基于智能分类算法的数据质量检测
2018-08-23
(广东警官学院 网络信息中心,广东 广州 510230)
为了进行大数据分析,存储的数据首先要是有效的。计算机的普及带动了各行各业信息化的飞速发展,这也使得电子数据变得非常普遍,特别是随着当今大数据和人工智能的迅速崛起,大到国家层面、小至个人用户,都越来越关心数据存储问题。随着数据量的不断增大,数据所包含的经纬信息也越来越复杂,导致了系统之间的信息孤立现象越来越明显,在一定程度上影响了数据的有效利用[1]。
面对复杂的信息流,数据很多时候是不完整的,甚至本身就是有质量问题的,因此,想要得到更加有价值的信息,提高数据源的可用性和多样性,数据中心和业务系统的数据质量就成为了非常重要的因素,数据检测环节变得不可忽视。基于此,本文中通过智能分类算法构建数据质量检测方法,对进入数据中心的数据进行检测分析及规划后期的数据处理问题[2]。
1 检测模型设计
建立数据质量检测方法模型的主要思路是,通过提取数据特征值,对数据进行归类,从而对数据进行处理。图1中给出了改进后的数据质量检测模型,包括特征值提取、智能分类和后续流程的设计[3]。
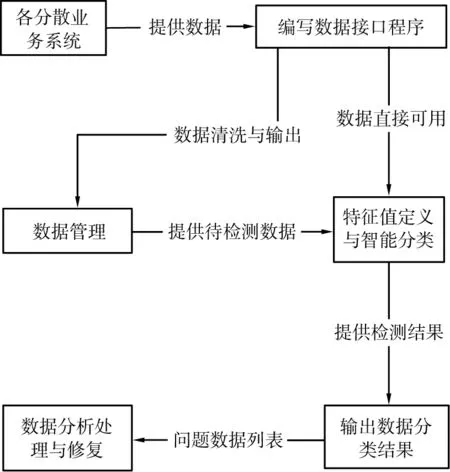
图1 数据质量检测模型
数据质量检测模型包含数据采集、数据清洗、数据特征的定义、数据分类算法和数据的分析及处理。
数据采集是指建设程序接口,从不同的业务系统中将分散的业务数据引流到数据中心来集中存储,形成业务大数据。
数据清洗是针对引流到数据中心的各个模块数据存储前的预操作,通过编制筛选算法及人工干预,去除掉脏数据和不需要的数据。
数据特征的定义也即提取特征值,是对数据采集与清洗之后深入了解数据的属性,掌握关键数据的含义、来源、存储方式[4]。
基于智能分类算法的数据检测是指根据事先制定的算法对数据的检测和分类。
数据的分析及处理是对分类后的数据的进一步处理,包括对数据准确性、一致性以及完整性进行评估,由数据管理人员对数据进行更正、修复,满足用户需求[5]。
2 基于智能算法的数据检测
2.1 数据源管理
数据源信息结构如表1所示。该表的作用是处理数据源信息并保存相关的信息,以便于用户查阅和分类算法的调用。由于数据具有多重信息且需要被存储起来,而数据库的信息基本由此来提供,因此,用户在操作时可以方便地获取数据源的基本信息[6]。在该信息结构表中,PROPERTY_NAME指的是每一种元数据属性,由上述分析可知,每一种数据源的PROPERTY_NAME会有多个,其对应的成员信息如下:

表1 数据源信息结构表
public class PropertyName initialize{
private String ip;//数据库连接的ip地址;
private String pmt;//数据库连接的端口信息;
private String dbName;//连接的数据库名称;
private String sch;//连接的模式名称;
private String dri;//数据库驱动信息;
private String usename;//登录数据库的用户名;
private String psw;//登录数据库的密码;
private String initPolSize;//数据库初始化连接数;
private String minPolSize;//数据库最小连接数;
private String maxPolSize;//数据库最大连接数;
private String waitConTime;//连接等待时间;
private String parClass;//解析类;
private String testSql;//测试数据库链接的SQL语句
}
2.2 数据特征值定义
本文中通过数据库、数据表和业务场景描述这3个纬度来对数据质量的特点进行详细表述,并举例分析。
数据库:收集各个业务系统的所有数据库及数据库的用途信息。在程序中定义2列,即数据库名和数据库描述。
数据表:收集各个数据库的所有业务表及其用途信息,在程序中也相应的定义3列,即数据表名、数据表描述和主要字段信息。
业务场景:对关系数据库和数据而言,通过数据库名及备注及具体业务表的表名和备注,还不能完整的模拟数据的分类属性,因此需要进一步定义数据的场景信息来描述数据的完整性信息。
本文中将参照数据库、数据库表、业务场景的各类信息提取特征值,构造15维度的特征向量,然后对数据通过式(1)进行特征值标准化操作。
(1)
式中:x、y分别为特征向量X和被标准化后的特征向量Y的元素;xmax、xmin为特征向量X的最大值和最小值;ymax、ymin为被标准化后的特征向量Y最大值和最小值。
2.2.1 相对率
经过对特征值的演算变换,对于提取的数据特征值通过式(2)计算数据的相对率,
(2)
式中:Ps为功率;f指对该数据进行快速傅里叶变换。
2.2.2 相对比率
计算数据在整个使用周期中的相对比率非常重要。相对比率采用式(3)进行计算,
(3)
式中:Pr指比率;i、j分别代表数据使用周期的开始与结束。
2.2.3 平均比率
计算数据在使用周期内的平均比率Sf为
(4)
2.3 数据检测的智能分类算法
数据质量检测可通过不同算法实现,以便更好地去发现数据中存在的错误、纰漏等相关问题。目前有很多不同的检测模式可以对数据进行检测,一种是数据挖掘的利用统计学方法进行检测,另一种则是设计质量约束规则对数据进行检测。数据挖掘方法属于自动化操作,虽然目前计算机对于数据中包含的专业术语、场景信息等相关数据还存在很多无法理解并模拟的瓶颈问题,导致其检测范围有一定的局限性,必须根据具体问题来调整分类特征值和支持向量机(SVM)算法的核函数,但是人工智能技术是大势所趋,这并不影响该方法的普及,为此本文中选择第1种方法进行实验。
对于数据中心来说,数据量十分庞大,数据质量规则也很复杂,要想将这些规则进行有效的组织和存储是非常困难的。综合已有文献及人工智能技术的发展趋势,采用智能分类算法是较为可行的途径,数据检测的智能分类算法流程如图2所示。

图2 智能分类算法流程图
该算法将模糊SVM算法扩展到多核模糊SVM算法,以获得较好的执行效果,但是,这些基于核的数据分类算法最关键的步骤是尽可能地组合和选择最好的核函数,而这一步通常受到数据先验知识和期望挖掘模式的严重影响,目前尚未找到寻找最优核的特定方法[7]。选择合适的核函数是核算法成功的关键,而从一个预定义的组中选择一个单一核函数是不足以代表数据检测数据中一个样本具有2个或多个类别的特性的。于是,近年来流行采用多核学习方法来替代固定的单核并取得较好的效果,应用范围也很广。
本文中将多核学习应用到模糊SVM中,并提出基于多核的模糊SVM算法,它能够寻找最优隶属度并可同时优化一组核函数组合的非负的权值数组。文中还将在数据检测分类过程中嵌入特征权重计算,选择不同的数据特征以产生不同的相似度量(由不同核函数一一对应的)。多核模糊SVM算法容易执行,对于数据类间存在明显重叠的特性具有较好的分类效果。本文中根据文献报道的传统SVM算法,派生出多核模糊SVM算法,之后将讨论实验结果,并进行总结。
核函数通常用于解决无效特征及相似度量问题。样本特性实效主要有2个方面原因:一是数据关系呈现非线性关系,通过核函数能把相似的数据定义到一个更为合适的空间,从而获得更好的模型;另一方面,选取的特征向量未必能够真实反映数据的固有特性,由此计算得到的相似度并不能反映数据之间真正的相似度。
构建多核函数集合有多种途径,根据上面所提及的2个问题,通常采用2种方法来构建。第1种方法:给定一组代表样本特性的数据向量,可以在Hilbert空间内采用一些可再生的核函数进行多核构建。例如,可以通过不同的核函数将样本数据映射到不同的非线性空间并在这些空间下进行数据相似度的计算。第2种方法:给定一组原始样本数据,可以提取不同类型的特征向量。例如,给定一组卫星图像集合,可以提取到颜色、纹理等不同类型的特征。在组合数据实验中,为了便于分析,可采取每一维作为一个特征,这样可以直观解释实验结果。
对核的选择原则一般是采用那些已经被证明是有效的核(特征)。比如,rbf核已被证明对许多分类问题有效,而poly核是一种流行的、有效特征识别的映射,被应用于图像识别当中。一般地,核(特征)选择越多,执行效果会越好,但是执行效果同样要受到计算资源和算法对不良核的敏感性等因素的限制。
一般来说,SVM算法决策树只能对应于某一组特定的函数集合,而不能是混合的函数集合。
数据检测中,组合多核函数的模糊SVM算法,其决策树和算法调整为
(5)

(6)
引理1 Mercer核的非负线性组合仍为Mercer核。
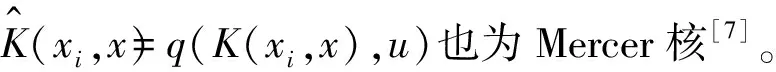
以定理2为理论逻辑基础,可以利用现有常用poly、rbf、erbf核函数构造新的模糊多核核函数,使其能够适用于数据样本集的训练学习[7]。
多核模糊SVM算法数据分类检测步骤如下:
1)将特征矩阵里的数据进行归一化处理。
2)按照式(5)建立分类数据的模糊集。
3)根据式(5)、(6)确定数据样本点模糊隶属度。
4)选择不同的核函数进行组合。
5)根据SVM算法的决策树,运用数据对多核模糊SVM算法进行训练,然后进行样本测试。在xml文件中,采用定义的规则来标记每一条数据的检测情况,对于关系数据库来说,它是一个表名或视图名;对于多维数据库来说,它可能是一个数据立方体名。
3 系统实现与分析
3.1 数据矩阵构造
实验采用c均值聚类和密度法相结合的双隶属法来确定分类样本的隶属度。根据样本点到类中心的距离,实验分别采用不同的计算方法,以设计智能分类算法的分类器逻辑。
第1种:类中心附近的样本点的计算,
(7)
式中:yi∈{-1, 1},yi=-1是负类,yi=1是正类;γ>0,为可调参数;R+为正有理数,R-为负有理数;D为样本函数,0+表示从大于0的一侧趋于0,0-表示从小于0的一侧趋于0。
第2种:远离类中心的样本点的计算,
(8)
式中: 0<η≤1,θ>0,为可调参数;ρ+为样本点的同类点密度,ρ-为样本点的异类点密度。
3.2 数据检测结果与系统测试
平均准确率定义为识别正确的样本数目与总样本数目的比值。数据检测准确率MSSRR计算公式为
(9)
式中:Ci为各子类正确分类数目;Etot为样本总数。
本文中使用到的样本均搜集自真实数据中心应用环境,其中正确数据1 500个,错误数据1 500个。
根据训练数据集得到的用于测试的智能分类算法,经过训练,算法中linear、poly、rbf、erbf等4个核函数的权值及参数值列于表2。分类结果与Kappa系数列于表3。

表2 采用数据集训练得到的分类算法参数
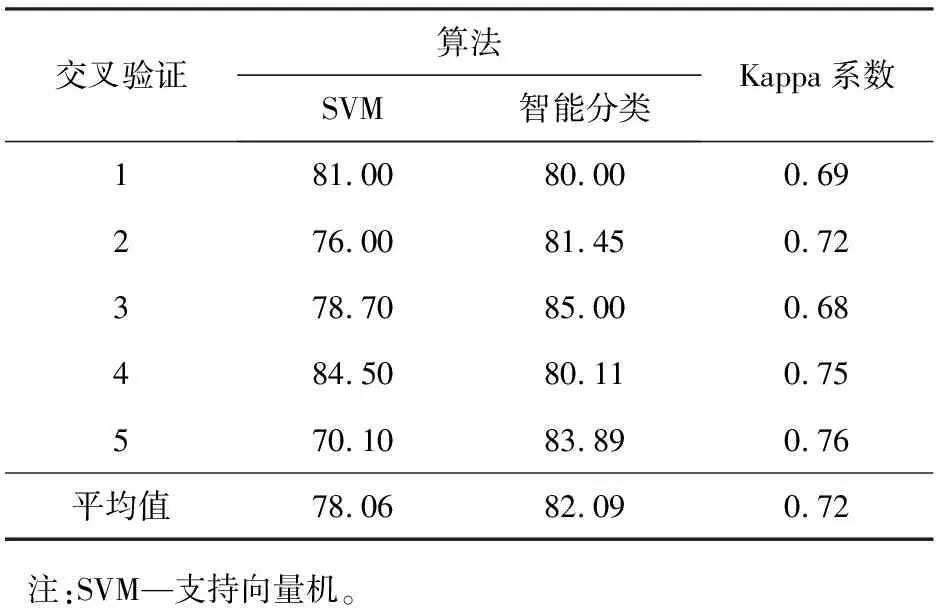
表3 分类结果与Kappa系数
经过对多核模糊SVM算法进行训练和测试,试验平均分类准确率可以达到82.09%。
以下将对设计的数据质量检测系统进行测试,验证是否满足预定目标。本文中的智能分类算法的模拟测试系统是基于B/S结构而开发的,采用HTTP/HTML的协议访问方式,同时采用Load Runner工具对该系统进行大用户量负载模拟测试。 为了对模拟算法系统进行清晰的实验分析,本文中的测试选择单一任务作为测试对象,即设计一个独立场景,验证不同访问方式下系统的表现。 表4所示为设计的独立场景的实验情况。
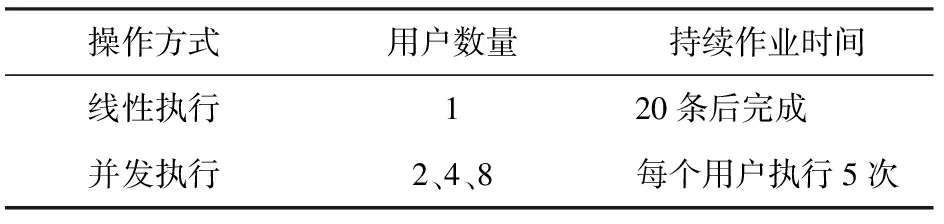
表4 独立场景
在单一场景中,对于顺序执行测试,算法运行全部成功,平均响应时间为218 s;对于并发执行测试,算法同样全部运行成功,平均响应时间是319 s。
4 结语
本文中虽然对数据检测的一些问题进行了研究,但是,针对业务数据量庞大及数据来源丰富的情况,在处理这些数据时需要综合考虑多方面的因素,才能制定不同的检测算法细节。此外,对于不同的数据中心,具体业务情况不同,其数据的特点又会有很大不同,因此需要更加充分地运用统计工具,结合数据挖掘的理论,有效提高数据识别的效率,以满足人工智能趋势下数据检测和大数据管理的需求。
