电子医疗下支持数据持有性验证检索方案
2018-08-20陈彦萍
李 梁,谭 薇,陈彦萍
LI Liang1,TAN Wei2,CHEN Yanping3
1.西安邮电大学 无线网络安全技术国家工程实验室,西安 710121
2.西安交通大学 网络中心,西安 710049
3.西安邮电大学 计算机学院,西安 710121
1.National Engineering Laboratory for Wireless Security,Xi’an University of Posts and Telecommunications Xi’an 710121,China
2.Network Center,Xi’an Jiaotong University,Xi’an 710049,China
3.School of Computer Science and Technology,Xi’an University of Posts and Telecommunications,Xi’an 710121,China
1 引言
电子医疗(E-health)[1-3]系统这一术语最先由Mitch-ell于1999年提出[4],该系统是电子信息技术与通信技术的完美体现,能实现医疗电子资源的存储、检索以及传输等功能。科学水平的不断发展,电子医疗系统的应用也越来越受到人们的广泛关注。电子医疗系统中存储着大量的患者电子病历,这些病历能够被各大医疗机构检索及参考;其次,像电子病历这样重要数据的缺失可能会导致误诊以及重复用药等医疗事故。因此,电子医疗系统的发展,伴随着众多安全问题的出现。
电子病历数据与传统纸质病历有着很大的不同,电子化病历容易被复制、共享、窃取以及修改等。波耐蒙研究所于2015年发布的《第五届医疗数据隐私与安全研究报告》显示,在美国超过90%的医疗机构存在数据泄露情况,40%的公司在过去两年内至少发生了5次数据泄露[4]。一旦患者知道自己的隐私被泄露,其对信息收集者的信任程度将大大降低。例如,当患者意识到电子医疗记录存在较高的隐私风险时,便会抱有抵制态度,比如在电子医疗记录中只提供有限的敏感信息,而这样很可能会妨碍就医的诚实性和医疗服务机构为患者提供最佳的治疗。
因此,如何有效保护电子病历数据的隐私性,如何有效保证云端电子病历的完整性便成为急需解决的问题。现如今有很多方案被提出应用于电子医疗环境中。例如,2009年Al-Neyadi等人[5]提出了电子医疗系统中基于内容的访问控制方案,利用该方案实现了对电子病历的访问控制,但该方案未能提供对电子病历的检索技术,未能实现对云端电子病历的持有性验证;2015年Yang等人[6]提出了电子医疗下基于属性的关键字检索方案,该方案利用基于属性的加密技术实现了云端电子病历的权限控制;2017年Yang等人[7]提出了电子医疗系统下可靠、可检索的隐私保护方案,但该方案依旧未能实现对云端电子病历的持有性验证。
而本文提出的电子医疗环境下支持数据持有性验证的数据检索方案是将支持数据持有性验证功能与传统可搜索加密系统结合,实现了功能上更加完全的数据检索系统。传统的数据支持性验证方案多种多样,例如,陈兰香[8]于2011年利用同态Hash给出了一种基于Hash函数同态性的数据持有性验证方案,但该方案无法检测服务器是否存在欺骗行为,安全性不高。而黄石等人[9]于2015年针对陈兰香的方案进行了改进,最终能够检测出服务器的行为。而本文方案中将编码理论知识与同态Hash函数相结合,提出了编码Hash函数实现了数据持有性验证功能,并将该功能应用于云环境下的数据检索系统中。
基于上述各方面因素考虑,本文提出了一种电子医疗环境下支持数据持有性验证的数据检索方案。本文方案主要完成了以下几个目标;(1)利用基于属性加密技术实现了云端电子病历的细粒度权限控制,将电子病历的权限进一步细化,同时方案安全性有所提高;(2)将编码相关知识与Hash函数相结合,提出了编码Hash[10-11]并应用于数据持有性验证中,据理论分析以及实验仿真分析,相对于其他相关方案均有较大的安全性以及性能优势;(3)利用编辑距离,实现了容错多关键字检索功能。
2 预备知识
2.1 双线性对
定义1(双线性对)定义G1和G2是素数阶为p的循环群,g是G1的生成元,运算e:G1×G1→G2映射拥有下面的3个性质。
(1)双线性:e(ga,gb)=e(g,g)ab,a,b∈ZP;
(2)不可退化性:存在x,y∈G1使得e(x,y)≠1;
(3)可计算性:对于所有的x,y∈G1,存在一个有效的算法可计算e(x,y)。
2.2 特权树
本文方案通过特权树来描述每一种特权,该树的每个非叶子结点是一个阈值门,每个叶子结点通过一个属性描述。本文所提及的特权类似于操作系统中的特权。每一份数据文件包含有几种可操作的行为,根据不同的资格条件,每种特权可以被赋予不同权限的用户。比如,{read_mine,read_all,delete,modify,create}是一个学生成绩的特权集合,只有该学生本人及其老师可以读该学生的成绩,但是所有其他的特权只能被授权给该老师,因此需要将{read_mine}这个特权授予该学生和其老师。
每种可执行操作均与某种特权p相关,而这个特权p是由一特权树Tp描述的,如果一个用户的属性满足该特权树Tp,那么该用户便被授予该特权p。这样不仅控制了文件的访问权限,而且还控制其他可操作行为,使得文件的控制更加细粒。
为了验证用户的身份并赋予其相应的特权,每份数据文件中包含有几种特权树。假如有r种这样的特权树,这就意味着有r种不同的特权。特权0可以被定义为读文件,其他特权可以被任意地定义。当m>n时,这并不意味着第m种特权比第n种特权的权限大。该特权树与文献[12]中所定义的类似。给定一个特权树,如果numx是结点x的孩子结点的数量,kx是x的阈值且0<kx<numx,如果至少有kx个孩子结点被赋值为真,那么该结点将被赋值为真。在特别情况下,当kx=1时,该结点便成为了OR门;当kx=numx时,该结点便成为了AND门。
如果用户的属性集合S满足特权树Tp或者是结点x,便定义Tp(S)=1或x(S)=1。Tp(S)可以通过以下递归算法计算得出。如果x是叶子结点,当且仅当att(x)∈S时,x(S)=1;如果x是非叶子结点,当结点x至少有kx个孩子结点返回1时,则x(S)=1。对于特权树Tp的根结点Rp来说,只有当Rp(S)=1时,Tp(S)=1。
2.3 编辑距离
编辑距离[13]是两个字符串之间相似度的测量。比如两个单词w1和w2的编辑距离ed(w1,w2)指的是一个单词变换成另一个单词所执行的最小操作步骤。这其中包含3个基本操作。
(1)置换:将一个单词中的字符变换成另一个。
(2)删除:从一个单词中删除一个字符。
(3)插入:将单个字符插入到一个单词之中。
给定一个关键字w,如果对于一个确定的整数d,使得ed(w,w′)<d满足,则用Ww,d表示关键字w′的集合。
2.4 编码Hash
传统Hash函数将任意长的消息映射成一个固定长度的摘要,其Hash函数是基于传统压缩函数构造而成的,而利用校验子译码问题构造出的编码Hash具有特殊的内部结构,Augot等在文献[14]中提出了编码Hash,且对该种编码Hash的内部结构进行了详细的讲解。
选择一个(n,k)纠错码,同时选择正整数ω使得ω可以整除n,将所有长度为n的码字等分为ω个块,每块有比特。该码的校验矩阵H是一个(n-k) ×n矩阵,同样将H等分为ω个子矩阵,H=(H1,H2,…,Hω),子矩阵表示为Hi。压缩函数F定义为:→,其中,则F的输入数据。压缩函数F的运算过程如下:
(1)将e bit输入数据x等分为ω个子块,即x1,x2,…,xω,每个子块xi包含比特,且
(2)将每个xi转换为0到之间的整数xi。
(3)选择相应的子矩阵Hi的第xi+1列,表示为
(4)将选好的ω个列累加,获得一个长为r的比特串,就是F的输出,即计算
上述说明了一次压缩过程,如图1所示为消息m的压缩过程。每次从消息m中选取e-r位输入,其次首轮随机选取r位填充数据,组合成e位的数据作为压缩函数的输入,经过压缩F函数后输出r位数据。接下来,输出的r位数据返回填充到输入中,直到将整个消息m压缩输出为r位数据,此r位数据为该消息m的Hash值。
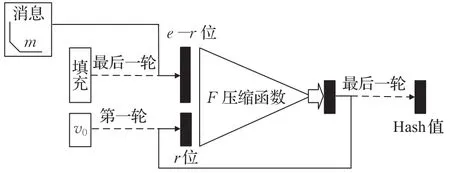
图1 编码Hash函数结构
3 方案介绍
3.1 系统模型
如图2所示为方案系统模型,该系统模型中包括授权中心、数据拥有者、数据使用者以及云服务器4个实体,数据拥有者以及数据使用者可以是医疗患者或医疗组织结构。
(1)授权中心:为了保护数据用户的隐私安全,本文方案采用多个授权中心为用户生成属性私钥,每个授权中心获得用户部分属性并独立运算生成部分属性私钥,最终将各部分属性私钥组合成某个用户的属性私钥SKu。
(2)数据拥有者:数据拥有者具备两方面的作用。
①文件上传:首先数据拥有者向授权中心请求获得属性私钥SKu,并利用对称加密算法(例如AES等)以及对称密钥Ke,加密数据文件F,生成文件密文C。其次,数据拥有者利用属性私钥SKu加密对称密钥Ke,生成对称密钥密文CT,同时数据拥有者在该密文中指定文件F的特权集合{Tp}p∈{0,1,…,r-1} ,其中p表示该文件的某种特权,r表示该文件包含的特权个数。接下来数据拥有者利用文件关键字集合生成搜索索引FI。最终数据拥有者将密文C、密钥密文CT以及索引FI上传至云服务器。
②数据持有性验证:数据拥有者将加密后的密文集合上传至云服务器前,对每个密文数据文件Cf利用编码Hash函数生成数据标签Tagf。数据拥有者进行数据持有性验证时,向云服务器随机挑战数据块,由云服务器计算相应的数据块标签Tagf'并返回给数据拥有者,判断Tagf与Tagf'是否相同,完成数据持有性验证。
(3)数据使用者:数据使用者输入搜索关键字集合,生成搜索请求符号发送给云服务器,云服务返回相应请求文件,验证用户身份,解密获得相应文件,获得文件的相应特权。
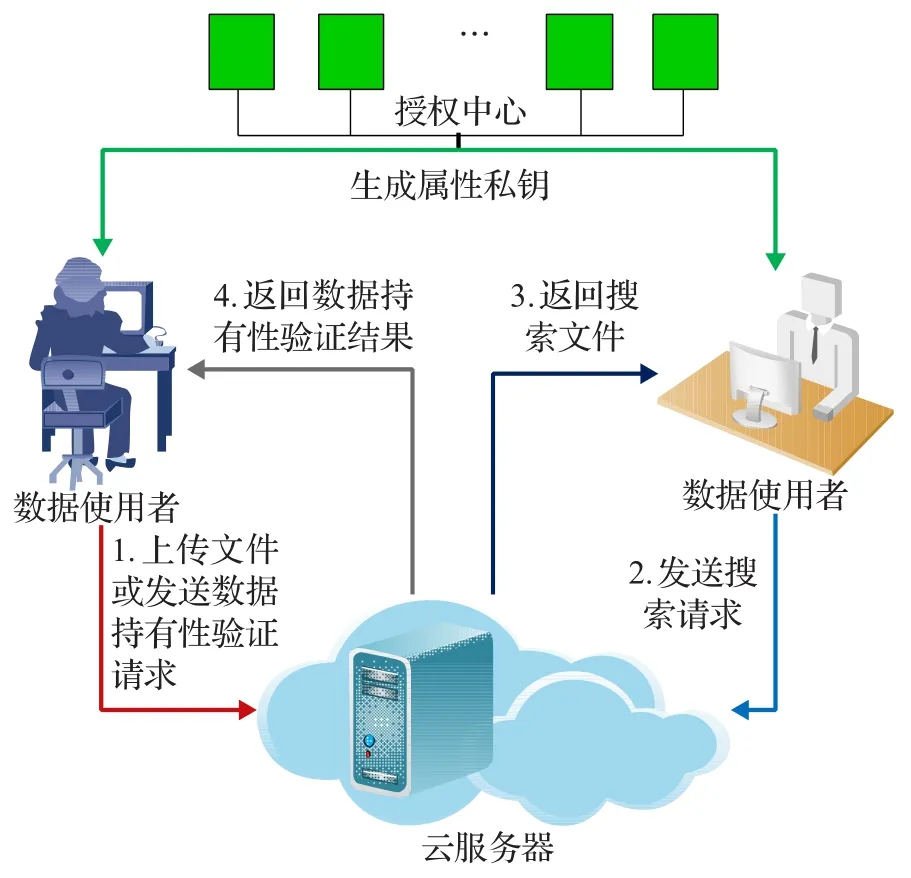
图2 系统模型
3.2 方案目标
电子医疗系统下支持数据持有性验证方案的设计目标主要包括以下几点:
(1)支持多个关键字容错搜索。文中将关键字集合首先进行预处理,生成关键字与文件集合相对应的二维索引表格;将输入的关键字经过编辑距离处理后查找二维索引表获得相应文件。
(2)利用编码Hash函数支持数据持有性证明,数据拥有者随时可以验证系统中数据的完整性。
(3)提供了对该医疗系统中病历数据的细粒度权限控制,明确了用户对文件数据的查看、修改等权限控制,使得病历数据的使用更加安全。
3.3 安全模型
本文方案首先假设N个授权中心对用户的身份信息感兴趣,各自会独立获取用户的身份信息,但授权中心不会与其他用户或者授权中心合谋,因为授权中心可能会接受政府等部门的监管。假设用户不可信,假设网络环境安全,依据上述假设环境,定义下面的安全模型。
Init:敌手A声称某几个授权中心在它的控制之下(但至少有两个授权中心不在敌手控制中),同时宣称它想挑战特权T0,该特权树中某些属性也包含在挑战者所控制的授权中心之下。
Setup:敌手与挑战者启动系统建立。
Phase1:敌手开始执行Key Generate算法查询,用于尽可能多地获得他想要的私钥,但这些私钥不满足特权树T0。
Challenge:敌手提交两个长度相等的消息M0和M1给挑战者,挑战者随机地抛掷硬币b∈{0,1},利用特权树T0加密消息Mb,随后将密文发送给敌手。
Phase2:Phase1可以被适当地重复执行,但没有私钥能够满足特权树T0。
Guess:敌手猜测并输出Mb′。
定义2对于所有的概率多项式时间敌手,如果其在上述游戏中无法获得不可忽视的优势,则说明该方案是安全的。
4 电子医疗系统下支持数据持有性验证方案
4.1 基本定义
电子医疗系统下支持数据持有性验证方案包括N个授权中心、数据拥有者、数据使用者以及云服务器4个实体。
定义3该系统中包含4个实体,每个实体包含以下算法过程:
(1)N个授权中心
①Setup(1l)算法:该算法为系统建立算法,输入安全参数1l,输出授权中心Ak的主密钥MKk以及整个系统的公钥PK,这里的k表示第k个授权中心。
②User Key Generate(PK,MKk,Αu):输入授权中心Ak的主密钥MKk、整个系统公钥PK以及用户u的属性集合Αu,输出用户的属性私钥SKu。
(2)数据拥有者
①GenerateT(Αu):输入用户u的属性集合Αu,输出特权树权限集合{Tp}p∈{0,1,…,r-1},这里的r表示特权个数。
②Encrypt(PK,Ke,{Tp}):输入系统公钥PK,对称加密密钥Ke以及特权树集合{Tp}p∈{0,1,…,r-1},输出密文CT。
③GenerateFI(W):输入关键字文件集合W,输出文件搜索索引FI。
④GenarateTag(C):输入密文文件集合C,输出数据持有性标签Tag。
⑤DataHoldCheck(i):输入随机数i∈Z,返回文件标签Tag′。
(3)数据使用者
①FileSearch(Keywords):输入关键字集合Keywords,获得搜索结果CT以及C。
②Decrypt(PK,SKu,CT):输入系统公钥PK、用户属性私钥SKu以及CT,输出对称密钥Ke。
(4)云服务器:云服务器主要存储用户的密文文件并提供一定的计算服务,例如利用编码Hash函数生成用户的数据标签Tag。
4.2 方案具体算法过程
本节将会按照定义1中算法过程对整个方案的具体算法详细说明。
(1)N个授权中心
①Setup(1l):任意一个授权中随机选择一个素数阶为p且生成元为g的双线性群G0并将其公开。随后所有授权中心各自独立且随机地选择vk∈Zp,同时计算Yk=e(g,g)vk并将其发送给其他所有授权中心,这些授权中心单独计算
然后,每一个授权中心Ak随机选择N-1个整数skj∈Zp(j∈{1,2,…,N}{k})并计算gskj,并将gskj与其他授权中心Aj共享。当接收到由Aj生成的N-1个gsjk后,授权中心Ak按照如下运算计算安全参数xk∈Zp:

②User Key Generate(PK,MKk,Αu):对于任意属性i∈Αu,每一个授权中心Ak随机选择ri∈Zp并单独地计算部分属性私钥将其秘密地发送给用户u。
接下来,每一个授权中心Ak随机选择dk∈Zp,并将其与其他授权中心共享,但对用户保密。然后,每个授权中心秘密将xk⋅gdk发送给用户u。任意一个授权中心计算,并将其发送给用户u。
因此,该用户计算属性i∈Αu的部分属性私钥为:

当用户u获得D、Di和Di'后,则该用户u的属性私钥为:
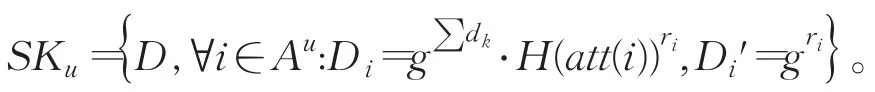
(2)数据拥有者
①GenerateT(Αu):该算法根据用户的属性集合Αu生成特权树权限集合该特权树权限集合根据2.2节中的原理过程生成。
②Encrypt(PK,Ke,{Tp}):在该算法过程中,采用Shamir的秘密分享技术构建特权树。在特权树Tp中存储某个随机数s∈Z,利用此随机数掩饰对称密钥Ke。采用Shamir的秘密分享技术将此随机数分享至叶子结点。具体过程如下:
对于每一个特权树Tp,对该树中的每一个结点x选择一个多项式qx,设置多项式qx的次数为dx,且比该结点中的阈值kx少1。从根结点Rp开始,随机选择sp∈Zp,并设定qRp(0):=sp且随机设置多项式qRp的其他系数。对于其他结点x,对应多项式的系数随机选择,但其常数项设置为qparent(x)(index(x)),使得qx(0)=qparent(x)(index(x)),这里的index(x)是结点x的孩子结点的索引,parent(x)是结点x的父结点。最终,选择一个随机数h∈Zp,使得h-1模上p存在,进而计算gh⋅sp和Dh-1,则密文CT可以表示为:

③GenerateFI(W):对于关键字集合 {w1,w2,…,wm},生成文件搜索索引的具体算法如下:
对于每一个wj∈W的关键字,数据拥有者计算其索引最终获得关键字集合索引FI=
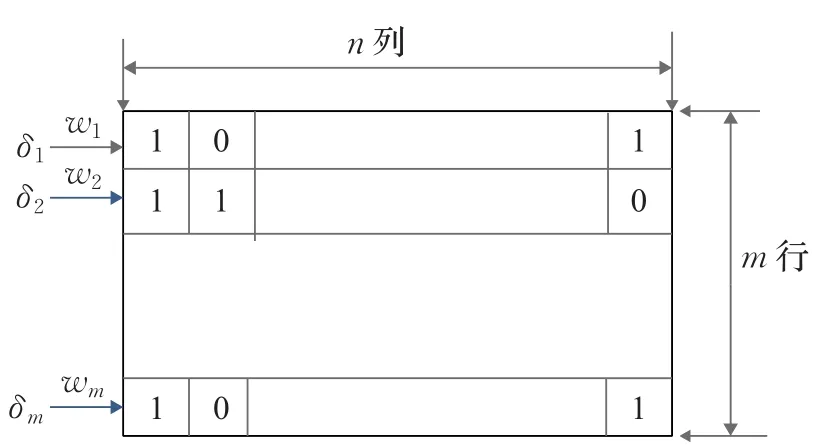
图3 索引矩阵δ
④GenerateTag(C):对于明文文件集合F={f1,f2,…,fn},采用对称加密算法以及对称密钥Ke加密生成密文集合C={c1,c2,…,cn},对于每一份密文ci,利用编码Hash函数生成对应的数据标签Tagi。例如,根据2.4节中定义的压缩过程,采用(8,5)的编码,ω=4,输入的数据位长度为e=4,返回的数据位长度为r=3。若待压缩的消息为(10110010101),最终压缩后消息为(101),则该消息(10110010101)压缩后的标签最终生成的标签集合为
⑤DataHoldCheck(i):该算法为数据拥有者的持有性验证过程。数据拥有者随机向云服务器挑战一个密文文件,云服务器将对应的密文ci返回给数据拥有者,数据拥有者利用GenerateTag(C)算法生成数据标签Tagi',并验证Tag=?Tagi',若相等,则说明数据持有性通过;否则,验证失败。
(3)数据使用者
①FileSearch(Keywords):当数据使用者输入搜索关键字集合,生成关键字索引集合并发送给云服务器。
②Decrypt(PK,SKu,CT):获得搜索后的密文C和CT后,数据拥有者通过特权树验证,解密CT获得对称密钥Ke,进而解密文件密文C,获得响应明文信息。
系统每个用户可以根据关键字搜索并下载云服务器上的密文,但是只有在成功解密密文文件之后,才可以对文件作相应的操作。首先,定义一个递归的解密算法DecryptNode(CT,SKu,x),这里的x代表特权树Tp中的某个结点。如果这个结点x是叶子结点,便让i成为结点x的属性并进行如下定义。
如果i∈Αu:

如果i∉Αu,便定义DecryptNode(CT,SKu,x):=⊥。如果x不是叶子结点,该算法将按如下过程进行:对于x的所有孩子结点z,调用算法DecryptNode(CT,SKu,z)并将输出Fz存下来。定义Sx是孩子结点z中任意一个包含kx个孩子结点的集合,使得Fz≠∅,如果没有这样的集合存在,那么这个结点将不满足,算法便返回⊥。否则,计算出Fx:

这里的d=index(z),Sx'=index(z)。
通过计算多项式的系数和p(0),使用多项式插值法可恢复出父结点的值。用户从云服务器下载了密文文件之后,从特权树Tp的根节点Rp开始,迭代地调用该算法,如果这个树被验证通过,就意味着该用户被赋予了特权p,于是:

当用户试着去阅读该文件时,通过下面的式子可以将解密密钥Ke恢复出来:

最终,通过该解密密钥,密文文件便可以被解密出来,如果用户需要对数据文件执行其他操作,那么该用户首先需要被验证是具有该操作的一个已授权用户。如果该操作需要第j种特权,那么该用户需要从特权树Tj的根结点Rj开始,迭代调用DecryptNode(CT,SKu,x)算法,得到。用上面同样的方程式可以获得Ysj,用户将Ysj和操作请求一同发送给云服务器,云服务器将会检查是否Ysj=Ej,这里的Ej∈并存储在云服务端,用于云服务端权限验证。
(4)云服务器
5 方案分析
5.1 安全性分析
(1)该方案能够抵抗授权中心的合谋攻击。
本文所设计的系统中,利用N个属性授权中心生成用户属性私钥。每个授权中心Ak生成一个随机的秘密参数集合,并通过安全通道将gskj与其他授权中心共享,而xk正是基于这些参数计算得来的。人们知道在素数阶为p的群G0上,DDH问题是难解的,因此gskj不会泄露关于skj的任何统计信息。这意味着即使一个敌手危害了N-2个授权中心,依旧有两个参数skj敌手无法知道。这个敌手无法猜到这个有效的参数,进而他无法构造一个有效的密钥,因此该方案能够忍受N-2个授权中心的合谋攻击。
(2)该方案能够有效保护用户的身份隐私安全,能够实现半匿名性。
定理1对于定义1的安全游戏,如果存在一个敌手以不忽略的优势赢得了该安全游戏,则至少存在一个概率多项式时间算法以不可忽略的优势解决DBDH困难问题。
证明 假设在本文方案中,一个概率多项式时间敌手的优势是ε,接下来将会证明能够以ε/2的优势解决DBDH困难问题。
设定e:G0×G0→GT是一个双线性映射,这里的G0是一个素数阶为p,生成元为g的乘法群。首先挑战者抛掷一个二元硬币u,如果u=0,则挑战者设定。否则设定这里的a,b,c,κ∈Zp,且是随机选取的。于是挑战者将给模拟者simulator,在接下来的DBDH游戏中,simulator扮演者挑战者的角色。
Init:攻击者A控制着受到危害的几个授权中心但系统中至少有两个授权中心没有被控制,剩下的授权中心被模拟者simulator控制,攻击者接下来宣称它打算挑战特权树T0,在该特权树中的一些属性被simulator所控制的授权中心掌握着。
Phase1 :对应于属性集合Α1,Α2,…,Αq,攻击者尽可能多地请求它想要的密钥,而这些属性集合被控制着,但它们均不满足特权树T0。当模拟者收到这些密钥请求后,将会计算私钥的响应组成部分,来回应攻击者的请求。对于所有的属性i∈Au,模拟者会随机选择ri∈Zp,并计算Di:=A⋅H(att(i))ri,Di':=gri。最终,模拟者将生成的私钥返回给攻击者。
Challenge:敌手向挑战者提交两个挑战消息m0和m1,挑战者抛掷一枚硬币γ随机选择mγ,并将其密文返回给敌手,消息mγ加密后的密文如下:

如果u=0,Z=e(g,g)abc以及之前已设定a=∑dk,以及Di=因此,CT*是消息mγ有效的密文,Di是用户私钥有效的组成部分。否则,如果u=1,Z=e(g,g)κ,于是就有E0=mγ⋅e(g,g)κ。因为κ∈Zp上的一个随机元素,则从敌手的角度来看,E0是群GT中的一个随机元素,因此密文CT*中没有包含关于mγ的任何信息。
Phase2:适当重复Phase1。
Guess:敌手提交关于γ的一个猜想γ′。如果γ′=γ,则模拟者simulator输出u′=0,这样意味着敌手给出了一个有效的DBDH元组;如果u′=1,意味着敌手给出了一个随机的五元组(g,A,B,C,Z)。
根据之前定义的游戏规则,模拟者simulator会按照算法方式计算公共参数以及私钥。如果u=1,则敌手将不会学习到关于γ的任何信息,因此有当γ′≠γ时,模拟者simulator输出他的猜想u′=1,因此有如果u=0,敌手会得到关于mγ一个有效的密文,根据定义,在这种情况之下敌手的优势是ε,因此有因为当γ′=γ时,模拟者给出了他的猜想u′=0,于是有则在该DBDH游戏中全部的优势为:

总结,如果一个多项式时间敌手在这个安全游戏中的优势为ε,那么在DBDH游戏中一个概率多项式时间敌手的优势为。因此,如果在这个安全游戏中,一个敌手拥有不可忽略的优势为ε,那么他将拥有不可忽略的优势去解决该DBDH游戏。因此,该安全性满足定义2的安全性。
(3)编码Hash安全性分析
安全性方面,该方案中编码Hash的安全性依赖于这样一个NP完全问题,输入有限域Fq上的一个(n-k)×n矩阵H,向量整数k>0,是否存在一个字其重量w(x)≤k,使得HxT=s。
文中得出结论,由于编码Hash的压缩函数是使用一个纠错码的校验矩阵构造的,且Hash函数FH的输出相当于计算一个(n,ω) 正则字的校验子,该编码Hash的安全性可以归约为校验子译码问题(SD)问题,且该校验子译码问题已经被证实属于NP完全问题,可有效抵抗目前的量子攻击,因此对其压缩函数求逆是几乎不可能的,从而该方案具有更高的安全性。
5.2 性能分析
本文提出了一种电子医疗下支持数据持有性验证检索方案,主要从密文检索以及数据持有性验证两方面说明本文方案的性能优势。
5.2.1 密文可搜索性能分析
密文可搜索实验平台的搭建主要依靠JPBC(Java Pairing-Based Cryptography Library)开源代码库以及Java开发平台Myeclipse 2014。关于JPBC有以下三方面的知识:
(1)JPBC是PBC(Pairing-Based Cryptography Library)的一个子库,利用该库可以直接利用Java语言进行双线性对的基本运算操作。
(2)利用该库可以直接将双线性对的运算外包给PBC库。
(3)该库是关于整数上的多重线性映射的一个实现,该实现支持多线程。
总之,JPBC是密码学研究中非常重要的工具之一。如下是本实验仿真运行的操作系统配置信息。
(1)电脑型号:联想ThinkPad T450s笔记本电脑;
(2)操作系统:Windows 10专业版64位;
(3)处理器:英特尔Core i7-5600U@2.60 GHz双核;
(4)内存:12 GB(三星DDR3L 1600 MHz)。
此次系统采用的文件数据集来自于中国知网上的期刊论文,根据前期计划,本次总共在中国知网上收集了3000份不同的期刊论文,同时为了增强本次实验的有限性,通过修改期刊名称以及关键字,将期刊论文集合一共拓展为12000份。本文主要对密文可搜索系统的系统建立、属性私钥生成以及安全索引生成与文献[15]、文献[16]进行了效率对比分析。
(1)系统建立阶段
图4所示为系统建立效率对比,从图中可以发现,本文方案在系统建立上具有较大的时间效率优势。
(2)属性私钥生成阶段
图5所示为属性私钥生成效率对比图,从图中可以发现,随着用户属性个数的增加,用户属性私钥的生成时间对比文件文献[15]和[16]具有较大的性能优势。
(3)安全索引生成阶段
图6所示为安全索引生成效率对比,从图中可以发现,随着关键字个数的增加,安全索引生成的效率优势越来越明显。

表1 方案效率对比分析

图4 系统建立效率对比
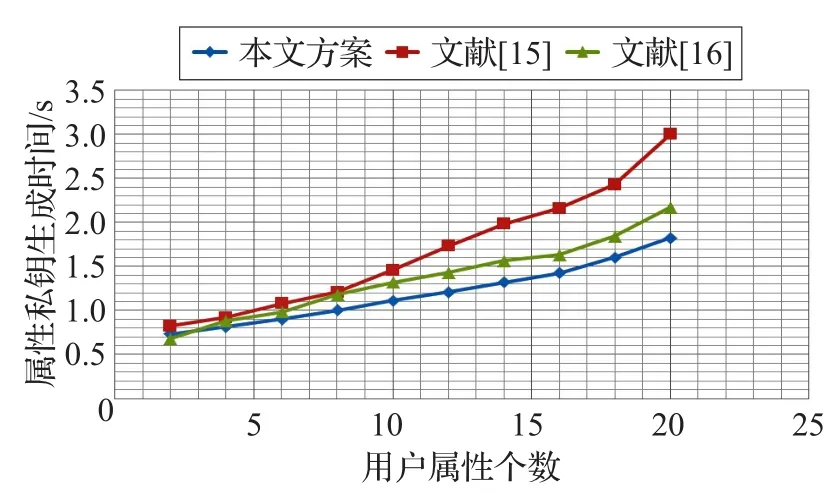
图5 属性私钥生成效率对比

图6 安全索引生成时间效率对比
5.2.2 方案各个阶段效率对比
为了更好地说明本文方案的效率,通过实验仿真将本文方案相关运算阶段与相关云存储下的数据检索方案进行了对比。如表1所示,通过进行系统建立、属性私钥生成、安全索引生成、特权树建立等阶段进行了对比说明。该表中说明本文方案在系统生成、安全索引生成、加密以及解密阶段均有较好的优势;本文方案支持文件特权控制以及数据持有性验证功能,而文献[15]和[16]不支持。
5.2.3 编码Hash函数效率分析
如表2所示是编码Hash函数的数据压缩时间开销对比,由于采用的纠错码的能力不一样,输入每比特数据的时间开销不一样,根据以上3种时间开销对比,当纠错码码长为n=1024时,每比特的平均时间开销最小。

表2 平均压缩时间对比
5.2.4 数据持有性相关方案效率对比分析
本文所提方案中基于编码Hash函数的数据持有性验证功能是本文的创新点,为了更好地说明该数据持有性的验证效率,将本文方案与相关数据持有性验证方案进行了对比。如表3所示,本文方案在数据持有性验证上有明显的效率优势。

表3 数据持有性验证效率对比
6 结束语
基于属性加密以及编码Hash相关知识,本文方案提出了一个电子医疗环境下支持数据持有性验证的数据检索方案。通过构造特权树,实现了对隐私文件的细粒度控制;通过编辑距离以及相关安全索引,实现了容错多关键字搜索;通过编码Hash,实现了数据持有性验证。通过一定的安全分析以及实验性能测试,说明本文方案具有一定的安全性,并在实际应用中具有一定的实用价值。
