的研究分析[30]。PLSR法集主成分分析、普通多元线性回归和相关分析于一体,它在描述光谱矩阵X变量的同时也描述了指标矩阵Y变量,较好地解决了自变量的多重共线性问题,在光谱分析领域得到了广泛应用。
2 结果与分析
2.1 不同霉变等级的玉米AFB1和ZEN含量
在进行AFB1和ZEN含量检测时,对每类玉米样品的50 个平行样本进行测定,以独立测定结果的绝对值差不超过算术平均值的10%为准,并将其平均值作为此类玉米样品的实际指标值,结果如表1所示。由表1可知,第4、5个等级的玉米中,这2 类毒素含量已超过国家标准(AFB1≤20 μg/kg,ZEN≤60 μg/kg)。
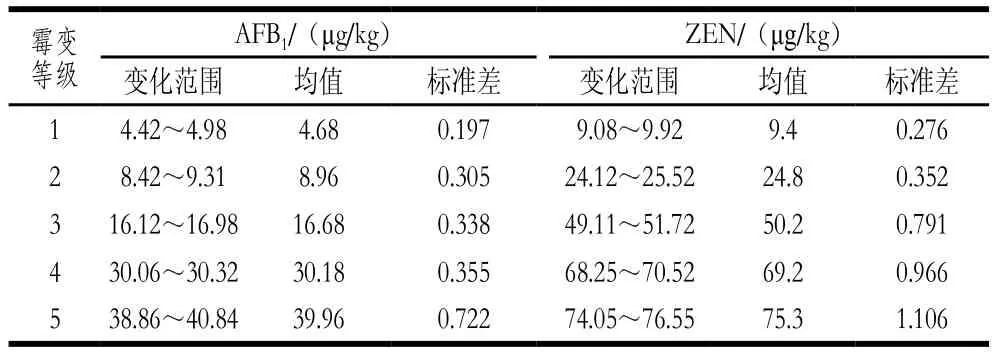
表1 5 个霉变等级玉米样品中AFB1和ZEN含量Table 1 AFB1 and ZEN values in 5 grades of moldy maize samples
2.2 光谱反射值曲线
提取每个玉米样本在371.05~1 023.83 nm波长范围内的高光谱图像的平均光谱反射值,结果如图2所示,371.05~480.55 nm和999.66~1 023.83 nm两个波段受噪声的影响较大,因此剔除了这2 个波段,最终采用的波段范围为481.06~999.15 nm。由图3可以看出,5 个等级玉米样品光谱曲线变化趋势基本相似,但不同霉变等级玉米的光谱值有差别,总体看来,5 个等级玉米样本具有一定的可分性,这为预测建模提供了可能。
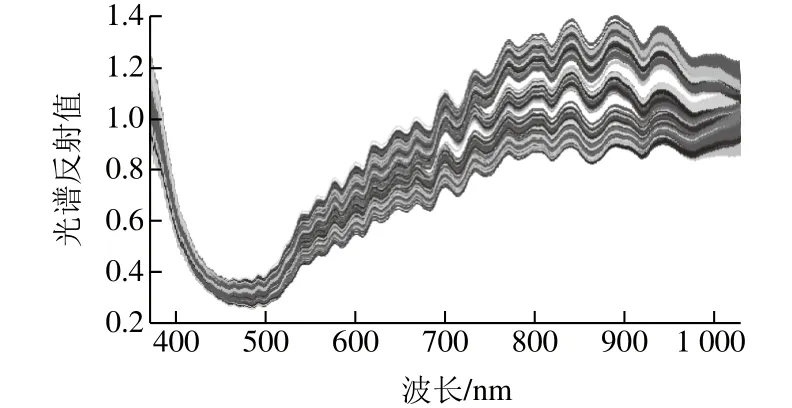
图2 250 个玉米样本的光谱反射值曲线Fig. 2 Spectral reflectance curves of 250 maize samples
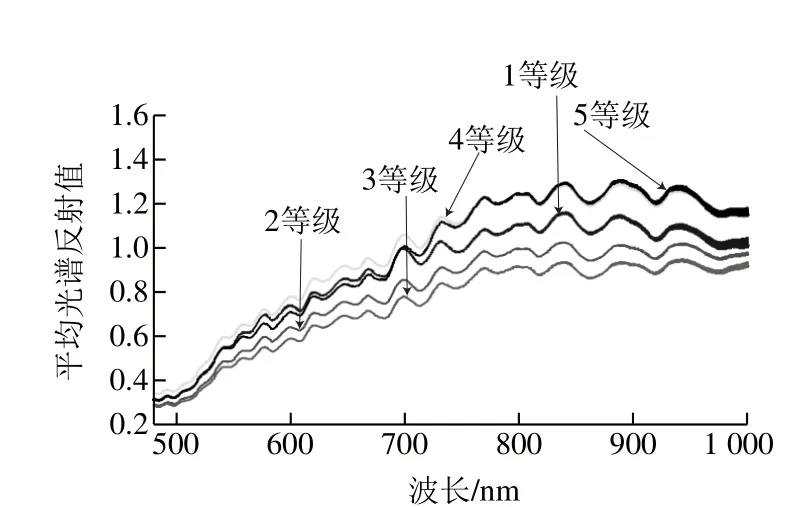
图3 5 类玉米样本的平均光谱反射值曲线Fig. 3 Average spectral reflectance curves of five grades of maize samples
2.3 光谱数据预处理
随机选取200 个样本作为校正集,剩余的50 个样本作为预测集。采用不同预处理方法对原始光谱数据进行预处理,并基于各预处理后的光谱数据建立PLSR模型,结果如表2所示。由表2可知,与基于原始光谱数据的预测结果相比,5 种预处理方法中,基于SNV建立的PLSR模型对这2 种毒素含量的预测效果最好,对应AFB1和ZEN含量的预测集相关系数和均方根误差(R2pre,RMSEP)分别为(0.994 4,0.984 6)和(0.991 6,2.320 9),因此确定SNV为预处理方法。
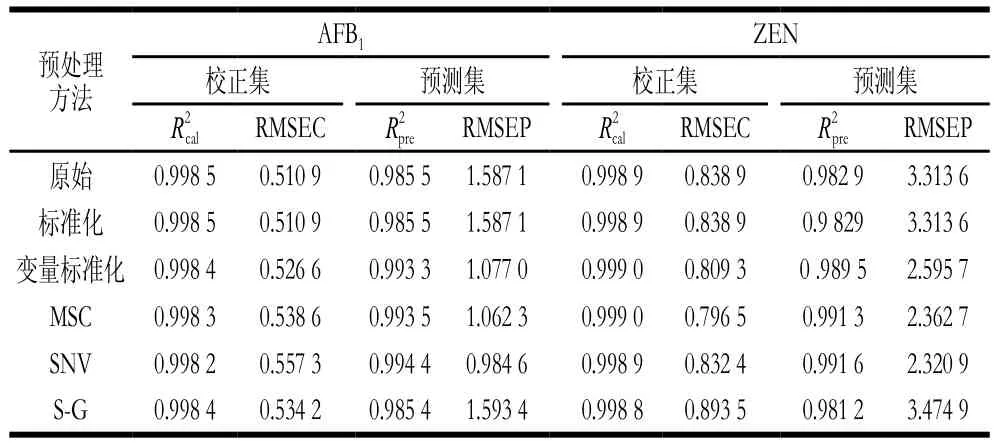
表2 基于不同预处理方法的PLSR建模结果Table 2 Results of PLSR models based on different pretreatments
2.4 校正集样本的优选
2.4.1 SPXY算法划分样本集数据
校正集样本的划分在一定程度上能够决定所建模型的预测性能,本实验采用SPXY算法对样本集进行划分。首先设定初始校正集样本个数为200 个,剩余的50 个样本为预测集样本,SPXY算法的详细步骤参考文献[26],划分结果如表3所示,不同霉变等级的样品间,校正集和预测集的样本个数存在较明显的差别。
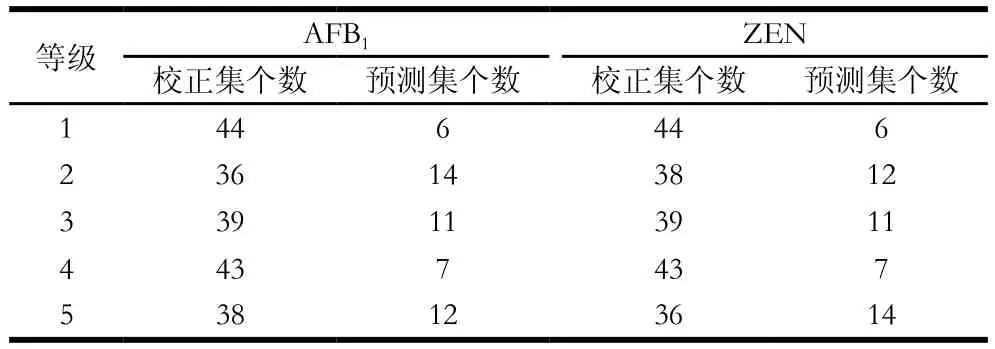
表3 SPXY划分样本集结果Table 3 Calibration and prediction set partitioned by SPXY
2.4.2 SPXY算法优选校正集样本
针对表3中初分的初始校正集样本,采用SPXY算法进行进一步优选,以尽量有效地降低样本间的共线性。确定样本数N的范围为80~200,步长为10,校正集样本优选过程中,分别基于优选出的校正集样本子集建立PLSR模型,其预测集的相关系数R2pre和RMSEP的变化如图4所示。
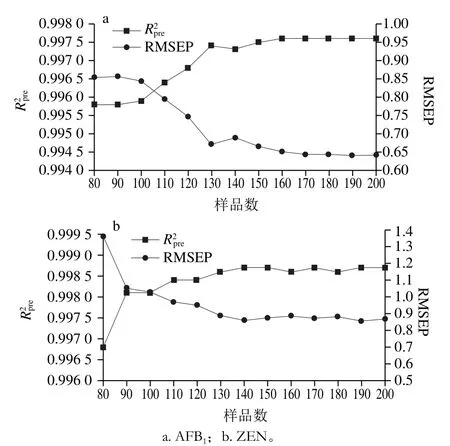
图4 R2pre和RMSEP随校正集样本数量变化曲线Fig. 4 Plots of R2pre and RMSEP values versus number of calibration set samples
由图4可以看出,R2pre随样本数N的增加呈递增趋势,但总体变化不明显(0.995~0.999),RMSEP曲线呈递减趋势,总体变化较明显。图4a中,对于RMSEP变化曲线,N在80~130范围内取值时,RMSEP变化差异明显,N在130~200范围内取值时,RMSEP的变化趋于平缓,N取值为130 为该曲线的拐点,该点对应的R2pre和RMSEP为0.997 4和0.672 0,当N取值为190时,R2pre达到极大值0.997 6,RMSEP降为极小值0.641 4,与N取130 时对应的R2pre和RMSEP相比,R2pre仅增加0.000 2,RMSEP仅减少0.030 6,从数值上看,两者差异较小,但校正集样本数增加了60 个,因此,为简化模型运算量,综合图4a中R2pre和RMSEP曲线的变化趋势,对于AFB1,最终从初始校正集中优选出130 个样本组成模型校正集。同样根据图4b,对于ZEN,最终从初始校正集中优选出140 个样本组成模型校正集,对应的R2pre和RMSEP为0.998 7和0.862 1。
经SPXY算法划分的预测集样本和初始校正集样本以及经SPXY算法优选的校正集样本的AFB1和ZEN含量变化情况如表4所示。由表4可知,无论是对AFB1还是对ZEN,SPXY法优选出的校正集样本的各指标值含量变化范围在初始校正集范围内,且标准差相近,证明SPXY算法优选后的样本具有一定的代表性。

表4 不同样本集玉米AFB1和ZEN含量分布Table 4 Distribution profiles of AFB1 and ZEN values in different sample sets
2.5 特征光谱的选择
2.5.1 光谱数据的降维
高光谱图像具有较高的光谱分辨率,容易对被测物进行分辨,但也会导致数据量的剧增和数据冗余。相邻波段间差异很小,直接进行特征波段的提取可能会漏掉某些有用信息,因此,本实验首先对光谱变量进行初降维。USS法通过控制步长选出间隔均匀、相关性低、信息量大的少量波段,从而可对光谱数据进行有效降维。在481.06~999.15 nm范围内,分别以正整数2、3、4、5、6……20为间隔,从1 023 个经预处理后的光谱波段中抽取光谱组成新的光谱矩阵并建立PLSR模型,根据模型的和RMSEP,确定最佳的步长间隔。表5为利用不同步长间隔下抽取的光谱建立的PLSR模型对AFB1和ZEN含量的预测结果。
从表5可以看出,当间隔为8,波段为128 个时,模型对AFB1含量的预测效果较好,R2pre和RMSEP为0.997 4和0.673 4;当间隔为7,波段为147 个时,模型对ZEN含量的预测效果较好,R2pre和RMSEP为0.998 8和0.835 4。对比只采用SPXY算法优选校正集样本而未对光谱变量进行筛选所建的PLSR模型结果可知,通过USS法进行变量筛选后所建模型对AFB1含量的预测精度变化不大,对ZEN含量的预测精度有一定的提高,但参与建模的变量数能显著减少。
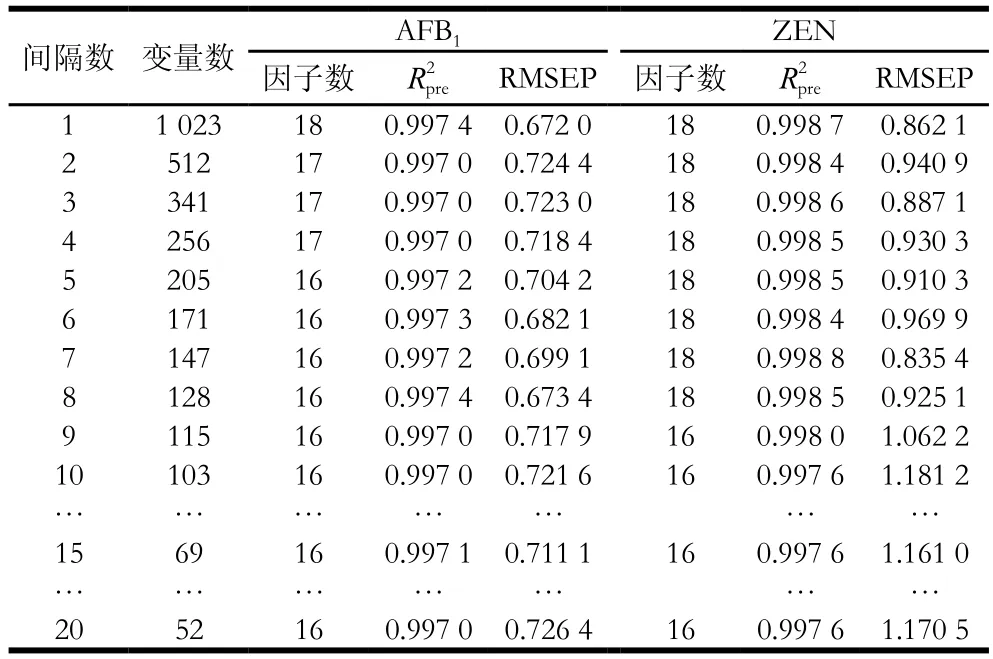
表5 基于不同间隔光谱数据建立PLSR模型预测结果Table 5 Predictive results of PLSR models with different numbers of spectral intervals
2.5.2 光谱特征波段的选取
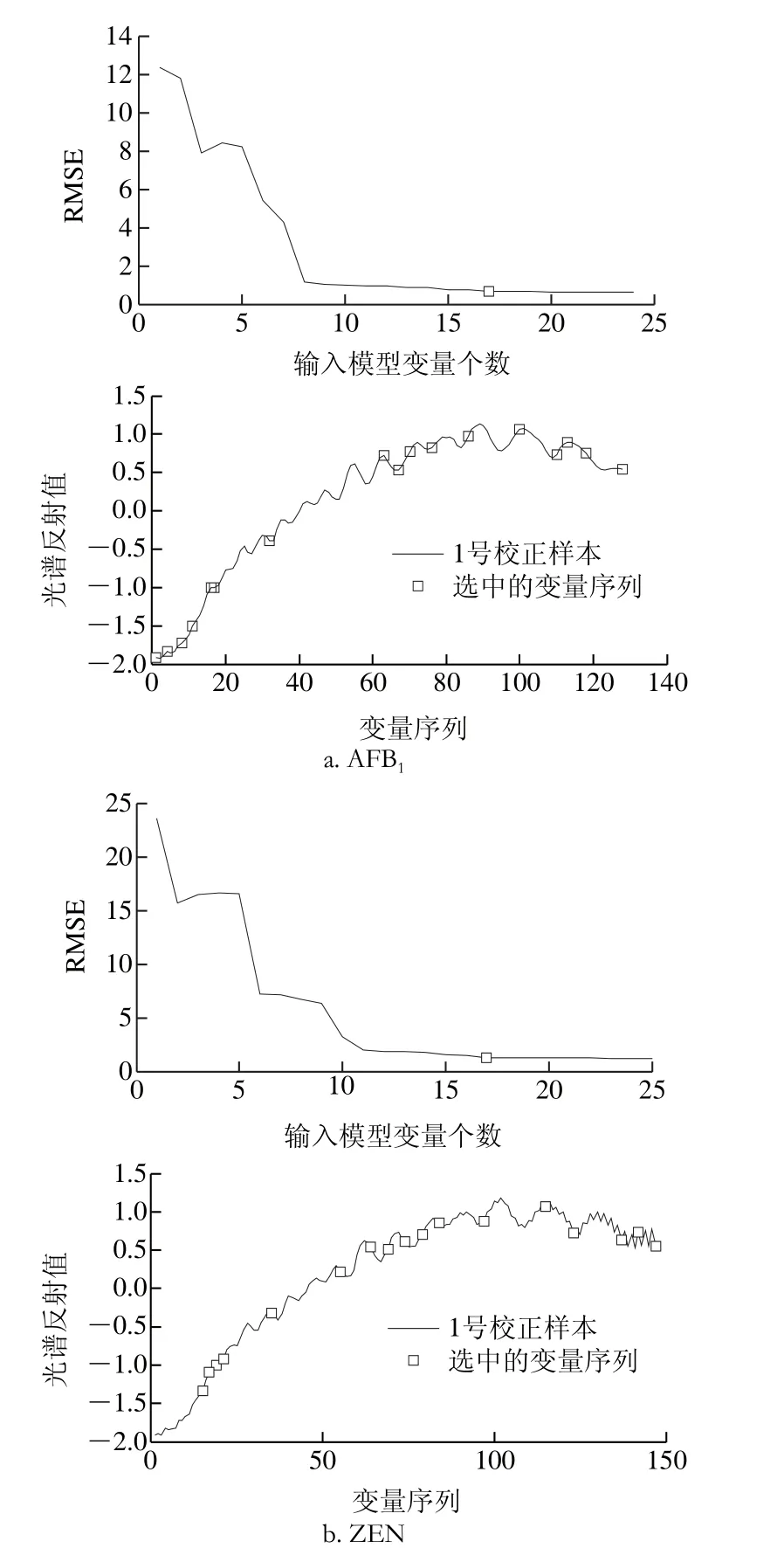
图5 基于SPA的变量筛选Fig. 5 Wavelengths selected by SPA
为进一步实现霉变玉米在线检测的检测时间短、准确率高的要求,本实验在USS法筛选波长变量的基础上,对比了SPA和CARS 2 种特征波长选择方法。
在SPA中,最小的交互验证RMSE对应的波长变量个数即为最终的选择结果,指定波段数N的范围为2~25,SPA的具体运算步骤可参考文献[28]。由图5a可以看出,从128 个波长变量中提取17 个波长时RMSE达到最小;由图5b可以看出,从147 个波长变量中提取17 个波长时RMSE达到最小。表6为基于SPA提取的特征波长建立的AFB1和ZEN含量的PLSR模型预测结果。
在CARS算法中,设定蒙特卡罗采样次数为50,CARS算法的具体运算步骤参考文献[29],如图6所示,基于CARS算法针对AFB1和ZEN含量的变量筛选过程,对这2 种毒素指标值,当采样次数分别为14 次和19 次时,对应的特征波长个数分别为18 个和19 个。
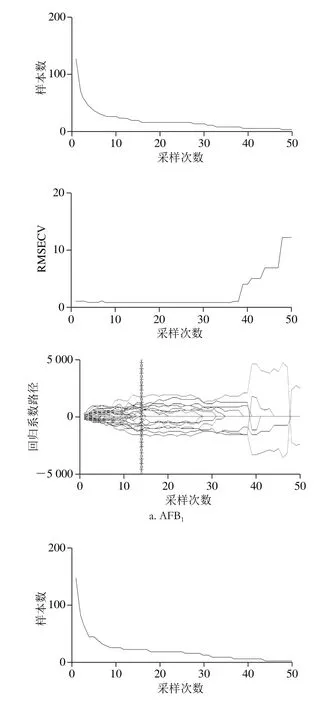
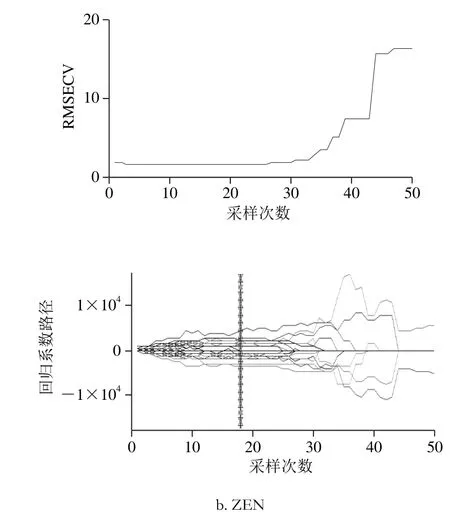
图6 基于CARS的变量筛选Fig. 6 Wavelengths selected by CARS

表6 基于SPA特征波长提取方法的PLSR模型结果Table 6 Parameters of PLSR models with characteristic wavelengths extracted by SPA

表7 基于CARS特征波长提取方法的PLSR模型结果Table 7 Parameters of PLSR models with characteristic wavelengths extracted by CARS
对比表6和表7可知,基于SPA筛选出的波长所建立的PLSR模型对AFB1和ZEN含量的预测效果较CARS算法好。
2.6 模型分析
原始光谱数据经过SNV预处理后,采用SPXY算法对校正集样本进行划分与优选,运用USS法结合SPA对光谱数据进行筛选,然后建立基于优选后的校正集样本及特征波长的PLSR模型。如图7所示,波长优选后,PLSR模型的预测能力依旧表现良好,AFB1含量的预测精度(,RMSEP)为(0.997 3,0.681 5),与优选之前的预测精度(0.997 4,0.672 0)相近;ZEN含量的预测精度(,RMSEP)为(0.997 7,1.144 1),略低于优选前的精度(0.998 7,0.862 1)。
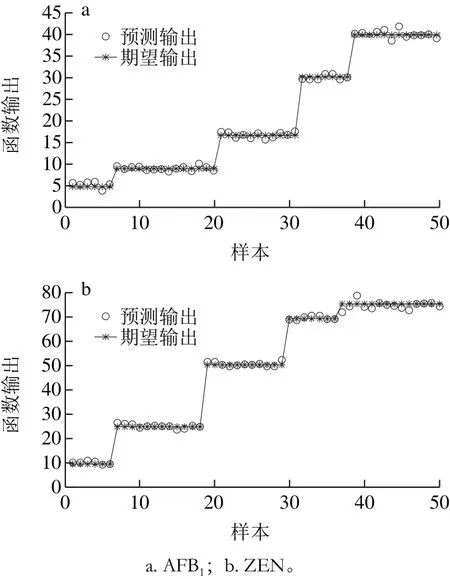
图7 基于特征波段建立PLSR模型预测结果Fig. 7 Predictive results of PLSR models based on characteristic wavelengths
3 结 论
本实验利用不同霉变时期的玉米光谱实验数据,研究了高光谱技术用于霉变玉米中AFB1和ZEN含量检测模型的构建,并得到以下结论:
1)对于AFB1和ZEN含量,经SPXY法分别优选出的130 个和140 个校正集样本的指标值变化范围在初始校正集范围内,且标准差相近,说明SPXY算法优选的样本具有一定的代表性。
2)基于SPXY法划分的初始校正集样本建立的PLSR模型预测精度明显高于划分之前的预测精度,且通过SPXY法对初始校正集样本进一步优选,PLSR模型精度基本不变,但校正集样本数减少为初始校正集的65%和70%,在保证模型稳健性的前提下,有效降低了校正模型的复杂性。
3)利用USS法结合SPA进行特征波段选择,最终从1 023 个波段中分别筛选出17 个波段。分别建立2 种毒素值基于各自特征波段的PLSR模型,结果显示AFB1含量预测精度(0.997 3,0.681 5)与优选前的预测精度(0.997 4,0.672 0)相差不大;ZEN含量预测精度(0.997 7,1.144 1)略低于优选之前的预测精度(0.998 7,0.862 1),R2pre从0.998 7降低到0.997 7,RMSEP从0.862 1上升到1.144 1,但波长减少为17 个,在保证模型精度的前提下,实现光谱数据的压缩。
综合上述研究结果,基于SPXY算法和SPA建立的高光谱检测模型,可以实现对霉变玉米中AFB1和ZEN含量的准确预测。
