基于非相似原理快速查找多个shapelets
2018-08-20韦庆锋何国良
韦庆锋,何国良
WEI Qingfeng,HE Guoliang
武汉大学 软件工程国家重点实验室,武汉 430072
State Key Lab of Software Engineering,Wuhan University,Wuhan 430072,China
1 引言
时间序列shapelets是时间序列中能够最大限度地表示一个类别的子序列,是时间序列局部特征的表示,由Ye等人[1]所提出。shapelets算法采用时间序列局部片段进行分类,很大程度上避免了噪声的影响,更加精确和健壮,同时,shapelets分类可以产生具有较高说明性的结果,能够很明确地显示出类别之间的差异之处,指明为什么一个特定的对象被分配到一个特定的类中,帮助研究人员更好地理解数据。shapelets已经作为时间序列领域一个重要的研究主题,受到了越来越多的关注[2-5],还被应用到了医疗服务[6]、运动检测[7]、电力需求分析[8]、聚类研究[9]等领域。
最早提出的基于shapelets分类是在查找出shapelets基础上通过构建决策树的方法来完成的,因此查找出shapelets的好坏决定了分类的效果。原始查找shapelets的方法要产生所有可能的候选集,然后依次计算它们的信息增益,找出最大的一个。它的时间复杂度为O(N2m4),N为数据集中时间序列的个数,m为时间序列的长度,由此可见计算shapelets所需的时间是非常大的,这成为它被广泛应用的最大障碍。尤其是随着科技的进步,越来越多的领域都需要对以往产生的大量时间数据进行分析挖掘,有些数据不仅仅是单变量的,更多是多个变量相互作用、共同发展,如股票数据、气象数据、多传感器产生的运动数据等。已有的查找shapelets方法由于时间复杂度太高,已经不能适应当今数据挖掘的需求,迫切需要一种既能保持shapelets特性,又能缩短计算时间的方法。
本文提出了一种新的查找shapelets的方法(NSDS):基于shapelets非相似的特性,根据子序列间距离分布设置一个距离阈值,从而过滤掉候选集中大部分相似子序列。再改变原始方法中计算耗时的信息增益为更加快捷的类可分离性计算,作为评价候选子序列的指标,最后得到得分靠前的多个子序列作为最终选择出的shapelets。通过实验表明,该方法在单变量时间序列数据集上查找出的shapelets的分类精度与已有方法相比有所提高,时间也得到了极大的缩减。NSDS方法扩展到多变量时间序列数据集后依然取得了不错的效果。
2 相关研究
自从shapelets方法提出,针对shapelets分类的加速提取研究是大多数研究者所关注的领域,下面主要介绍国内外学者的相关研究。
文献[1]中采用了提前停止距离计算和熵剪枝的加速方法,这两种方法虽然简单但是很高效,尤其是第一种方法,因为原始查找shapelets框架中共产生Nm2个候选子序列,每个候选子序列都需要计算与所有时间序列间的距离。若能减少距离的计算时间则可以大大提高整体算法的运行速度。
文献[2]中使用了符号聚合近似(Symbolic Aggregate Approximation,SAX)对原始时间序列进行维度约减,将原始数据离散化表示为字符串。在此基础上随机遮盖部分字符串统计剩下部分的相似性,结合类别号对区别能力进行打分,经过多次遮盖后选取得分靠前的候选者,再进行后续的信息增益计算得到分类性能最好的子序列。
文献[3]中利用了三角不等性[10]加速了子序列和时间序列间距离计算过程,主要是利用了以下数学原理:两边之差小于第三边。具体来说先设置一个基准子序列O,然后计算两个子序列A、B到O的距离之差作为距离下界dlb,A、B之间的实际距离一定是大于等于dlb的,当dlb大于已有的最小实际距离时,就可以放心地对A、B进行剪枝,这样就减少了距离计算的次数。又采用了文献[11]中证明的不同长度序列下界之间的关系,在只计算一次实际下界的情况下推导出更长子序列的下界,从而减少了下界的计算开销。最后,再使用一个近似函数在遍历子序列长度时不是每次往上加1长度,而是跳跃性地递增。
文献[4]提出了通过计算原始时间序列间的距离来对数据进行转换,然后使用现有的分类方法(如SVM)查找shapelets;文献[5]中使用了特征向量和融合正则化套索相结合的数学方法来寻找shapelets位置;此外,还有使用查找关键点[12]、非频繁子序列[13]等技术剪枝shapelets候选集合的方法。
以上的大多数方法还是基于原始方法中查找shapelets框架的改进,在大量的候选子序列中去寻找能最好地表示一个类别特征的shapelet,虽然创新了许多距离计算方式、剪枝、距离下界等技术,但是运行效率不稳定,受数据集自身数据分布影响较大,在有些较大数据集上时间消耗还是难以接受。
3 基础知识与符号
下面介绍一些本文中的基础知识和符号:
定义1时间序列T和子时间序列s。
一个按时间顺序排列的观测值称为一条时间序列T={t1,t2,…,tm},每一个值ti表示该时刻下的记录数值,m表示时间序列的长度。
时间序列T中一个连续片段称为子时间序列i表示子序列的起始位置,l为子序列的长度。
定义2数据集D。
多个时间序列及其对应的类标号组成了一个数据集D=<T1,c1>,<T2,c2>,…,<TN,cN>,N表示数据集中的时间序列的数目。
定义3子序列距离。
两条相同长度的子序列s、s′,经过Z标准化后使用欧氏距离计算它们之间的相似性,表示为:

定义4子序列和时间序列距离。
子序列和时间序列的长度不等,因此通过在长时间序列上依次滑动短序列找出最小距离作为两者之间的距离,表示为:
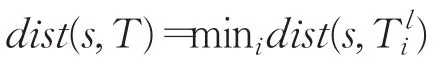
定义5相似性距离阈值。
通过对原始查找shapelets方法的研究发现:同类别时间序列中存在大量相似的子序列,不同类别中依然存在许多相似的子序列[14],这是因为不同类别序列间的差异主要是来自那些局部具有特殊形态的序列片段,而非整体都是不同的。这些特殊片段往往范围不是很大,却有着能够区分其他类别的特别形态,而余下的其他片段却没有关键信息,彼此之间差异很小。根据shapelets的特性(它对表征特定类样本时距离很小,相反对其他类别时的距离较大),那些到任意类别距离都小的子序列是不可能成为shapelets的。基于以上分析使用子序列间距离表征相似性,设置一个距离阈值ε,当子序列之间的距离小于该阈值时,则认为它们之间是相似的,反之则是非相似的。通过这个阈值过滤掉候选集合中的相似子序列,省去后续无用的距离计算。ε的设置方法是对数据集中所有子序列间距离从小到大排序,统计其整体分布情况,确定某一累计总体距离比例p(事先设置参数)下对应的距离。
下面通过一个具体的实例来讲解ε的设置方法:任意选择3个单变量时间序列数据集(Fish,50words,InlineSkate),计算每个数据集中子序列间的距离,按从小到大的顺序排列后统计在不同距离区间下的分布比例,所得到的数据使用Excel绘图,结果如图1所示,可见大多数分布都是倾向于距离较小一侧的。以Inline-Skate为例,选择数据集中累计占比p=0.25所对应的距离(该例中为1.7)设置为距离阈值,也就是说针对InlineSkate数据集子序列间距离小于1.7时认为它们是相似的。p值越小,过滤越多,候选子序列也就越少。通过第5章的实验结果可以看到通过此方法可以过滤掉大部分的候选子序列,而只选择少量的(约为0.1%)子序列进行距离计算。p值的设置需要视不同数据集的情况区别分析,没有一个统一的数值,经过反复试验本文中将其设置为{0.15,0.25,0.35}三者中的一个。
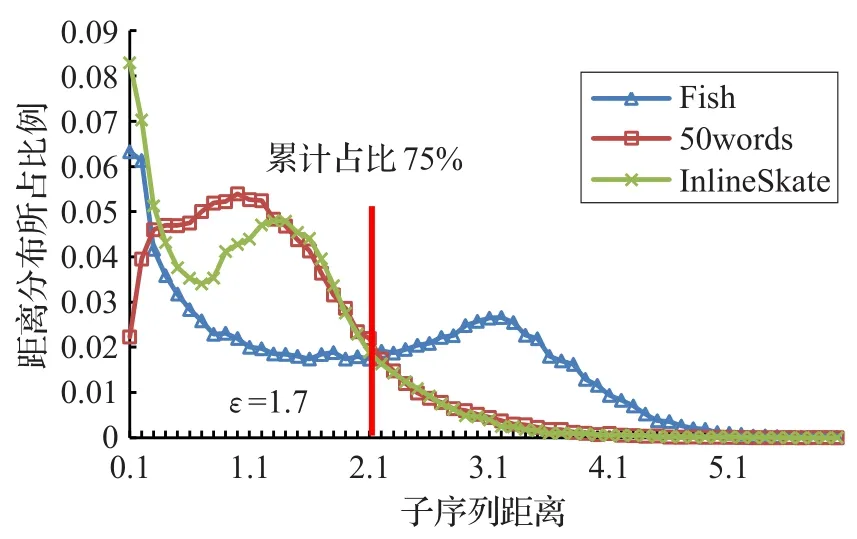
图1 子序列距离分布
定义6基于离散矩阵的类可分离性。
假设有一组样本(x,y)∈(Rd×Y),其中Rd为d维特征空间,Y={1,2,…,c}为类标集合。样本总数为N,ni表示第i类中的样本个数,xi,j表示第i类中第j个样本,u为所有类别的样本均值,ui为第i类对应所有样本的均值。则类间离散度矩阵Sb和类内离散度矩阵Sw定义为:


基于离散矩阵的类可分离性为两者的迹或者行列式的比值,即J=Sb/Sw,J值越大,表示类可分离性越好[15]。
对于一个候选子序列candidate,计算它与所有时间序列的距离,直观表示如图2所示,其中红色矩形代表的是candidate和类别1样本的距离,绿色三角形代表的是和类别2样本的距离。按距离大小映射到一维坐标后,按照类内类间离散度矩阵的定义进行计算,就可以通过类可分离性来评价该候选子序列分类性能,得分越高表明该子序列分类性能越好。
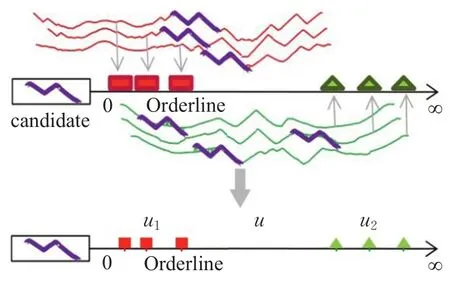
图2 基于离散矩阵的类可分离性
4 非相似shapelets快速查找
4.1 算法综述
在第3章理论与技术基础之上,给出了步骤严密的算法。整体思路是首先通过距离阈值过滤掉相似的子序列,再使用类可分离性对过滤后的子序列进行评价,从中选择得分靠前的部分为shapelets,最后使用选择出的多个shapelets对测试序列进行分类。
4.1.1 计算距离阈值
算法1computerThreshold
输入:训练集Tr(样本数N,长度m,类标集合C={1,2,…,c}),累计比例p,shapelets长度集合Φ∈RL。
输出:距离阈值ε。
1.Y←∅;
2.for 1,2,…,Nm
3.i←rand(N);Φl=rand(ΦL);j=rand(m-Φl+1);
4.i′←rand(N);j′=rand(m-Φl+1);//随机选择子序列起始位置和长度
5. select random candidate:s←Ti,j:j+Φl-1;
6. select random candidate:s′←Ti′,j′:j′+Φl-1;
7.Y.add(dist(s,s′));//计算子序列间距离加入到Y集合
8.sort(Y);
9.ε=Y[p];
距离阈值ε的计算是该算法的基础,它决定着过滤性能的好坏,按照定义5中介绍的原理与方法,具体计算过程如算法1所示。先初始化一个集合Y用来存放子序列间的距离,设置一共需要计算的子序列组数为Nm,任意选取两条长度相同位置不同的子序列(步骤2~6),按照定义3计算子序列之间的距离,将得到的距离存放于Y中(步骤7)。此处在选择子序列对时,不是将全部可能位置可能长度的子序列全部计算一遍,而是使用了固定数量下随机选取的方法,这样做的好处是保证了与总体分布误差很小的情况下大大减少了比较的次数,降低了整体计算的时间复杂度。等到所有的子序列间距离计算完后对Y进行排序(步骤8),得到事先设置好的参数——累计比例p下对应的距离(步骤9)。
4.1.2 查找shapelets
算法2DiscoveryShapelets
输入:数据集Tr(样本数N,长度m,类标集合C={1,2,…,c}),累计比例p,PAA压缩比例r,shapelets长度集合Φ∈RL,shapelets个数k。
输出:kShapelets,kDistance。
1.R=∅;B=∅;disToShapelets=∅;
2.ε←computerThreshold(Tr,p,Φ);//计算距离阈值
3.for 1,2,…,NmL
4.i←rand(N);Φl=rand(Φl);j=rand(m-Φl+1);
5. select random candidate:s←Ti,j:j+Φl-1;
6. if!similarWith(s,B)//候选子序列和已选子序列是否相似
7.Dis←dist(s,Tr);
8.score(s)=ClassSeparability(Dis,C);//计算类可分离性
9.disToShapelets.add(Dis);B.add(s);
10. elseR.add(s);
11.sort(score);
12.kShapelets←selectK(B);
13.kDistance=selectK(disToShapelets);
查找shapelets过程如算法2所示:给定一个时间序列训练集Tr,先对其中的时间序列进行Z标准化,使得处理后的数据满足标准正态分布。然后有选择地根据数据集大小进行PAA(Piecewise Aggregate Approximation)处理来降低时间维度。对原始数据预处理结束后,初始化备用集B、拒绝集R和子序列到时间序列距离集disToShapelets为空(步骤1),集合B中存放的是非相似子序列,R中存放的是与B中相似的子序列。然后计算距离阈值ε(算法2)。在选取候选子序列s时,并没有按照原始方法中的滑动窗口遍历每一种子序列,然后再增加窗口宽度重复滑动的方法,而是采取了随机选择起始位置,随机选择子序列长度的方法。为了不失一般性,将最外层的循环次数设置为NmL(步骤3),产生的随机数满足均匀分布,这样做和原始方法中候选集的数目差不多。随机选取一条候选子序列(步骤4、5),计算它与备用集B中子序列间的距离(步骤6),若大于阈值ε,就将它加入到B中,否则加入到拒绝集R中。对加入到备用集B中的子序列,计算它与训练集中所有时间序列的距离dist(s,Tr),再通过类可分离性(定义6)对dist(s,Tr)计算评价得分score,并将dist(s,Tr)加入到距离集合disToShapelets中(步骤7~10)。待全部候选子序列计算完成后将B内子序列按照得分非递增的顺序排序(步骤11),最后选择得分靠前的k个子序列作为kShapelets及其对应的kDistance(步骤12、13)。
4.1.3 对测试序列分类
算法3oneNN(Te,kShapelets,kDistance)
输入:测试集Te(样本数N,长度m,类标集合C={1,2,…,c}),选择出的k个shapelets及其对应的训练集的距离kDistance。
输出:分类准确率Accuracy。
1.correctNum=0;
2.fori=1:N;j=1:k
3.testToShapelets=dist(kShapeletsj,Tei);
4.testToTrain=testToShapelets-kDistance;//经处理转换后测试样本和训练样本间距离
5.classVal=argmin(testToTrain);//将最近邻测试样本的类标号作为分类结果
6. ifclassVal==testClassi
7.correctNum++;
8.Accuracy=correctNum/N;
查找出shapelets的根本目的是为了对测试序列进行分类,原始方法中使用的是决策树的分类方法。这样做的不足之处是:
(1)决策树中每个节点是唯一shapelet,若此shapelet性能不好,将导致分类的彻底失败;
(2)对于多分类问题就要选择多个shapelets,而原始方法中就只能通过多次查找来解决,这样做非常耗时,而且有选择相似shapelets的风险。
为了解决这些问题,将由算法2得到的kDistance看成是k个特征属性组成的向量,每个特征为一个shapelet到所有训练序列的距离。对测试序列和k个shapelets进行距离计算后,也将得到包含k个属性的特征向量。再使用1-NN分类方法寻找每个测试序列的最近邻训练样本,以此来确定测试序列的类别,具体过程如算法3所示。对于训练集Te中每个样本,计算它与kShapelets的距离,得到一个长度为k的距离向量testToShapelets(步骤3),然后与训练集kDistance中寻找距离最近的样本对应的类标号作为该测试样本的类别(步骤4、5),若与真实类别相同则correctNum累加1(步骤6、7)。最后返回整体的准确率。
4.2 参数分析
4.2.1 PAA的压缩比例设置
算法2中提到算法开始前有选择地对原始数据进行PAA降维处理,若使用PAA的压缩比例r={1/2,1/4,…},r值越小则降维幅度越大;但是降维后的数据会忽略掉一些原始特征,有可能影响后续的分类效果,因此r值也不能设置得过小。在图3中根据此问题测试了3个数据集,分析它们在使用不同的PAA压缩比例r后的分类效果。随着r的减小,分类准确率会有所降低,时间消耗降低较为明显。因此只要r值设置得合理,可以减少计算时间,分类精度也没有太大的影响。
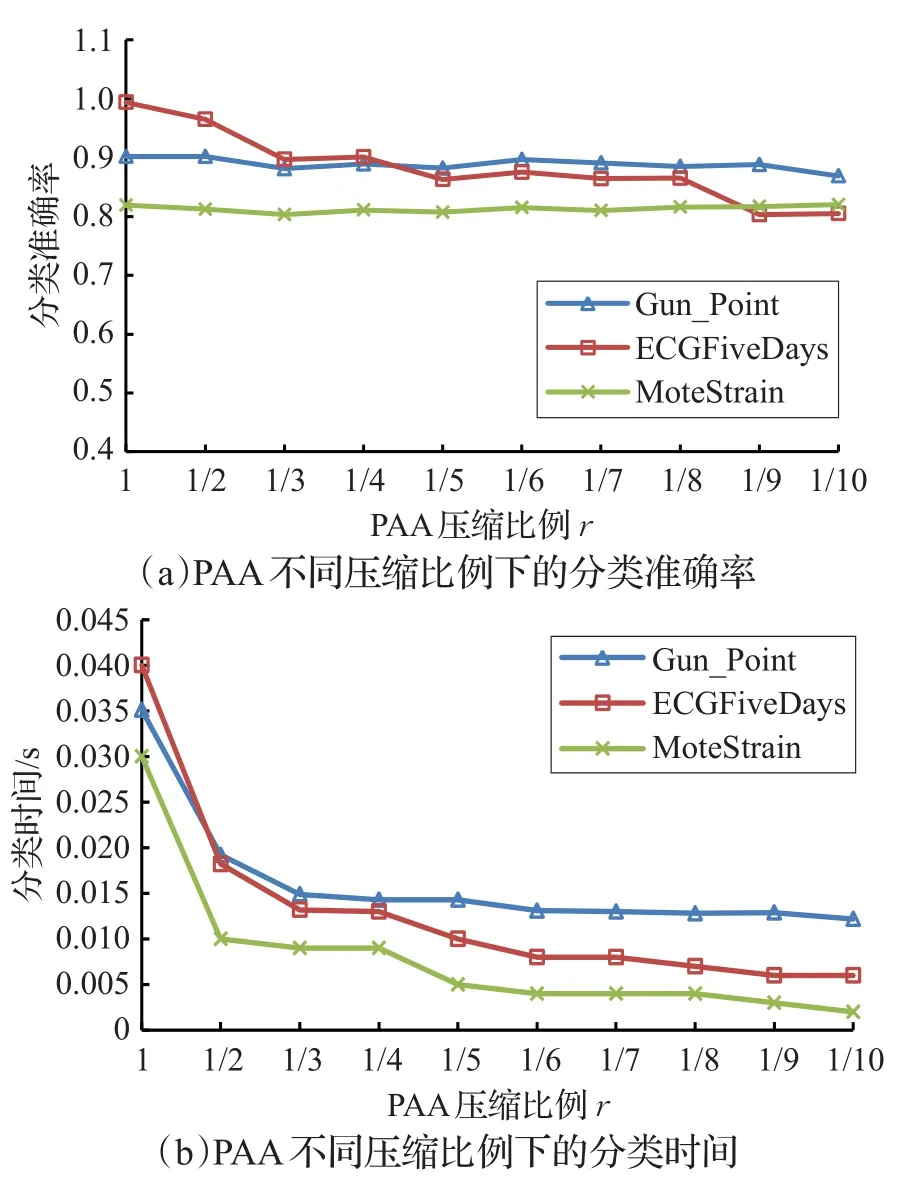
图3 PAA不同压缩比例下的分类对比
4.2.2 子序列长度的设置
在搜索不同长度的候选子序列时,原始方法中采用的是窗口逐步加1的方式,这样做虽然可以把每种可能性都考虑到,但是低效。因为shapelet的核心思想是找出那些代表特征的时间片段,只要是包含了这些关键特征,无论是长序列还是短序列对分类是没有太大差别的,所以原始方法中一个很突出的问题就是最终选择出的shapelets之间有很大的重合,而这些重复计算占用了大量的时间,最终导致效率低下。为了解决这一问题,在设计shapelet长度集合Φ时把候选长度设置为若干个固定值。为了证明此方法的有效性,假设选取子序列的长度为0.2~0.6 m,将此长度区间平分为n(n=3,4,…,15)份,也就是子序列长度有n种可能,统计查找出的shapelets分类情况,结果如图4所示。由结果可得,子序列长度可选范围的大小对分类精度影响不大,但是长度数量越多,花费的时间也就越多。在本文的实验中,统一设置子序列长度为Φ={0.2 m,0.4 m,0.6 m}。

图4 不同子序列长度下的分类比较
4.2.3 shapelets数量的设置
算法2步骤12和13中选择得分靠前的前k个子序列,k值大小对后续分类准确率和时间影响较大,这是一个对算法性能有重要影响的参数。因此做了以下实验:令k值由小变大,分析它对分类精度的影响,结果如图5所示。因为shapelets数目只会影响到测试集分类时间和结果,对训练集寻找shapelets的时间没有影响,所以只给出了分类准确率的结果。虽然没有分类时间的比较,但是显然知道:分类时间和shapelets数目成正比关系。由结果可得:选取较少的shapelets时,会降低分类准确率,随着数目的增加,准确率有所上升,到一临界值时数目再增加,准确率也不会发生变化。不同的数据集临界值不同,在后面的实验中将k统一设置为备用集B中子序列总量的50%。
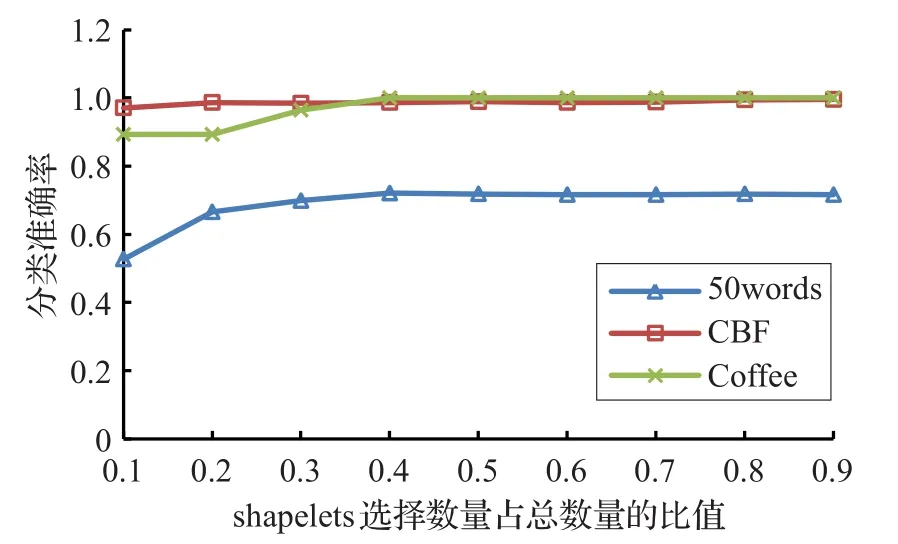
图5 选择不同shapelets数目对分类的影响
4.3 时间复杂度分析
对于样本数为N、时间长度为m的数据集,原始算法中shapelet候选集的大小为Nm2,查找最好的shapelet时间复杂度为O(N2m4)。若使用PAA进行时间维度的降维,其压缩比例r={1/2,1/4,…},那么降维后的时间复杂度为O(r4N2m4)。通过设置一个距离阈值可以对候选子序列进行过滤,假设过滤的比例为其中为备用集合中子序列的数量,为拒绝集中子序列的数量。因此,若PAA和过滤子序列的方法同时被使用,候选集的大小为fNr2m2,最终查找多个shapelets的时间复杂度为O(fNr2m2×Nr2m2)=O(fN2r4m4)。本算法还需要额外计算两部分:计算距离阈值和比较候选子序列与已选子序列间的相似性,前者的计算复杂度为O(Nrm×rm)=O(Nr2m2);后者的复杂度为O((1-,其中为子序列长度可能取值的数目,根据4.2节中的分析,由于的数量级为1~2,因此额外需要计算部分的复杂度为O(2Nr2m2),相比于过滤后的子序列中查找shapelets的时间复杂度O(fN2r4m4)相差1~2个数量级,所以最终的时间消耗为O(fN2r4m4)。本方法和原始方法计算时间比值是fr4,第5章的实验结果同样验证了此分析的结论,由此可见NSDS方法可以大大缩短计算时间。
5 实验结果
5.1UCR数据集
为了评价本文新提出的非相似shapelets快速查找方法(NSDS)的有效性,选用了UCR作为单变量时间序列数据集[16],它们中大多数已被用到时间序列的仿真实验中,每个数据集的具体信息描述如表1所示,采用原数据集中默认的训练集和测试集。分类器采用1-NN,使用欧氏距离计算样本之间的相似性。实验环境为Core i7四核CPU,主频3.60 GHz,内存8 GB,Windows 8系统,使用Java编程语言。对比算法选用文献[2]中提出的FS算法。
5.2 单变量时间序列分类性能
将NSDS方法和FS方法在每个数据集上分别计算10次,取其平均值作为最终的实验结果,如表2。其中第3~5列的r、p、k分别对应算法2中的3个输入参数:PAA压缩比例、距离累积比例、最终选择shapelets集中的数目。通过设置不同的参数,经过多次实验,取最好分类结果时对应的参数值。第6列的数值表示的是最终选择出的shapelets子序列数目占所有候选子序列的比值,当该比值小于0.001时只进行标记,未给出精确数值。最后4列代表着两种方法各自的分类准确率和查找shapelets时间,为了明显起见,将分类准确率高和运行速度快的数值加粗表示。
由表2结果可得:NSDS方法在分类准确性上要优于FS方法,在所有的45个数据集中有33个数据集使用NSDS方法分类准确性更高,最大地提升为Cricket_Z数据集的0.285,最小的为ECGFive数据集上的0.003,平均为0.101。相对地在另外12个数据集中,FS方法分类准确性优于NSDS方法的幅度都较小,最大的也只有0.046,最小的为0.003,平均为0.022。
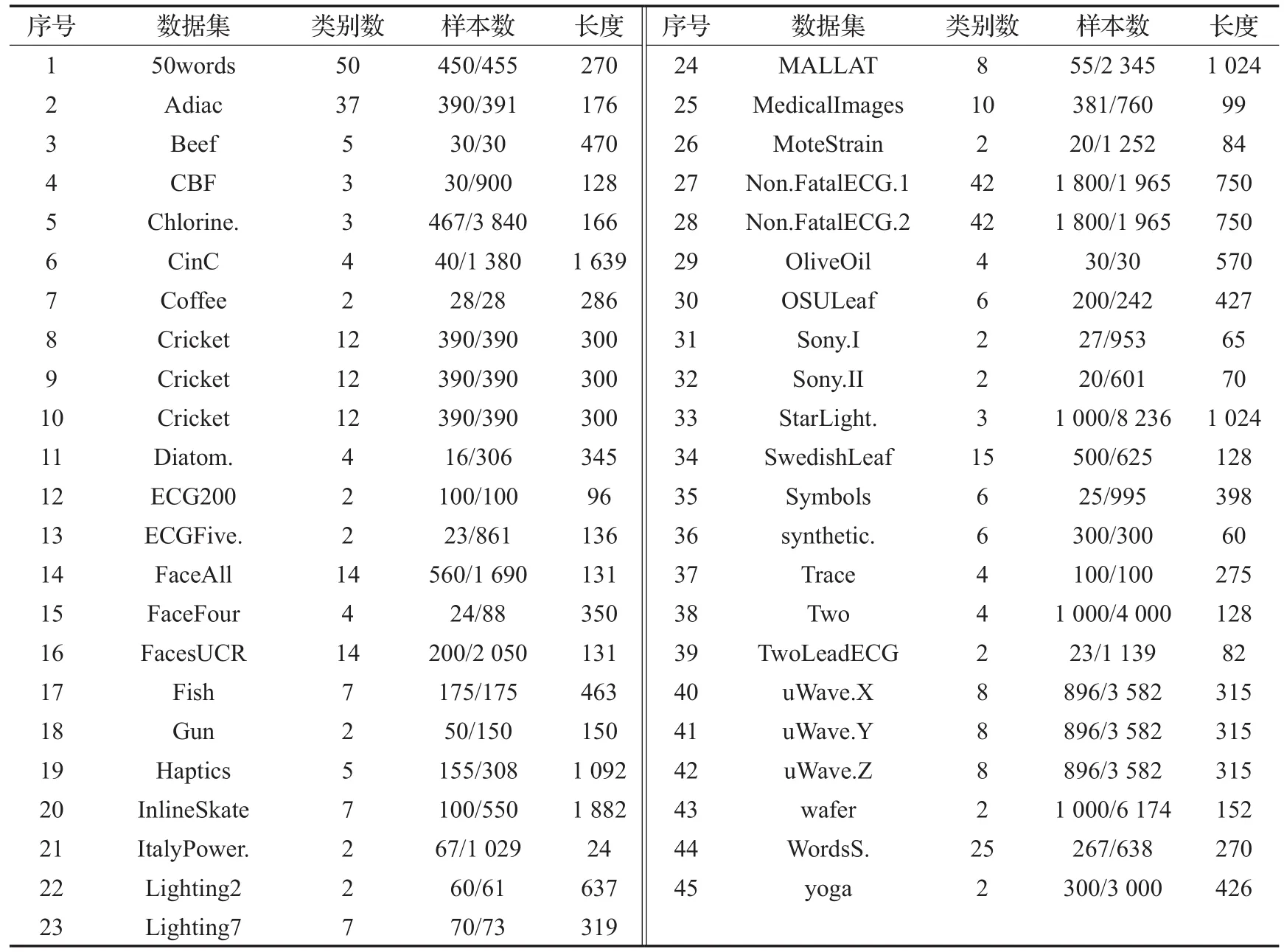
表1 UCR时间序列数据集

表2 UCR数据集分类准确率和时间对比
图6为两种方法分类准确率比较的直观显示,图中左上部分的区域代表FS算法查找出的shapelets分类准确率较好,相反的右下部分代表NSDS方法较好,且距离对角线越远的区域代表两者之间差别越大。从图6中可以明显看到大约3/4数据集的结果都落在了NSDS区域,且整体偏离对角线的幅度大于落在FS区域里的数据集,这和之前的定量分析相一致。

图6 NSDS方法与FS方法分类准确率比较
在查找shapelets时间方面,NSDS方法一致优于FS方法,并且优势非常明显,平均都要快3~4个数量级,与4.3节中时间复杂度分析的fr4相一致。最大的速度提高是InlineSkate数据集,提高了119354倍。在每个数据集上的查找时间都控制在几秒以内,这无疑对后续的数据挖掘或者是计算能力不是很强的设备提供了可能性。NSDS的计算时间之所以能够如此之短,除了PAA降维的作用之外,更主要是因为使用了距离阈值过滤候选子序列的方法,从表2中可以看出最终选择出的shapelets子序列数目占所有候选子序列的比值都非常小,大多数都在10-3级别,最大的也仅有0.07。剩下的少数子序列计算它们与时间序列的距离也就变得非常容易,这种先过滤后计算方式可以最大程度地减少时间复杂度,优于先计算后过滤的方式[17]。
5.3 shapelets可解释性
知道使用shapelet进行分类的一个很大优势是它具有良好的可解释性,能够很明确地显示出类别之间的差异之处,指明为什么一个特定的对象被分配到一个特定的类中,帮助研究人员更好地理解数据。在本文方法中是选择出最好的k个shapelets,通过类可分离性评价好坏,那么这k个shapelets是否依然保持了良好的可解释性呢,为此将所选择出的shapelets结果绘制出来,结果如图7所示。
由图7可得,图(a)中为Trace数据集中不同类别的样本直观表示,可见每种类别都有自己独一无二的特性,如类别1中在时间点50附近有一个短暂的高峰,类别2和类别1的区别就是没有这种高峰,显然这个短暂的高峰就是一个shapelet。图(b)中为通过NSDS算法得到的shapelets中部分子序列,很明显shapelet1包含了之前人为分析应该为shapelet的片段,同样另外2个也包含了其他类别显著的特征。该结果同时也说明了shapelet只需要包含这些关键特征,长序列和短序列是没有太大差别的。
5.4 多变量时间序列数据分类性能

图7 Trace数据集中NSDS方法选择出的shapelets
目前使用较多的多变量时间序列分类方法是基于实例的,也就是说选择合适的相似性度量方法计算实例之间的距离,再按距离大小进行分类。例如,基于动态时间弯曲(DTW)和K-NN的多变量时间序列分类方法使用非常广泛,但是在某些数据集上表现得并不是很理想[18];或者是使用特征表示方法,对原始数据进行特征提取,再进行分类[19];还有的学者将多种处理手段融合,比如Banko和Abonyi[20]将基于PCA的特征提取方法与DTW相似性度量方法相结合,转换后的数据保留了变量间的相互关系;Prieto等人[21]提出了分层分类的策略,先使用多分类器对每个变量进行学习,融合底层分类结果后再使用高层学习器确定最终类别。
以上这些方法有的计算复杂度很高,有的在处理过程中丢失了原始数据的物理特性,有的经过复杂计算后对分类性能提升并不高。结合本章对子序列shapelet的学习,使用基于多个shapelets的组合分类器方法来对多变量时间序列分类。具体来说就是对每个变量使用NSDS方法寻找多个shapelets,然后使用1-NN方法分类,这样就构建出d个分类器(d为变量数),采用投票的方式融合多分类器的结果作为最终分类类别。
人体活动识别是指在测试者身上放置多个运动感应器来记录活动数据,并对这些数据进行挖掘来获得运动模式的过程,该研究邻域近几年随着运动记录设备的普及化而得到了越来越多的关注[22-24]。这些活动数据从本质上来说就是多变量时间序列,每个变量代表着一个感应器获得的时序数据。因此实验中选用文献[22]中介绍的Daily and Sports Activities Data Set作为实验数据。

表3 NSDS方法在运动数据集上分类结果
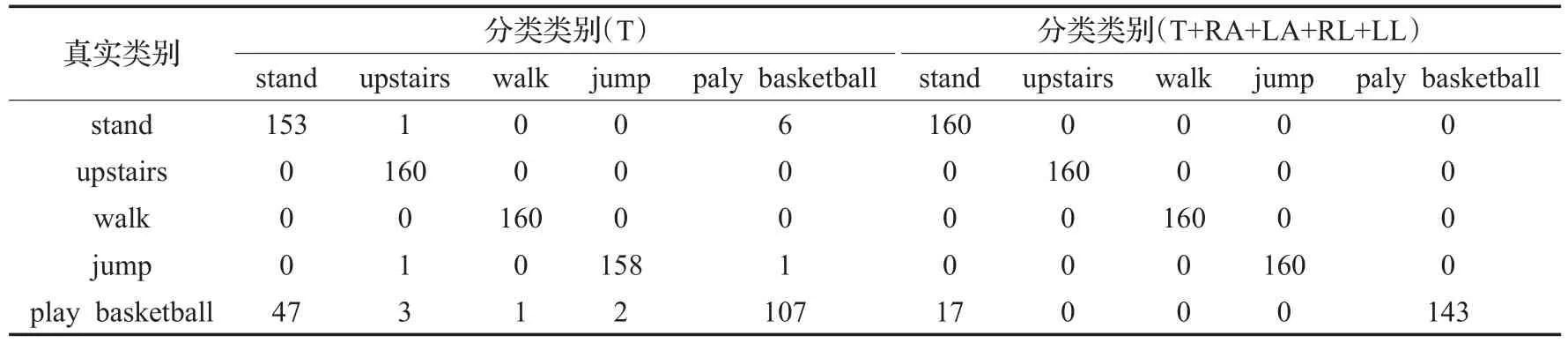
表4 不同感应设备下的混淆矩阵
Daily and Sports Activities Data Set是由Bilkent University从8个实验者采集而得:在每个实验者身上的5个不同部位放置5个感应设备采集19种动作的运动时间序列。每个设备包含多个加速度计、陀螺仪、磁强计感应器,最终得到数据集包含9120个样本,每个样本变量维数45,时间维数125。本实验选择其中5类常用的动作(站立、行走、上楼、跳跃、打篮球),也就是共2400个样本。随机选择其中2/3作为训练集,1/3作为测试集,PAA压缩比例r设置为0.5,距离累积比例p设置为15,重复10次,取平均值作为最终结果,如表3所示。
由表3结果分析可得:根据测试者身上感应设备的多少而采集到的数据集变量数是不相同的,分别使用单一感应设备和组合感应设备来对运动进行识别。表中第2列代表不同的放置部位:T(躯干)、RA(右胳膊)、LA(左胳膊)、RL(右腿)、LL(左腿)。显然NSFS方法对运动识别的准确率较高,当仅使用一个感应设备时,可以达到最低91.275%、最高95.125%的准确率。其中放置在右腿的感应设备采集的数据分类准确率最高,这和人们的常识也相一致:腿部动作幅度最大。随着变量数的增加,分类准确率逐渐增加,查找shapelets和分类所需的时间也在逐步增加,当使用全部5个感应设备时,分类准确率达到97.625%,这说明了有些动作是需要身体各部位协作来完成的,如果只是观察其中某个部位错误分类的可能性也就越大。
为了更加深入地分析该数据集,给出了表3中序号1和序号9实验中一次结果的混淆矩阵,如表4所示。表中各行代表真实类别,各列代表使用NSDS方法得到的预测类别。对于upstairs和walk两个动作,使用基于躯干的传感器和所有传感器都可以做到完美分类,错误率为0;stand和jump动作中有个别样本被错误分类;分类效果最差的是play basketball动作,在两种情况下的分类错误数分别为53和17,相应的错误率为33.125%和10.625%。其中主要是被错误分类成stand动作,在使用基于躯干的传感器时有47次被错误分类成stand动作,使用全部传感器时这一错误次数为17。分析其中的原因是和数据自身采集时有关,因为数据在采集时要求测试者连续完成每个动作5 min,然后将所收集的数据按照5 s的窗口划分成60等份,在做play basketball这个动作时,中间会有短暂的静止状态,这些静止状态被划分成小块时就会和stand动作很相似;其次因为play basketball这个动作更多的是手臂的参与,而躯干有时会处于静止状态,所以在只使用T时play basketball被错误分成stand的次数远远高于使用全部感应设备。
6 结束语
本文提出了一种快速查找非相似时间序列shapelets的方法,充分利用shapelets思想的特性,而不拘泥于原始方法中的框架,使用了多种加速方法和近似计算,在不影响分类精度甚至是提升精度的情况下极大地减少计算时间。为解决多变量时间序列的shapelets问题或者计算能力不强的设备上使用shapelets问题提供了一种可行的选择。在后续的工作中将会继续致力于时间序列shapelets的研究问题,进一步改进本方法,减少参数的输入,尽量减少人为因素的影响,增强算法的鲁棒性。
