高维数据聚类中相似性度量方法的研究
2018-07-11李慧敏
◇李慧敏 李 川 翟 祥
聚类作为一种无监督的学习算法,被广泛应用于社会生活的各个领域。它的主要目的是对大量未知标注的数据集,按照数据的内在相似性划分为多个类别,使类别内的数据相似度较大,而类别间的数据相似度较小。传统的聚类方法主要分为层次聚类和划分式聚类:层次聚类将每一个样本视为一个小类,自下而上将相似的两类进行合并,最终形成一个大类;划分式聚类则将所有样本视为一个类簇,通过不断分裂这个大类簇形成各个小类。K-means算法是划分式聚类里非常典型的一种聚类方法,由于其适用于大样本的特点,被广泛应用于商业数据分析中,例如近来较为热门的客户画像技术,就是利用K-means聚类技术建立一个标签体系来定义客户的价值。
一、传统聚类方法存在的问题
随着信息技术日新月异的发展,大量的数据从各行各业产生,这些数据的数量和属性个数同时以几何倍数快速增长,K-means算法的应用也因此而受到局限。原因主要有两点:首先,在高维空间中,数据的分布具有高度的“稀疏性”和“空空间性”;其次,传统的聚类方法是针对低维数据而设计的,当数据上升到高维空间中时,传统的聚类方法将失去其原本的性能。若仍采用传统的聚类方法来分析数据间的关联信息,将会出现如下几个问题:
(一)相似性函数失去效用
传统的聚类方法大多采用距离函数来度量相似性程度,在高维空间中,点与点之间的距离会随着维度的增加而失去对比性,距离函数将会失去意义。
(二)类中心无法确定
在聚类过程中,一般使用平均距离确定每次迭代过程中的类簇中心点,在高维情况下,由各个类簇计算得到的均值就会非常接近,聚类过程受到阻碍从而无法确定最终类簇中心点所在的位置。
(三)计算过于复杂
维度上升必然会导致传统聚类方法的计算量增加,效率降低,其应用性也随之受到限制。
由此可见,相似性函数的定义在聚类分析中占领着相当重要的地位。高维空间中的聚类分析必须在获得相似性度量方法的前提下进行,因此,研究一个适用于高维数据的相似性函数具有非常重要的意义,也是目前急需解决的任务。
二、相似性度量方法的介绍
传统的相似性度量指标主要是围绕距离函数而展开的。通常情况下,根据不同的应用场景选取不同形式的相似度函数以便达到更好的描述效果。相似性指标的选取直接决定了聚类结果的质量。
(一)传统的LP距离函数
假设空间中存在着由组成的n个数据样本,其中,i=1,2,…,n,m为每个样本点的属性个数,即维度数。用数据集形式可表示为:

对于空间中的任意两个样本点:Xi=(Xi1,Xi2,…,Xim),Xj=(Xj1,Xj2,…,Xjm),定义距离函数如下:
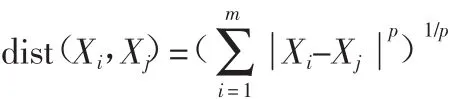
这种度量LP被称作范数,其中P是一个参数。当p=1时,是曼哈顿距离;当p=2时,是欧式距离;当p趋向无穷时,则为切比雪夫距离。该函数在低维空间中能有较好的应用效果,然而在高维空间中的表现结果是极不稳定的。Aggarwal[1]认为,对于满足独立同分布的一组数据点,采用范数作为高维空间中的距离函数时,点与点之间的距离将失去对比性,也就是说,高维空间中查询点到所有点的距离都几乎是相等的。在这种情况下,最近邻点的查询是不稳定的,聚类算法的性能自然也会随之下降。
(二)现有的相似性度量方法
关于相似性度量函数,现已有许多学者提出了相应的改进方法,主要包括函数PIDist(X,Y)[2]、NPsim(X,Y)[3]、Hsim(X,Y)[4]、Close(X,Y)[5]、Esim(X,Y)[6]、Gsim(X,Y)[7]、Psim(X,Y)[8]等。这些函数虽然能适用于高维空间,但是仍然存在着一些不足。
PIDist(X,Y)函数基于等深的思想度量两个样本的相似性,在面对方差较大的数据时应用性受到限制。Hsim(X,Y)和Close(X,Y)函数对数据的量级不敏感,较难发现差值相同的两个维度之间的区别,且在高维空间中不具有对比性。Esim(X,Y)函数是 Hsim(X,Y)和 Close(X,Y)函数的组合情况。Gsim(X,Y)函数的均值权重极奇不稳定。Psim(X,Y)函数的取值则与维数有关,不同维数不具有可比性。这些函数共有的一点,就是忽略了噪声维的影响,而且函数对数据的类型和分布都有着一定的要求。因此,难以广泛应用。
三、高维空间的特点
“维度灾难”最早是由Bellman[8]提出的,指对于一个含有多个变量的函数,随着变量(维度)的增加,网格的数目会呈指数级增长,因此,想要在这个多维网格中去寻求最优化的函数是不太可能的。高维空间中的聚类就是一个多变量求最优的过程,必然会出现“维度灾难”的问题,这是高维空间的特殊性所决定的。
(一)稀疏性
在高维空间中,数据对象的分布具有“稀疏性”。假定d维空间中存在一个包含N个样本点的数据集,并且该数据集中的每一维度相互独立,均服从[0,1]均匀分布,可以认为d维的数据集分布在一个超立方体单元中。若存在一个边长为s的超立方体,那么对于任一样本点而言,落在这个超立方体中的概率为Sd,其中s满足条件0<s<1。显然,随着维度d的增加,这个概率值将会加速衰减,超立方体包含样本点的可能性也会越来越小。例如,当维度d=100时,仅有大约0.59%的数据落在边长为0.95的超立方体中。
更进一步,假定维度d=50,样本点N=1012,数据服从均匀分布的情况下,若将空间中的每一个维度分成完全相等的两部分,那么整个空间就被划分为250个网格单元。此时,包含数据点的网格单元共有1012个,非空网格单元的个数仅占到总网格单元个数的0.08%。由此可见,高维空间中数据的分布存在高度的稀疏性,以至于聚类过程中较难形成簇。
(二)空空间性
对于一组服从正态分布的数据,其中心点到各样本点之间的距离也服从正态分布。随着维度的上升,超立方体单元的内切球的体积会先增加后逐渐减小,如图1。各样本点普遍分布于该超立方体的边角上,中心点附近没有相邻的点存在,这就是所谓的“空空间”现象。若用欧氏距离来衡量样本点之间的距离,那么各样本点到中心点的距离会随维度的增加而增大,最小距离和最大距离的差异逐渐减少,欧氏距离失效,与之相对应的聚类方法也失去效用。
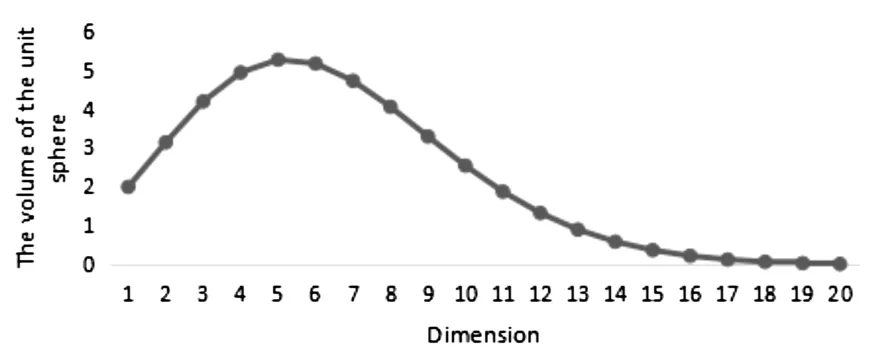
图1超立方体单元内切球体积随维度的变化情况
四、基于信息熵的相似性度量方法
在对高维数据进行聚类分析时需要考虑到两个问题:一方面,随着维度的上升,数据点的分布通常会变得稀疏且远离中心,最近邻距离失去意义;另一方面,对于一个由众多属性构成的数据,影响其最终聚类结果毕竟只是那些少数的相关维,余下的噪声维通常会掩盖住数据真实的信息。本文针对这两点,对距离函数进行重新设计,提出了一种基于信息熵的相似度计量方法,即先通过信息熵筛选相关维,再根据选定的维来计算样本之间的相似性。
(一)信息熵
信息熵反映的是具有确定概率的事件所传递的信息量。在概率论和数理统计中,随机变量的取值是不确定的,但是服从某种概率分布,随机变量的每个取值代表了一定的信息量,平均每个取值的信息量就是该随机变量的信息熵。
假设一个随机变量 X 在集合 S={X1,X2,…,Xn}上取值,并且其概率分布 P(X)={P1,P2,…,Pn},那么,随机变量 X 的信息熵是其所有取值的信息量的期望值,记为H(X),表达式为:
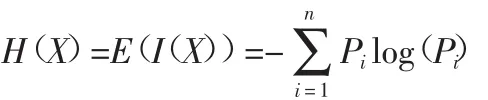
在聚类分析过程中,数据点是围绕着簇中心进行划分的,簇的半径越大说明这一类别的数据点分布得较为分散,簇的半径越小则意味着数据点分布得更为紧密。从单个变量的角度而言,如果该维上相似程度较高的点分布得较为紧凑,而相似程度不高的点分布较为稀疏,那么聚类的结果就更好。因此,利用信息熵进行维度筛选时,信息熵值越大的维就越有可能成为相关维。
假设空间中存在由n个样本点形成的簇X,维数为m,用数据集形式表示如下:

利用信息熵筛选相关维的步骤如下:
1.将第i个维度对应的变量值进行排序,等宽分为k段,并统计每一段内的样本点个数,记为ni,同时得到每一段的概率值
2.根据信息熵的计算公式,依次计算各个维度的信息熵,记为 H={h1,h2,…,hm};
3.将H的值按从大到小排列,选取前d个,生成一个二值向量 δi={δ1,δ2,…,δm},其中 δi=1 的那些维即为满足条件的相关维,也是后续进入相似度计算的相应属性维。
(二)基于信息熵的相似性函数
一个优良的相似性度量函数首先要在计量数据对象的相似性方面具有一定的对比性,易于索引,即能显著区分不同的两个数据点。此外,函数本身不能过于复杂,应符合人们的思维习惯。因此,本文的设计思路如下:(1)在信息熵的分段前提下,依次计算各个维度下分段的宽度其中分别对应第i个维度下的最大值和最小值;(2) 若满足 Xi-yi<Ri,则认为样本点在维度i上具有相似性,权重yi=1,否则默认yi=0。
设计的相似性函数如下:
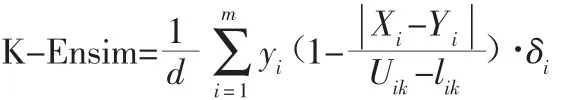
上式中,Xi和Yi分别代表两个样本点X和Y在第i维的取值,δi和yi均为二值向量,d为通过信息熵选取的有效维数,Uik和lik则分别对应于第i个维度下k个分段的上下界值。
K-Ensim相似性函数具有如下几点性质:
1.函数在经过信息熵筛选后的维度上计量相似性。
2.函数只统计相似性较高的维度。样本点在同一维上的差值只有在同一分段内,在该维上才被视为具有相似性。
3.函数引入了Uik-lik这一差值的处理,使得样本点的相似性在不同维度不同分段均具有可比性。
4.函数的取值范围为[0,1],值越大,相似性越高。
(三)高维空间的稳定性分析
为了验证K-Ensim函数在高维空间中的稳定性,利用MATLAB的随机函数按照不同的维数生成数据对象各1000条,其中每一维度都是独立的,且服从正态分布。衡量标准如下:
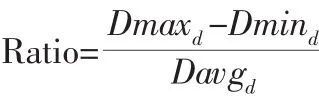
其中,Dmaxd、Dmind和Davgd分别为d维空间中数据点到原点的最大距离、最小距离以及平均距离。

图2 比值Ratio随维度的变化情况
从图2中可以看到,随着维度的增加,上述比值是逐渐上升的,当维度很高时,比值能稳定在一个非零的常数水平。这说明K-Ensim函数在高维空间中能区分最近邻距离和最远邻距离,稳定性得以验证。

表1 基于欧氏距离的聚类结果

表2 基于Ensim函数的聚类结果
五、仿真实验结果及分析
为了进一步验证K-Ensim函数在高维聚类分析中的有效性,从UCI数据库上选取了测试数据集Wine,通过仿真实验来对比欧氏距离和Ensim相似函数在算法应用上的性能差异。Wine数据集共有178个数据样本,分为三类,各类的样本数分别是59、71和48,每条样本均有13个属性。此次实验选取k-means聚类算法,采用欧式距离和K-Ensim函数作为相似性函数分别进行聚类。两种算法所得结果如下:
综合表1、表2的情况看,基于K-Ensim相似函数的聚类算法得到了相对较好的聚类效果,整体准确率提高了10.67%。表2利用信息熵筛选了9个变量进入相似度的计算,算法划分的结果与数据集实际的分布更为接近,每一类的准确率都得到了显著提高,尤其在区分第三类上表现最为明显。实验结果表明本文提出的Ensim改进函数不仅能合理地度量高维数据之间的相似程度,而且能有效地应用于高维数据的聚类分析。
六、结语
本文从聚类分析着手,以经典的K-means算法为例,通过对传统的聚类方法在高维空间中存在的问题进行分析,得到改进相似性函数的必然性和迫切性。针对高维空间中数据分布存在稀疏性和空空间的特性,文中设计了一种基于信息熵的相似性度量方法,该方法通过信息熵筛选相关维,然后将每个维度进行等分,得到各个维度下的固定段长,只统计差值处于同一段长内的相似性。改进的相似性度量函数更具优势:它不仅能缓解高维所带来的影响,还能使聚类算法的精度得到显著的提升。
[1]Aggarwal C C.Re-designing distance functions and distance based applications for high dimensional data[J].Acm Sigmod Record, 2001(01).
[2]Aggarwal C C,Yu PS.The IGrid index:reversing the dimensionality curse for similarity indexing in high dimensional space[C].ACM SIGKDD International Conference on Knowledge Discovery&Data Mining.ACM,2000.
[3]Li W,Wang G,Li K,et al.Similarity measurement method of high-dimensional data based on normalized net lattice subspace[J].Chinese High Technology Letters, 2017(02).
[4]杨风召,朱扬勇.一种有效的量化交易数据相似性搜索方法[J].计算机研究与发展,2004(02).
[5]邵昌昇,楼巍,严利民.高维数据中的相似性度量算法的改进[J].计算机技术与发展,2011(02).
[6]王晓阳,张洪渊,沈良忠,等.基于相似性度量的高维数据聚类算法研究[J].计算机技术与发展,2013(05).
[7]黄斯达,陈启买.一种基于相似性度量的高维数据聚类算法的研究[J].计算机应用与软件,2009(09).
[8]赵恒.数据挖掘中聚类若干问题研究[D].西安:西安电子科技大学,2005.
