基于位置的社交网络中基于时空关系的超网络链接预测方法
2018-08-28陈元会黄宏程
胡 敏,陈元会,黄宏程
(重庆邮电大学通信与信息工程学院,重庆400065)(*通信作者电子邮箱huanghc@cqupt.edu.cn)
0 引言
随着计算机信息技术的不断发展和互联网的迅速普及,在线社交平台已经成为人们生活中不可或缺的一部分,人们可以通过这个平台建立自己的好友关系网,与好友进行即时的交流互动,这很大程度上方便了人们的生活;特别是近年来,基于位置的社交网络(Location-Based Social Network,LBSN)的出现,使得一些位置服务在短时间内受到了大量用户的推崇,获得了极大的成功。在LBSN中,用户可以在他去过的位置进行签到,并向好友分享自己的签到地点,这种签到行为能够真实反映用户的位置活动,使得线上虚拟世界和线下物理世界之间建立起密切联系[1],为社会网络链接预测带来了新的机遇和挑战。
链接预测是社会网络分析与挖掘中的一个重要方法[2],其主要目的是挖掘网络中可能存在的缺失链接或者未来链接。目前研究者们已经提出了许多基于同构网络的链接预测方法,刘思等[3]针对随机游走方法存在较强的随机性问题,利用Deep Walk学习网络中各节点间的潜在网络结构相似性,并指导随机游走过程。Duan等[4]通过引入一种集成方法解决了大规模网络下链接预测问题。这些方法在一定程度上解决了同构网络中的链接预测问题,但这些方法并不适用于异构网络。基于位置的社交网络是一类异构网络,异构网络是指网络中存在不止一种类型的节点和边(例如:位置节点和用户节点、用户 用户边、用户 位置边等);因此,越来越多的研究者开始研究LBSN中的链接预测方法。Scellato等[5]发现在Gowalla中30%的新链接发生在有过相同签到位置的用户间,进而通过位置特征、社交特征以及全局特征,提高了链接预测的准确性。该方法虽然通过位置关系缓解了数据稀疏性问题,但只考虑了两跳之内的预测空间,使得预测精度存在一定的瓶颈。Valverde-Rebaza等[6]探索了用户的移动模式和社会模式,提出了内外共同位置(Within and Outside of Common Places,WOCP)、共同邻居位置(Common Neighbors of Places,CNP)、总共和局部重叠位置(Total and Partial Overlapping of Places,TPOP)三种新特征,并通过实验验证了特征的有效性。Bayrak等[7]考虑到不同类别的位置对于链接建立的影响程度不同,提出了两种新的基于类别的特征,实验表明,新引入的特征提高了链接预测性能。
以上方法主要是在社会因素的基础上引入了位置因素的影响,通过这种额外的“资源”达到了提高预测性能的目的。时间因素对于链接预测也有着一定的影响。Cheng等[8]通过签到时间间隔、位置熵以及共同位置信息预测用户之间的朋友关系。Crandall等[9]发现如果两个用户在相同的时间和相同的地点出现过,即使时空共现的次数比较少,也会极大增加他们之间产生链接的概率;Li等[10]也得到了相同的结论。然而时间因素的引入,使得本就稀疏的网络变得更加稀疏,因此单独考虑这一种因素显得不够合理。
针对数据的稀疏性问题,刘怡君等[11]首次提出了基于超网络中的链路预测方法,通过引入超三角结构作为相似性指标,能够度量不同层网络对链接产生的影响,提高预测性能。方哲等[12]在此基础上提出了一种加权超网络中的链接预测方法,通过加权超边构建加权超三角形结构,并对节点间的链接关系进行预测,实验证明,权值的引入提高了异构网络中的链接预测性能。文献[13-14]也验证了权值的引入对异构网络预测性能有较大影响。但是在基于位置的社交网络中,边权值不仅存在于同构边之间,同时存在于异构边之间,现有大多数研究仅考虑可观测边权值对网络的影响[14-15](如用户对项目的评分、评论次数等),忽略了网络中不可观测的边权值,难以挖掘整个网络的特性,同时目前基于超网络的方法仅仅考虑了简单的超三角结构,缺乏对更深层次超边结构的发现,无法挖掘更多的隐含关系。
针对以上问题,本文提出了一种LBSN中基于时空关系的超网络链接预测方法。该方法可以有效融合时间因素、社交因素、位置因素的影响,并且能够合理量化网络边权重,较好地缓解数据稀疏性问题,同时能够提高网络的解释性以及预测性能。
本文的主要工作如下:
1)针对LBSN中网络的异构性以及时空关系特性,提取时空节点,将网络划分成“时空 用户 位置 类别”四层超网络,通过该模型可以将时间因素通过节点的形式有效融入到超网络中,以一种新颖的方式解决了因时间维度缺失所带来的预测精度缺失问题。
2)为了使网络更加符合实际,本文基于用户影响力、隐关联关系、用户偏好以及节点度信息,量化超网络中的相关边权值,构建四层加权超网络模型,边权值的定义和量化使得网络中节点间的关联关系更加准确,有助于提高模型的可解释性以及预测精度。
3)在加权超网络模型的基础上,定义多种类型的超边结构,提出一种LBSN中的超网络链接预测方法,通过该方法捕捉用户之间潜在的多种关联关系,有效解决了数据稀疏性问题,同时提高了预测准确度。
1 问题定义
1.1 相关定义
定义1 时空子网GT=(VT,ET,WT)。
时空子网GT是基于时空节点和时空节点间的关联构成的网络。其中:VT表示时空节点,如果有两个或两个以上的用户在某个特定的时间段共同访问了某个位置,那么该位置就被称为一个时空节点;ET表示时空节点之间的有向连边,即两个时空节点之间的关联关系;WT表示时空节点之间的关联权重。
定义2 用户子网GU=(VU,EU,WU)。
用户子网GU是基于用户节点和用户节点间的关系构成的网络。其中:VU表示用户节点;EU表示用户节点之间的有向连边,即两个用户节点之间的社会关系;WU表示用户节点之间的关联权重。
定义3 位置子网GP=(VP,EP,WP)。
位置子网GP是基于位置节点和位置节点间的关联构成的网络。其中:VP表示位置节点;EP表示位置节点之间的有向连边,即两个位置节点之间的关联关系;WP表示位置节点之间的关联权重。
定义4 类型子网GC=(VC,EC,WC)。
类型子网GC是基于类型节点和类型节点间的关联构成的网络。其中:VC表示类型节点;EC表示类型节点之间的有向连边,即两个类型节点之间的关联关系;WC表示类型节点之间的关联权重。
1.2 问题形式化
为了形式化地描述本文研究的科学问题,首先假设G=(V,E,W)是本文研究的基于位置的社交网络,以及网络中的用户行为数据B={(b,vi)|vi∈V}。在上述定义的基础上,量化子网间的关联权重WM,则网络可以划分成“时空 用户
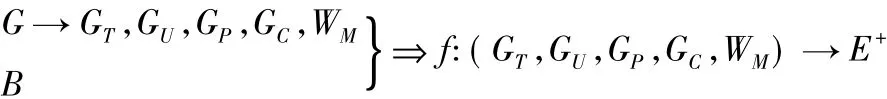
1.2.1 问题输入
基于上述定义,本文研究内容的输入为:
1)基于位置的社交网络G=(V,E,W);
2)络中的用户行为B={(b,vi)|vi∈V},表示用户vi的行为b,这里的用户行为包括用户间的跟随行为、用户对位置的签到和评分等。
1.2.2 问题输出
在给定基于位置的社交网络G=(V,E,W)以及网络中的用户行为B={(b,vi)|vi∈V}的前提下,解决如下问题:
1)如何构建网络模型,解决基于位置的社交网络中的链接预测面临的网络异构性、权值定义不完善、未考虑时间因素等问题。通过提取时空节点,将网络划分成“时空 用户 位置类别”四层超网络,融合时间因素的影响,同时挖掘用户的隐位置 类别”四层加权超网络:GT、GU、GP、GC、WM,可以利用本文提出的方法预测用户子网中用户之间可能存在的链接关系E+。更明确的问题定义表示为:式行为,计算用户间影响力,利用用户的兴趣偏好以及位置间的潜在关联关系,量化超网络中的相关边权值,构建四层加权超网络模型 SG=(GT,GU,GP,GC,WM,B)。
2)如何利用加权超网络模型进行链接预测,并解决网络稀疏性问题。通过定义多种类型的超边结构可以量化用户间不同的关联关系,解决数据稀疏性问题,并引入参数集合θ,量化每种超边结构的重要程度,求取最优参数集合θ+=Pθ(E|G),利用最优参数集合θ+对用户间的链接关系E+进行预测,即E+=Pθ+(EU|GU)。
2 基于时空关系的超网络链接预测方法
本文方法主要包括三个阶段:1)构建加权超网络模型,构建时空 用户 位置 类别四层超网络,将时间、社交、位置等因素有效融合,然后基于用户影响力、隐关联关系、用户偏好以及节点度信息量化超网络中的边权值,构建四层加权超网络模型;2)建立加权超边结构,在加权超网络模型的基础上,建立超边结构;3)建立超链接预测,对每种超边结构的重要程度进行量化,从而对用户间的链接关系进行预测。
2.1 构建加权超网络模型
在上述定义的时空子网、用户子网、位置子网以及类别子网的基础上,子网与子网间也有一定的关联,如图1所示。通过四种不同的加权方式对子网内以及子网间的边权值进行定义和量化。

图1 加权超网络模型Fig.1 Weighted supernetwork model
2.1.1 基于用户影响力
在基于位置的社交网络中,每个用户的影响力是不同的。如果某个好友对我们的影响力极低,那么我们很难通过该好友与其他人产生某些行为与联系。所以,通过用户的影响力量化用户 用户边权值w(u,u')是提高模型解释性和准确性的一种可行方法。本文主要通过挖掘基于位置的社交网络中的追随行为以及追随网络来度量用户的影响力,如果用户u'在其好友u签到过的地方进行了一次签到,则认为用户u'产生了对用户u的追随行为。由追随行为构成的有向网络,称之为追随网络Gf=(Vf,Ef),其中:Vf表示追随网络中的用户,Ef表示追随行为的有向边。与此同时,我们将用户影响力分为用户个体影响力以及用户间影响力,并分别通过追随网络以及追随行为来度量。
1)用户个体影响力。
用户个体影响力Iu用于度量用户因自身行为对网络中其他用户产生的影响,是一种全局角度的度量方法。由于个体影响力会随着时间而动态变化,有的用户可能开始比较活跃,其签到行为产生了许多追随边,产生了较大的影响力,之后活跃度下降,则其影响力会逐渐减弱,长久如此,影响力会衰减至一个较低的稳定值。因此,在考虑用户影响力的时候,时间因素的影响极为重要。
本文首先划分s个不同的时间切片,将每个时间切片中用户的追随行为构成相应的追随网络(,…),用户的最终个体影响力由每一个时域中的个体影响力贡献而来,并且离当前时刻越久远的时域其个体影响力衰减越多。考虑到网络中孤立节点的存在,本文采用LeaderRank算法[16]求解用户个体影响力。该算法通过引入Ground Node,很好地解决了PageRank中因孤立节点而造成的排序结果不唯一的问题,算法的迭代公式如下:

其中:Nu表示用户u的邻居节点;koutu'表示u'的出度。
在稳定状态下,LeaderRank将Ground Node的分数均匀分布到所有其他节点,因此节点的最终得分可以表示为:

其中:Ig(td)是Ground Node在稳定状态下的分数;N表示用户节点个数。
随着时间的推移,用户的影响力会随之递减,所以本文定义衰减函数为:
其中:tc表示当前时刻;ti表示第i个时间片;tm表示影响力减小的半衰期。则用户u在当前时刻个体影响力总值Iu为:

其中Iuti表示第ti个时间片用户u的个体影响力。
2)用户间影响力。
用户间影响力Ii(u,u')用于度量用户u对用户u'的影响力大小,是一种局部视角的度量方法。通常情况下,两个用户之间交互次数越多,则他们之间的影响力会越大。在本文中将追随行为视为用户间的交互并以此来度量用户间影响力。提出追随地点比例Ip和追随签到比例Ic这两种衡量指标:

其中:Mu',u表示用户u'追随用户u的签到地点数;Positionu表示用户u的签到位置总数;Ku',u表示用户u'追随用户u的总签到次数;Checkinu表示用户u的签到总次数。
综合考虑用户间影响力Ii(u,u')和用户的个体影响力Iu,则用户影响力I(u,u')为:

其中:Iu为用户个体影响力;Ip为追随地点比例;Ic为追随签到比例;1+2+3=1,本文中1=0.4,2=3=0.3。
基于用户影响力,可以定义用户 用户边权值w(u,u'),对于节点对u-u',如果u'对u的用户间影响力高,则对应权值w(u,u')也应当高,所以用户间的边权值为:

2.1.2 基于隐关联关系
隐关联关系指的是无法直接通过用户的签到信息观察到的关系,例如两个位置之间的关系以及两个类别之间的关系。曹玖新等[17]将两个位置之间的这种关系定义为兴趣点相关,本文中的位置 位置边权值是在此定义的上进行改进的。
1)位置 位置边权值w(p,p')。
如果某个用户在一定的时间阈值内连续访问了某两个位置,那么这两个位置就存在一定的隐含关联关系,同时由于大多数用户喜欢访问与曾经去过的位置相近的位置[18],所以本文通过距离以及隐含关联关系定义位置与位置之间的边权值:

其中:geodist(p,p')表示位置p和p'间的距离;Countp表示所有被关联位置次数的最大值;Count(p,p')表示两个位置被关联的次数。
2)时空 时空边权值w(t,t')。
时空节点之间的边权值是在位置边权值的基础上增加时间距离,其定义如下:

3)类别 类别边权值w(c,c')。
如果两种类别属性同时出现在多个位置,那么这两种类别之间也就存在一定的隐含关联关系,例如从数据统计中可以发现类别Bars与类别Nightlife经常出现在多个位置的类别属性中,隐含地表明这两种类别之间存在一定的相关性。本文通过这种相关性定义类别 类别边权值:

其中:Count(c,c')表示同时属于类别c和类别c'的地点个数;Countc表示同时属于类型c和其他某种类型的地点数的最大值。
2.1.3 基于用户偏好
用户偏好反映了用户对位置的喜好程度,如果两个用户对同一个兴趣点表现出浓厚的兴趣,那么这两个用户有很大的可能会产生链接关系,所以为了有效融入偏好信息,提高超网络模型的可解释性,本文从用户评分入手定义和量化用户位置边权值w(u,p)以及用户 时空边权值w(u,t)。
在基于位置的社交网络中,用户对位置的评分属性能够直观地反映出用户对这个位置的偏好程度。比如,用户u1在p1、p2、p3三个位置进行过评分,并分别给出了5、3、1的评分值,如果不考虑用户对这个位置的评分属性,那么会给每条用户 位置边赋值1/3,但实际上这是不准确的,如果用户u1对p3的评分为1分,表明用户对这个地方是不满意的,这个时候,应当增加u1-p1的边权值,减小u1-p3的边权值。因此,应当给用户偏好高的位置更高的权值,本文参考文献[19]的方法通过指数函数定义用户 位置边权值,计算式如下:
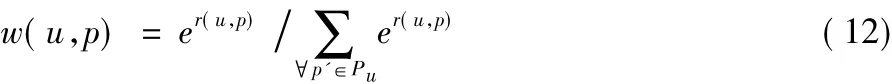
其中r(u,p)表示用户u在位置p处的评分。
基于同样的道理,用户 时空边权值也可以相应地通过指数函数进行定义,计算式如下:
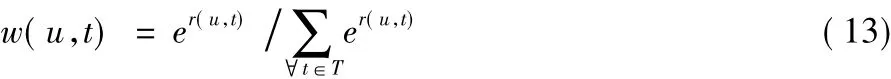
其中r(u,t)表示用户u在时空节点t处的评分。
需要注意的是如果用户对一个位置进行过多次评分,本文仅将用户的最后一次的评分作为标准。
2.1.4 基于节点度信息
通过节点度信息定义和量化边权值类似于资源分配的原理,如果节点出度较多,则每个出度节点获得的资源就会相对较少。
1)时空 用户边权值w(t,u):

其中|Ut|表示时空节点包含的用户个数。
2)位置 用户边权值w(p,u):

3)位置 类别边权值w(p,c):

其中|Cp|表示位置p所属的类别个数。
4)类别 位置边权值w(c,p):

其中|Pc|表示类别c包含的位置个数。
2.2 建立加权超边结构
2.2.1 加权超边结构相关定义
在加权超网络模型中,存在着多种类型的超边,比如用户节点与位置节点间构成的边可称为一条超边,用户节点与时空节点间构成的边也可称为一条超边。由于不同的超边,其包含的异构节点个数不同,因此,定义三种类型的超边。
定义5 一类超边SEI。一类超边是指只包含一种类型节点的超边,在超网中属于一类特殊的超边。例如,两个用户节点构成的一条超边称之为一类超边。一类超边表明了同层子网中节点之间的关联关系,例如对于用户子网,指的是用户之间的好友关系。
定义6 二类超边SEII。二类超边是指相邻两层子网之间的节点对构成的边,其特点是只包含两种异构节点。例如,用户与位置节点或者用户与时空节点之间构成的超边,称之为二类超边。
定义7 三类超边SEIII。三类超边是指相邻三层子网构成的边,其特点是包含三种异构节点。例如,用户、位置和类别节点构成的超边,称之为三类超边。
如图2~3所示,图2为相邻的两层网络,其中:(t1-t2)构成了一条一类超边,记为SEI(t1-t2);(u1-t1)构成了一条二类超边,记为SEII(u1-t1);(u3-t1)也构成了一条二类超边,记为SEII(u3-t1)。图3为相邻的三层网络,其中:(u1-p1-c1)组成了一条三类超边,记为SEIII(u1-p1-c1),(c1-p3-u3)也组成了一条三类超边,记为SEIII(c1-p3-u3)。

图2 二层超网络Fig.2 Two-layer supernetwork

图3 三层超网络Fig.3 Three-layer supernetwork
定义8 超边权重。超边权重是指每条超边所具有的权值,可通过超边中包含的边权值计算得到。例如,图2中的二类超边SEII(u1-t1),其超边权重WSEII(u1-t1)=w(u1,t1);图3中的三类超边权重WSEIII(u1-p1-c1) =w(u1,p1)·w(p1,c1),WSEIII(c1- p3- u3)=w(c1,p3)·w(p3,u3)。
基于这三种类型的超边,本文提出加权超边结构,通过加权超边结构解决用户与用户间的超链接预测问题。在以往的方法中,主要是通过加权超三角形结构来计算节点之间的关联程度,其主要思想是通过不同超边之间的共现节点将两条超边关联起来,从而得到超三角形结构用于度量节点间的相似性。这种方法适用于异构网络,能够简单高效地捕捉两个节点之间的额外关联,在缓解数据稀疏问题的同时也提高了预测准确度。然而超网络不仅可以描述同构节点之间的关联,同时能够描述异构节点之间的关联,因此考虑的网络层次越深,关联链越长,则越可以反映出节点间细粒度的隐性关联。本文通过构造多种类型的加权超边结构挖掘节点间的隐含语义关系。
在本文的方法中主要包含三类加权超边结构,分别为加权超三角形结构、加权超矩形结构以及加权超混合结构。下面通过图2~3对这三类结构进行举例说明。
2.2.2 加权超三角形结构
1)单加权超三角形结构。
如图2所示,可以通过时空节点t1与用户节点u1、u3构成的单层加权超三角形结构来计算u1、u3间的相似性。如果包含u1、u3的单加权超三角形结构个数越多,权值越大,则认为它们之间的关联性也越大,越可能产生链接。该超三角形结构包含两条二类超边SEII(u1-t1)和SEII(t1-u3),超三角形结构的权重为对应超边权重之积,计算式如下:
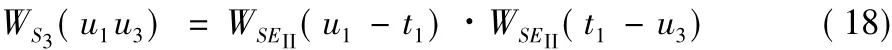
需要强调的是本文定义的超边结构均为闭环结构,具有方向性,所以WS3(u1u3)≠WS3(u3u1),后文同理。
2)双加权超三角形结构。
双加权超三角形结构包含两个连续的单加权超三角形结构,例如,图2中SEII(u1-t1)和SEII(t1-u2)组成了一个单加权超三角形结构WS3(u1u2),SEII(u2-t2)和SEII(t2-u3)也构成了一个单加权超三角形结构WS3(u2u3),这两个单加权超三角形结构可以组合成一个双加权超三角形结构,用来度量u1、u3之间的相似度,该结构的语义信息为用户u1和u3都喜欢与用户u2在相同时间相同的位置活动。该双加权超三角形结构权值为对应的两个单加权超三角形结构权值之积,所以权值为:

3)三层加权超三角形结构。
三层加权超三角形结构是指由两条三类超边组成的三角形结构。如图3所示,超边 SEIII(u1-p1-c1)和超边SEIII(u1-p3-c3)就组成了一个三层加权超三角形结构。其权值为两条三类超边权值之积,所以权值为:
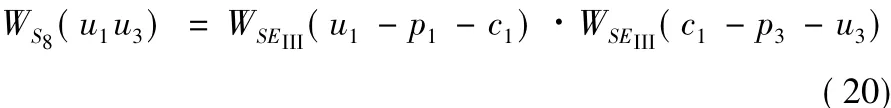
2.2.3 加权超矩形结构
如图2所示,超边 SEII(u1-t1),SEI(t1-t2),SEII(t2-u3)可以构成一个加权超矩形结构,该加权超矩形结构中包含了u1、u3两个节点,可用于度量u1、u3之间的相似性,该结构的语义信息为用户u1和u3喜欢在两个相关的时空节点处活动,其权值为对应超边权值之积,所以权值为:

2.2.4 加权超混合结构
1)加权超混合I结构。
混合I结构是指在单三角形结构的基础上增加一条一类超边而组成的结构。如图2所示,由超边SEII(u1-t1),SEII(t1-u2),SEI(u2-u3)组成的结构属于混合I结构,该结构表达的语义信息为u3的好友u2喜欢与u1在相同的时间相同的位置活动,其权值为对应的单加权超三角形结构权值与一类超边权值之积,计算式如下:
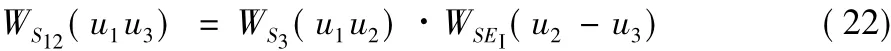
2)加权超混合II结构。
混合II结构是指在矩形结构的基础上增加一条一类超边而组成的结构。如图2所示,由超边SEII(u1-t1),SEI(t1-t2),SEII(t2-u2),SEI(u2-u3)组成的结构属于混合II结构,其权值为对应的加权超矩形结构权值与一类超边权值之积,计算式如下:

可以看出层次越深,关联链路越长,超边结构越丰富。本文列出了其中19种加权超边结构,如表1所示。
从前文分析可知,不同的加权超边结构具有不同的语义信息,例如S2结构体现了位置熵[20]的含义,位置熵是指如果两个用户在一个很多人去过的地方有过共同签到,很难预测这两个人之间存在好友关系,因为这有可能是一种巧合,但是如果两个用户经常在一个很少人去过的地方进行签到,则表明它们之间很可能存在一定的关系。所以一个位置的受欢迎程度也对链接预测有着影响,而通过S2结构能够有效捕捉到这种影响。S3结构能够挖掘出用户的一种短期兴趣,此处的短期兴趣解释为用户可能只在某一个时间段才具有的兴趣,例如每周五晚上7点去电影院看电影。这种兴趣只会发生在特定的时间段,但更能体现出用户的个性。S11结构反映了两个用户虽然没有去过同一个位置,但却经常去相同类别的地方,这体现了两个用户拥有相同的类别偏好,有助于挖掘用户间的关联关系。
2.3 超链接预测
对于训练集中任意两个用户(u,v),均存在上述的19种加权超边结构特征,这些特征的集合可以表示为W(u,v)={WS1(u,v),WS2(u,v),…,WS19(u,v)}。本文通过逻辑回归计算u对v产生链接的概率:
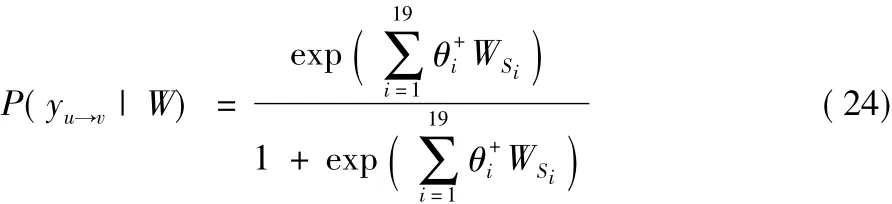
其中θi表示第i个加权超边结构对链接建立的影响程度,利用梯度下降算法来更新参数值,参数更新过程如下:

其中:λ表示学习步长;yu-v表示用户间是否存在链接。当每个参数的变化值都小于某个阈值时,参数更新已收敛,得到最优参数集合θ+。
最终对于测试集中的用户对(u,u'),其产生链接的概率为:

当 P(yu-u'~ W) 大于等于阈值 ξ时,yu-u'取值为 1,认为用户间存在链接;否则yu-u'取值为0,认为用户间不存在链接。从而找出了用户间可能存在的链接关系E+。yu-u'定义式如下:
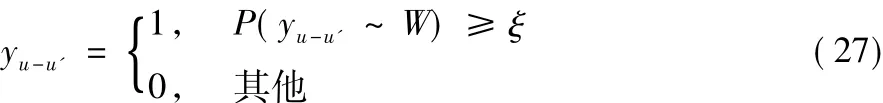
2.4 算法描述
本文输入为基于位置的社交网络G=(V,E,W)以及网络中的用户行为B={(b,vi)|vi∈V},输出为用户子网中的可能存在的链接关系E+。通过构建加权超网络模型,建立多种加权超边结构计算用户节点之间产生链接的概率,从而预测用户间可能存在的链接关系。其算法描述如算法1所示。
算法1 基于时空关系的超网络链接预测方法。
输入 基于位置的社交网络G=(V,E,W);网络中的用户行为 B={(b,vi)|vi∈ V}。
输出 用户子网中可能存在的链接关系E+。
//划分四层超网络
1) 基于用户的签到位置p和时间time构建时空节点T;
2) 构建时空子网GT、用户子网GU、位置子网GP和类别子网GC;
3) 基于用户影响力、隐关联关系、用户偏好以及节点度信息定义网络边权值,并依据式(1)~(17)对网络边权值进行量化;
4) 构建三种类型的超边SEI、SEII、SEIII,并计算超边权重WSE;
5) 基于三类超边,建立加权超三角形结构、加权超矩形结构、加权超混合结构,并依据式(18)~(23)计算加权超边结构的权重WSi;
6) For j←1 to|M|do //|M|为总节点对个数
7) For i←1 to 19 do //19种超边结构
8) 计算每一个超边结构下的WSi;
9) End for
10) 依据式(24)计算链接产生概率,并加入候选集合Ms;
11)End for
12)根据式(26)计算Ms集合中的P(yu-u'~W);
13)根据式(27)判断用户间可能存在的链接关系E+。
3 仿真实验与分析
3.1 数据集
本文采用yelp数据集进行实验,数据集来源于yelp挑战赛的开放数据集,包含了用户表、商家表以及评论表。用户表中有每个用户的好友列表、评论次数等信息,商家表中有所属类别、经纬度以及一些详细的属性标签。评论表中有用户对商家的评论、评分以及评分时间。
实验中,删除总评论数少于10次的不活跃用户以及被评论总次数少于5次的商家以减小稀疏数据的影响,处理后的用户签到分布以及商家被签到分布情况如图4所示。图4(a)中横坐标为20的坐标点表示用户签到次数在[10,20)的用户数。从图4可以看出用户签到以及商家被签到次数均符合幂律分布特性。

图4 用户和商家签到分布Fig.4 Check-in distribution of users and businesses
接下来对预处理后各层子网以及相邻子网间的情况进行统计说明。
1)四层子网。针对时空子网,由于yelp数据集中评论时间只能精确到天,考虑到相隔时间太长会影响时空节点的本质作用,所以本文以同一天为标准提取时空节点,实验中总共提取的时空节点个数为850 437个,所以该层节点数为850437个,理论上任意两个时空节点之间均存在连边(通过权值控制连边强弱);针对用户子网,由于剔除了总评论次数少于10次的不活跃用户,所以该层保留的有效节点数为426656个,相比于原始用户数据占比0.414,好友关系数为2703594条,相比于原始用户关系占比0.461;针对位置子网,由于剔除了被评论次数少于5次的商家,所以该层的剩余节点数为95190个,相比于原始商家数占比为0.661,理论上任意两个商家位置之间均存在连边;针对类别子网,由于部分商家被踢除,导致总体类别数下降,由原来的1192类商家减少到1007类,所以该层的节点个数为1007个,相比于原始类别数据占比为0.845,理论上任意两个类别节点之间均存在连边。
2)相邻子网。由于剔除了部分用户以及商家,使得用户 位置边减少(评论签到关系),由原来的4 153 150条边较少为2943312条边,占比为0.709;用户 时空节点之间的边数统计为4295 788条,从数据统计结果可以看出,对于大多数时空节点来说,仅包含两个用户,随着时空节点包含用户数的增多,相应时空节点个数按幂律分布减少,如图5所示,位置 类别之间的边数统计为351952条。
3.2 评价指标
本文中,主要使用准确率(precision)、召回率(recall)、F1指标(F1-measure)、受试者工作特征曲线下面积(Area Under the receiver operating characteristic Curve,AUC)来评估算法的质量。
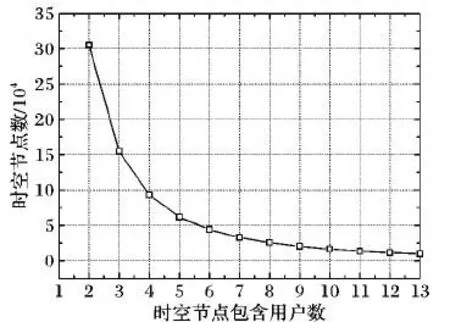
图5 时空节点分布Fig.5 Distribution of spatio-temporal nodes
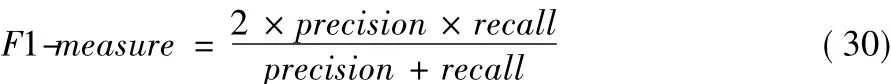
4)AUC。
AUC是评估链接预测结果质量的常用指标。AUC指标可以描述为在测试集中随机选择一条存在连边的分数值比随机选择一条不存在连边的分数值高的概率。这样独立重复比较n次,在n次中,如果有n'次在测试集中存在连边的分数比不存在连边的分数值高,有n″次在测试集中存在连边的分数值与不存在连边的分数值相等,则AUC值可以定义为:

一般来说,AUC值越高代表预测性能越好,完美结果的AUC值是1.0,而随机预测结果的AUC是0.5。
3.3 实验结果与分析
在实验中,采用不同的比例(0.5~0.9)来划分数据集以准确评估算法的性能。首先对比不同超边结构及其组合下的准确率、召回率、F1值以及AUC。令:K1表示加权超三角形结构,K2表示加权超矩形结构,K3表示加权超混合结构。
实验结果如图6所示,其中横坐标表示训练集占整个数据集的比例。从图6可以看出,随着训练集边数占总边数的比例加大,所有指标均呈现上升状态,表明预测的效果在不断提升。从图6(d)中AUC指标可以看出,训练集占比为0.9时,各特征的预测性能达到最优。其中:K1的预测效果是最好的,其次是K3,最后是K2。其原因是K1结构能够捕捉到较多重要的信息,比如,其中的S1结构能够捕捉两个用户的共同好友信息,S2结构能够捕捉两个用户的共同签到地点信息,S3结构能够捕捉两个用户的共同时空节点信息,而这些都是预测用户之间链接较为重要的信息。
在两两组合的预测效果中,K2+K3的预测性能最差,预测效果低于K1特征,K1+K3的预测性能最好,可以看出组合
1)准确率。
令VL为得分最高的L个节点对,如果在VL中只有m个节点对存在连边,则准确度可以表示为:

2)召回率。
令M=|E|,表示网络中存在的边,假设算法预测出来的缺失边个数为m,则召回率可通过如式(29)求得:

3)F1指标。
通过准确率和召回率,可以得到F1综合指标,其定义如下:特征的效果要优于组合中单个特征的效果。K1+K2+K3由于 有效融合了每组结构特征的信息,所以其预测性能最优。
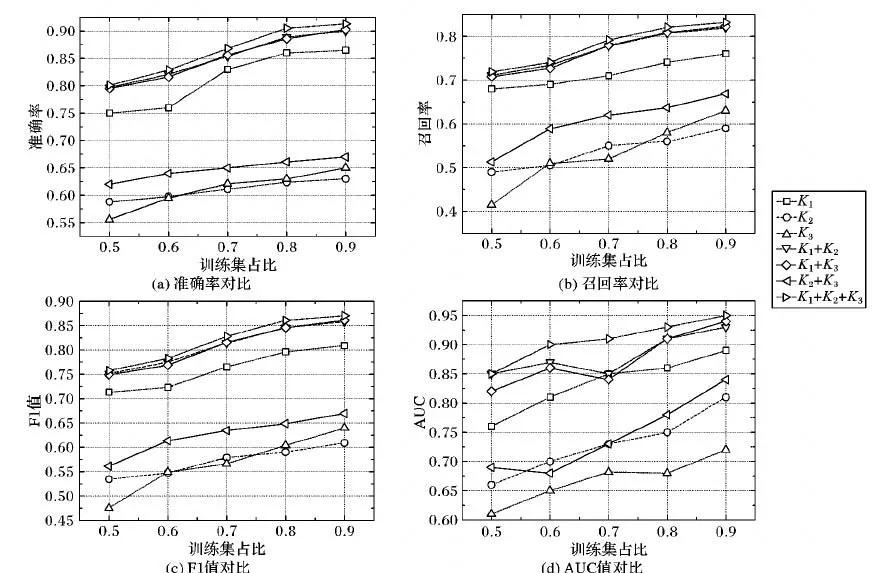
图6 不同特征组合下各指标对比Fig.6 Comparison of different indicators under different combinations of features
由于训练集占比为0.9时,算法性能最优,所以后面的对比实验均采用0.9来划分数据集。为了验证时空节点的引入对实验结果的影响,本文对比包含时空节点层的加权超网络模型与不包含时空节点层的加权超网络模型(用户 位置 类别三层),并分别提取模型中的加权超边结构,计算节点间的相似性,实验结果如图7所示,其中横坐标表示不同的指标,纵坐标表示这些指标下的测试值。

图7 时空节点对比Fig.7 Comparison of spatio-temporal nodes
从图7中可以看出,引入时空节点层之后,算法的准确率、召回率、F1值以及AUC都有一定程度的提升,其原因是时空节点不仅能够捕捉两个用户在访问位置上的兴趣相似性,同时还能捕捉其在访问时间上的相似性。因此,即使两个用户共同签到位置数较少,但只要他们在这些地方的签到时间比较接近,也能够通过时空节点层准确捕捉他们之间的相似性,从而对链接关系进行有效预测,而这些是无法通过位置节点做到的。时空节点层的引入使得我们可以兼顾位置因素的影响以及时空因素的影响,通过对这两类信息的有效利用,本文的算法性能得到了一定的提升。
最后对比不同方法之间的性能优劣,本文选取同构网络中的方法以及异构网络中的方法与本文的方法进行对比。同构网络中的对比方法选择经典的共同邻居指标 (Common Neighbor,CN)[21]、资 源 分 配 指 标 (Resource Allocation,RA)[22],其中 CN 是由 Liben-Nowell等[21]提出的解决链接预测问题的基本方法,是一种基于邻居结构的标准度量方法;RA则是由Zhou等[22]在CN的基础上提出的改进方法,并验证了其在多个网络中的有效性,这两种方法属于同构网络中解决链接预测问题的代表性方法。异构网络中选择文献[8]中的方法Model-II、文献[12]中的超链接预测方法超网络杰卡德指标(Supernetwork JACCARD,SJACCARD),以及文献[13]中的PathPredict方法,其中Model-II方法基于两个用户所有的共现位置信息提出了五种相关特征:加权共现次数、加权共同位置数、平均时间间隔、最小时间间隔、最大时间间隔,并验证了算法的优越性;SJACCARD方法为加权超网络下的一种方法,该方法通过加权超三角结构预测节点之间的链接关系,取得了一定的效果;PathPredict方法为异构网络链接预测中的基准方法,该方法通过路径数、随机游走等方式度量异质节点之间的语义关联关系,适用于无权网络。本文所有结果均采用10折交叉验证得到,六种方法的性能对比结果如表2所示。
由表2可以看出,所有的异构方法均要优于同构方法,反映出异构方法对信息的利用率更高。CN和RA方法仅仅利用到了同构网络中的社交关系,所以其各指标均相对较低,RA方法由于通过节点的度信息量化了不同邻居节点的贡献,所以其性能要优于CN。在异构方法中由于SJACCARD方法仅仅利用到了两种异构加权超三角形结构,未能利用到同构边关系,所以其AUC值仅比CN高出0.049,PathPredict方法虽然通过多种元路径特征较好地捕捉了异构关系,但其没能有效利用网络中的多种权值信息,所以其AUC值低于本文方法,但高出 CN方法0.154,Model-II方法的性能优于PathPredict,AUC值达到了0.915,较好地证明了时间因素的引入能够提高预测精度。本文方法通过引入时空节点以及多种异构结构,同时较好地结合了网络边权值,预测性能最优,AUC值达到0.958,相比于异构网络方法中的Model-II方法,AUC值提升了4.69%。

表2 不同方法的性能对比Tab.2 Performance comparison of different methods
4 结语
链接预测研究可以用于解决网络中的链路缺失问题,在推荐领域具有重要的应用前景。针对LBSN链接预测中网络权值利用不完善以及数据稀疏性等问题,本文提出了一种可行方法。该方法通过用户影响力、隐关联关系、用户偏好以及节点度信息对超网络中的边权值进行定义和量化,并通过多种加权超边结构来捕捉用户间的多种关联关系,缓解数据稀疏性问题的同时提高了链接预测性能。实验结果表明,本文方法相比现有其他方法有着更加准确的预测精度,更加适用于复杂的异构网络推荐领域,可提高用户对平台的忠诚度以及黏度,从而令平台具备更加长久的发展空间。
本文仅针对一个社交网络数据进行研究,而大多数用户会活跃在多个社交平台,例如QQ和微博,如何获取相应数据并合理构建多维度的超网络模型来预测网络中的连边关系是我们下一步要解决的关键问题。
