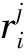一种基于聚类和AdaBoost的自适应集成算法
2018-07-19王玲娣
王玲娣, 徐 华
(江南大学 化工物联网工程学院, 江苏 无锡 214122)
机器学习所关注的问题之一是利用已有数据训练出一个学习器, 使其对新数据尽可能给出最精确的估计. 集成学习为该问题提供了一种有效可行的解决方式, 与一般的机器学习算法目的相同, 分类仍然是集成学习的基本目标, 但集成学习将多个分类器的分类结果进行某种组合来决定最终结果, 以此取得比单个分类器更好的性能. 常用的集成学习算法有AdaBoost[1],Bagging(bootstrap aggregating)[2]和随机森林[3]等. 其中, AdaBoost算法由于其简单的流程及较理想的效果, 已成功应用于人脸检测[4-5]、车辆识别[6]、疾病诊断[7]和目标跟踪[8-9]等实际问题中.
集成学习主要包括两个组成部分: 1) 构造差异性大且准确率高的基分类器; 2) 基分类器组合规则, 如简单投票法, 包括多数投票、一致表决、最小投票等. 一般增加差异性可分为显性和隐性两种方式. 显性方式是指最大化某个与差异性相关的目标函数, 集成不同的基分类器[10-12]. 隐性方式是指从训练样本或样本特征入手, 通过构造不同的训练子集或特征子集来训练不同的基分类器, 如姚旭等[13]利用粒子群算法(PSO)寻找使AdaBoost依样本权重抽取的数据集分类错误率最小化的最优特征权重分布, 根据该最优权重分布对特征随机抽样生成随机子空间, 以增大基分类器间的差异性, 并提出一种基于AdaBoost和匹配追踪的选择性集成算法[14]; 文献[15]整合特征选择和Boosting思想提出了BPSO-Adaboost-KNN集成算法. Parvin等[16]提出了一种基于分类器选择聚类技术的集成分类框架, 先利用聚类技术将基分类器分组, 再从不同组中选择基分类器组合, 完成选择性集成; Xiao等[17]提出了一种基于监督聚类的用于信用评估的分类方法, 先利用聚类方法将每个类别的样本聚类分组, 再将不同类别、不同组的样本组合在一起构成不同的训练子集, 最后在训练子集上生成一组不同的基分类器.
AdaBoost使用加权多数投票规则组合基分类器, 基分类器的权重对不同的测试样本都是固定不变的, 并未考虑到测试样本与基分类器之间的适应性, 且AdaBoost在训练基分类器的过程中, 一直聚焦在错分样本上, 错分样本的权重逐步增加, 会导致正确分类样本的权重过低, 基分类器倾向于在样本空间的部分区域有较好的效果, 其他区域的样本被忽略. 这也是AdaBoost对噪音敏感的原因. 所以, 需要区别对待不同的测试样本, 充分挖掘基分类器的分类能力, 使基分类器的权重可针对不同的测试样本自适应调整.
针对上述问题, 受文献[16-17]的启发, 并结合集成学习对基分类器的要求, 本文提出一种基于聚类和AdaBoost的自适应集成方法. 一方面利用聚类分组确保不同组的基分类器之间的差异性, 每组分别进行AdaBoost训练, 以保证较高的局部分类正确率; 另一方面结合测试样本到不同分组中心的距离及AdaBoost对此样本判别的置信度动态调整基分类器的权重.
1 AdaBoost算法
AdaBoost算法是一个自适应地改变训练样本分布的迭代过程, 使基分类器聚焦在难分的样本上. 其原理是: 训练集中的每个样本均被赋予一个权值, 构成向量D, 并初始化为相等值, 然后根据某种基分类器训练算法得到第一个基分类器, 再根据该分类器的错误率调整训练样本权重, 降低被正确分类的样本权重, 提高被错误分类的样本权重. 基于改变的样本分布, 继续训练基分类器. 如此往复, 便可得到一组基分类器. AdaBoost算法如下.
算法1AdaBoost算法.
输入: 训练集{(x1,y1),(x2,y2),…,(xm,ym)}, 其中类标签yi∈{-1,1}; 迭代次数T.
初始化D1(i)=1/m, 第一次迭代时每个样本的权重均为1/m.
fort=1 toT
在Dt下训练得到基分类器ht;
计算ht的加权错误率
εt=∑Dt(i)[ht(xi)≠yi],
其中[ht(xi)≠yi]是指示函数, 若ht(xi)≠yi成立, 则返回1, 否则返回0;

更新样本权值:
其中Zt是归一化因子;
end for
2 基于聚类和AdaBoost的自适应集成方法设计
本文提出一种自适应集成方法(adaptive ensemble method based on clustering and AdaBoost, AECA).
2.1 算法思想
差异性是集成学习的基础, 如果是同一算法在不同设置下的集成, 则差异性一般源于基分类器的训练样本, 这样同一算法在不同训练样本下即可训练出不同的基分类器. 经典的集成方法Bagging和AdaBoost都是同一算法在不同设置下的集成, 其差异性源于训练样本的不同. 将一个大的训练样本集根据相似度分成多个组, 在每组进行分类训练, 这样就在分类器训练前显性地增加了差异性, 从而不用在训练过程中考虑如何平衡差异性和分类正确率的问题, 因为差异性在训练样本划分时分类器训练前即给予了保证, 而分类正确率即成了在分类器训练过程中唯一需要考虑的因素.
图1为一个二维二分类问题, 其中“●”和“■”表示两类数据. 由图1可见, 对于子集S1, 分类函数y1可成功地将“●”和“■”所表示的两类样本正确分类; 在子集S2中, 分类函数y2也能对两类样本点正确分类. 但一个单分类器则很难以高的正确率将这两类样本区分. 至于常用的集成算法, 如Bagging, 是通过随机重采样构造一组基分类器, 随机选择的样本有可能均匀地来自子集S1和S2, 这样基分类器的正确率可能会很低, 从而导致最终集成性能的下降. 此外, 基分类器间的差异性也不能保证. 而先对训练样本聚类, 分成若干个子集, 再分组分类, 则可有效解决上述问题. 通过聚类将训练样本分成子集S1和S2, 这些子集分别表示了样本的不同空间特征, 再根据某种分类算法各自训练分类器, 即可得到局部正确率较高的两个分类器.
对于测试样本, 与该测试样本较相似的训练样本分组上训练出的分类器对其正确分类的可能性更大. 因此本文在每个分组上根据AdaBoost算法训练出一个强分类器, 然后组成一个更强大的分类器. AECA算法过程如图2所示. 由图2可见, AECA算法有两个重要组成部分:
1) 先对训练样本进行聚类分组, 再在每组样本上根据AdaBoost算法训练得到分类器{H1,H2,…,Hk};
2) 将训练得到的分类器进行整体集成.
AdaBoost算法训练出的分类器对样本类别进行判定时有对判定结果的置信度, 整体集成综合考虑具体测试样本与各分组的相似度及AdaBoost分类器的置信度, 按照加权投票策略进行, 其中每组分类器的权值针对测试样本自适应调节.

图1 样本聚类示例Fig.1 Examples of sample clustering

图2 AECA算法示意图Fig.2 Schematic diagram of AECA algorithm
2.2 训练样本分组训练
AECA算法的第一步是对训练样本进行分组, 将相似的样本归到同一组中, 不相似的划分到不同组中, 再分别进行AdaBoost训练. 其中样本分组基于k-均值算法实现. 相似度是聚类的基础, 常用特征空间中的距离作为度量标准计算两个样本间的相似度, 距离越小越相似. 假设X为样本空间, 每个样本xi∈X,xi=(xi1,xi2,…,xim), 其中m表示样本的维数(特征). 经典的距离度量标准是m维特征空间的欧氏距离:
(1)
k-均值算法是发现给定数据集k个簇的算法, 簇个数由用户给定, 每一簇均通过质心, 即簇中所有点的中心描述. 假设cls(i)表示第i个簇, 由n个样本组成, 则该簇的质心centroid(i), 即簇中所有数据的均值:
(2)
算法2k-均值算法.
1) 随机选择k个样本作为初始质心;
2) repeat;
3) 根据式(1)计算样本与每个质心的距离, 将样本指派到距离最近的质心表示的簇中, 形成k个簇;
4) 根据式(2)重新计算每个簇的质心;
5) until质心不发生变化.
初始质心的选择是k-均值算法的关键步骤, 常见的方法是随机地选取初始质心, 但当质心随机初始化,k-均值的不同运行将产生不同的结果. 故需要重复运行多次, 在有限的迭代次数中, 找到一个相对较优的目标函数值. 为了评价最后聚类质量的好坏, 通常使用误差的平方和作为度量聚类质量的目标函数, 但本文的目的不是聚类结果的好坏, 而是为更好地分类, 故本文使用分类正确率作为目标函数. 原始数据集中样本特征值可能是不同取值范围的, 为了避免样本某一个特征值远大于其他特征值, 影响计算结果, 本文先将训练样本集进行数值归一化, 将任意取值范围的特征值根据
转化到0~1区间内, 其中: oldValue表示原特征值; max和min分别表示该特征的最大和最小值.
2.3 分类器自适应权值计算

(3)
为计算各分类器对测试样本自适应的权重w, 首先计算测试样本到各簇质心的距离, 距离越近权值越大. 假设测试样本集为X={x1,x2,…,xm}, 根据欧氏距离计算测试样本xi与簇质心Sk之间的距离dik, 构成距离矩阵:
(4)
然后根据
(5)
将距离矩阵转换成各个簇分类器对测试样本的权值矩阵:
(6)
得到各簇分类器对测试样本的权值矩阵后, 即可进行最后的集成, 因为各簇的分类器是根据AdaBoost算法训练得到的, AdaBoost算法产生的强分类器除了对样本有一个预测类别, 还有置信度margin值. 对于二分类问题, AECA算法进行强分类器最后的集成前, 要保留置信度, 待乘以具体的针对测试样本的自适应权值后相加再取符号. 对测试样本的预测根据
(7)
计算得到. 这样各簇的强分类器中基分类器的权值固定, 但针对不同样本置信度是不同的, 且在最后的集成中, 强分类器对测试样本的权值是自适应的.
2.4 算法描述
首先, 将总样本集分成训练集、验证集和测试集三部分, 且三部分互斥.k-均值算法的目标函数是验证集的分类准确率, 在多次迭代中取验证正确率最高的聚类结果. 一次迭代过程如图2所示, 先通过k-均值算法将训练样本集分成多个簇, 每个簇以簇质心为代表; 然后在每个簇上进行AdaBoost训练分别得到一个强分类器, 当数据集较大时, 该步骤可以并行处理; 最终按照加权投票策略将多个强分类器组合, 其中每个强分类器的权值根据测试样本到每个簇质心的距离计算得出, 原则是距离越近权值越大, 权值之和为1. 关于每组样本上AdaBoost的基分类器数目的取值, 在给定总的基分类器数目的情况下, 每组基分类器的数目取值按照组与组之间的样本数之比分配, 而簇数k则取实验数据集的类别数.
算法3AECA算法.
输入: 训练集, 验证集, 基分类器数目N, 循环次数T.
1) 初始化Top_Accuracy=0, Best_cents=Null, Best_Classifiers=Null
2) fort=1 toT:
3) 根据k-均值算法将训练集分成k个簇, 并得到k个质心
4) 根据AdaBoost算法分别在k个簇上进行训练, 得到k个强分类器classifiers
5) 在验证集上, 根据式(6)计算k个强分类器的自适应权值
根据式(8)计算验证集的分类正确率accuracy
6) if accuracy>Top_Accuracy:
Best_cents=cents
Best_classifiers=classifiers
Top_Accuracy=accuracy
7) end for
输出: Best_cents, Best_classifiers.
3 实 验
3.1 实验环境及数据集
AECA算法基于Python 2.7语言实现, Bagging、随机森林和AdaBoost算法均源自Python机器学习工具包sicikt-learn(http://scikit-learn.org/stable/index.html). 实验共用UCI(http://archive.ics.uci.edu/ml/datasets.html)中的10个数据集, 各数据集信息列于表1. 由表1可见, 数据集Horse,ILPD,Pima中有部分数据缺失, Horse的缺失高达30%. 一般可将缺失值用0或平均值替代, 本文实验中使用属性平均值替代缺失值. 在计算分类正确率时, 为保证计算的准确性, 使用十折交叉验证法. 其中AECA算法需要验证集, 从9份训练集中随机抽取10%的数据作为验证集, 余下的数据则作为训练集. 另外一份作为测试数据集, 这样训练集、验证集和测试集并无交叉, 循环次数为20. 利用双边估计t检验法计算95%的置信水平下的分类正确率均值的置信区间, 计算公式如下:
(8)


表1 实验数据集信息
3.2 实验结果分析
本文将从两方面验证AECA算法的有效性: 1) 比较Bagging、随机森林、AdaBoost算法及AECA算法在相同集成规模下的分类正确率; 2) 从统计的角度, 根据秩和检验法比较AECA算法与其他3种集成算法差别是否统计显著.
3.2.1 分类正确率比较 分类正确率实验结果列于表2, 其中最后一列表示AECA算法在每个数据集的分类表现排序, 在置信水平95%的情形下, 比较4种算法在基分类器数目为50时的分类正确率. 由表2可见, AECA算法在Australian,German,Heart,Horse,ILPD,Pima和Sonar等数据集上的分类正确率均高于其他3种集成算法, 分别比排在第二位的算法高1.74%,0.1%,4.45%,4.97%,2.57%,4.74%. AECA算法的分类正确率在Breast数据集上的表现与随机森林算法基本相同, 在Messidor与Transfusion数据集的表现不是最好, 但也不是最差. 因此, AECA算法的总体表现优于其他3种常用集成算法.
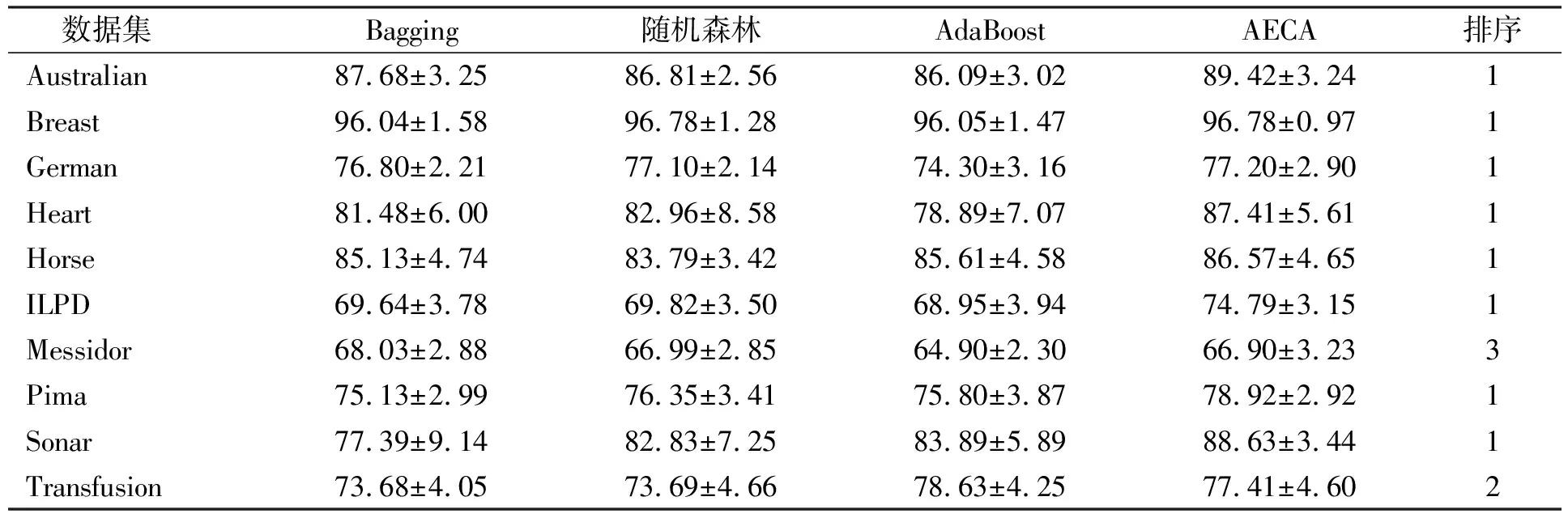
表2 AECA算法与其他3种集成算法的分类正确率(%)比较
为了更直观地观察4种集成算法的分类性能, 参考文献[18]中的统计量进行分析比较, 统计结果列于表3. 表3为每种算法在所有数据集上的正确率比较, 若用row表示第一种算法的分类正确率, col表示第二种算法的分类正确率, row/col表示这两种算法的正确率比值, 若row/col>1, 则表示第一种算法的分类性能优于第二种算法, 否则相反. 其中“赢/平/败”值表示win/tie/loss统计量, 这3个值分别表示row>col, row=col, row 表3 4种算法的分类统计结果 3.2.2 显著性差异检验 利用秩和检验法对上述结果进行分析, 以得到更具统计意义的实验结论. 秩水平的计算公式为 (9) (10) 其中:k表示比较的算法数;J表示每种算法的实验次数;α表示置信水平;qα可查“The Studentized Range Statistic”表得到. 本文实验比较4种算法在置信水平为95%(即α=0.05)情形下的分类效果, 故k=4,J=10,q0.05=1.860, 代入式(10)可得临界值为1.073 87. 4种算法的统计结果列于表4. 表4 4种算法的秩水平 由表4可见, Bagging、随机森林、AdaBoost和AECA算法的秩水平之差分别为1.7,1.1,1.7, 均大于差异临界值1.073 87. 故本文提出的AECA算法与常用集成算法Bagging、随机森林、AdaBoost的差异是统计显著的, 且AECA算法可获得更高的分类正确率, 因此, AECA算法是有效的. 综上所述, 本文提出了一种基于聚类和AdaBoost的自适应集成算法, 该算法首先利用聚类将训练样本分组, 充分利用训练样本信息, 使得组内样本相似度高, 组间差异性大, 从而既保证了不同组上的分类器差异, 又可得到一个较高的局部分类正确率; 最后集成借助AdaBoost的margin值以及测试样本到各组的距离, 使用加权投票策略, 达到各组分类器权值对测试样本自适应调节的目的, 充分挖掘了分类器的分类能力, 从而得到较高的整体集成分类性能. 实验结果验证了该算法的有效性.