面向行人再识别的特征融合与鉴别零空间方法
2018-08-20翟懿奎陈璐菲
翟懿奎 陈璐菲
(1. 五邑大学信息工程学院,广东江门 529020; 2. 广东省海量生物特征信息处理工程技术研究中心,广东江门 529020)
1 引言
行人再识别技术是指在无重叠监控摄像中,检索某个监控摄像头拍摄到的某个行人是否在其他监控摄像中出现。由于监控摄像拍摄得到的图像分辨率低,且拍摄视角和行人姿势发生变化、拍摄背景复杂,导致同一行人在不同监控摄像中的外观不同,因此行人再识别问题是一个具有挑战性的问题。为有效解决这些问题,目前广大研究者关于行人再识别算法提出的解决方法主要集中在特征表示和度量学习两方面,其中特征表示方法[1-10],提取具有鉴别能力且对视角和光照不变的特征;度量学习方法[11-18],利用机器学习方法学习两张行人图像的相似度度量函数,使得相关行人对的相似度高。
特征表示方法主要是提取图像颜色和纹理特征,Gray和Tao[1]将行人图像分割成水平条纹,再利用RGB、HS、和YCbCr颜色特征,并在HSV的亮度V通道处使用21个纹理滤波器,并用Adaboost挑选出较好的特征,但该方法特征不能有效解决视角问题。Fa-renzena等[2]提出局部特征对称性积累(symmetry-driven accumulation of local feature, SDALF)方法,利用行人对称性与非对称性减少背景干扰,以增强视角变换的鲁棒性。Zhao等[3]提出显著特征,并将行人特征划分成重叠小块,提取每块显著颜色特征与局部不变特征。但在姿态变化的情况下显著性区域会出现偏移或消失,导致识别效果差。Das等[4]提出一致性再识别网络(Network Consistent Re-identification, NCR)框架,并提取行人的头、躯干和腿部HSV直方图特征。Yan等[5]提出回归特征聚合网络(recurrent feature aggregation network, RFA-Net),先提取图像的颜色和LBP特征,并与LSTM结合获得基于序列特征,充分利用序列数据集信息。Liu等[6]提出基于累积运动上下文的视频人重识别方法,采用空间和时间分离的两路卷积网络结构,然后将获得的表观特征和运动特征融合作为RNN的输入,提高rank1识别率。使用深度学习得到的图像特征能够提高识别率,但是深度学习需要大量的数据以及大量的视角进行训练,存在对小数据集的处理效果并不理想的问题。Pedagadi等[7]提取HSV和YUV空间颜色直方图,然后利用PCA提取不同特征的主要成分并降维。Liu等[8]为解决外表变化提出一种有效的半监督耦合字典学习方法,更好地表示特征内在结构。Liao等[9]提出局部最大事件(Local Maximal Occurrence, LOMO)特征,并利用HSV颜色直方图和SILTP描述算子提取特征,SILTP既具有LBP的尺度不变形,且图像噪声鲁棒的特点。Zheng等[10]为每个小块提取11维颜色描述算子,并通过词袋(Big-of-Words, BoW)模型把这些颜色描述算子聚集到全局向量。
不同行人的特征描述子间距离最大,同一行人的特征描述算子间距离最小。因此,度量学习方法主要是学习行人特征间最佳距离。Weinberger和Saul等[11]提出大间隔最近邻分类(Large Margin Nearest Neighbor, LMNN)算法,该算法采用三元组形式,并加上不相似样本对约束得到最优矩阵,但构建三元组的方法会丢失一些重要的训练特征距离。Kostinger等[12]提出保持简单且直接算法(Keep it Simple and Straight, KISS),通过模型参数估计直接得到最终距离函数的参数矩阵,为后续计算提供方便。该方法用于大尺度数据的学习,但在估计训练数据不足时,存在估计处理的参数不准确的问题。Davis等[13]提出基于信息论度量学习(Information Theoretic Metric Learning, ITML)算法,把欧式距离矩阵看作单位阵,并将该矩阵转换映射到一个高斯模型,然后用散度来度量不同欧式距离矩阵之间的相似性。Liao等[9]提出交叉视觉二次判别分析(Cross-view Quadratic Discriminant Analysis,XQDA)算法,是KISSME算法和贝叶斯人脸算法的扩展,以学习低维子空间度量,该度量函数分别用来度量同类样本和非同类样本。随后Xiong等[14]提出一种新的基于内核的距离学习方法,利用4种基于核的度量学习方法即归一化成对约束成分分析法(regularized Pairwise Constrained Component Analysis, rPCCA)、核化局部Fisher判别分析法(kernel Local Fisher Discriminant Classifier, kLFDC)、边际Fisher分析法(Marginal Fisher Analysis, MFA),巧妙利用核技巧避免解决复杂的散列矩阵,既减少运算量又提高识别率。Chen等[15]为解决不同视角提取的特征差异而提出不对称距离模型,学习具体摄像机投影到包含特征差异的通用空间。但该方法需根据拍摄场景的书面分别学习与数目对应的投影矩阵,会增加训练时间和存储复杂度。Zhang等[16]为解决小样本类问题提出有差异零空间方法训练数据,同一个人的图像数据在零空间内集合成一个点,达到最小化类内差异和最大化类间差异。You等[17]改进LMMN算法提出顶部推距离学习模型(top-push distance learning model, TDL),缩小正样本间的差异,惩罚离的最近的负样本,比LMMN有更强约束。Zhou等[18]利用深度学习将特征学习和度量学习统一在一个框架下,进行端对端的训练和推理,并利用基于空间的循环神经网络模型,使得相似度量融合了上下文信息而变的鲁棒,但该模型没有在小数据集上进行实验。
为解决上述行人再识别算法存在的问题,本文提出面向行人再识别的融合特征和鉴别零空间方法。特征融合则是将条纹特征与块状特征相互融合,其中条纹特征将图片水平方向无重叠分成18条,每条提取HSV、LAB、RGB和YCrCb四种颜色特征以及Gabor纹理特征;块状特征则将图片水平重叠分成7块,利用高斯分布从每块中取小块提取RGB、HSV、LAB和nRnG四种颜色特征。度量距离算法是将原始特征空间投影到另一个具有区分性空间,本文鉴别零空间采用Foley-Sammom 零空间变换模型学习一个投影矩阵,将高维特征向量转换成低维特征向量进行行人匹配。实验结果表明所提方法能充分融合行人图像特征,对环境有较强鲁棒性,可有效提高识别率。
本文其余章节的组织安排如下。第2节介绍本文所提条纹与块状特征提取和融合方法;第3节介绍Foley-Sammom零空间变换算法及相应步骤;第4节介绍本文算法在公共数据集上的实验;第5节总结全文。
2 特征提取与融合方法
2.1 条纹特征提取方法
条纹特征是将图像水平无重叠均匀分成若干个条纹,然后从每个条纹中获取颜色和纹理特征,最后融合所有条纹特征。颜色特征中常见RGB、HSV、LAB和YCrCb等颜色直方图,纹理特征主要包括LBP、SIFT、Gabor滤波器等。本文中,条纹特征的颜色特征选择RGB、HSV、LAB和YCrCb四种颜色直方图,纹理特征选择Gabor滤波器,其中RGB颜色空间上的距离不能表示人眼视觉上的颜色,因此在机器视觉上可以将其转换成其他颜色空间。HSV能很好地反映人类对颜色的感知和鉴别能力,且其亮度与图片色彩信息无关,色调和饱和度与人的感受颜色方式紧密联系[19]。LAB颜色空间描述方式与拍摄角度和设备无关,能够较好的处理不同设备获取图像颜色特征的差异。YCrCb是一种颜色空间,用于优化彩色视频信号的传输,其Y表示明亮度,Cr和Cb均表示色度,用于描述图像色彩和饱和度。且Cr和Cb反映的是彩色图像RGB蓝色和红色信号与RGB亮度之间的差异,RGB转化成YCrCb的公式如下:
Y=0.299R+0.587G+0.114B
Cr=0.5R-0.4187G-0.0813B+128
Cb=-0.1687R-0.3313G+0.5B+128
(1)
Gabor滤波器常用作纹理特征提取,易于调谐方向和径向频率带宽以及中心频率,并在时域和频域中同时达到最佳分辨率[20]。Gabor滤波器在频域空间以(0,0)点为中心,定义为:

(2)
(3)
图1表示条纹特征提取方法,每张图像大小设置为144×48,然后将该图像水平方向无重叠分成18层水平条纹,每层水平条纹提取HSV、LAB、RGB和YCrCb四种颜色特征和16个Gabor纹理特征,其中颜色特征包含RGB、LAB、HS和YCrCb 11个颜色通道,并在V亮度中提取Gabor纹理特征,因此每条条纹的特征维数均为416,最后18条水平条纹特征融合成一个特征向量,其特征维数为7488。
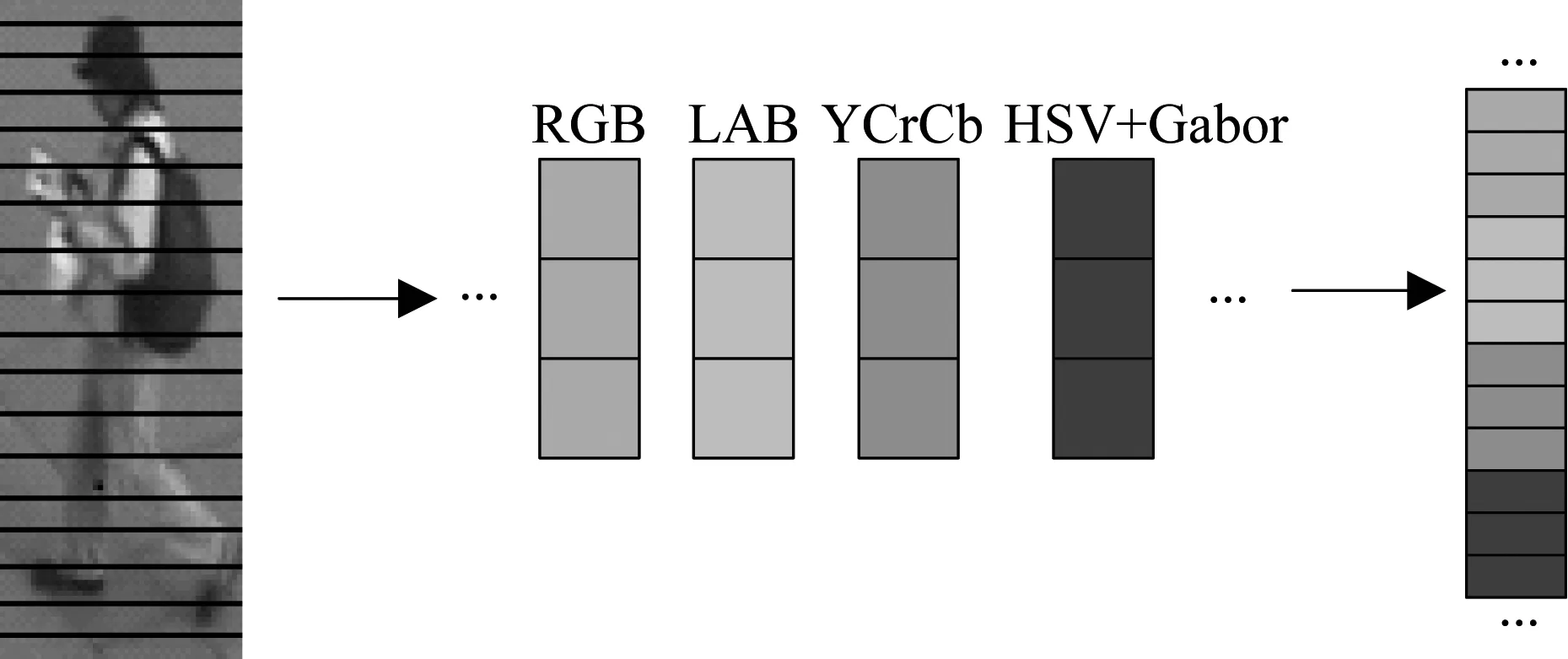
图1 条纹特征提取
2.2 块状特征提取方法

(4)


(5)
(6)
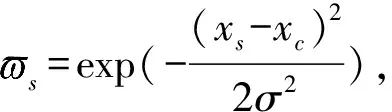

(7)

(8)
2.3 条纹与块状特征融合方法
单一特征提供的信息有限,可利用合理方法表达行人多个特征,获得更多的行人特征信息,取得满意结果。特征融合主要方法包括数据级融合、特征级融合和决策级融合,其中数据级融合处理的数据量过多,无法实时处理,因而很少运用在实际应用
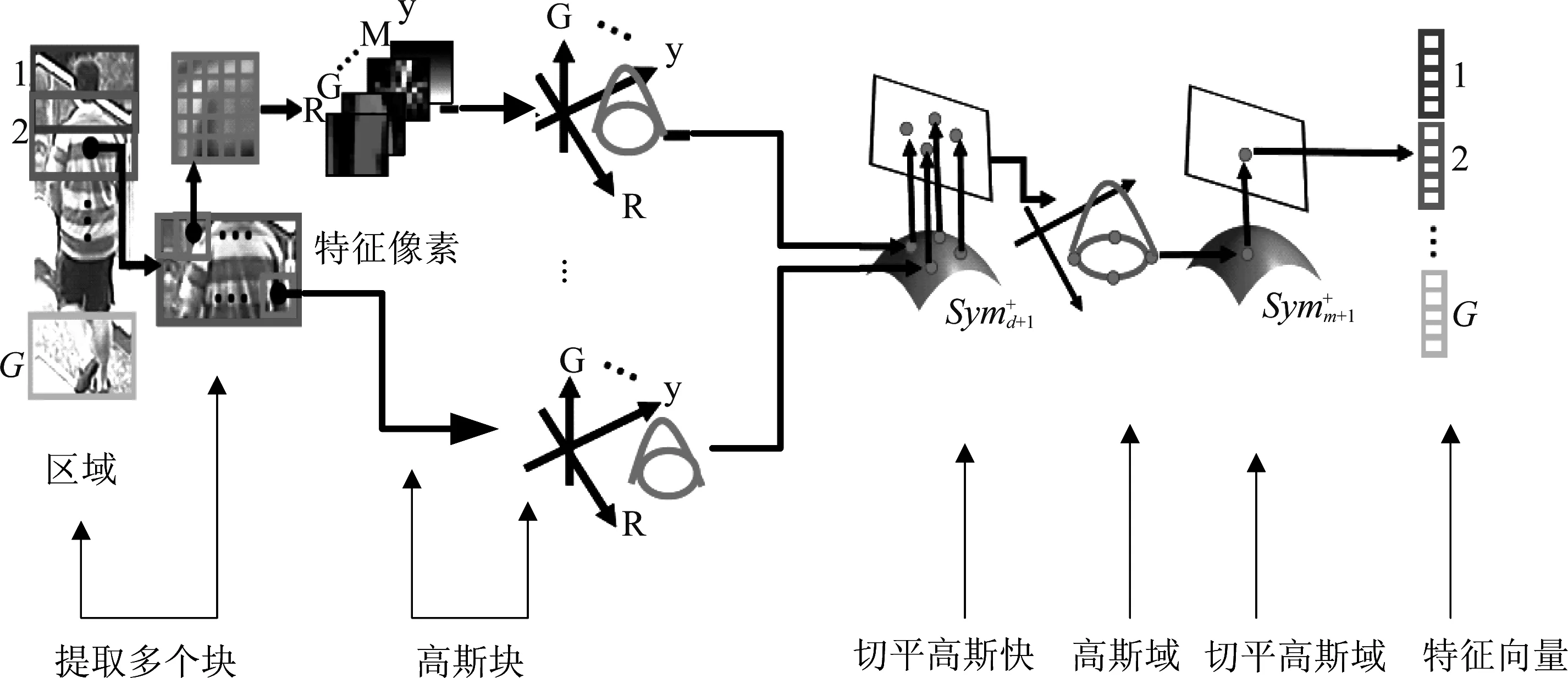
图2 块状特征提取
中;特征级融合主要针对提取的特征向量融合,丰富目标物体特征,其数据量不多,能实现实时处理;决策级融合则是对每个特征最终分类结果进行融合[34]。特征级融合可以分为特征组合和特征选择两种实现方式,其中特征组合方法是将待融合的特征向量按某种组合形成新的特征向量,通常有串行特征融合和并行特征融合,而本文特征融合选用特征串行融合方法。
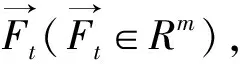
算法1特征融合算法流程
输入:N对相关行人图像{X,Y},(X=(x1,x2,…,xn),Y=(y1,y2,…,yn))

步骤1将行人图像大小统一为144×48;

步骤3图像大小统一为128×48;


3 Foley-Sammom零空间变换算法
3.1 Foley-Sammom 零空间变换
两种特征融合之后得到的特征向量维数高,本文采用Foley-Sammom 零空间变换 (null Foley-Sammom Transform, NFST)方法将特征从高维空间投影到低维空间[35, 16]。NFST是Foley-Sammom变换(Foley-Sammom Transform, FST)的扩展,FST学习投影矩阵W∈Rd×m,每一列的投影矩阵定义为w,是一种使Fisher最大化的最佳判别标准:
(9)
其中Sb表示类间散点矩阵,Sw表示类内散点矩阵。优化公式(9)可以解决广义特征问题:
Sbw=λSww
(10)

wTSww=0
(11)
wTSbw>0
(12)
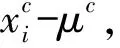
(13)
(14)

Zt={z∈Rd|Stz=0}={z∈Rd|z⊥Stz=0}=
(15)
w=β1u1+…+βN-1uN-1=Uβ
(16)
St维数是N-1,因此有N-1个基准向量。由于w∈Zw,把公式(16)代入公式(11)解决特征问题:
(UTSwU)β=0
(17)
3.2 Foley-Sammom零空间变换算法步骤

算法2Foley-Sammom零空间算法步骤
输入:Xx,Xc,K,P0=0
输出:学习的投影矩阵W
步骤1用Xx评估W0;
步骤2t=0;


步骤5以最高百分比f来创建伪类Pt+1;
步骤6t=t+1;
步骤7重复步骤3到步骤6,直到收敛。
4 实验结果与分析
本节首先介绍本文所用数据库和参数设置,其次把本文算法单独与条纹特征、块状特征进行比较,最后和已有最新行人再识别算法进行性能比较。
4.1 数据库介绍及设置
本文方法在VIPeR[22]、Prid_450s[23]和CUHK01[24]3个数据库上进行测试,并且每个数据库在同等条件下训练10次,最后取平均值为测试的最终结果。VIPeR数据库目前是比较常用的数据库,也是比较具有挑战的数据库之一,其主要面临视角变化、复杂背景、光照以及姿势等因素挑战。该数据库包含632个人,每个人包含两张图像,分别从不同角度拍摄而得,且图像大小统一为128×48;Prid_450s数据库包含450个行人,每个行人有两张图像,分别从不同角度拍摄,但其图像大小不一。CUHK01数据库与其他两个数据库不同,其图像拍摄源于校内,也是目前行人再识别中比较常用并具有挑战性数据库之一。该数据库包含791个人,每个人有4张图像,其中每个角度获取每人两张图像,其像素大小统一为160×60。本实验数据库评估方法采用single-shot方法,随机选择p对行人图像作为训练集,余下作为测试集,其中测试集由行人图像库和查询集组成。每队行人图像的一张并入查询集,另一张则并入行人图像库,其中p分别取值为316,225和485。累积匹配特性(CMC)曲线是行人再识别算法性能常用的评价指标,其rank-k识别率表示与目标样本中找到最k个相似的样本正确的行人概率。
4.2 实验结果与分析
4.2.1融合特征与单一的条纹特征和块状特征在不同数据库中性能比较
为验证本文融合特征的性能,将其在VIPeR、Prid_450s和CUHK01 3个数据库上分别与单独的条纹特征和块状特征进行比较。从表1可以看出融合特征方法的识别率明显高于条纹特征和块状特征,块状特征识别率明显高于条纹特征。本文实验表明,在度量方法与评估方法相同的情况下,块状特征提取的图像信息比条纹特征更充分,融合特征的图像特征信息明显比块状特征充分,本文所提融合特征方法能有效描述行人信息,对环境变化有较强鲁棒性,因而可提高识别率。

表1 融合特征与单一的条纹特征和块状特征在不同数据库中性能比较
4.2.2本文方法与其他方法分别在不同数据库性能比较
本文方法在VIPeR数据库上分别与LOMO+NBFT[16]、GOG+XQDA[21]、LOMO+XQDA[9]、MKFSL[25]、Ensemble[26]、Semantic[10]、MCKCCA[27]和Kernel X-CRC[28]比较,其rank1到rank20识别率如表2所示。图3是本文方法与其他方法识别率的CMC曲线图,曲线分布情况明显表明本文提出方法比最近几年提出的算法识别率略高。其中GOG+XQD、MKFSL和Kernel X-CRC均是最新提出的算法,其特征提取采用GOG描述器,其识别率均比本文单独块状特征高,但比融合特征低,进一步说明本文所提融合方法能更充分地提取图像行人特征信息,有效提高识别率。

图3 不同算法在VIPeR数据集上的识别率
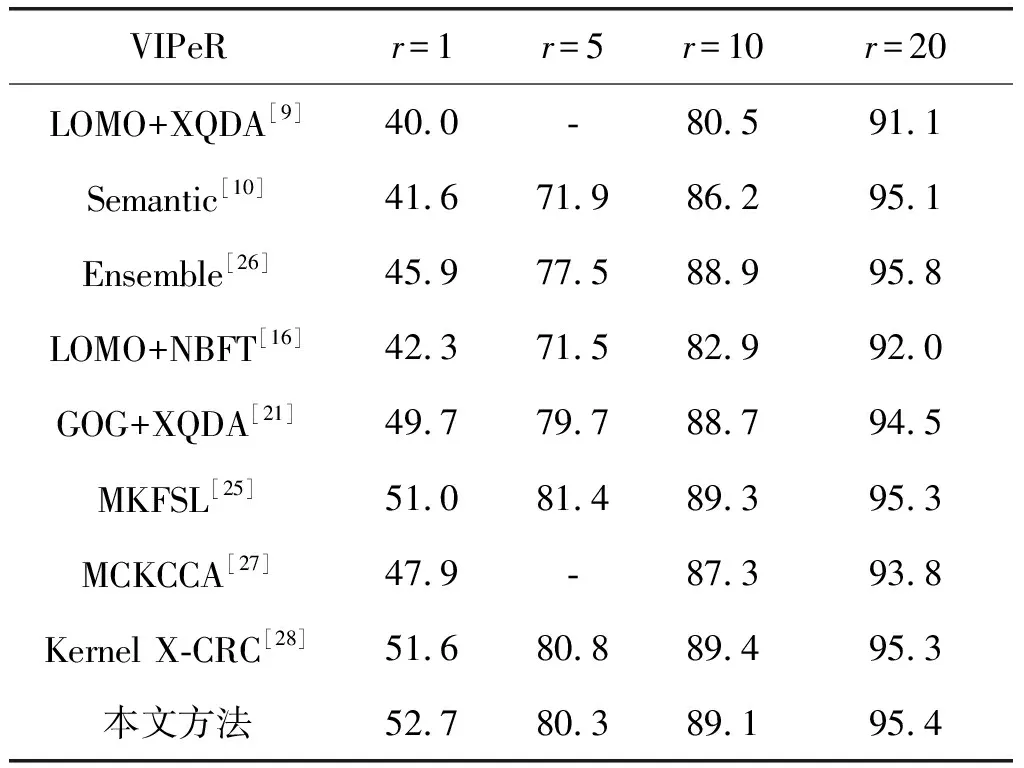
VIPeRr=1r=5r=10r=20LOMO+XQDA[9]40.0-80.591.1Semantic[10]41.671.986.295.1Ensemble[26]45.977.588.995.8LOMO+NBFT[16]42.371.582.992.0GOG+XQDA[21]49.779.788.794.5MKFSL[25]51.081.489.395.3MCKCCA[27]47.9-87.393.8Kernel X-CRC[28]51.680.889.495.3本文方法52.780.389.195.4
本文方法在Prid_450s数据库上分别和LOMO+NBFT[16]、MKFSL[25]、SCNCD[31]、GOG+XQDA[21]、Semantic[10]、LOMO+XQDA[9]、MirrorKMFA[30]和MCKCCA[27]进行比较,各方法识别率曲线如图4所示。表3直观反映本方法rank1识别率达到72.2%,明显高于其他方法的识别率。其中GOG+XQDA最近已提出新算法中效果最好的算法,但其rank1识别率低于本文方法将近4%,且rank1到rank20识别率均比低于本文方法。MKFSL与本文方法类似,均采用特征融合方法,但其采用GOG块状特征与WHOS[36]特征融合方法,rank1识别率为66.9%,低于本文方法将近6%。实验表明,本文提出方法取得了较好识别效果,特别是rank1识别率达到较高准确率,可较好地推广到实际应用中。

图4 不同算法在Prid_450s数据集上的识别率

Prid_450sr=1r=5r=10r=20SCNCD[31]41.668.979.487.8Semantic[10]44.971.777.586.7MirrorKMFA[30]55.479.387.893.9LOMO+XQDA[9]62.685.692.096.6LOMO+NBFTL[16]60.5-88.693.6GOG+XQDA[21]68.488.894.597.8MCKCCA[27]55.8-90.895.5MKFSL[25]66.989.394.297.7本文方法72.289.895.098.0
由于本实验采用single-shot方法评估,但与其他方法不同,每个人4张图像随机选两张用来实验,数据相对较少。本文方法在CUHK01数据库上分别与Kernel X-CRC[28]、GOG+XQDA[21]、MKFSL[25]、MFFIML[33]、MultiCNN[32]和MirrorKMFA[30]进行比较,其识别率曲线如图5所示。表4表明MKFSL和Kernel X-CRC的识别率比本文方法略高,但rank5和rank10较低,且算法模型比本文方法复杂。本文方法在数据较少的情况下仍能达到较好的结果,可行性较高。
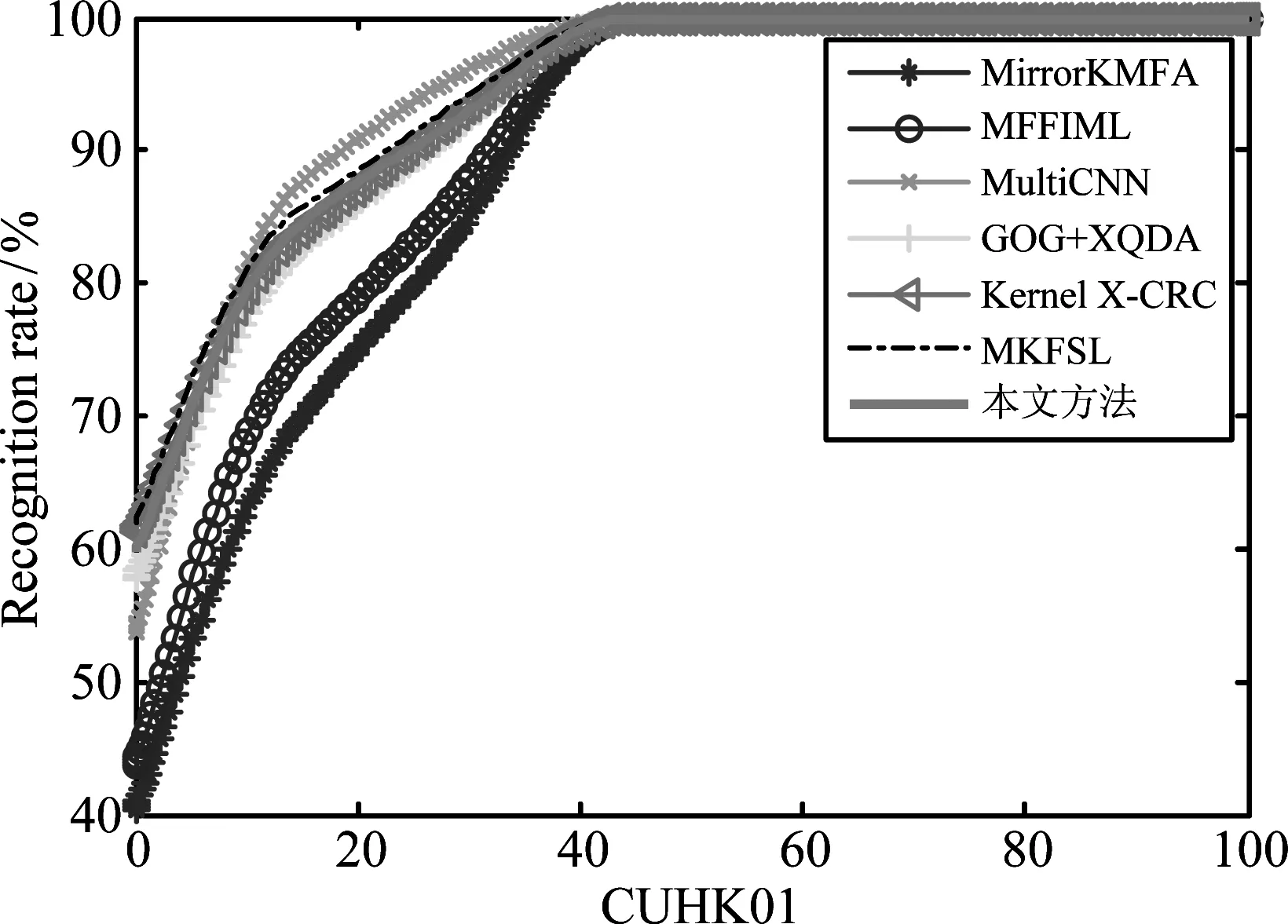
图5 不同算法在CUHK01数据集上的识别率

CUHK01r=1r=5r=10r=20MirrorKMFA[30]40.464.675.384.1MFFIML[33]43.770.879.087.3MultiCNN[32]53.784.391.096.3GOG+XQDA[21]57.879.186.292.1Kernel X-CRC[28]61.280.987.393.2MKFSL[25]62.082.9-94.2本文方法59.781.287.992.6
5 结论
本文提出面向行人再识别的融合特征与鉴别零空间方法,利用颜色和纹理特征分别提取条纹特征和块状特征,并将这两种特征融合,然后利用鉴别零空间降低特征维度,取得了较好的效果。由于存在行人姿势变化,光照变化以及遮挡和视角变化等困难,在多个公共数据集的实验结果表明,本文方法取得了比主流方法较好的效果。这体现本文方法不仅具有良好识别性能,且具有较高特征鲁棒性。为进一步提高识别率,下一步将考虑从多特征中自适应选择角度进行研究。
[1] Gray D, Tao Hai. Viewpoint Invariant Pedestrian Recognition with an Ensemble of Localized Features[C]∥Proceedings of the 10thEuropean Conference on Computer Vision. Marseille, France: IEEE, 2008(5302): 262-275.
[2] Farenzena M, Bazzani L, Perina A, et al. Person Re-identification by Symmetry-Driven Accumulation of Local Feature[C]∥Proceedings of the 2010 IEEE Computer Vision and Pattern Recognition. San Francisco, USA: IEEE, 2010(23): 2360-2367.
[3] Zhao Rui, Ouyang Wanli, Wang Xiaogang. Unsupervised Salience Learning for Person Re-identification[C]∥Proceedings of the 2013 IEEE Computer Vision and Pattern Recognition. Washington, USA: IEEE, 2013(9): 3586-3593.
[4] Das A, Chakraborty A, Roy-Chowdhury A K. Consistent Re-identification in a Camera Network[C]∥Proceedings of the 2014 European Conference on Computer Vision, 2014(8690): 330-345.
[5] Yan Yichao, Ni Bingbing, Song Zhichao, et al. Pedestrian Re-identification via Recurrent Feature Aggregation[C]∥Proceedings of the 2016 European Conference on Computer Vision, 2016(99): 701-716.
[6] Liu Hao, Jie Zequn, Jayashree K, et al. Video-Based Person Re-identification with Accumulative Motion Context[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2017(99): 1-11.
[7] Pedagadi S, Orwell J, Velastin S, et al. Local Fisher Discriminant Analysis for Pedestrian Re-identification[C]∥Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Washington, USA: IEEE, 2013(9): 3318-3325.
[8] Liu Xiao, Song Mingli, Tao Dacheng, et al. Semi-supervised Coupled Dictionary Learning for Person Re-identification[C]∥Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). Washington, USA: IEEE, 2014(8): 3550-3557.
[9] Liao Shengcai, Hu Yang, Zhu Xiangyu, et al. Person Re-identification by Local Maximal Occurrence Representation and Metric Learning[C]∥Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston USA: IEEE, 2015: 2197-2206.
[10] Zheng Zhiyuan, Hospedales T M, Xiang Tao. Transferring a Semantic Representation for Person Re-identification and Search[C]∥Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston USA: IEEE, 2015: 4184- 4193.
[11] Weinberger K Q, Saul L K. Distance Metric Learning for Large Margin Nearest Neighbor Classification[J]. Journal of Machine Learning Research, 2009,10(1): 207-244.
[12] Kostinger M, Hirzer M, Wohlhart P, et al. Larger Scale Metric Learning from Equivalence Constraints[C]∥Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. RI, USA: IEEE, 2012: 2288-2295.
[13] Davis J V, Kulis B, Jain P, et al. Information-theoretic Metric Learning[C]∥Proceedings of the 24th international conference on Machine learning. New York, USA: 2007(227): 209-216.
[14] Xiong Fei, Gou Mengran, Camps O, et al. Person Re-identification Using Kernel-based Metric Learning Methods[C]∥Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Washington, USA: IEEE, 2014(8695): 1-16.
[15] Chen Yingcong, Zheng Weishi, Lai Jianhuang, et al. An Asymmetric Distance Model for Cross-View Feature Mapping in Person Re-identification[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2016 (27): 1661-1675.
[16] Zhang Li, Xiang Tao, Gong Shaogang. Learning Discriminative Null Space for Person Re-identification[C]∥Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV: IEEE, 2016: 1239-1248.
[17] You Jinjie, Wu Ancong, Li Xiang, et al. Top-Push Video-Based Person Re-identification[C]∥Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV: IEEE, 2016: 1-10.
[18] Zhou Zhen, Huang Yan, Wang Wei, et al. See the Forest for the Trees: Joint Spatial and Temporal Recurrent Neural Networks in Video-Based Person Re-identification[C]∥Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017: 4747- 4756.
[19] Saghafi M A, Hussain A, Saad M H M, et al. Appearance Based Methods in Re-identification[C]∥Proceedings of the 2012 IEEE 8thInternational Colloquium on Signal Processing and ITS Application. Melaka, Malaysia: IEEE, 2012(2012): 404-408.
[20] 李钰,孟祥萍. 基于Gabor滤波器的图像纹理特征提取[J]. 长春工业大学学报:自然科学版,2008,29(1): 78- 81.
Li Yu, Meng Xiangping. Image Texture Feature Detection Based on Gabor Filter[J]. Chinese Journal of Changchun University of Technology: Natural Science Edition, 2008,29(1): 78- 81. (in Chinese)
[21] Matsukawa T, Okabe T, Suzuki E, et al. Hierarchical Gaussian Descriptor for Person Re-identification[C]∥Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV: IEEE, 2016: 1363-1372.
[22] Gray D, Brennan S, Tao Hai. Evaluating Appearance Models for Recognition, Reacquisition, and Tracking[J]. International Workshop on Performance Evaluation of Tracking and Surveillance, 2007(3): 41- 47.
[23] Roth P M, Hirzer M, Koestinger M, et al. Mahalanobis Distance Learning for Person Re-identification[M]. Person Re-identification. Florence, Italy, 2014: 247-267.
[24] Li Wei, Zhao Rui, Wang Xiaogang. Human Re-identification with Transferred Metric Learning[C]∥Proceedings of the 11th Asian conference on Computer Vision. Daejeon, Korea: 2012(7724): 31- 44.
[25] Yang Xun, Wang Meng, Hong Richang, et al. Enhancing Person Re-identification in a Self-trained Subspace[J]. ACM Transactions on Multimedia Computing, Communications, and Applications, New York, NY, USA, 2017,13(3): 1-14.
[26] Paisitkriangkrai S, Shen C, Hengel A van den. Learning to Rank in Person Re-identification with Metric Ensembles[C]∥Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston USA: IEEE, 2015: 1846-1855.
[27] Lisanti G, Karaman S, Masi L. Multi Channel-Kernel Canonical Correlation Analysis for Cross-View Person Re-identification[J]. ACM Transactions on Multimedia Computing, Communications, and Applications, New York, NY, USA, 2017(13): 1-19.
[28] Prates R, Schwartz W R. Kernel Cross-View Collaborative Representation based Classification for Person Re-identification[C]∥Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017: 1-10.
[29] Zhang Ying, Li Baohua, Lu Huchuan. Sample-Specific SVM Learning for Person Re-identification[C]∥Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV: IEEE, 2016: 1278-1287.
[30] Chen Yingcong, Zheng Weishi, Lai Jianhuang. Mirror Representation for Modeling View-Specific Transform in Person Re-identification[C]∥Proceedings of the 24thInternational Joint Conference of Artificial Intelligence. Buenos Aires, Argentina: 2015: 3402-3408.
[31] Yang Yang, Yang Jimei, Yan Junjie, et al. Salient Color Names for Person Re-identification[C]∥Proceedings of the 2014 European Conference on Computer Vision. Springer, Cham, 2014(8690): 536-551.
[32] Cheng De, Gong Yihong, Zhou Sanping, et al. Person Re-identification by Multi-Channel Parts-Based CNN with Improved Triplet Loss Function[C]∥Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas, NV: IEEE, 2016:1335-1344.
[33] 齐美彬,胡龙飞,蒋建国,等. 多特征融合与独立测度学习的行人再识别[J]. 中国图像图形学报, 2016,21(11):1464-1472.
Qi Meibin, Hu Longfei, Jiang Jianguo, et al. Person Re-identification Based on Multi-Features Fusion and Independent Metric Learning[J]. Chinese Journal of Image and Graphics, 2016,21(11):1464-1472.(in Chinese)
[34] 刘苗苗. 基于2D和3D SIFT特征融合的一般物体识别算法研究[D]. 南京:东南大学, 2015.
Liu Miaomiao. Generic Object Recognition Research Based on Feature Fusion of 2D and 3D SIFT Descriptors[D]. Nanjing: Southeast University, 2015.(in Chinese)
[35] Foley D, Sammon J. An Optimal Set of Discriminant Vectors[J]. IEEE Transaction on Computers, 1975,100(3): 281-289.
[36] Lisanti G, Masi L, Bagdanov A D, et al. Person Re-identification by Iterative Re-Weighted Sparse Ranking[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015,37(8):1629-1642.
