基于多视角非负矩阵分解的人体行为识别
2018-08-20郭炜婷夏利民
郭炜婷,夏利民
GUO Weiting,XIALimin
中南大学 信息科学与工程学院,长沙 410075
College of Information Science and Engineering,Central South University,Changsha 410075,China
1 引言
近年来,基于视频的人体行为分析引起了计算机视觉研究者的广泛关注,在视觉监控系统、人机交互、体育运动分析等方面都具有广阔的应用前景。
在以往的研究工作中,研究人员采取不同的方法提高单个摄像头的人体行为识别准确率。Ronao等[1]提出一种深度卷积神经网络,探索行为和一维时间序列信号的固有特性,同时自动从原始数据中提取稳定特征。Gao等[2]提出基于SR-L12稀疏表示的人类行为识别算法。Gao等[3]提出基于RGB和深度运动历史图像的全局结构动作描述符。周鑫燚等[4]提出一种RGB和深度图像特征联合的人体行为识别方法。
然而在单视角环境下,观测角度和光线的变化会使得识别难度增加,而且在当前观测角度下,未必能够捕捉到最理想的行为特征。因此,许多研究者尝试利用多视角方法来解决此类问题。Shen等[5]将动作姿态用三关节点集合表示,在两帧间寻找由三节点构成的刚性运动的不变量。Li等[6]提出一种生成贝叶斯模型,不仅将特征和视图联合起来考虑,还学习不同类别的判别表示。Li等[7]通过学习一个低维度流形,并对动态过程建模重建3D模型。这些多视角算法,通常需要提前知道不同视角之间的角度,这就严重限制了它们的应用。因此,研究者们更注重视角不变特征学习。例如,Zheng等[8]提出将两个同时学习的源域和目标域的字典组成可转换字典对,使得同一动作在两个不同视角下具有相同的稀疏表示。Liu等[9]用一个双向图来建模依赖于视角的视觉词袋模型,这就将一个BOVW动作模型转换为一个BOBW模型,在不同视角下拥有显著稳定性。Junejo等[10]利用自相似矩阵与SVM分类器,为每个视图分配一个单独的SVM分类器,应用融合方法实现最终结果,但是无法发现视图之间的相关性。Gao等[11]提出基于组稀疏与图集的多视图判别结构化字典。Hsu等[12]提出金字塔结构的词袋模型(BoW-Pyramid)描述时空矩阵,但不适当的分割会对识别率产生影响。Hao等[13]利用稀疏编码算法将不同视图的低层次特征转换为高层次特征,然后采用多任务学习(MTL)方法进行联合动作建模,但低层次特征在不同视角下具有差异性,将会影响动作建模。
本文提出一种基于时空矩阵和多视角非负矩阵分解的人体行为识别方法。在底层特征提取过程中,提取每个视频帧的时空描述符,其包含足够充分的动态和静态信息。原始动作视频包含很多图像帧,而一个动作可以只用几帧来表示从而达到降低计算量的效果,因此本文利用人工免疫聚类算法提取视频的关键帧。自相似矩阵(Self-Similarities Matrix,SSM)特征具有仿射不变性和投影不变性,可以用来解决观测角度改变对人体行为识别的影响,本文改进自相似矩阵,从而构建基于时空描述符的时空矩阵(Spatio-Temporal Matrix,STM)。考虑到视频大小存在不同,每一个视频包含的帧数将有所不同,则形成的时空矩阵大小不尽相同,而提取视频关键帧可以统一时空矩阵的大小。为了进一步得到不同视角下同一个行为的共享相似性特征,本文利用多视角非负矩阵分解算法(Multi-View Nonnegative Matrix Factor,MultiNMF)同时分解不同视角下的时空矩阵,得到共识矩阵。最后,通过计算共识矩阵的最大相关系数对人体行为进行分类。通过多视角非负矩阵分解算法分解不同视角下相同动作的时空矩阵得到的共识特征矩阵,对视角改变拥有良好的鲁棒性,提高了识别精度。
2 基于时空矩阵的动作表示
使用时空矩阵(STM)进行动作表示。首先需要提取动作的低级特征,提取的低级特征应能详尽地描述一个动作。其次改进自相似矩阵上下三角形对称的结构,使得改进的自相似矩阵(即时空矩阵)同时包括运动信息和形态信息。关键帧提取则是为了统一时空矩阵的大小以及去除冗余帧。
2.1 特征描述符提取
为了得到视频帧中的运动和形态信息,从而完整地描述一个动作,本文提取方向梯度直方图(HOG)和光流直方图(HOF)作为低级特征。将视频帧分为n个子区间,将每个子区间划分为2×2个网格,在每个网格内,计算像素点梯度方向并量化为8个单位的直方图生成当前网格的HOG描述符,同时计算其中光流并量化为9个单位的直方图生成当前网格的HOF描述符。结合各网格的直方图,得到第i个子区间维度为68的低级描述符pi=[HOGT,HOFT],其中HOG向量维度为32(2×2×8),HOF向量维度为36(2×2×9)。结合各子区间的直方图,得到第i帧的联合特征描述符Pi=[p1,p2,…,pn],第i帧HOG特征描述符第i帧HOF特征描述符
2.2 关键帧提取
为了去除视频冗余帧并提高计算性能,本文对原始视频提取关键帧。K-means聚类算法对初始化很敏感,若初始化不当,很可能导致算法收敛到局部极值点而得不到最优划分,但其原理简单,收敛速度快。人工免疫聚类算法将免疫原理与K-means方法相结合,可以获得比K-means方法更接近于全局最优的解,同时具有计算效率高,聚类能力强等优点,因此本文采用人工免疫聚类算法提取关键帧。该算法一方面将待处理的数据视作免疫系统的抗原,另一方面将待处理的数据经K-means方法后得到的聚类中心视作初始抗体,通过抗体对抗原不断进行识别,最终得到最优抗体。
(1)将原始视频的T帧图像P=[ ]P1,P2,…,PT根据式(1)计算N个类心,其中Cj.center表示待处理数据经过K-means聚类得到的第j个聚类中帧的数目,Cj(j=1,2,…,N)表示第j个聚类中心,即初始抗体。

(2)将抗体与抗原之间的欧式距离定义为两者之间的亲和度,根据亲和力最大原则,将T帧图像分配到不同的Cj中。每完成一次聚类,采用式(2)判断抗原的分配情况:

其中,uij表示抗原Pi属于Cj(j=1,2,…,N)的程度,取值为0或1,有如下定义:

(3)根据式(4)对抗体进行变异,其中ξ是学习率或成活率,确定系统搜索抗原的方向,取值需要依据抗体和抗原的亲和程度确定;PY是每一类中含有的抗原;C是根据每一类中含有的抗原数克隆出同样数目的抗体;Cis为新抗体。选择新抗体与抗原之间亲和度最大的一个抗体为最佳抗体,即新的聚类中心,而对其他抗体进行清除。

(4)重复上述(2)、(3)步骤,直到式(2)达到最小,产生的最优抗体作为聚类中心,并输出聚类结果。
(5)聚类完成后,选择各类中处于中间位置或距类心最近的一帧图像为关键帧,关键帧数为N。
2.3 时空矩阵构建
自相似矩阵是一个反映图像序列相互关系的矩阵,其拥有仿射不变性和投影不变性。特征自相似矩阵中丢弃帧的特征而只保留帧与帧之间的特征差异,特征差异由两个特征描述符之间的距离来体现并且其与观察运动的视点位置关系不大[14]。对于两个不同时刻的相似动作,这两个特征描述符之间的距离小;而对于两个不同时刻差异很大的动作,则这两个特征描述符之间的距离较大。自相似矩阵特征在视点改变时,变化较小,可以很好地表示不同视点下的人体运动。因此本文用自相似矩阵来描述运动。
经人工免疫聚类算法后,得到N个关键帧。给定视频关键帧图像序列P={P1,P2,…,PN} ,则SSM定义如下:
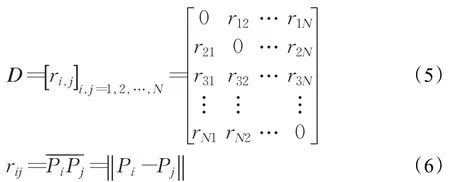
其中,‖⋅‖表示低级特征向量之间的距离。因为对角线上的每一个元素都代表特征向量与其本身的距离,所以等于0。因为Pi到Pj之间的距离与Pj到Pi之间的距离相等,显然D是一个对称矩阵。该矩阵的模式取决于用于计算的特征和距离度量。
本文将rij定义为从动作序列中提取的HOG特征描述符之间和HOF特征描述符之间的欧氏距离。用关键帧的结构描述符G={g1,g2,…,gN}和运动描述符F={f1,f2,…,fN}表示一个行为,因为D是一个对称矩阵,上下三角形会拥有重复的信息,所以将自相似矩阵重新定义为时空矩阵:

时空矩阵上三角形表示HOG特征描述符的欧式距离,而下三角形则表示HOF特征描述符的欧式距离,对角线仍然为0。自相似矩阵上下三角形使用同样特征的距离(形状特征距离或运动特征距离)表示一个动作,是一个对称矩阵,即拥有重复的特征信息,只能从形状或运动一个方面描述行为;而时空矩阵上三角形包含形状特征距离,下三角形包含运动特征距离,是一个非对称矩阵,拥有不同的特征信息,全面描述了一个行为的形状和运动。因为HOG(形状特征)与HOF(运动特征)为互补特征,所以HOG与HOF特征结合比单一HOG或HOF特征能更好地表示一个动作,从而时空矩阵相比自相似矩阵能更好地描述一个动作。
3 基于非负矩阵分解的多视角学习
上文得到的时空矩阵在视角变化下具有高度稳定性。为了深度挖掘不同视角下相同动作的时空矩阵共享的相似稳定结构,用于在视角改变的情况下进行人体行为分析。本文采用多视角非负矩阵分解算法对不同视图的时空矩阵进行联合因式分解。
3.1 多视角非负矩阵分解
假设第j类动作有S个样本由nv个视角观察。定义表示第v个视角下的时空矩阵,对于每一个视角下的,可以分解为其中是每个视角下的基础矩阵,而是每个视角下的系数矩阵。V*为共识矩阵,反映了不同视角下时空矩阵共享的相似和稳定结构,即所要得到的共享视角不变特征。本文提出关于的联合最小化问题:
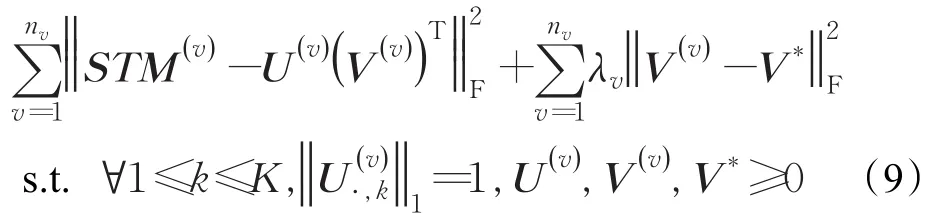
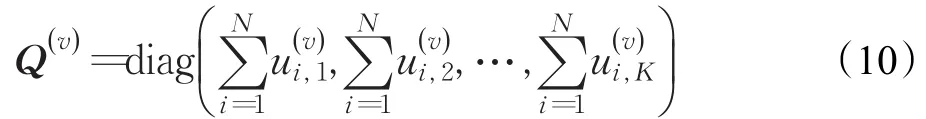
则式(9)等价于最小化目标函数O:

3.2 优化求解
为了解决优化问题,提出了一种迭代更新过程。具体地说,重复以下两个步骤,直到收敛:(1)固定V*,更新和使函数O最小;(2)固定和,更新V*使函数O最小。
3.2.1 固定V*,更新和
当V*是固定的,对于每个给定的视角v,U()v的计算不依赖于或因此,使用STM、U、V和Q来表示和,显示本小节的简洁性。则式(11)转化成如下形式:



采用拉格朗日乘子法求解V:
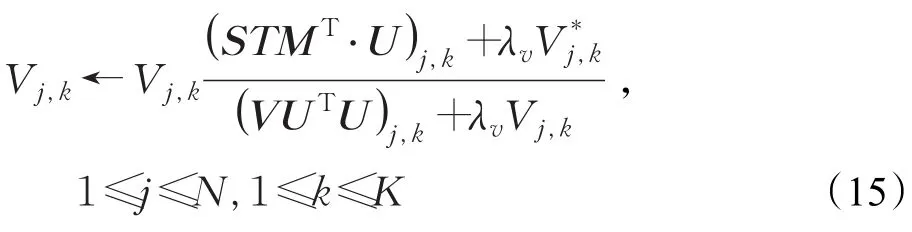
目标函数O对V*求偏导,得到:
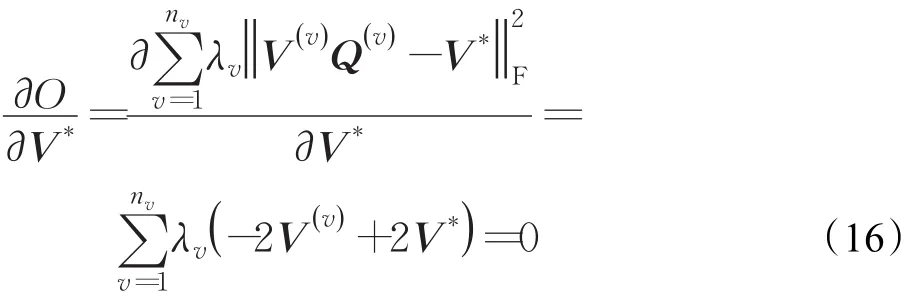
从而得到V*的精确解:
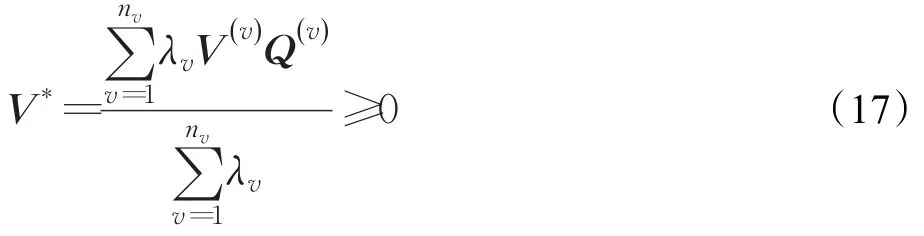
基于多视角非负矩阵分解算法分解不同视角下的时空矩阵如算法1所示。
算法1多视角非负矩阵分解算法(MultiNMF)
3.Repeat
4.Forv=1tonvdo
5.Repeat
9.直到式(12)收敛
10.end for
12.直到式(11)收敛
4 人体行为分类
上文计算得到的共识矩阵V*反映了不同视角下时空矩阵共享的相似稳定结构,为确保深度视角不变特征,其融合了多视角的信息且对视角改变具有鲁棒性。为了在视角变化情况下,仍有较高人体行为识别率,本文对共识矩阵V*进行人体行为分类,采用的分类方法是共识矩阵的最大相关系数。
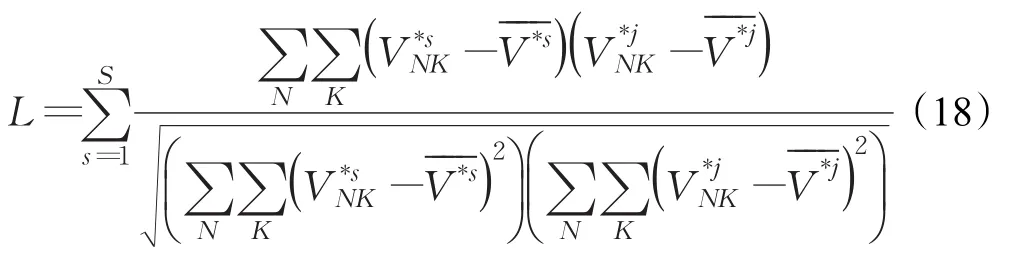
其中,V*s∈RN×K表示一类动作中第s个样本的最终训练共识矩阵;V*j∈RN×K表示第j类动作的测试共识矩阵;
分别表示训练共识矩阵和测试共识矩阵的平均值。L表示一类动作中所有训练特征矩阵与测试特征矩阵相关系数的总和,因为矩阵的相关系数越大,说明两个矩阵越相似,所以认为测试样本属于最大L值的那一类动作。
5 实验与结果
为了验证所提方法的有效性,本文在WVU数据集、i3Dpose数据集上进行实验。考虑到数据集中视频数量的限制,本文采用留一交叉方法验证分类效果。电脑配置是Intel®CoreTMi5-3210M CPU,2.5 GHz主频,4 GB内存的普通电脑,运行环境是Win7操作系统。其中根据文献[15],K取4,λv取0.01,N取30。
5.1WVU数据集
WVU数据集由12个动作组成,分别是静止站立、点头、鼓掌、单手挥、双手挥、打拳、慢跑、跳、踢、捡、投、打保龄球。每个动作由20个人在相同位置执行,由8台摄像机记录,记录角度如图1C1~C8标注所示,帧大小为640×480像素,WVU数据集均为单一行为,识别相对简单。WVU数据集中的操作示例如图1所示。

图1 WVU数据集操作示例(双手挥、打保龄球)

表1 不同视角融合方法对识别的影响
5.1.1 不同视角融合方法对识别的影响
本文改变多视角信息融合方法并与本文方法进行了对比。其中FV/Bowv与稀疏编码相结合;GM-GS-DSDL[11]是基于组稀疏与图集的多视图判别结构化字典学习用来融合不同视角信息与识别人体行为。结果如表1所示,采用单视角进行识别时,最高的人体识别率为C3摄像头下的87.47%,采用多视角进行视角信息融合然后识别时,最好的识别率分别为88.61%、89.77%、91.04%、91.49%、92.31%、93.87%、94.82%。可以看出,多视角识别率远远高于单视角识别率,而且随着用作训练数据的视角越多,人体行为识别率越高。原因是用作训练数据的视角越多,则共识矩阵V*包含的不同视角信息越丰富,对视角改变愈稳定。所提方法的识别率为94.82%,高于FV/Bowv结合稀疏编码方法的93.28%、92.56%。因为从不同的摄像机视角记录特定的动作时,动作外观完全不同,最终也会得到完全不同的FV/Bowv底层特征,这将会降低人体行为识别率,而时空矩阵由时空特征向量之间的欧氏距离表示,随着视角改变变化较小,同时,多视角非负矩阵分解算法进一步挖掘了不同视角下时空矩阵共享的相似稳定结构,使得最终得到的特征对视角改变具有很强的鲁棒性。所提方法的性能略低于GM-GS-DSDL方法,因为GM-GS-DSDL一方面利用图集算法融合不同视图,去除重叠兴趣点,探究其一致性属性,另一方面构建了判别结构化字典发现多个视图之间的潜在相关性。由表1可以看出利用时空特征向量之间的欧氏距离表示的时空矩阵结合多视角非负矩阵分解能很好地融合多视角信息,进行多视角下人体行为识别,识别率达到94.82%。
5.1.2 不同非负矩阵分解方法对识别的影响
为了验证本文多视角非负矩阵分解方法的优越性,分别使用非负矩阵分解(NMF)、局部非负矩阵分解(LNMF)、稀疏非负矩阵(SNMF)以及凸非负矩阵分解算法(CNMF)分解所有视角下的时空矩阵,由5.1.1小节可知使用所有视角的信息进行训练时拥有最高的人体行为识别率,结果如表2所示,多视角非负矩阵分解方法性能远优于其他非负矩阵分解方法。因为MultiNMF算法通过对多视图进行因式分解得到了不同视图共享的一致性结构,即共识矩阵V*,其对视角改变具有很好的鲁棒性;而其他NMF方法提出的传统标准化策略要么难以优化求解,要么不能产生有意义的一致性结构,使得不同视图的融合变得困难。

表2 不同非负矩阵方法对识别的影响
5.1.3 与其他方法比较
本文通过交叉验证方法测试WVU数据集得到每个动作的详细识别率,从而验证提出方法的有效性。本文方法整体识别率为94.82%。表3中对单挥手、慢跑、捡行为具有100%识别率,打保龄球行为识别率最低,为87.50%。因为打保龄球行为容易与捡、投行为混淆。
从表4可以清晰地看出本文提出的方法总体识别率高于其他多视角方法,准确率达94.82%。在关键帧提取部分,虽然K-means具有收敛速度快的优点,但得到的聚类中心并非为最佳聚类中心,而免疫原理中学习率确定系统搜索抗原的方向,这种启发式的搜索方法,可以寻找到比K-means方法更接近于全局最优的解,因此利用免疫原理对K-means结果进行优化,在某种程度上,人工免疫聚类算法提高了收敛速度,形成了更稳定的类,提高了对原始视频提取关键帧的准确性,则由关键帧构成的时空矩阵能更精确地描述一个行为。其次时空矩阵在不同视角下的稳定性以及基于多视角非负矩阵分解构建的多视角目标函数,使得得到的行为特征对视角变化具有很强的鲁棒性,提高了行为在多视角下识别准确率。另外,对本文方法的计算复杂度在WVU数据集上进行测试,统计6种方法分别在数据集中计算平均时间。从表4中可以看出文献[11]计算时间长,因为GM-GS-DSDL一方面使用了图集算法,另一方面构建了判别结构化字典,消耗大量时间;文献[12]并未对原始视频提取关键帧,导致计算量庞大;文献[13]中,Fisher向量的计算复杂度大于词袋模型的计算复杂度,所以前者消耗时间较长。所提方法提取了关键帧,大大减少了需要处理的视频帧数,并且利用多视角非负矩阵方法分解时空矩阵,计算简单有效,因此计算速度较快。

表3MVU数据集的混淆矩阵 %

图2 i3Dpose数据集实例(跑步、弯腰)
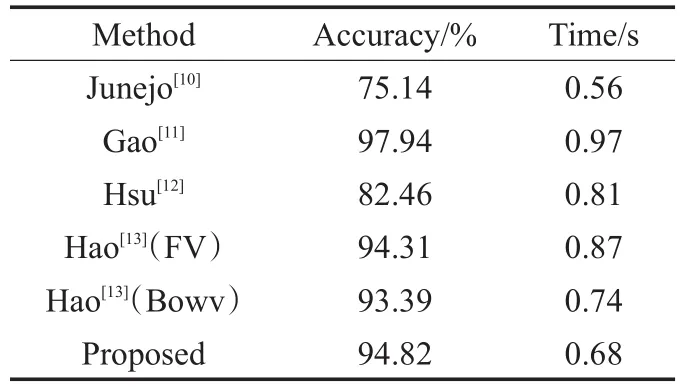
表4 与其他方法比较结果
5.2 i3Dpose数据集
在i3Dpose数据集上对本文方法进行了测试。该数据集包含了12种不同行为的视频,其中包括6种单一行为,分别是走、跑、向前跳、原地跳、弯腰、单手挥,4种混合行为,分别为坐下-起立、走路-坐下、跑步-下落、跑步-跳-走路,2种交互行为,两人招手与推人,每一个行为由8人执行8台摄像机记录,摄像机记录角度如图2 C1~C8所示。i3Dpose数据集不仅包括了单一行为,还包括了混合行为以及交互行为,后两者行为识别难度大于单一行为识别难度。
5.2.1 不同视角融合方法对识别的影响
在i3Dpose数据集上,同样改变多视角信息融合方法并与本文方法进行对比。由表5可知,正视角C6拥有最高单视角识别率;所有视角融合具有最高多视角识别率。所提方法性能优于其他视角融合方法,原因在5.1.1小节有详细阐述,但低于在WVU数据集上的表现。因为i3Dpose数据集有混合行为以及交互行为,混合行为难以确定有效的关键帧;对于交互行为,本文没有建立多个目标之间的复杂交互模型,也没有对交互区域有效地提取运动特征,因此识别准确率较低。
5.2.2 不同非负矩阵分解方法对识别的影响
本文同样使用不同的非负矩阵分解算法对时空矩阵进行分解,进行对比的非负矩阵分解算法与5.1.2小节相同。结果如表6所示,MultiNMF明显优于其他非负矩阵分解算法,因为MultiNMF能有效提取出不同视角下时空矩阵的一致性结构。
5.2.3 与其他方法比较
表7给出了i3Dpose数据集的混淆矩阵。本文方法整体识别率为88.68%,其中单一行为识别率明显高于混合行为以及交互行为,因为混合行为难以确定关键帧;对于交互行为,没有对实施交互行为的主体之间建立交互模型,同时也没有对交互区域进行有效特征提取。表8给出了在i3Dpose数据集上与其他方法比较的结果,所提方法在人体行为识别准确率上以及复杂度计算上优于其他先进方法。因为i3Dpose数据集存在混合行为以及交互行为,其在视频大小与视频内容上比单一行为视频更加丰富、复杂,提取关键帧难度增加,所以在i3Dpose数据集上所用时间增长。

表5 i3Dpose数据集上不同视角融合方法对识别的影响
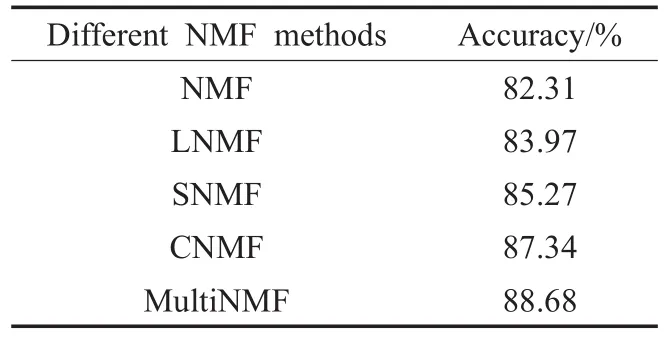
表6 不同非负矩阵方法对识别的影响
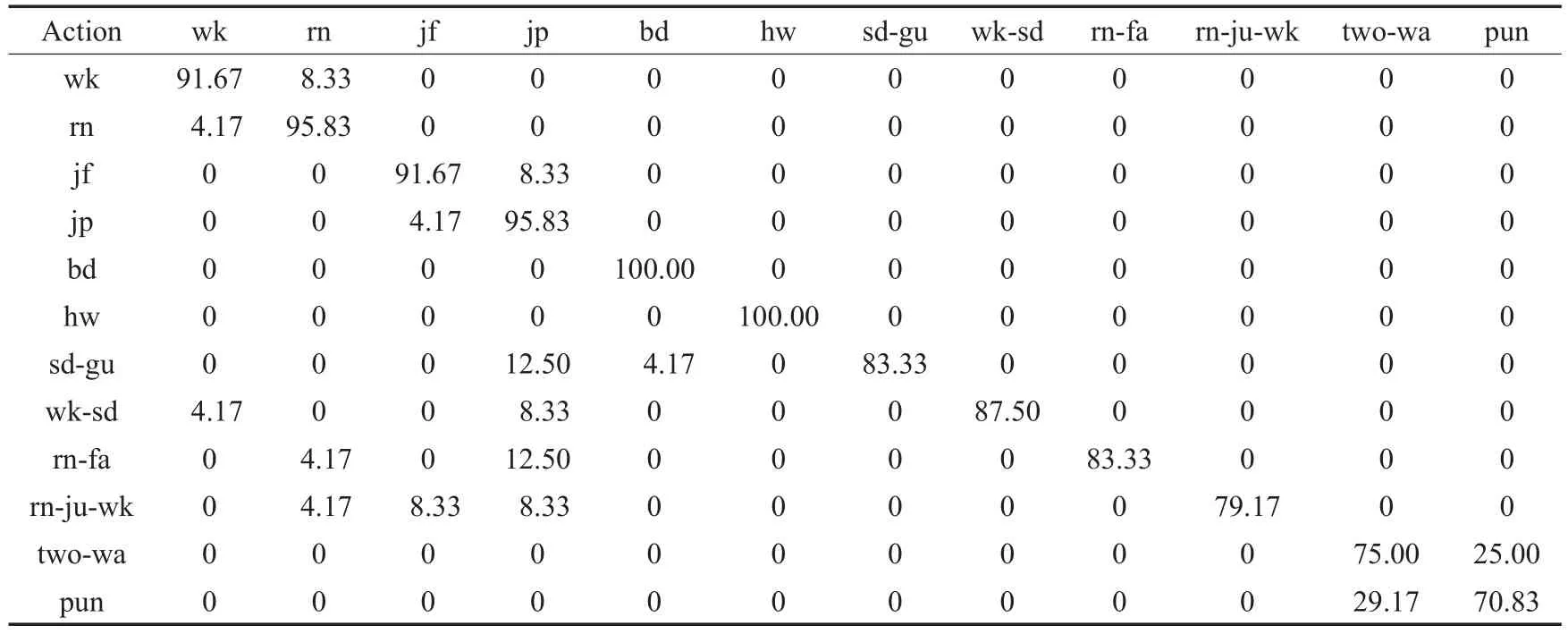
表7 i3Dpose数据集的混淆矩阵 %
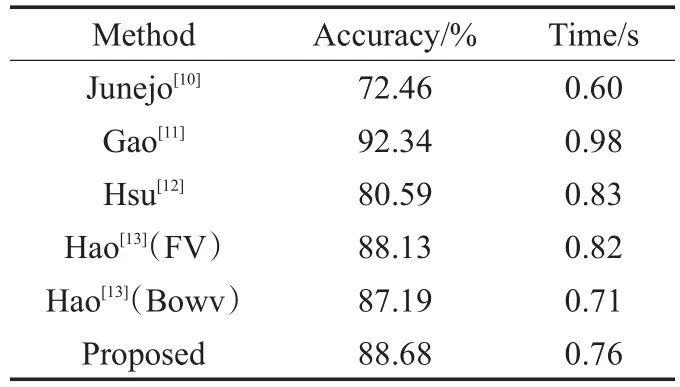
表8 与其他方法比较结果
6 结论
本文提出了一种基于时空矩阵和多视角非负矩阵分解的多视角人体行为识别方法。主要工作如下:
(1)为了去除视频冗余帧提高计算性能,利用人工免疫聚类算法提取视频的关键帧。
(2)联合不同视角下相同动作的时空矩阵进行多视角非负矩阵分解得到的共识矩阵,减小了视角变化对同类动作产生的差异性;与其他多视角方法相比,本文方法不需要重建三维模型,也不需要对不同视角之间的关系进行计算。
(3)在WVU、i3Dpose数据集上利用本文方法与已有方法进行了对比实验,结果表明该方法具有更高的识别精度。
