三维芯片多层与多核并行测试调度优化方法
2018-08-28汪加伟任福继
陈 田 ,汪加伟,安 鑫,任福继,3
(1.合肥工业大学计算机与信息学院,合肥230601;2.情感计算与先进智能机器安徽省重点实验室(合肥工业大学),合肥230601;3.德岛大学工学部,日本 德岛770-8506))
(*通信作者电子邮箱ct@hfut.edu.cn)
0 引言
目前,传统的二维(Two-Dimensional,2D)芯片在集成度和功耗等方面面临许多困难和挑战。与2D芯片相比,三维(Three-Dimensional,3D)芯片结构具有更高的传输带宽、更低的延迟和更低的功耗[1],目前已经成为学术界和产业界的研究热点。3D芯片在其堆叠过程中,随着电路的复杂性逐层增加,会导致测试难度不断增大,而整个芯片的可测试性问题也是3D芯片获得应用的主要难点之一[2]。在3D芯片多核测试中,如何将测试数据移入位于不同层各个芯核的扫描链中以及如何缩短测试时间一直是3D片上系统(System on Chip,SoC)中测试访问机制(Test Access Mechanism,TAM)设计的重要问题。如果测试激励移入一个芯核中扫描链的频率很高,测试时可能会产生过高的测试功耗。另一方面,如果采用多核并行测试,会在并行测试的局部区域产生大量的电路开关活动,有可能使这一部分电路在测试时产生噪声,导致芯片良品率的损失;同时,也可能导致芯片局部温度升高,在芯片上产生热斑,这对没有散热装置的裸片而言,很容易造成芯片因过热而失效[3]。因此,如何在功耗限制下,缩短3D多核测试时间、提高测试并行度是一个很重要的问题。然而,在测试过程中,由于测试引脚和芯核之间传输测试数据的TAM资源有限,利用有限的资源最小化测试时间被认为是一个NPHard问题[4]。文献[5]将该问题转化为二维装箱问题,并使用传递闭合图与动态分区相结合的方法来进行求解,取得了良好的效果,但仍有可以提升并行度的空间。另外,一些最优化方法也被引入用于解决该问题,如:文献[6]使用整数线性规划的方法并定义了一种退出搜索循环的约束策略求解TAM宽度限制下的最优资源分配,但是该方法在SoC规模较大时计算量极高;文献[7]基于遗传算法提出了一种测试调度优化方法,拥有较强的随机搜索能力,但是该方法在遗传基因确定和基因突变的规划等方面存在非常大的多变性;文献[8]将量子寻优算法作为解决装箱问题的策略。这些调度优化方法虽然减少了测试所需的时间,但是仍然受限于TAM架构设计。一些学者将研究方向放在TAM的优化设计上,设计了基于时间段分割方式的测试访问方法[9]和将位于不同层的芯核先进行伪平面设计再进行扫描链均衡的方法[10]等。然而,这些设计与调度方法在同一时间段内只有部分芯核能够并行测试,测试过程中仍然存在大量空闲的TAM资源;另外,为了保证测试时间较短,这部分芯核在测试时的频率也相对较高,使得整个堆叠在测试过程中的发热不均、芯片失效的风险仍然存在,而时分复用的TAM设计方法在这些问题上有着明显优势。
时分复用作为一种典型的多路复用技术,最初被广泛应用于电话公司的数字语音传输,文献[11]中将时分复用方法用于解决2D芯片的测试问题,文献[12]在此基础之上将其应用到3D芯片的TAM设计中。这一方法能够让堆叠中的所有芯核并行测试,并且每个芯核在测试时都被限制在较低的频率下。本文在文献[12]的基础上,提出了一种基于分时复用的协同优化各层之间、层与核之间测试资源的调度方法。
在整个3D芯片的堆叠过程中,多个芯核被分配到不同层。因为连接三维芯片不同层的TSV长度很短,所以TSV可以在GHz范围内传输测试数据[13],并且TSV在3D堆叠的不同层之间建立了高速的垂直通信接口[14],但是芯核的测试频率受到功耗的约束,因此整个3D堆叠只能在较低的频率下进行测试[12]。时分复用的方法将自动测试设备(Automatic Test Equipment,ATE)的全局测试时钟(Global Test Clock,GTC)从堆叠芯片的底部输入,经过TSV传输,并通过各层间移位寄存器对时钟频率进行分解,然后进入3D堆叠中的不同层,进入每一层的层间测试时钟(Layer Test Clock,LTC)与全局测试时钟相比相对较低。同样,再将LTC经过核间移位寄存器进一步分解,这样,到达不同芯核的测试时钟频率会被再次降低。所有芯核共享数据通道,并根据分配到的时钟接收测试数据,从而保证了多个芯核可以在较低频率下并行测试。
但是,在时分复用数据通道进行芯核测试的过程中,由于各个芯核的测试数据量不成比例,这使得用于分频的寄存器的设计问题变得十分复杂,并且会产生部分的空闲测试时钟周期,造成测试资源的浪费。为了解决这一问题,本文设计了一种基于贪心算法的寄存器分配方案,并提出了一种使用离散二进制粒子群优化(Discrete Binary Particle Swarm Optimization,DBPSO)算法优化芯核在三维堆叠中布图的方法,协同优化层间与核间的测试并行度,该方法充分利用测试传输通道的数据传输潜力,以减少绑定前、绑定中和绑定后的测试时间。
1 测试优化方法
1.1 面向3D SoC的整体测试流程
3D SoC与传统的2D SoC相比结构更为复杂,因此测试流程也相对繁琐。为了更好地解决可测试性设计问题,本文在3D SoC设计之初就将测试问题纳入设计范围并使用时分的方法设计测试结构,通过合理分配整个SoC上的芯核分布,尽可能平衡层内芯核的测试时间,保证层间测试并行度,进一步减少测试时间。本文设计流程可以分为以下几个步骤:
1)将不同芯核所需的测试数据按照全局测试通道宽度进行等长分段;
2)按贪心策略确定寄存器分配方案;
3)对整个三维芯片按照不同芯核所在的层号进行二进制编码,将整个三维堆叠表示为二进制形式;
4)使用基于BPSO的方法求得最优的芯核布图。
本文方案可以有效解决层内和层间测试的并行问题,因此可以应用于绑定前、绑定中和绑定后的测试过程中。对于一个m层的3D SoC,一般的测试过程如下:
1)对每一层芯片都进行绑定前测试,保证每一片芯片在绑定前都是有效的;
2)对每一次部分堆叠的绑定都进行一次测试,保证部分堆叠的有效性,共需要进行m-2次绑定中测试;
3)对绑定后的完整堆叠进行绑定后的完整测试;
4)对封装后的整个3D SoC进行1次最终测试。
根据文献[14],在测试过程中,一个由m层芯片堆叠而成的3D芯片,需要经过2m次测试步骤。本文在一般测试流程之前对芯核进行了优化设计,整体流程如图1所示。
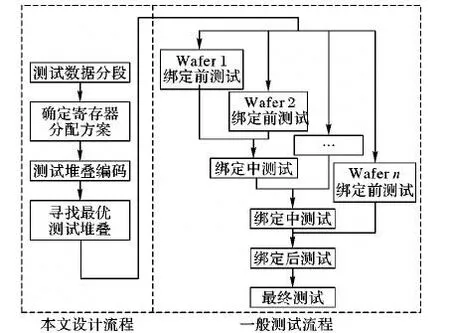
图1 寻找最优测试堆叠方案Fig.1 Scheme of searching optimal test stacking
1.2 层与核间移位寄存器设计
在共享测试数据通道的环境中如何使得测试数据从ATE输出后按照既定逻辑到达指定的芯核是数据调度的主要问题。数据先经过全局测试通道调度到不同层,再在各层间经过调度到达指定的芯核,而层核间测试数据调度的关键在于层与核间移位寄存器的设计。
在整个堆叠的每一层都分配一个相同结构的移位寄存器,目的是将GTC信号进行划分,转换为每一层的LTC。在图2中,堆叠的每层上都有一个四位的循环移位寄存器,寄存器的初始值分别为“1010”“0100”“0001”。当 GTC信号的一次脉冲来临时,每层的循环移位寄存器进行一次移位,GTC信号被分解为原频率的1/2、1/4和 1/4分别进入 Layer 1、Layer 2和Layer 3,且不同层内的脉冲并无冲突。
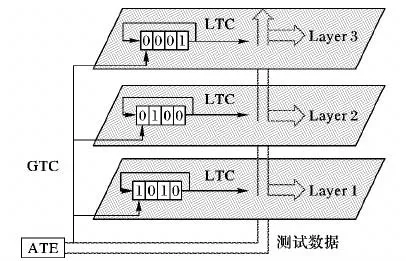
图2 层间移位寄存器设计Fig.2 Design of interlayer shift register
层内移位寄存器设计如图3所示,与层间数据传输频率划分类似,在每一层内,通过循环移位寄存器将LTC分解为不同芯核的测试频率。与层间频率划分不同的是在层内多个芯核共用一个寄存器。从不同的寄存器中引出输出信号作为不同芯核的数据传输时钟,当某一寄存器数据由0跳变成1时,芯核从共享的全局测试数据通道中接收一次测试数据段,从而减少多个移位寄存器带来的额外面积开销。

图3 核间移位寄存器设计Fig.3 Design of inter-core shift register
在图4中,每个芯核用于测试的扫描链有多个,当一个接收数据的脉冲到来时,多段扫描链从全局测试时钟上接收一个测试数据段,直到整个扫描链被填满,然后进行芯核的测试。
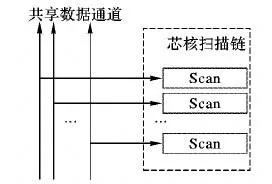
图4 全局数据通道共享方式Fig.4 Sharing method of global data channel
1.3 测试数据集的寄存器分配方案
在层间和核间的移位寄存器设计中,如果层或者芯核分配到的用于产生局部时钟的触发器数比例越高,那么,通过对GTC分频得到的测试数据段的时钟频率也越高。由于不同层之间或者同一层的不同芯核之间所需时钟周期数不一致,需要有效的寄存器分配方案。
假设在测试中,传送测试数据的全局测试通道宽度是确定的,芯核A、B和C接收测试数据各需要100、200和300个时钟周期。如果每个芯核都只分配一个触发器,那么,当芯核A完成测试时,芯核B、C仍然没有测试完成,继续进行测试时为A分配的测试资源会出现空闲状况。为了保证所有芯核能够被完整测试,芯核A会产生200个空闲时钟周期,芯核B会产生100个空闲时钟周期,共产生300个空闲的时钟周期。如何分配移位寄存器以保证每个芯核能获得合适的测试时间是多核并行测试中的一个重要问题。
为了降低成本减少面积开销,需要对移位寄存器的规模作一定的约束,为此,可以在设计时将移位寄存器中触发器的数量限制在给定值以内。本文提出了一种基于贪心算法的寄存器设计方案。假设给n个芯核最多分配r个触发器,具体设计步骤如下:
1)初始,为每一个芯核分配一个触发器,计算空闲周期并将该次分配记为最优分配;
2)为每一个芯核尝试分配下一个触发器时,计算该次分配所产生的空闲时钟周期,将该触发器分配给空闲时钟周期最少的芯核;
3)将步骤2)分配与最优分配进行对比,如果空闲时钟周期小于最优分配的空闲周期,则更新最优分配;
4)判断r个触发器是否分配完成,如果没有完成,重新进行步骤2);
5)输出最优分配。
以前文提到的芯核A、B和C为例,假设最大触发器数量为7,图5中的方块标记了当次分配触发器后所产生的空闲时钟周期,并且每次选择分配的芯核都用深色标出。首先为三个芯核各分配一个触发器,将第4个触发器分配给芯核C时,空闲时钟周期最小;将第5个触发器分配给芯核B时,空闲时钟周期最小;当7个触发器分配完成后,最优分配是为芯核A、B和C分别分配1、2、3个触发器的方案,此时的空闲时钟周期为0。

图5 移位寄存器分配过程Fig.5 Allocation process of shift register
层间移位寄存器的分配也采用该方法,只需要将芯核的测试数据量替换为完成该层测试所需的时钟周期。
1.4 多芯核排列的编码方式
为保证测试时间最短,不同层的测试完成时间应保持一致,可以通过优化芯核在不同层上的分布来解决这样的问题。同时为了保证功耗安全,针对某一个指定的芯核,它的测试时钟频率应该被限制在某一个频率之下,以保障芯核在测试过程中不会因为频率过高而产生热故障,即在功耗约束下,求得一个最优三维堆叠,使得整体的测试时间最小。
对于一个拥有m层并有n个芯核的三维芯片,问题在于如何将n个芯核分配不同层中,对于一个特定的芯核k,它所在的层号:qk(0<qk≤m,qk∈Z)表示这一个芯核处于整个三维芯片堆叠的层号,其中Z表示整数集,针对一个给定的三维芯片堆叠,其芯核1到n的层号排列可以表示为一个n维的向量:(q1,q2,…,qk,…,qn),0 < qk≤m,qk∈Z,1≤k≤n。对向量中芯核k,其层号用qk二进制编码表示,层编码长度为「lb(m)?,对某一个确定的三维芯片堆叠,其二进制编码长度l为:

图6表示的是一个三维堆叠分配方案的编码,它有4层并包含8个芯核。标志4层要2个二进制位,共有8个芯核,所以码字长度为16比特。按照每两位为一个芯核层号的规律,可以将图6的二进制编码还原为一个原始的三维芯片中芯核分配方案,即底层分配Core4和Core8,第二层分配Core2和Core7,第三层分配 Core3和 Core5,第四层分配 Core1和Core6。如果某一次分配使得整个三维芯片堆叠需要的测试时钟周期最少,则该编码所表示的三维芯片堆叠为最优的三维芯片芯核分配方案。对于一个规模较大的三维芯片,如何寻找三维芯片的最优测试堆叠是一个复杂的问题,本文使用离散二进制粒子群优化算法来解决这一问题。

图6 分配方案二进制编码Fig.6 Binary coding of allocation scheme
1.5 离散二进制粒子群优化算法
粒子群优化(Particle Swarm Optimization,PSO)算法由鱼群、鸟群的群体智能规律设计出来的,DBPSO算法是PSO基础上的改进版本,用以解决PSO算法在离散空间寻优问题中存在的局限性,本文引入该方法用以寻找三维芯片的最优堆叠。
在一维的空间中存在多个粒子,每一个粒子表示的空间点都是一个三维芯片堆叠方案的二进制编码,粒子的每一个维度只能取值0或者1,粒子的位置和速度根据自身和同伴的经验进行动态的调整,经过多次迭代之后找到一个最优的空间点作为三维芯片的最优分配方案。
整个种群(种群中粒子的总数为p)第i个粒子的位置表示为Xi=(bi1,bi2,…,bil),Xi即为一次三维堆叠分配方案,将测试所需的时钟周期数的倒数作为种群的适应度,粒子的适应度越高,则该粒子的位置更优。将特定粒子在历史上获得的最优位置记为Pbesti,最优位置Gbest看成是种群到目前的最优解,那么粒子的速度 Vi=(vi1,vi2,…,vil)。
当前的粒子速度Vi中某一维的速度vid由当前的种群的状态决定:
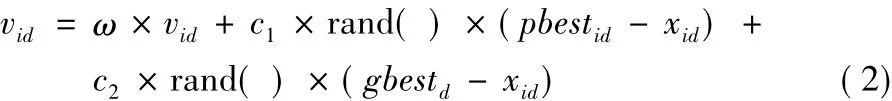
其中:pbestid为当前粒子历史最优Pbesti的第d维;gbestd为全局最优位置Gbest的第d维;ω、c1和c2分别为上一代粒子速度vid、pbestid和gbestd对当前粒子速度影响的权重,当前粒子某一维的速度表示在下一次迭代中该二进制位取1的概率,为了将速度值映射到区间[0,1]中,使用sigmoid函数:
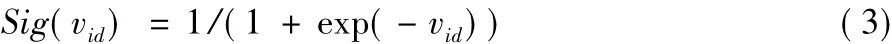
sigmoid函数是将变量映射到[0,1]区间的S型函数,其中的Sig(vid)作为位置xid取1的概率,使用rand()函数落入[0,1]区间的位置来模拟随机性:
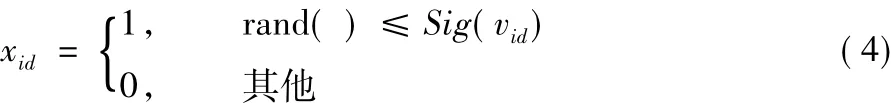
所有粒子位置更新后,Pbesti和Gbest也将得到更新,重新计算粒子的飞行速度vid。初始种群和初始粒子速度随机生成,种群经过多次迭代后收敛,最终获得种群最优解作为分配方案。
2 基于时分的测试结构
本文整体测试结构如图7所示。在设计阶段,本文方案需要根据测试数据量对3D SoC进行可测性设计优化,保证位于不同层的芯核完成测试的时间相差不大。在图7中,用于测试的数据被预先存储在ATE中,ATE发出的测试数据进入全局测试通道,经过层间的通信接口共享到不同层的不同核中。全局测试时钟经过层间移位寄存器和核间移位寄存器的分解,到达芯核后变成芯核接收数据段的频率。每次脉冲来临时,芯核就从全局测试通道接收一次数据段,当某一芯核接收到完整的测试向量,进行一次测试。
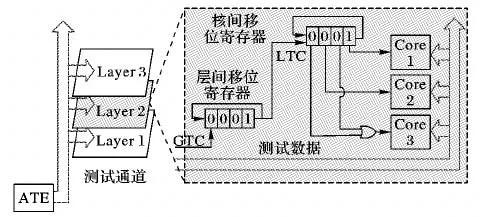
图7 并行测试结构Fig.7 Parallel test structure
对单个芯核k来说,在测试数据量和测试频率一定的情况下,测试时间tk与芯核k数据传输带宽wk成反比。将tk和wi当作矩形的长和宽,则矩形面积为:

面积 sk恒定。假定有5 个芯核 C1、C2、C3、C4和 C5,在无有效的TAM设计下,每个芯核只能串行测试,图8(a)中表示了使用串行测试方法所需要的时间,整个堆叠的测试时间较长。在进行合理的TAM资源分配后,部分芯核可以进行并行测试,相较于串行测试方法测试时间有所减少;但在图8(b)中,某些时间段仍然有大量空闲的TAM资源,存在测试资源的浪费。
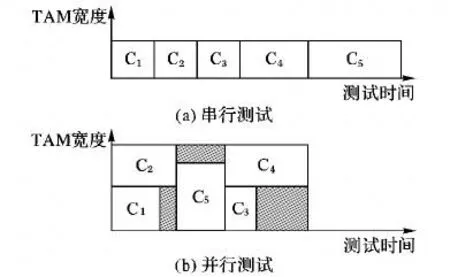
图8 串行测试与并行测试方法对比Fig.8 Comparison of serial test and parallel test methods
在本文中的测试架构设计中,所有芯核共享测试资源,理论上通过频率上的分配可以使得所有芯核在相同的时间完成测试。在图9(a)中,测试资源得到了合理的分配,使得测试时间进一步减少。然而,考虑到控制上的复杂性,在图9(b)的实际分配情况中,每个芯核的测试完成时间会略有偏差,但仍能保证芯核在比较接近的时间点完成测试;虽然造成了少量的资源浪费,但是测试效率保持了较大的提升。
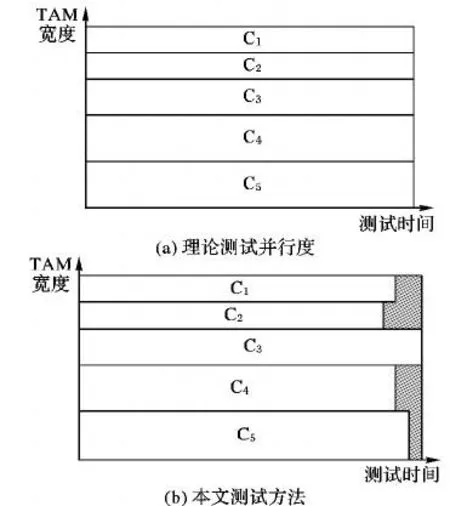
图9 本文测试调度方法与理论测试方法对比Fig.9 Comparison of proposed test scheduling method and ideal test method
3 实验与结果分析
为了验证本文分配方法的有效性,采用ISCAS-89标准测试电路中4个测试电路(C2670,C7552,S420,S641)模拟芯核进行测试,算法在Windows平台PC上采用C++程序设计语言模拟实现芯核测试过程。层间移位寄存器进行分配时的各个芯核传输测试数据需要的时钟周期数如表1所示。
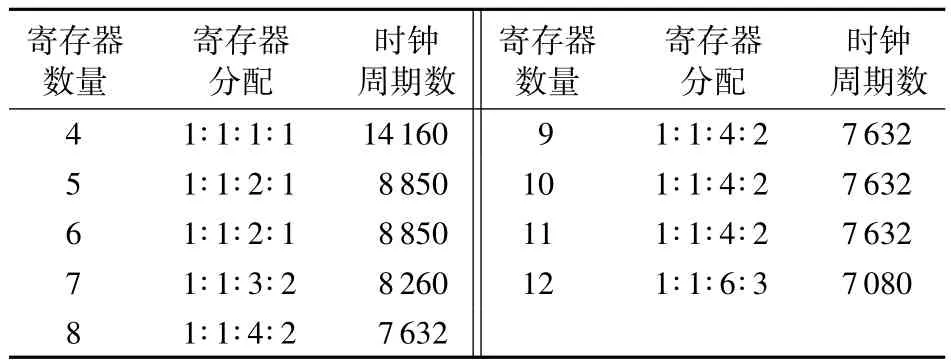
表1 芯核测试数据分配结果Tab.1 Allocation results of core test data
实验数据表明移位寄存器内寄存器的数量对测试所需时钟周期量有较大的影响。随着移位寄存器的数量增加,测试所需时钟周期急剧减少,最后趋于稳定。测试数据量的下降趋势如图10所示。
为了验证多芯核优化方案的有效性,实验选取了12个芯核、4层堆叠的三维芯片作为实验对象,层间和核间最大的寄存器数量取12个。由于芯核在测试过程中并行工作,实验通过控制ATE传输数据的频率保证整个芯片的测试功耗始终在安全阈值以下。
图11是测试通道宽度为48时,原始三维堆叠和优化后的三维堆叠TAM利用率的对比。为了更加直观地对比利用率,将每一个时钟周期作为图像的一个像素点。当该时钟周期内TAM正在使用时,像素点标为黑色;TAM空闲时,像素点标为白色。由于图中黑白像素点较为密集,部分区域黑白交替呈现出灰色,颜色越深,表示黑色像素点的占比越高。图11中,优化后的堆叠生成的图像黑色像素点较优化前占比更高,即优化后的TAM利用率更高。在测试过程中,测试资源的利用率得到提高后,相应的测试时间得到缩短。
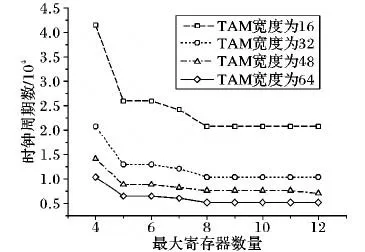
图10 最大寄存器数量与测试数据量的关系Fig.10 Relationship between maximum number of registers and amount of test data

图11 优化前后TAM利用率对比Fig.11 Comparison of TAM utilization ratio before and after optimization
本文方案优化前后的对比如表2所示。由表2可知,优化后的三维堆叠测试时间有所下降:测试通道宽度为16、32、48、64 时,测试时间分别下降 14.44%、12.71%、14.35%、14.45%,平均测试时间下降13.98%,并在整个TAM利用率上有较大的提升;测试通道宽度为16、32、48、64时,TAM利用率分别上升 16.88%、14.60%、16.75%、16.88%,平均 TAM利用率上升16.28%。
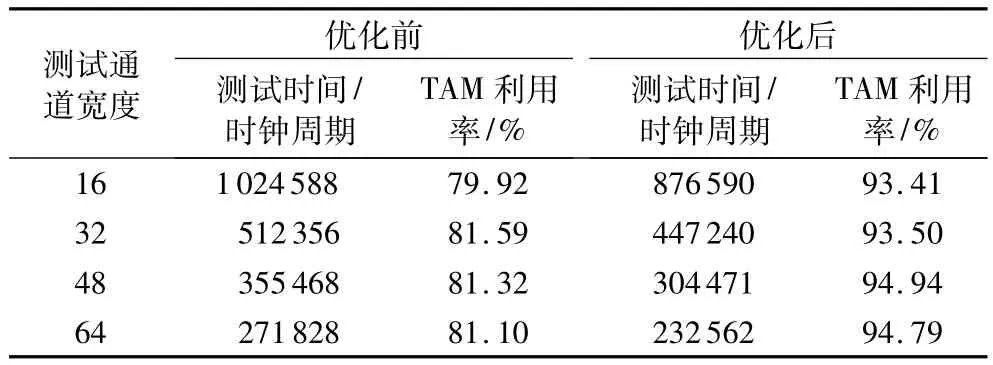
表2 优化前后测试时间和TAM利用率对比Tab.2 Comparison of test time and TAM utilization ratio before and after optimization
为了验证本文方案在测试时间上的效果,本文在ITC'02基准电路中的3D SoC(p22810、p34392和p93791)上进行实验,并与近些年来的一些方案在相同的测试频率和TAM宽度下进行了测试时间上的对比,实验结果如表3所示。其中:文献[6]方案使用整数线性规划方法寻找最优装箱策略,来提高测试并行度;文献[8]方案使用量子寻优算法优化测试调度;文献[9]方案是将测试过程按时间分段的测试架构设计;文献[10]方案采用了一种先伪平面化的结构设计再进行扫描链均衡的优化设计方法;文献[12]方案是一种时分复用的架构设计,该方案也是本文方案的研究基础;文献[16]方案是一种标准可配置的测试架构设计。总体来看,由于基准电路中部分芯核之间存在依赖关系,所以绝大多数方案不能对这类芯核并行测试;而本文方案采用时分复用的策略,宏观上看各个芯核虽然并行测试,但在测试中某一时刻,只有不多于一个芯核在进行测试,所以不存在冲突的问题。由表3可知,在相同测试频率和TAM宽度的情况下,除了文献[8]方案未提供p34392的实验数据外,本文方案均使用了较短的测试时间,有效地降低了芯片的测试成本。此外,本文方案因为所有芯核都可以并行测试且测试频率较低,相较于其他方案只有部分芯核可以并行测试,整个堆叠的发热更为均匀,也相对更安全。
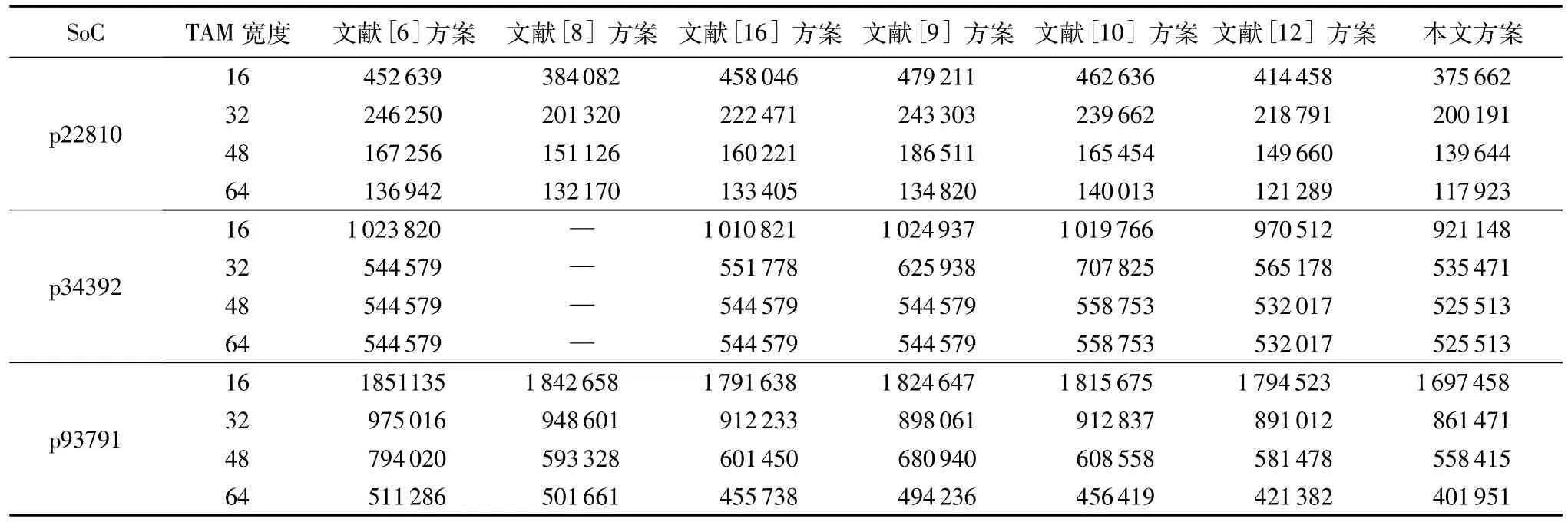
表3 不同方案的测试时间(时钟周期数)对比Tab.3 Comparison of test time(clock cycle number)of different schemes
4 结语
针对测试时间对测试成本的重要影响,本文提出了一种基于时分复用的层核间测试数据调度的多芯核优化方法。通过合理分配层核上的移位寄存器数量,提高不同芯核的测试并行度,同时使用DBPSO算法优化芯核在三维堆叠中的位置,求出最优测试芯核布图。实验结果表明,该方法不仅可以协同优化测试数据在层与核间的测试调度,并且适用于绑定前、绑定中和绑定后测试。由于方法考虑了芯核间的测试并行度问题,在减少测试时间的同时,也降低了各个芯核的测试频率,从而保证了芯核的安全测试。
本文方法目前每个时钟周期只能对一个芯核进行测试数据的传输,进一步的研究方向在于如何使相容的测试数据可以同时送入不同的芯核中,进一步提高芯核的测试并行度,减少3D SoC的测试时间。参考文献(References)
[1] 王喆垚.三维集成技术[M].北京:清华大学出版社,2014:6-18.(WANG Z Y.Three-Dimensional Integration Technology [M].Beijing:Tsinghua University Press, 2014:6 -18.)
[2] LEE H H S,CHAKRABARTY K.Test challenges for 3D integrated circuits [J].IEEE Design and Test of Computers, 2009, 26(5):26-35.
[3] NICOLICI N, AL-HASHIMI B M.Power-Constrained Testing of VLSI Circuits [M].Boston, MA:Springer, 2003:113 -115.
[4] IYENGAR V,Chakrabarty K,MARINISSEN E J.Test wrapper and test access mechanism co-optimization for system-on-chip [J].Journal of Electronic Testing,2002,18(2):213-230.
[5] ZHAO D,UPADHYAYA S.Dynamically partitioned test scheduling with adaptive TAM configuration for power-constrained SoC testing[J].IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems,2005,24(6):956-965.
[6] CHAKRABARTY K,IYENGAR V,CHANDRA A.Test wrapper and TAM co-optimization[M]//CHAKRABARTY K,IYENGAR V,CHANDRA A.Test Resource Partitioning for System-on-Chip.New York:Springer US,2002:65-93.
[7] 梁旭,李行善,于劲松.基于遗传算法的并行测试调度算法研究[J].电子测量与仪器学报,2009,23(2):19 -24.(LIANG X, LI X S, YU J S.Research on the task schedule algorithm based on the GA [J].Journal of Electronic Measurement and Instrument, 2009,23(2):19 -24.)
[8] XU C P, ZHANG J, ZHANG M.Test scheme of SOC test with multi-constrained to reduce test time[C]//Proceedings of the 2009 International Conference on Electronic Packaging Technology&High Density Packaging.Piscataway, NJ:IEEE, 2009:970 -973.
[9] ROY S, GHOSH P, RAHAMAN H, et al.Session based core test scheduling for minimizing the testing time of 3D SOC [C]//Proceedings of the 2014 International Conference on Electronics and Communication Systems.Piscataway, NJ:IEEE, 2014:1 -5.
[10] 李娇.层次化SOC可测性架构及测试调度优化策略研究[D].上海:上海大学,2014:63 -83.(LI J.The research on DFT structure and test scheduling optimization for hierarchical SOC [D].Shanghai:Shanghai University,2014:63 -83.)
[11] VARTZIOTIS F, KAVOUSIANOS X, CHAKRABARTY K, et al.Time-division multiplexing for testing DVFS-based SoCs [J].IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2015,34(4):668 -681.
[12] GEOFGIOU P,VARTZIOTIS F, KAVOUSIANOS X, et al.Twodimensional time-division multiplexing for 3D-SoCs [C]//Proceedings of the 2016 IEEE European Test Symposium.Piscataway,NJ:IEEE,2016:1-6.
[13] NDIP I, CURRAN B, LOBBICKE K, et al.High-frequency modeling of TSVs for 3-D chip integration and silicon interposers considering skin-effect,dielectric quasi-TEM and slow-wave modes[J].IEEE Transactions on Components, Packaging and Manufacturing Technology,2011,1(10):1627-1641.
[14] SHEIBANYRAD A, PETROT F.Asynchronous 3D-NoCs making use of serialized vertical links [M]//SHEIBANYRAD A,PETROT F,JANTSCH A.3D Integration for NoC-based SoC Architectures.New York:Springer, 2011:149 -165.
[15] MARINISSEN E J, ZORIAN Y.Testing 3D chips containing throughsilicon vias [C]//Proceedings of the 2009 IEEE International Test Conference.Piscataway, NJ:IEEE,2009:1-11.
[16] 李广进,陈圣俭,牛金涛,等.数字IP核的IEEE Std1500外壳架构设计研究[J].微电子学与计算机,2012,29(10):42 -46.(LI G J, CHEN S J, NIU J T, et al.Research on IEEE Std1500 wrapper design for digit IP core [J].Microelectronic & Computer,2012, 29(10):42 -46.)
