基于Hadoop的中医药数据管理策略研究
2018-06-20梁杨丁长松于俊洋
梁杨 丁长松 于俊洋


摘要:目的 为解决传统方法采集、存储和处理海量中医药数据的低效问题,探索数据管理的新策略。方法 根据中医药数据的典型特征,设计基于Hadoop的分层管理架构,对串行数据挖掘算法进行MapReduce化改进;部署单节点服务器和分布式集群,采用8组不同规模的数据集,进行数据采集实验和串并行算法实验。结果 数据传输时间在非分布式环境下通常超过3000 s,增幅较大,而在分布式集群下一般不超过300 s,增幅平缓;当数据规模超过一定范围后,与伪分布式和完全分布式下的并行算法比较,非分布式下串行算法的运行耗时急剧增加。结论 与传统单节点系统相比,基于Hadoop的中医药数据管理平台采集、存储及处理海量数据的效率明显提高,尤其适用于大规模非结构化或半结构化的中医药数据。
关键词:中医药数据;Hadoop;分层管理;MapReduce;分布式
DOI:10.3969/j.issn.1005-5304.2018.05.021
中圖分类号:R2-03 文献标识码:A 文章编号:1005-5304(2018)05-0096-05
Research on TCM Data Management Strategy Based on Hadoop
LIANG Yang1, 2, DING Chang-song1, YU Jun-yang3
1. School of Information Science and Engineering, Hunan University of Chinese Medicine, Changsha 410208, China; 2. School of Information Science and Engineering, Central South University, Changsha 410083, China;
3. Software School, Henan University, Kaifeng 475001, China
Abstract: Objective To solve the inefficiencies of traditional methods of collecting, storing and processing mass TCM data; To explore new strategies for data management. Methods According to the typical characteristics of TCM data, a hierarchical management architecture based on Hadoop was designed and a processing algorithm based on MapReduce was improved. The single node server and Hadoop distributed clusters were deployed. Data acquisition experiment and serial and parallel algorithm experiments were conducted, using eight groups of data sets of different sizes. Results The data transfer time was usually more than 3000 seconds with larger increase under non-distributed environment, while it generally did not exceed 300 seconds with moderate growth rate in distributed clusters. In addition, when the data size exceeded a certain range, the running time of the serial algorithm under non-distributed environment was drastically increased, comparing with the parallel algorithm under pseudo-distributed and fully distributed environment. Conclusion Compared with the traditional single node system, the TCM data management platform based on Hadoop has significantly improved the efficiency of collecting, storing and processing massive data, especially for large-scale unstructured or semi-structured TCM data.
Keywords: TCM data; Hadoop; hierarchical management; MapReduce; distributed
中医药数据具有异构、数据量大、类型多样、价
基金项目:国家重点研发计划(SQ2017YFC170323);湖南省重点研发计划(2017SK2111);湖南中医药大学青年教师科研基金(99820001-221)
通讯作者:丁长松,E-mail:dinghongzhe@yeah.net
值密度低等特征[1]。目前对中医药数据的管理主要依赖于单节点系统。然而,面对海量高维的中医药数据时,单节点系统在实现数据快速迁移、高并发读写及高并行处理等方面的局限性明显[2],难以满足中医药数据高效采集、存储和处理的迫切需求[3-4]。为了在合理的时间约束内完成对大规模中医药数据的处理,亟需研究更高效的数据管理模型和处理算法[5]。为此,本研究结合中医药数据特征,针对传统中医药数据管理方法的局限性,设计了基于Hadoop的中医药数据管理平台。
针对海量数据分布性、异构性、多样性的特点,崔杰等[6]从系统编程实现的角度采用了MVC三层架构设计,结构清晰,易于扩展,但其结构型模式数据交互性差,访问效率低;针对传统关系型数据库无法满足海量数据存储与访问的问题,姚林等[7]提出了基于NoSQL的分布式存储与扩展解决方法,有效降低了数据迁移的代价和风险,提高了大数据高并发读写性能;李伟卫等[8]将MapReduce编程模型应用在数据挖掘算法中,有效提高了大数据挖掘工作的效率。在上述研究基础上,本研究基于Hadoop分布式集群,提出的中医药数据管理平台分层设计了数据采集、存储管理及数据处理模块,对应解决海量数据在“采集-存储-分析”过程中面临的低效问题[9]。与此同时,数据处理模块采用基于MapReduce并行处理框架改进的数据挖据算法,对任务进行并行化处理,在面对海量中医药数据时提升了系统的计算效率[10]。
1 数据管理平台分层設计
1.1 主体架构
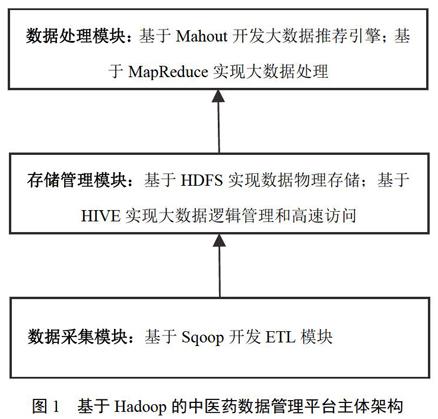
结合中医药数据的海量、异构、多样、复杂等特性,从分层管理的角度,设计并实现基于Hadoop的中医药数据管理架构,并对系统结构进行模块化分层,耦合度低、内聚性高、扩展性好、独立性强。数据管理平台整体架构由3个关键模块(数据采集模块、存储管理模块和数据处理模块)构成,主体架构见图1。
图1 基于Hadoop的中医药数据管理平台主体架构
3个关键的功能模块分别代表数据管理平台的3个层次,并分别对应数据获取、数据存储与查询管理、数据处理分析这3个核心过程,属层次化设计模式。数据流向由下至上,首先经过采集模块对数据信息进行收集,然后流向数据库所在层对数据进行存储管理,最后流向数据处理模块完成分析和处理。
1.2 数据采集模块
数据采集层的任务是把不同数据源中的数据采集并导入存储设备,即数据传输的过程。采集模块核心部分是基于Sqoop开发的数据仓库模块(ETL模块),可用于传统关系数据库和基于Hadoop的中医药数据管理平台间的数据交换,能极大方便和简化数据迁移,改善数据互操作性,优化数据利用方法。
具体数据传输过程:首先,ETL模块通过JDBC与数据源连接,将采集到的SQL类型数据转为Sqoop类型数据。然后,将其作为格式化的输入数据提交给MapReduce任务。最后,启动部分数量的Map和Reduce任务,将数据存入分布式文件系统。
1.3 存储管理模块
存储管理模块基于分布式文件系统(HDFS)实现底层数据的物理存储。访问数据时,不仅能保证系统具有较好的整体可用性和可靠性,而且具有较高的吞吐率。此外,本层采用Hive技术,对基于Hadoop的中医药数据管理平台的数据进行整理、查询和存储,高效地实现数据存储管理功能。
在Hadoop集群上,本层模块采用HDFS作为大数据的物理存储单元,并利用Hive技术创建Hive数据仓库,用作数据存储的逻辑单元。Hive提供了类似于结构化查询语言(SQL)的Hive QL,高效地管理HDFS文件,弥补了SQL和关系型数据库在大数据管理上的不足。
具体过程:Hadoop集群采用Master/Slave结构,指定1台主机作为Master节点,负责NameNode和TaskTracker的任务。其中,NameNode的主要作用是管理文件系统的命名空间,利用相关接口对文件的访问进行控制;而DataNode则按照NameNode指令以Data Block方式存储中医药数据。HDFS采用DataNode间的数据拷贝策略,以尽量减少单点故障可能造成的不利影响,提高存储管理模块的安全性、鲁棒性及可靠性。
1.4 数据处理模块
数据处理模块主要功能是高效地完成中医药大数据的分析处理。其中,数据挖掘算法对大数据的预测分析起到了关键的作用,为数据处理决策过程的重要基础。本研究根据中医药数据海量、异构等特点,设计了基于Hadoop的大数据处理模块,结构见图2。
图2 大数据处理模块
处理模块层的关键是集成相关大数据处理算法,如数据挖掘算法、大数据推荐算法等。因此,为更好实现数据推荐,本模块采用Mahout技术,其提供的机器学习库能高效实现数据推荐、分类、聚类等算法。
处理模块层实现过程如下:首先,DataModel模块根据用户习惯将来自下层模块的中医药数据进行加载和存储;然后,Neighborhood模块对DataModel存储的数据进行使用,并根据多个用户间的相关性来计算用户相似度;最后,把用户相似度作为数据推荐模块的输入,通过数据推荐算法输出推荐结果。
2 基于MapReduce的算法改进
MapReduce并行计算框架是数据处理模块的核心,负责大规模中医药数据集的并行计算、任务调度以及监控等,其输入来自于HDFS文件。当执行MapReduce程序时,Map任务将运行在集群的多个乃至全部节点上,从而能处理任意的文件输入。Mapping阶段生成的中间键值对必须在节点间进行交换,通过关联到数值上的不同键来隐式引导,把具有相同键的数值发送到运行同一个Reduce任务的结点进行合并,形成最终结果。
处理算法的优劣在软件层面决定了处理效率的高低。因此,针对基于传统关联规则的串行数据挖据算法中存在的效率低、内存消耗大、时间复杂度高、实现方法复杂等缺陷,本研究提出基于MapReduce改进的并行挖掘算法,其具体流程如下:
①将原始事务集D划分为N个(TID,list)格式的数据块,分配给M个节点执行独立计算。其中,list是对应的项目,TID为事务标识符。
②执行Map程序,首先扫描各数据块,生成局部频繁1项集,再生成各数据块的局部候选k项集Cki,并计算局部候选项集的局部支持度local_supp。
③在相应节点执行Reduce程序,合并Map任务的输出结果。
④在相应节点上,通过Reduce函数对不同数据块相同候选项集的支持度求和,进而得出全局支持度。
⑤将局部候选k项集的全局支持度和最小支持度阈值进行对比,进一步求得局部频繁k项集。
⑥将r个局部频繁k项集进行融合,进而求得全局频繁k项集。
⑦重复迭代,直至结束。
该算法的时间复杂度为O(n2),对应的伪代码见图3。
基于MapReduce改进的并行挖据算法
输入 原分块后的事务集Di,最小支持度阈值min_supp
输出 频繁项集L
Begin
L1=find_frequent_1-itemsets(Di);
for (k=2; Lk-1!=Φ; k++)
{
Cki=apriori_gen(Lk-1); ‘生成局部候选k项集
For each transaction t∈Di
{
Cli=Map();
}
Lk=Reduce();‘Lk是全局频繁k项集
}
return L;
procedure Map(TID, list)
for each Im∈Cli‘Im是Cki的项
{
EmitIntermediate(Im, local_supp);
}
procedure Reduce(Im, local_supp)
result=0;
for each Im∈Cli
result+=ParseInt(local_supp);
Emit(Im, result);
End
图3 基于MapReduce的并行算法伪代码
3 实验设计与检验
3.1 实验平台部署
本研究在实验室条件下搭建Hadoop平台,将中医药数据管理平台部署在具有6个节点分布式集群上,包括1个NameNode和5个DataNode。NamNode主要负责管理HDFS,DataNode主要负责存储数据文件。
NameNode硬件配置。CUP:Intel? Core?i3-7100,双核四线程处理器;内存:16 GB;硬盘:2 TB。
DataNode节点硬件配置。CUP:Intel? Core? i3-7100,双核四线程处理器;内存:8 GB;硬盘:2 TB。
Hadoop集群软件配置。操作系统:Ubuntu14.04(64位);SSH:client和server;Java:OpenJDK 7; hadoop-2.7.1;数据库:MongoDB 3.2.8,Hive1.2.1,Eclipse;虛拟机:VirtualBox。Hadoop平台的具体搭建步骤不赘述。
此外,考虑到与分布式集群的比较,并尽量接近实际应用,本研究选择较高的硬件配置来部署单节点服务器。CUP:Intel? Core?i5-7500,四核四线程处理器;内存:16 GB;硬盘:4 TB。在非分布式实验中选择关系型数据库MySQL进行数据管理。
3.2 数据来源
采用的数据源来自国内中医药在线公开的药方数据库(地址:dbshare.cintcm.com:8080/DartSubject/ index.htm、db.yaozh.com、cowork.cintcm.com/engine/ windex.jsp、www.taozhy.com/ShuJuKu/default.aspx、www.tcm100.com/ZhongYiYaoShuJuKu.aspx等),数据总量为1 TB,由于数据量有限,实验仿真允许选择性重复使用相关数据。
3.3 结果与分析
3.3.1 数据采集实验比较
数据采集时间以数据传输时间作为主要评价指标。本研究中的数据采集模块采用了支持并行的Map和Reduce任务来提高数据的传输速率。因此,在不同集群配置下需通过多次不同数据规模的实验找出该集群整体性能和任务数能同时达到的最优平衡点。结果见图4。
图4 数据采集实验结果
为计算数据由数据源到目标文件系统的传输时间,实验设计如下:文件系统每接收到一条传来的数据即自动插入时间戳,当所有数据传输完成时根据首尾两条数据的时间戳之差即可计算出全部数据的传输时间。当数据规模较大时,传统单节点系统数据的传输时间通常超过3000 s,并且随着数据量的不断增大,数据传输过程的耗时呈线性大幅增加。而本研究的数据采集模块在数据量达到集群最大负载能力之前,随任务数的增多,传输时间不断减小;之后,即使数据量继续增加,传输时间的增幅也相对缓慢。此外,本研究采集模块基于Hadoop分布式集群的高可扩展性,可以方便地通过增加DataNode节点来提高Map和Reduce任务数阈值,进一步提升并行工作能力,采集更大规模的数据时能够减缓耗时增长率,甚至降低耗时。因此,与传统单节点系统比较,Hadoop分布式集群具有更强的数据传输能力。
3.3.2 同一单节点下串行算法和并行算法实验比较
Hadoop集群可以在单节点上以伪分布模式运行,通过不同Java进程模拟各类节点。实验设计如下:在同一单节点服务器上,首先以非分布模式运行串行算法,然后以伪分布模式运行并行算法。结果见图5。
图5 单节点串并行算法实验对比
在同一单节点硬件环境下,当数据规模不大时,串行算法的执行速度较快,但随着数据规模的持续增大,一旦超出一定的规模值(图5中为106 GB附近)时,串行算法的执行时间迅速增加,处理性能严重降低,最后甚至会因内存不足而无法完成任务。基于MapReduce的并行算法可通过并行任务间的交互较好地利用内存,随着数据规模的增加,逐渐体现出优势。
3.3.3 非分布式下串行算法和完全分布式下并行算法实验比较
搭建真实的计算机Hadoop集群,在完全分布式环境下运行MapReduce化的并行算法。实验设计如下:分别在部署好的单节点服务器和完全分布式的Hadoop集群上处理同等规模的相同数据集(与图5实验数据集相同),其中单节点系统采用串行算法以非分布模式运行,Hadoop集群采用基于MapReduce改进的并行挖掘算法以完全分布模式运行。结果见图6。
图6 非分布式和完全分布式实验对比
当数据规模较小时,实验结果与图5类似,非分布模式下串行算法的耗时较少。不同的是,随着数据规模的持续增大,完全分布模式下并行算法的挖掘时间近似于线性增加,耗时增幅相对较小,能在有效的时间约束内完成任务。有效解决了在应对大规模数据时单点主机处理耗时迅速增加、处理性能严重降低的问题。上述分析表明,面对大数据环境下的数据处理过程,多采用串行算法的单点系统存在局限性,而支持并行计算框架的分布式集群则表现出良好性能。
4 小结
针对中医药数据量大、数据异构、价值密度低等特点,如何高效地对中医药数据进行采集、存储和处理是管理中医药数据的核心问题。本研究在分析现有的大数据管理架构和关键算法的基础上,首先设计了基于Hadoop分布式集群的数据管理平台整体架构,其次分别详细设计并实现了数据采集、存储管理和数据处理等3个核心模块,然后从算法层面上提出了基于MapReduce改进的数据挖掘算法,最后实验结果表明,本文设计的中医药数据管理平台通过对系统架构的模块化分层设计以及处理算法的改进,使中医药大数据的采集、存储和处理过程的耗时大幅减少,在大数据管理方面比传统单节点系统有更优的性能。采用更大的集群规模和數据集,进一步细化系统架构设计,优化大数据处理算法,是下一步研究方向。
参考文献:
[1] 于琦,崔蒙.中医药信息的特征研究[J].中国中医基础医学杂志, 2012,18(10):1137-1139.
[2] 杨薇,崔英子,杨海淼,等.医疗大数据在中医药研究领域的应用与思考[J].长春中医药大学学报,2016,32(3):625-627.
[3] 邓宏勇,许吉,张洋,等.中医药数据挖掘研究现状分析[J].中国中医药信息杂志,2012,19(10):21-23.
[4] 尚尔鑫,范欣生,段金廒,等.基于关联规则的中药配伍禁忌配伍特点的分析[J].南京中医药大学学报,2010,26(6):421-424.
[5] 佟旭,谢晴宇,孟庆刚.论大数据时代背景下中医药数据集成分析的科学价值[J].中国中医药信息杂志,2015,22(8):1-3.
[6] 崔杰,李陶深,兰红星.基于Hadoop的海量数据存储平台设计与开发[J].计算机研究与发展,2012,49(S1):12-18.
[7] 姚林,张永库.NoSQL的分布式存储与扩展解决方法[J].计算机工程, 2012,38(6):40-42.
[8] 李伟卫,赵航,张阳,等.基于MapReduce的海量数据挖掘技术研究[J].计算机工程与应用,2013,49(20):112-117.
[9] 吕峰,李丽娇,高云英,等.基于Hadoop在中医药数据挖掘中的应用[J].电子设计工程,2016,24(22):112-114.
[10] 黄斌,许舒人,蒲卫,等.基于MapReduce的数据挖掘平台设计与实现[J].计算机工程与设计,2013,34(2):495-501.
(收稿日期:2017-07-04)
(修回日期:2017-08-08;编辑:向宇雁)
