基于HBase的路网移动对象时空索引方法
2018-08-28李顶圣陆佳民张立霞
冯 钧,李顶圣,陆佳民,张立霞
(河海大学计算机与信息学院,南京211100)(* 通信作者电子邮箱 jiamin.luu@hhu.edu.cn)
0 引言
随着智能定位设备的不断发展,路网移动对象数据量呈现指数级的增长趋势。此外,路网移动对象数据具有对象沿路网运动、数据在不同的路段中分布不均等特点。传统的关系型数据库已经无法满足海量路网数据的存储需求,HBase作为一种分布式的数据库系统,数据以key/value的形式进行存储,有效解决了海量数据的存储低效问题,但HBase缺少高效路网环境下的时空索引。
为了弥补原生HBase针对时空对象高效索引机制的不足,近几年提出的具有代表性的索引研究主要有两种:可扩展的基于位置服务的数据管理系统——MD-HBase(Multidimensional Data HBase)[1]和 时 空 HBase 索 引 (Spatial-TEmporal HBase IndeX,STEHIX)框架[2]。MD-HBase是文献[1]提出的索引框架,相比原生的HBase能够显著提高海量时空数据的查询性能,但是由于只在上层创建索引,未考虑在存储层创建索引,其性能提高有限。针对这一问题,文献[2]在MD-HBase的结构上进行改进提出了STEHIX索引框架,主要用于提高时空数据的范围查询和 KNN查询的查询效率。与MD-HBase相比,STEHIX索引框架因为在存储层创建了一维索引,因此对时空数据的查询效率有很大提升。上述两种索引框架在应用到路网环境下的时空数据索引当中时,依然存在以下几方面的问题:利用常见的等大小的空间划分方法,如四叉树[3]或者 kd-tree[4]的空间划分方法,在对空间对象的查询过程中会出现“死空间”问题;由于在不同路段中车流量信息是分布不均的,采用均衡的子空间分配算法可能会导致集群节点的热点问题,从而造成服务器的存储压力;原生的HBase只支持基于Rowkey键的查询、基于Rowkey区间的范围查询和全表扫描,不能支持复杂的多条件查询。而STEHIX索引框架并没有考虑Rowkey键设计对索引的影响,同时STEHIX应用于路网的性能有待提高。
针对STEHIX处理路网环境移动对象时空索引存在的数据热点分布、空间划分“死空间”等问题与不足,本文在HBase存储结构的基础上设计并实现了一种高效的路网移动对象HBase索引框架(HBase indexing framework for Road network Moving objects,RM-HBase),通过对原生HBase索引结构的上层Hmaster进行改进,解决分布式集群数据的热点分布问题;通过提出空间对象索引RN-tree(Road Network tree),解决空间划分中的“死空间”问题,提高了路网环境下的空间检索效率;同时通过对原生Hbase的 RowKey值进行设计及下层HRegion进行索引提高路网时空数据的索引性能。
1 RM-HBase索引框架
1.1 索引框架
1.1.1 路网时空数据定义
路网移动对象数据是时空数据的一种特殊环境下的子类,数据包括一维时间和二维空间共三个维度。对路网时空数据进行定义是进行索引框架研究的基础,其中数据包括两种类型:空间路网数据和移动对象数据,本文对每种数据的定义如下。
1)空间路网数据。
本文研究的空间路网数据包括横坐标和纵坐标两个维度,移动对象(如车辆等)沿着路网中的路段在空间中运动,因此对移动对象的位置定义包括两个维度。本文采用路段模型[5]对路网建模,路网中的基本元素为路段。模型创建后生成路网图,其中:图中顶点的集合表示两个路段之间的交叉点;图中的边集合表示实际的路段。每条路段采用两个顶点作为唯一性编码标识。
2)移动对象数据。
移动对象数据是由路网中的移动对象(车辆等)随时间运动而产生的数据,也就是最终存储在集群节点中的数据。该类数据是一种时空数据,数据按条存储在HBase的用户表中,每条移动对象数据记录的属性如表1所示。
本文的分布式数据库HBase表用于存储路网中的移动对象数据,HBase数据库中只存储一张移动对象数据表:MoveObject。HBase的Region中Store数量与列簇的个数相对应,为了避免出现不同Region中的数据热点问题,同时降低每个Region初始化时创建Store的代价,每张表中只设计一个列簇:objectinfo,该列簇下包括五部分属性:移动对象标识oid、道路标识rid、经度信息pos_x、纬度信息pos_y和时间time。在MoveObject数据表中的定义形式分别是:objectinfo:oid、objectinfo:rid、objectinfo:pos_x、objectinfo:pos_y 和 objectinfo:time。此外,表中的时间戳TimeStemp属性用于记录数据的版本。

表1 MoveObject表的结构Tab.1 Structure of MoveObject table
1.1.2 RM-HBase 的结构
RM-HBase是本文提出的一种用于解决海量路网移动对象数据高效索引问题的新型框架,该框架基于Hbase的内部存储结构对索引过程加以改进。将HBase划分为上下两层:上层包括ZooKeeper和HMaster,是数据的管理层,主要通过.ROOT表和.META 表实现关系映射索引[6];下层包括HRegionServer,是数据的存储层,通过Region实现数据存储。新框架的设计思想受STEHIX索引框架启发,结合路网环境中的数据特点,对原生HBase存储结构作了如下三个方面的优化:
1)设计路网空间索引RN-tree以提高索引效率,空间路网数据存储在HMaster中的内存区域中,索引的创建过程包括两个阶段:空间路网划分和RN-tree的创建。RN-tree是一棵多路径平衡搜索树。
2)基于HBase上层的索引结构设计。上层索引设计的改进包括对.META表中的存储内容重新设计映射关系和根据路段历史数据分布情况设计路段分配算法两个方面,然后将所有路段数据映射到不同的Region和HRegionServer,解决数据的热点分布问题,同时利用分布式框架的分布式查询机制显著提高查询效率。
3)基于HBase下层的索引结构设计。同一路段中的移动对象数据被存储到同一块Region中,在每个Region中的改进包括两部分:首先是设计 Rowkey键的组成结构,通过Rowkey键高效地组织数据记录的存储顺序;其次是在Region中创建多重索引,提高移动对象数据在Region内的索引效率。
RM-HBase的结构框架如图1所示。
1.2 基于原生HBase的结构改进
1.2.1 上层索引结构设计
为了解决数据热点问题同时提高路网空间对象的查询效率,本文对.META表内部的映射关系进行了改进,同时引入了历史数据计算路段概率的方法对路段到Region进行分配。本小节主要对路段衡量指标和路段分配算法两部分进行介绍。
1)计算路段衡量指标。
本文利用每条路段的历史数据积累情况将路网中的路段分配到不同集群节点的服务器HRegionServer和Region中进行存储,从而确保数据在不同集群节点中的负载均衡,解决集群节点的数据热点问题。路段分配算法根据统计学原理,以查询地区的一周(从周一到周日)数据记录作为分配依据对历史移动对象数据记录数量进行统计,选用一周数据作为分配依据的原因是:根据文献[7]对长期统计数据的研究发现,车流量数据随一周变化出现周期的波动走势。

图1 RM-HBase结构框架Fig.1 Structural framework of RM-HBase

其中:i,j分别表示每条路段的两个顶点标号;pij代表路段vivj所占的比重是本文的目标值;totalij代表路段vivj在上述一周内的移动对象数据总量;N表示查询区域内的路段总数;totalij代表查询区域中一周内的所有路段中产生的移动对象数据总量。
对所有查询地区的所有路段都利用式(1)计算比值pij,最终得到一个由所有路段pij值组成的二维链表。链表节点的数据部分包括两部分:路段编码和路段的衡量指标pij。按照pij从大到小对路段进行排序,其中链表的首节点存储pij值最大的路段信息,最终得到按pij排序的有序链表rlist。下面介绍利用如何利用路段分配算法将路段rlist分配到不同的Region和HRegionServer当中。
2)路段分配算法。
路段分配算法的实现思路是在已知HBase集群节点(即HRegionServer)个数k的情况下,将rlist中的所有路段分成k个子类,使得每个子类中包含的路段对应的概率之和差异最小。路段分配算法主要分为两步进行:第一步是将路段分成k个子类;第二步是将k类中的每条路段根据路段编码分配到不同的Region中。第一步的路段划分算法的主要思想如下:首先设置k个空桶并对桶从0,1,…,k-1编号,将rlist中的元素按照pij值的大小,从大到小循环所有的桶,将路段依次存
本文采用的衡量标准的计算方法如式(1):放到k个桶中。例如:第一次循环将rlist[0] ~ rlist[k-1]依次存放到桶0~k-1中。随后,继续判断k个桶中当前所有路段pij值和的大小情况,确定和最小的一个桶,将下一个值rlist[k]存放到该桶中。算法的结束条件是rlist中的元素循环完毕,最终返回所有路段的分配结果列表bucketlist,该列表中存储的是路段。根据上述分类结果,将k个桶中的路段分别存储到对应的HRegionServer中。路段分配算法的具体执行过程如算法1,算法1中涉及的findminbucket算法执行过程如算法2所示。
算法 1 RoadSegDistribution()。
输入 有序的路段对应概率数组rlist,路段划分的类别个数k;
输出 返回k台服务器存储的路段集合bucketlist。
bucketNum=k; //桶数
buckets=new LinkedList〈int〉(); //创建链表集合
for each bucketNum i do //初始化桶
buckets[i].add(rlist[i].value);//先将 rlist中0,1,…,k - 1元素加入桶中
end for each
bucketsum=0; //记录每个桶的数据和
LinkedList〈LinkedList〈int〉〉bucketlist=newLinkedList
〈LinkedList〈int〉〉(); //存储最终的路段分配结果,此外,//将0~k-1条路段加入bucketlist
for each rlist i do
int min=findminbucket(buckets); //确定和最小的桶
buckets[min]+=rlist[i]; //更新最小值
bucketlist.get(min).add(rlist[i].rid); //加入 bucketlist
end for each
return bucketlist
算法2 findminbucket()。
输入 链表集合buckets;
输出 返回pij和最小的同的索引。
min=MAX; //初始化最小值为MAX
minIndex=0; //初始化最小值下标为0
for each buckets i do
if buckets[i] < min then
min=buckets[i]; //循环每个桶,找到 pij和最小的桶
minIndex=i;
end for each
return minIndex
算法1对路段的分配能够解决集群节点的数据热点问题。
1.2.2 下层索引结构设计
本文针对HRegionServer的内部数据存储结构,在每个HRegionServer中进行了两方面的索引改进,以提高数据在Region内的查询效率。两方面的改进分别是:创建Region索引和设计Rowkey键,下面分别对两部分的改进进行说明。
1)创建Region索引。
本文在HRegionServer的每个Region中分别创建两个索引:时间索引t-index和移动对象索引o-index,分别用于提高时间属性的查询效率和移动对象的查询效率。时间索引t-index创建在时间属性 objectinfo:time上,移动对象索引o-index创建在对象属性objectinfo:oid上。
本文提出的索引是一种多重索引。上层索引相当于主索引,创建在.META表中,通过表中的映射关系确定每条路段的起始存储地址。o-index和t-index相当于附加索引。创建索引时,以移动对象和时间作为次关键码,分别创建两个链式索引用以索引时间和移动对象。图2是对移动对象索引的链表结构,左侧存储次关键码信息和对应关键码的头指针,右侧的链表是将存储有次关键码的记录,按照时间顺序连接在一起;每个链表节点中存储的是该记录的存储地址。t-index结构与o-index的索引结构相类似,此关键码是时间区间,链表头指针指向的是按照时间的先后顺序排列的移动对象记录。在对移动对象进行查询时,首先查询左侧的表,判断移动对象是不是位于当前的块中,如果当前块中包含该移动对象则继续通过对应记录的头指针查找该移动对象的所有记录;如果当前块中不含有待查询的移动对象数据,则将放弃对该块的查询,这种索引的设计能够有效地提高移动对象数据的查询效率。在进行时间查询时,过程与上述过程类似:首先通过此关键码判断候选Region中是否存在待查询的时间区间,如果不存在则放弃在该块内的继续查询,如果存在则通过头指针查询当前时间区间内的链表信息,找到所有满足时间的候选记录集合。
2)设计Rowkey键。
HBase表中的数据基于行键进行存储。在进行Rowkey键设计时要充分拉开不同Rowkey键的差异性。通过设计Rowkey键提高HBase的查询效率,在文献[8]和文献[7]中已经得到了成功的应用。根据HBase表数据按照字典序排序的原则,本文对表中Rowkey键的设计内容如式(2):其中:rid是路段的标识id;T表示移动对象记录的存储时间;oid是移动对象的id。基于以上的Rowkey设计,数据首先按照路段存储,其次按照时间属性进行存储,最后依照移动对象进行存储。


图2 o-index索引结构Fig.2 Index structure of o-index
当查询条件到来时,首先匹配路段rid,如果路段id匹配。系统首先沿当前Region查找当前路段的入口地址,由于数据首先是按照所在的路段进行存储的,因此上述Rowkey设计能够极大地提高路段起始存储地址的定位速度。其次匹配条件中的时间范围,最后再考虑移动对象oid。这种Rowkey设计的优点在于:在每个Region的StoreFile中同一路段的移动对象时空数据被连续存储在一起,查询时只需要确定当前StoreFile的首地址和下一个连续StoreFile的首地址就能够判断当前块中是否存储了所有当前路段,从而直接获取所有的当前路段数据。此外同一条路段的数据,按时间进行连续存储,这种设计方式能够提高索引的创建效率,通过上述Rowkey设计能够快速获取连续时间段的数据集合和满足移动对象条件的记录集合。
1.3 路网索引RN-tree设计
1.3.1 RN-tree结构设计
本文提出的RM-HBase索引框架中包括两层索引机制:上层是RN-tree用于检索待查询对象的空间信息;下层采用链表组成的一维索引o-tree和t-tree索引用于检索时间和对象属性。本小节介绍的正是上层的RN-tree索引的结构,该索引的创建目的是希望通过该索引提高空间路段的查询效率。
通过按路段的路网划分方法解决等大小的空间划分方法出现的“死空间”问题;通过在中间节点中存储范围、叶子节点存储路段的索引设计,在实现范围查询的同时实现对空间的降维[9]。索引的创建包括三个阶段:路网建模、路网划分和RN-tree创建。路网建模是以路段作为最小单位对路网空间进行建模,路网空间最终被转换成图结构,图中顶点代表路段与路段之间的拐点;路网划分是根据图的路段数量对路网空间进行划分,中间节点存储一个空间范围,叶子节点存储路段信息,子路网的划分见1.3.2节;RN-tree是一棵多层次搜索树,叶子节点的存储范围的并集是父节点的存储范围,RN-tree的创建过程见 1.3.3 节。
1.3.2 路网空间划分算法
RN-tree中路网划分的最小单位为路段,将整个空间路网区域根据路段划分成多个子区域[10]。划分过程借鉴G-tree[11]的划分思想:划分过程包括两个参数f和n,参数f表示树的中间节点的孩子节点个数,参数n表示最小子图中包含的最大路段条数。假设当前任意最小子图包含的元素个数为count,则当图的划分满足count≤n时,路网划分过程结束。n在路网划分算法中作为算法的一个输入,该值的大小根据用户的需求由用户进行自定义设置。本文采用改进的Kernighan-Lin算法[12]对路网进行划分。
算法3是路网的划分算法,该算法的思想是将当前路网一分为二。首先对初始状态的路网区域以路段为单位进行随机划分,随后通过不断交换两个子区域中的路段,使得最终两个子图的代价差最小,此时对路网的划分结束。
算法3 RoadNetworkPartition()。
输入 G(V,E),G表示待划分的图,f表示孩子节点数,n表示子图中最大元素个数;
输出 f个划分后的子图graphset,该过程是一个迭代的过程。
graphset=initializeGraph(G,f,n);
//将图G随机划分成两个子图(A1,B1)
do //循环gset中的每个子图中的边界A1=A,B1=B;
//计算每个节点的内部和外部代价g=internalcost+externalcost
for each|V|/2 i do //循环每个子图中的节点
int maxmal=0;
g[i] =d[a[i]] +d[b[i]] - 2*c[a[i]][b[i]];
//计算每个顶点i的权重和
if g[i] > maxmal then
maxmal=g[i];
//找到 g[i]值最大的两个路段 a[i]和 b[i]
end if
a[i]→ B1,b[i]→ A1; //分别交换 a[i]和 b[i]到 B1和 A1
UpdatedValue(graphset,a[i],b[i]);
//更新交换后两个子图的d值
end for each
int k=FindK(g[i])
//找到 g[1],g[2],…,g[k],其中 g[k]是 g[i]中的最大值
if g[k] > 0 then
a[1],a[2],…,a[k] [1],b[2],…,b[k];
end if
return graphset
上述算法是将区域一分为二的划分方法,当需要将区域划分为2n(其中n>1)个子图时,继续采用算法3中的方法进行迭代划分。对路网的划分方法与等空间的划分方法相比,能够有效避免将一条路段切分成多段的情况,为高效的路网空间对象查询奠定了基础。
1.3.3 RN-tree 结构设计
RN-tree是一棵多路径平衡搜索树,树中存在两种节点:中间节点和叶子节点。如图3是f=2,n=4的RN-tree结构示意图。索引中将整个路网空间作为根节点G0。利用1.3.2小节提出的路网划分算法,对路网区域进行划分。例如,首先将根节点G0覆盖的范围被划分成两个子区域G1和G2,根据路段对路网空间继续划分,最终将所有路段划分到索引中的叶子节点当中,下面分别对中间节点和叶子节点的内部结构进行介绍。
中间节点存储两部分数据:孩子子图的子图边界和当前子图的覆盖范围。每个图的子图个数为f,为了记录f个子图两两之间的子图边界信息,通过链表结构存储子图边界数据。链表的数据部分分为两部分:分别存储两个路段顶点的编号和两个顶点的位置信息。编号的存储位置存在前后差别,前部分编号表示当前顶点存储在左侧子图中、后部分编号表示当前顶点位于右侧子图中,其中每条子图边界指向.META表中的一行记录的地址。根据中间节点包含的路段的最小外界矩形的四个顶点确定中间节点在两个平面维度上的范围。

图3 RN-tree索引结构Fig.3 Index structure of RN-tree
叶子节点存储最终的路段数据。叶子节点存储两部分信息:路段的空间范围和路段的顶点信息。利用两个顶点vi(x1,y1),vj(x2,y2)的位置信息,确定路段的空间范围。当子路网中的路段数满足count≤n时,路网划分过程停止,叶子节点中的元素来自当前子路网中的路段元素。每个叶子节点存储一个路段,该叶子节点中存储该路段的最小外接矩形的对角线信息,也就是该路段的顶点信息。最终,每个叶子节点指向.META表中的一行记录,该记录就是路段到Region及HRegionServer的映射信息。
RN-tree创建在空间路网数据上,RN-tree存储在HMaster的内存当中。在进行时空查询时,系统首先通过RN-tree确定查询条件中的空间范围路段集合rset,根据索引的查询结果确定HMaster中的.META表定位该路段中数据的存储位置;其次通过.META表的映射关系确定当前路段中的移动对象存储的Region和HRegionServer信息,利用Region内的时间索引和对象索引进一步提高筛选对象和时间信息的效率;最终利用数据记录的空间信息pos_x和pos_x,精确定位移动对象的记录。由于RN-tree的中间节点存储了范围信息,叶子节点存储的是对应的路段,在查询的最后通过RN-tree将多维的范围信息转换成了一维的路段编码,因此与STEHIX相比,RN-tree相当于代替了四叉树和Hilbert曲线两部分的功能,能够同时实现空间对象查询和空间降维工作。
2 路网时空查询算法
2.1 时空范围查询
1)查询类型定义。
路网中的时空范围查询主要有两种类型:基于范围覆盖的查询和基于路径覆盖的查询。基于范围覆盖的查询指查询范围是一个矩形区域或者圆形区域,基于路径覆盖的范围查询指查询范围是多条完整的路段。本文首先介绍基于范围覆盖的查询,基于范围覆盖的查询定义如下:
定义1 给定路网G(V,E),查询条件包括矩形覆盖范围([x1,x2],[y1,y2]) 和时间区间[ts,te]两部分。查询结束后返回在时间区间[ts,te]内经过区域([x1,x2],[y1,y2]) 的所有移动对象记录。
2)查询算法实现。
基于范围覆盖的查询算法的查询过程包括三个子过程:可以简要概括为“空间 时间 空间”。第一个“空间”是利用RN-tree索引当前查询范围覆盖的所有路段,这个过程是一个空间的模糊查询过程;“时间”是利用RM-HBase下层的时间索引t-index选出满足查询时间区间的记录,第二个“空间”是利用HBase的字典序排序特点和Rowkey键的设计,对候选集内的记录再次进行空间位置筛选。
基于范围覆盖的范围查询算法实现过程如算法4所示。
算法4 RangeQuery()。
输入 范围查询区间([x1,x2],[y1,y2]),时间区间[t1,
t2];
输出 符合查询条件的移动对象集合。
rset=searchRoadTree(RR,x1,y1,x2,y2);//查找RN-tree确定查询范围内的所有路段,//其中RR是RN-tree的根节点
rslist=getMetaTable(rset);
//定位路段对应的Region和HRegionServer地址
Map(roadID,HRegionServer,rlist);
//利用MapReduce将候选集中的路段查询任务分配到
//对应的HRegionServer和Region中并行执行
for each rslist.HRegionServer do //所有 HRegionServer并行运行
startRowkey=getThisRowkey(rslist.roadID)
//获取每个路段的起始存储地址
endRowkey=getNextRowkey(rslist.roadID)
//查询下一路段的起始地址Rowkey
scan.setStartRow(startRowkey);
scan.setStopRow(endRowkey);
//利用scan函数得到当前路段的候选集合
for each scan.result do
if t1≤ r.getTimeStemp≤ t2
&& r.pos∈ (x1,y1,x2,y2)then
molist.Add(r);
end if
end for each
end for each
olist=ReduceRecord(roadID,molist);
//利用Reduce将不同服务器的结果合并
return olist //返回满足条件的移动对象
基于路径覆盖的查询的查询过程比基于范围覆盖的查询更简洁。查询过程分为路段查询和时间查询两部分:首先通过HMaster中的RN-tree索引查询该范围内的路段,通过.META表确定存储了待查询路段的Region及HRegionServer;然后在Region中利用内部时间索引t-index索引确定满足时间条件的记录。
2.2 时空范围查询
1)查询类型定义。
空间中的KNN查询主要包括两类:静态空间的KNN查询和动态时空的KNN查询。本文主要解决动态时空数据的KNN查询问题,该查询需要同时考虑时间和空间维度,本文所述的时空KNN查询中查询点和被查询点都位于路网的路段当中,具体的查询定义如下:
定义2 给定路网G(V,E),查询条件包括三部分:查询的点坐标 p(x,y)、待查询对象数量k和时间区间[ts,te]。查询最后返回在时间区间[ts,te]内出现的距离点p最近的k个移动对象记录。
2)查询算法实现。
路网环境中的时空KNN[14]查询是一个递归的查询过程:第一次首先查询点p所在的路段,随后查询该路段中距离p点最近的k个对象记录;第二次查询与该路段查相邻的路段中的移动对象记录;直到新的路段中距离p点最近的点的距离dist(p,ox)要大于候选集合中的最远距离distmax,此时对于该路段及其后续路段的查询结束,查询过程直至所有路段的查询都结束。其中 dist利用欧氏距离:dist(p,px) =计算得到,ox代表未知查询点。
本文提出的时空KNN查询算法的伪代码描述如算法5。
算法5 KNNQuery()。
输入 查询点p,时间区间[t1,t2]和k;
输出 符合查询条件的移动对象集合。
rset=getRoadRRTree(q) //确定q的所在路段,RR为根节点
molist=getMovingObject(rset,t1,t2);
//找到路段中的所有移动对象
if molist.lenght > k then
molist=chooseKObject(q,molist);
//选择距离q最近的k个移动对象重新赋值
end if
distmax=getMaxDis(molist);
vlist← {r.vi,r.vj}; //相关边的顶点列表
return RecursQuery(vlist,molist,distmax);
路网时空KNN查询的向外扩展可以采用递归调用算法6是递归查询过程的具体实现。
算法6 RecursQuery()。
输入 顶点集合vlist,移动个对象候选集molist,最大距离distmax;
输出 符合条件的移动对象。
if vlist==null then
return molist;
end if
v=vlist.dequeue(); //相关顶点出栈
rset=FindEdgeOfV(v); //找到与v相关的所有路段
for each rset.r in elist do
distmin=getMinDis(q,r); //当前路段中距离q的最短距离
if distmax≥distmin then
list← getMovingObject(r,t1,t2);
molist=list+molist;
if molist.length > k then
molist=chooseKObject(q,molist);
end if
vlist.enqueue(edge.vj); //将边的另一个顶点加入队列
end if
end for each
distmax=getMaxDis(molist);
return RecursQuery(vlist,molist,distmax);
2.3 移动对象轨迹查询
1)查询类型定义。
移动对象轨迹查询[15],顾名思义其查询过程中需要同时考虑查询的时间属性和空间属性两个方面。移动对象在路网中运动,因此其运动轨迹必然是沿着路网中的路段,具体查询定义如下:
定义3 给定路网G(V,E),查询条件包括两部分内容:查询对象标识o和查询时间区间[ts,te]。最后返回在时间区间[ts,te]内移动对象o的运动轨迹。
2)查询算法实现。
由于查询条件中只给出了移动对象的标识信息,因此无法预先确定移动对象经过的位置信息。查询条件中不包含空间位置,因此不需要RN-tree索引的参与。该查询过程可以概括为三个子过程:“全路段 移动对象 时间”。其中“全路段”查询是利用.META表的映射向所有的路段发送查询;“移动对象”查询是利用Region中的移动对象索引o-index查询移动对象的记录;“时间”查询则是利用o-index中的按时间顺序排列的链表结构,确定满足时间条件的记录集合。
本文提出的移动对象轨迹查询算法的伪代码描述算法7。
算法7 TrajectoryQuery()。
输入 移动对象o,时间区间[t1,t2];
输出 按时间排序的移动对象位置坐标tjlist。
roadlist=getTotalRoadSegmet(); //得到所有路段的id
for each roadlist.roadID do
roadID→HRegionServer;//映射到不同的HRegionServer,并行查询
end for each
for each roadID in HRegionServer do
//循环每个HRegionServer中的路段
sRowkey=getStartRowkey(roadID);
eRowkey=getEndRowkey(roadID);
for each Rowkey∈[sRowkey,eRowkey]do
if Rowkey.oId==o && t1≤ Rowkey.time≤ t2then
keylist.Add(Rowkey);
end if
end for each
end for each
tjlist.Add(getObjectResult(keylist));
return InsertSort(tjlist); //进行排序
3 实验与结果分析
3.1 索引框架的性能分析
3.1.1 实验环境
本文实验基于HBase分布式数据库平台,因为HBase部署在Hadoop集群上层,因此实验环境首先需要部署Hadoop集群环境。实验环境包括两部分:硬件环境和软件环境。
硬件环境:本文采用阿里云的租赁式服务器ECS进行实验,实验采用的Hadoop集群节点数为5,其中1个节点配置为NameNode,4个节点配置为DataNode(其中NameNode设置为 HBase的 HMaster,DataNode设置为 HBase的 4个HRegionServer)。
软件环境:开发环境为Myeclipse2014;开发操作系统为Windows 10;Hadoop 版本为2.5;HBase版本为1.2。
实验方案:本文的实验数据通过BerlinMod Benchmark[13]来生成。为了区分不同时间段的数据量,本文在生成实验数据时,将移动对象的运动轨迹按照工作日和双休日进行规划,根据路段对数据进行不均匀的分配。实验中生成了2 000个移动对象的运动轨迹,并对每个移动对象的运动轨迹按如下的方式进行设计:在工作日设置家和工作点作为运动轨迹的起始位置;双休日的运动轨迹随机生成。关于数据量的增长问题,先生成1 GB数据,若实验中对数据的需求量大于1 GB,则采用复制的方式增加数据量。
3.1.2 实验:集群的数据分配
本文在设计RM-HBase索引框架时,将路段映射到不同的HRegionServer和Region中,当该路段中产生了路网移动对象时空数据时,数据被存储到该路段映射的Region中。其中,本文对“路段——Region”的映射关系是利用每条路段的历史数据量分布情况产生。这种分配算法能够有效地解决Hadoop分布式集群节点的数据热点问题,图4是在一次实验中100 GB数据在不同节点上的分布情况,将上述数据分别利用STEHIX和RM-HBase在DataNode集群节点中进行存储。图4中的对比实验结果显示:在RM-HBase的不同节点中,数据分配表现出均衡的特性,STEHIX索引框架的数据分布则不是很均衡。

图4 不同集群节点的数据量Fig.4 Data amount of different cluster nodes
由于实验不具有普遍性,为了检验RM-HBase索引框架在解决数据热点问题中表现出的普遍性性能优势。接下来本文进一步对上述结果进行分析,选用标准差作为数据指标,用于表现集群中不同节点之间的数据量差异。式(3)给出了标准差的计算方法:

其中:N代表集群的节点数量;μ表示集群中数据的均值;xi表示节点i中数据的存储量。
标准差随着数据量从40 GB到320 GB相应的变化情况如图5所示。从图5中能够明显看出,随着集群中存储的数据量的增加,STEHIX索引框架中集群节点数据量的标准差都大于10 GB,这一数值说明在STEHIX的分布式集群节点中,数据的分配是不均衡的;而RM-HBase索引框架中集群节点数据量的标准差都小于2.5 GB,这一数值表明数据在RM-HBase索引框架的分布式集群的节点中,数据分布是均衡的,不会出现数据热点问题。

图5 集群节点的数据分配Fig.5 Data allocation of cluster nodes
出现上述数据分布现象的原因可以通过RM-HBase索引框架中路段分配算法加以解释:由于路网环境中移动对象只在路段中运动且路段之间的数据量存在较大差异。若采用等大小的矩形区域划分方法创建索引,则单位时间内每个子区域中产生的数据量存在巨大差异,从而造成集群的每个节点中的数据量参差不齐,继而引起集群节点中的数据热点分布问题。而由于RM-HBase索引框架利用不同路段的历史数据量将路段均匀映射到不同的服务器中进行存储,从而有效避免了数据热点问题的发生。
3.2 算法的性能分析
针对三种时空查询算法的性能分析,本文实验部分选用的对比对象是 STEHIX索引框架,实验的具体配置与RM-HBase索引框架的实验相同,本小节主要介绍算法实验的数据来源和数据生成过程,然后依次对时空范围查询、时空KNN查询和移动对象轨迹查询的算法性能实验结果进行分析。
3.2.1 实验数据
本文实验数据利用MinnesotaTG项目对外提供的数据生成接口,用户能够对路网区域、生成的移动对象数量、移动对象的运动轨迹、生成时间进行自定义。路网选取美国Colorado区域的交通网络;车辆时空数据则是利用BerlinMod Benchmark[13]测试集来动态生成。
实验选择的区域覆盖了1057066个路段,数据模拟周期为7 d,每分钟记录一条位置信息,初始移动对象为2 000个,通过复制已获得数据集的方式获取更多数据。
3.2.2 实验一:时空范围查询
时空范围查询实验分别包括查询窗口大小和数据量对范围查询耗时的影响。图6显示了随着查询窗口大小变化,时空范围查询耗时的变化情况。实验固定时间维度,依次选取1×1、2×2、3×3、4×4、5×5、6×6矩形查询窗口,查询2 h的移动对象数据记录。实验结果表明:随着查询窗口的扩大,STEHIX和RM-HBase的时空范围查询耗时都在不断地增加,但是STEHIX索引框架的查询时间增加速度要明显高于RMHBase索引框架。产生这种现象的原因在于:RM-HBase中的RN-tree索引能够提高路段数据的查询效率,同时根据RN-tree中的路段分配算法,相邻的路段可能被分配到不同的HRegionServer中存储,因此在进行范围查询时不同HRegionServer的路段能够进行并行查询,同时;在Region内对Rowkey键值的结构进行了改进,能进一步提高移动对象的查询效率。此外,RM-HBase在Region中创建了高效的时间索引t-index,该索引能够高效地筛选时间区间。

图6 查询窗口对范围查询性能的影响Fig.6 Effect of query window on range query performance
图7 是随着移动对象数据量的增加范围查询的耗时变化情况。实验设定查询窗口大小为6×6,其中分布式集群的数据量变化区间为40 GB~320 GB。从图7中能够明显看出:随着数据量的增加,两种索引框架的范围查询耗时也在不断地增加。但是与STEHIX相比,RM-HBase索引框架的耗时存在明显的性能较低情况。此外,随着数据量的增加RM-HBase的范围查询耗时增速越来越缓慢。出现上述现象的原因:随着移动对象数据的不断增加,Region块内的时间索引也需要不断进行更新操作,因此查询耗时随之增加。
图8显示了随着集群节点变化,时空范围查询的耗时变化情况。实验设定查询窗口大小为6×6,数据量为320 GB,其中分布式集群节点数量变化区间为1~10。从图8中能够明显看出:随着集群节点数量的增加,两种索引框架的范围查询耗时也在不断地减少,且RM-HBase的查询效率明显优于STEHIX,但是RM-HBase的查询耗时降幅越来越缓慢。出现上述现象的原因:随着集群节点的数量不断增加,通过下层索引检索最终结果的耗时情况会趋向稳定。时空KNN查询与轨迹查询的实验现象与此实验一致,因此后面不再介绍。
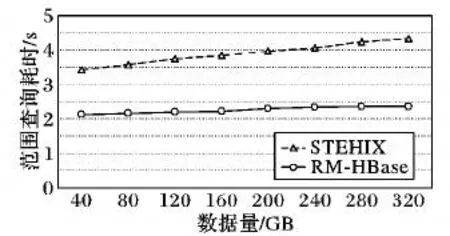
图7 数据量对范围查询性能的影响Fig.7 Effect of data amount on range query performance
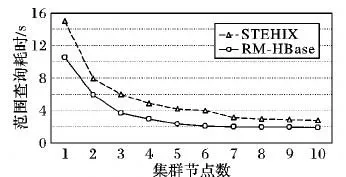
图8 集群节点数量对范围查询性能的影响Fig.8 Effect of number of cluster nodes on range query performance
造成上述索引差异的原因是:RM-HBase对HBase进行了全面的改进,首先通过RN-tree,明显缩小了范围查询的区域,使得每次的查询过程都是有效的,避免“死空间”问题的出现,从而提高了路段对象的查询效率;其次通过Rowkey键的设计,数据按照“路段 时间 移动对象”的字典序进行数据连续存储。因此在确定了查询区间范围后,能够快速地定位该范围内的所有移动对象记录;而STEHIX只是按照矩形空间对数据进行存储,在每个Region内数据的存储是无序的,因此查询性能受到影响。
3.2.3 实验二:时空KNN查询
该部分实验分为两组实验:第一组实验测试随着k值的变化KNN查询的耗时变化情况;第二组实验测试随着移动对象数据量的变化KNN查询耗时的变化情况。
随着查询中k值变化时空KNN查询的耗时变化结果如图9所示。实验设置整个查询区域中初始移动对象数量为2000,其中 k 值依次取 4、8、16、32、64。通过实验结果可以得出:随着k值的增加,两种索引框架的耗时也是不断增加的,但是RM-HBase的耗时增加速率要低于STEHIX索引框架;在相同k值的查询中,STEHIX索引框架的查询耗时明显大于RM-HBase索引框架。这说明:随着k值的增加,RM-HBase索引框架的时空KNN查询性能明显优于同等条件下的STEHIX索引框架。
出现上述性能差异的原因是由于:RM-HBase索引在进行KNN查询时,首先利用RN-tree通过路段与路段间的连接关系快速定位移动对象所在的路段,能够高效地对空间查询范围进行剪枝;其次,根据当前路段的顶点再进行扩展路段的查询,在Region内则通过时间索引t-index提高时间维度的查询效率并利用本文的Rowkey设计能提高目标记录的查询速度。而STEHIX索引框架在进行KNN查询时,对空间路段的查询是盲目的,它是通过查询与查询点相邻的所有子区域找到所有的查询结果,因此查询效率较低。
图10是随着数据量的不断增加,KNN查询的耗时变化情况。实验中设定查询条件k=3,移动对象的数据量变化范围为40 GB~320 GB。实验结果同样显示:随着数据量的不断增加,RM-HBase索引框架的时空KNN查询中具有突出的性能优势。出现上述性能差异的原因是:随数据量的增加,RM-HBase通过RN-tree能够有效减少需要路段的查询范围,实现对查询范围的快速剪枝。空间路段查询结束后,RM-HBase利用链式时间索引t-index筛选满足时间区间的对象记录。由于本文在Rowkey设计时充分考虑了数据的字典序连续存储问题,因此时间的查询效率能够得到有效的提高。STEHIX索引框架没有考虑路网环境的特点,因此在KNN查询时,需要连续查询多个连续的数据区域,每次的扩展查询都是需要查询四个方向的数据区域,而RM-HBase改变了这种查询局面,只需要查询与现有空间相连的路段,同时能够避免KNN查询的不完全性。

图9 k值变化对KNN查询性能的影响Fig.9 Effect of k value change on KNN query performance

图10 数据量对KNN查询性能的影响Fig.10 Effect of data amount on KNN query performance
3.2.4 实验三:移动对象轨迹查询
本文提出的RM-Hbase除了能够支持时空范围查询和时空KNN查询外,该索引框架还能高效地支持移动对象轨迹查询。查询条件包括移动对象和时间区间,该部分实验主要测试随着移动对象数量变化,轨迹查询的响应耗时情况。
随着数据量的不断增加,查询一个移动对象在2 h内运动轨迹的查询耗时情况如图11所示。实验结果显示:RMHBase索引框架的查询性能要明显优于STEHIX。两种索引框架与非分布式相比在轨迹查询时效率都能表现出明显的增加,这是由于分布式集群的固有优势而确定的。出现上述现象的原因包括两方面:首先RM-HBase在Region内增加了移动对象索引o-index,能够高效地确定移动对象是否位于当前Region以及移动对象的存储位置;其次RM-HBase重新设计了Rowkey键的结构,这也进一步提高了移动对象和时间区间的检索效率;更重要的是,RM-HBase的o-index结构中包括移动对象记录单链表,单链表按照时间排序,因此在找到移动对象记录后,能够通过其后面的链表首地址找到当前Region中所有的满足移动对象和时间条件的记录。STEHIX在移动对象查询时由于没有提供移动对象索引,因此需要查询所有的Region,此外通过t-index找到所有满足时间区间条件的记录,最后需要从大量的满足时间的数据中筛选移动对象信息。

图11 数据量对轨迹查询性能的影响Fig.11 Effect of data amount on trajectory query performance
4 结语
RM-HBase是针对Hadoop子项目HBase的索引结构改进而提出的索引框架,主要用以解决海量路网移动对象数据的高效时空索引问题。本文通过对原生HBase索引框架的上下层重新设计,有效地解决了路网空间移动对象的查询过程中的“死空间”和路段分配中的集群数据热点问题,同时设计了针对RM-HBase框架的相关查询算法。实验结果表明RMHBase框架相对于STEHIX框架在路网环境下移动对象有时空检索效率的提升;然而本文中路网划分方法的计算代价较大且由于RN-tree索引节点中存储了大量的数据,需要占用更大的索引存储空间,因此进一步的研究方向是如何提高路网空间的划分效率。
