虚拟变量回归在SPSS中的分析与实现
2018-06-15曹玉茹
曹玉茹
(上海对外经贸大学 统计与信息学院,上海 201620)
0 引言
在计量经济学的分析中,利用回归模型来寻找经济变量间的关系是广泛应用的一种数量分析方法。通常情况下,回归分析中变量都是定量数据,原因是模拟回归需要样本数据。然而在实际的操作中,模型中只考虑定量变量是不全面的。因为很多经济现象不仅受一些定量数据的影响,还会受到一些定性数据的影响。比如自然灾害、战争等特殊时期对经济的影响,特殊政策的颁布对经济产生的影响等。如果能确定某一研究结果存在这种定性影响,那么仅仅用定量数据对被解释变量进行解释显然是不够严谨的,很可能对模型的预测结果产生很大偏差。但由于定性数据是不等距的,不符合回归分析中对自变量要求,如果直接把定性数据直接引入线性回归模型,结果很难解释,且容易存在很大偏差,此时可以考虑将虚拟变量引入回归模型来解决此类问题。而关于虚拟变量回归在软件中的实现却不是非常方便,尤其对于各种加法和乘法规则的实现,相应的研究也不多,本文利用虚拟回归模型与方差分析及协方差之间的关系,提出了一种基于SPSS软件的虚拟变量回归模型软件实现的新方法,通过实际案例得到了较好的验证。
1 虚拟变量回归模型和方差分析的关系
虚拟变量本质上算不上一种变量类型(如连续性变量分类型变量),虚拟变量技术就是把多分类型变量转换成二分类型变量,即虚拟化,再把其作为解释变量纳入到回归模型中的一种方法。如果多分类变量有k个类别,则可以转化为k-1个二分变量。每个二分变量用0,1赋值,1表示受到某种因素影响,0表示没有受某种因素影响。一般将基础类、肯定类设置为1;比较类、否定类设置为0的原则。虚拟化后的变量将可以直接纳入回归模型进行分析和预测。
在实际数据分析中,如果不去考虑具体的模型结构和预测问题,关于影响因素的显著性问题可以使用协方差分析来解释,其中把定性因素作为固定因素,定量因素作为协因素考虑,其结论主要解释定量变量的影响效果。但如果进一步想了解定性因素对结果影响程度的大小,一种解决方法是分组进行两类情况的回归,检验参数是否显著不同,这种方法一方面计算比较繁琐,最重要的是它割裂了变量之间具有交互影响的情况,所以不全面;还有一种方法就是用全部变量作单一回归,其中包含定量数据也包含定类数据,从应用的角度出发,如何将这种转换的理论利用统计软件实现验证,这正是本文讨论的问题。
鉴于虚拟变量回归和方差分析的密切关系[1],本文将方差与协方差分析的结果应用到虚拟变量回归中,反推出虚拟变量回归模型的具体形式,并提取出更多的信息。设因素有k个总体或水平,检验k个总体的均值是否相等,提出如下假设:

假设有三个总体A B C,虚拟变量设置如下:
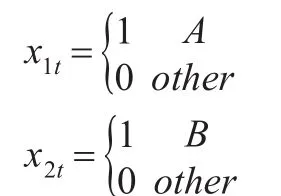
虚拟变量模型为:

对模型(2)求期望:
当X1t=X2t=0时,E(y)=β0即总体C的均值E(C)。
当 X2t=0时,E(y)=β0+β1即总体 A 的均值 E(C)'β1为总体A与C的均值差。
当 X1t=0时,E(y)=β0+β2即总体B的均值 E(C)'β2为总体B与C的均值差。
则单因素方差分析的假设(1)等价于:
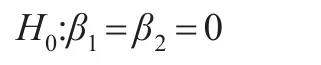
H1:β1'β2至少有一个不等于0,即虚拟变量模型中的总体显著性F检验。
关于单因素方差分析中的多重比较指的是通过对总体均值之间的配对比较来进一步检验到底哪些均值之间存在差异,常用最小二乘法(LSD)来解释。
从上面的分析可以看出:虚拟自变量回归分析中的线性关系是否显著问题与单因素方差分析中的因素的显著性描述是完全一致的,也就是说单因素方差分析问题可以用回归分析方法解决,反之自变量都是0-1型虚拟变量的回归分析问题也可以用方差分析的思路来解决问题。
在文献[2]中作者已经证明了行列因素分别为双水平的双因素无重复试验方差分析问题在判断行列因素是否有影响的F检验中等价于回归分析问题中的系数显著性的t检验。
2 虚拟变量回归模型分类
2.1 单一虚拟变量的回归模型[3]
一种情况是:回归模型中只包含虚拟变量作为解释变量。比如要分析A校的本科毕业生与B校的本科毕业生在收入上是否存在显著差异,则可以设模型为:

其中Y1为收入变量,Dt为毕业学校的虚拟变量,当数据来源是A校毕业生时Dt为1,反之为0,当选择工作年数相同的样本分析,在满足各种检验的条件下参数B2的估计值就是两种毕业生收入的平均差异。如果解释变量是多分类的(假设有N类),以某一个特征为参考可以设置N-1个虚拟变量。在SPSS数据分析模块中,此模型实质等同于单因素方差分析模型或者均值比较模型,即可以使用方差分析给出是否存在差异性的解决方案,但如果要对两校毕业生的收入作预测则最好使用回归分析模型。
2.2 多个虚拟变量的回归模型[4]
如果模型中想要同时分析多个定性变量的影响,比如在上述分析中加入性别因素的影响,此时可以用两个虚拟变量。对于每个虚拟变量的取值仍然是0或1,如果是男生虚拟变量D2t取值为1,否则为0。模型为:
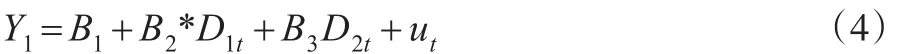
此模型说明相同性别中A校比B校毕业生的收入高B2,相同学校,性别男的收入比性别女的收入高B3。
但上面的模型隐含了一个假设条件就是:两校毕业生之间性别的级差效应保持不变,在两种性别之间学校的级差效应保持不变。这种假设显然是有问题的,A校的男性和女性在收入方面的差距和B校的男女生收入差距可能不一样,这就存在所谓的交互效应,简单来讲,就是说不同学校和性别这两个因素对于收入的影响不是独立的,而是互相影响,也即有交互效应。所以模型应该修改为:
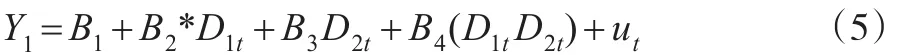
至于模型的选择取决于模型检验的结果,如拟合优度,标准误差大小,自变量的显著性以及考虑自变量之间的共线性问题是否影响模型精度。
2.3 复合类型变量回归模型[5,6]
假如定量变量X和定量变量Y存在显著的相关关系,同时发现还有一个定性因素对Y的变动产生影响,此时可以建立一个如下的回归模型:
此模型采用加法方式引入虚拟变量,主要描述截距的变换,模型表明:在不考虑定性因素影响的情况下,常数项即模型的截距为B1,在考虑定性因素的情况下,模型的截距为B1+B2。但此模型仅考虑了定性变量的单独影响,而实际中由于定性变量不同相应的定量变量对应变量的影响有所不同,即可能存在交互影响,因此模型可修改为:

2.4 基于SPSS软件的模型实现
下面通过实例验证说明虚拟自变量回归在统计软件SPSS中实现的新方法:
利用spss自带的数据文件Employee.sav研究企业的当前工资水平与哪些因素相关,及其具体的的影响程度问题为例,分析基于虚拟变量的回归模型的spss实现方法研究。基于虚拟变量回归模型的spss代码实现:
RECODE jobcat(1=1)(ELSE=0)INTO cat1.
RECODE jobcat(3=1)(ELSE=0)INTO cat2.
REGRESSION
/MISSING LISTWISE
/STATISTICS COEFF OUTS R ANOVA
/CRITERIA=PIN(0.05)POUT(0.10)
/NOORIGIN
/DEPENDENT salary
/METHOD=STEPWISE educ jobcat salbegin jobtime prevexp minority cat1 cat2
/SAVE ZRESID.
EXECUTE.
注:cat1和cat2是jobcat变量的两个虚拟自变量,其中cat1表示是否为Clerical(办事员),cat2为是否为Maneger(经理)。模型指标结果如表1。
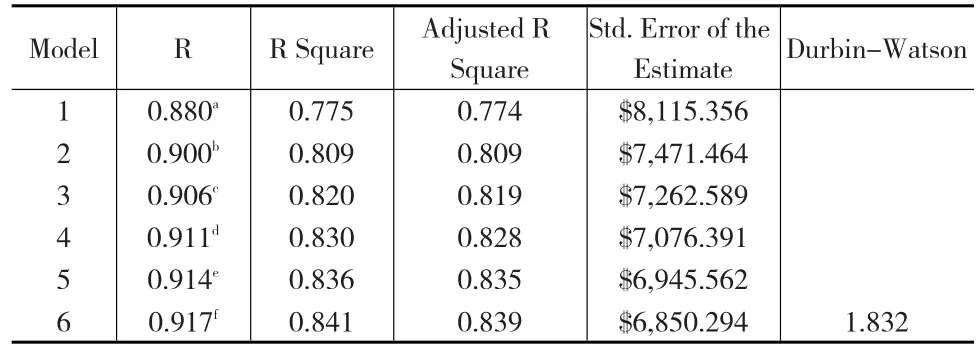
表1 模型综述表g
模型拟合优度0.839,估计误差6850.294,DW参数为1.832。
基于协方差分析的SPSS实现及其结果(表2):

表2 模型综述表
UNIANOVA salary BY jobcat minority WITH edu csalbegin jobtime prevexp
/METHOD=SSTYPE(3)
/INTERCEPT=INCLUDE
/CRITERIA=ALPHA(0.05)
/DESIGN=educ salbegin jobtime prevexp jobcat minority jobcat*minority.
EXECUTE.
在前面的无交互虚拟变量模型中minority对因变量不存在显著影响,但是这里显然可以看出jobcat与minority之间存在对结果影响的交互作用,这点启发我们对于原来的虚拟变量回归模型做进一步修改,添加交互效应到模型中。
进一步通过虚拟自变量完成协方差分析及相应结果(表3):
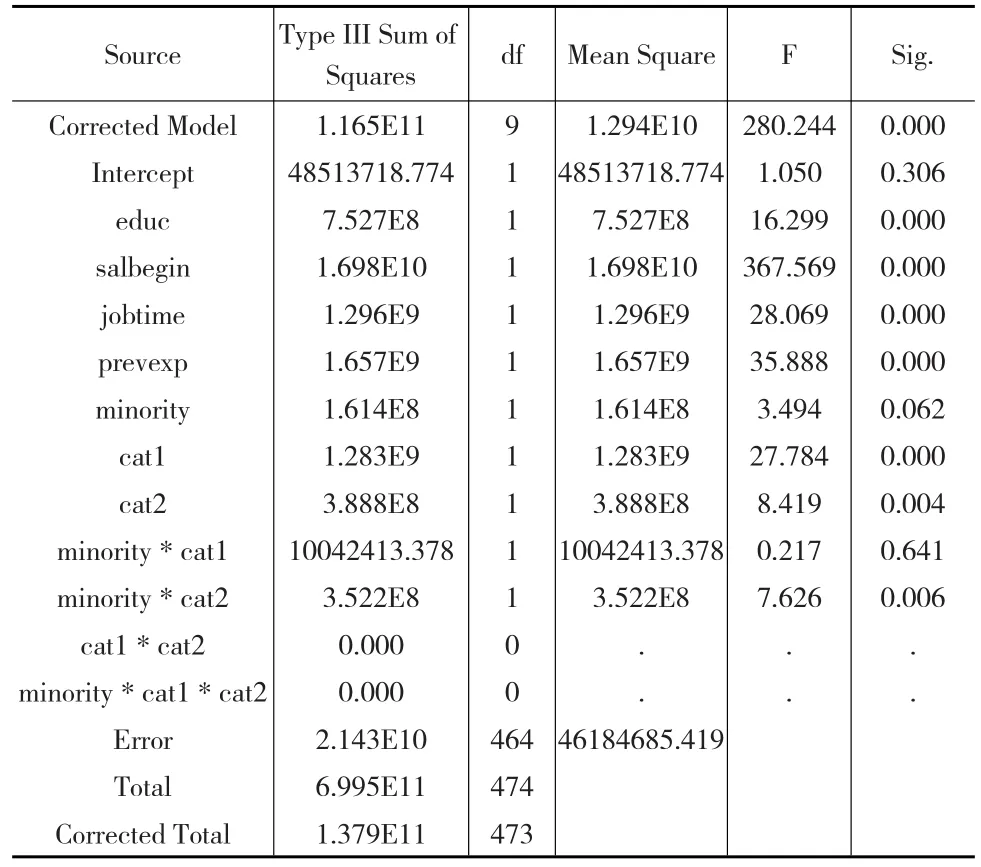
表3 自定义模型综述表(含交互)
UNIANOVA salary BY minority cat1 cat2 WITH educsalbegin jobtime prevexp
/METHOD=SSTYPE(3)
/INTERCEPT=INCLUDE
/CRITERIA=ALPHA(0.05)
/DESIGN=educ salbegin jobtime prevexp minority cat1 cat2 minority*cat1 minority*cat2 cat1*cat2 minority*cat1*cat2.
EXECUTE.
即cat2与minority之间存在对结果影响的交互作用,这点启发我们对于原来的虚拟变量回归模型做进一步修改,添加交互效应到模型中。根据上述分析可以考虑利用虚拟变量模型公式(5)进行分析,具体操作如下,首先得到交互项cat2m。
COMPUTE cat2m=cat2*minority
然后利用非参数检验证明虚拟变量的乘积cat2m是对因变量显著影响的,方法结果(表4和表5):
NPAR TESTS
/M-W=salary BY cat2m(0 1)
/K-S=salary BY cat2m(0 1)
/MISSING ANALYSIS.
EXECUTE.

表4 非参数检验结果a

表5 非参数检验结果a
再利用公式(5)及回归分析模型得到如下结果(下页表6):
REGRESSION
/MISSING LISTWISE
/STATISTICS COEFF OUTS R ANOVA
/CRITERIA=PIN(.05)POUT(.10)
/NOORIGIN
/DEPENDENT salary
/METHOD=STEPWISE educ salbegin jobtime prevexp minority cat1 cat2 cat2m
/RESIDUALS DURBIN
/SAVE ZRESID.
EXECUTE.
同时得到具体的虚拟变量回归模型为:
Y=0.646*salbegin-0.145*prevexp+0.096*jobtime-0.237*cat1+0.113*educ+0.053*cat2m
结果得到模型拟合优度0.841,估计误差6808.709,DW参数为1.830,模型参数得到改善。且通过模型得知办事员的当前工资水平较其他类别员工要低一些,这也符合实际情况。
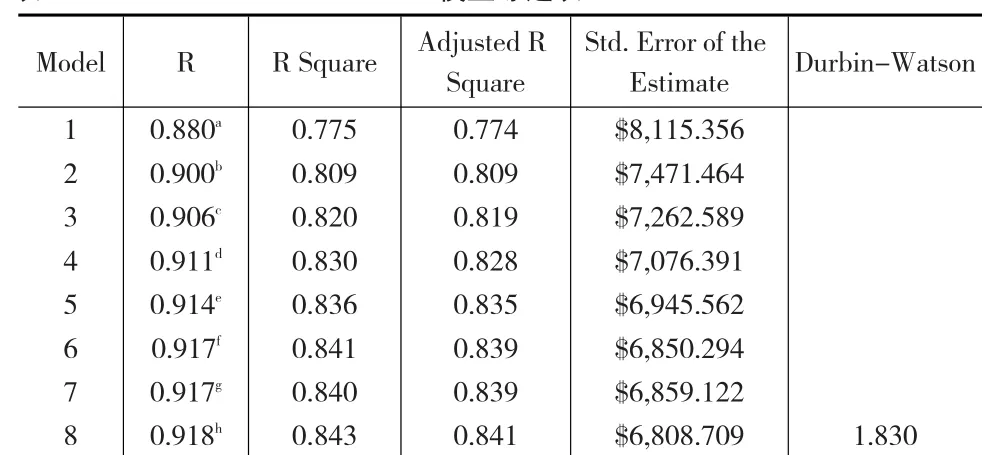
表6 模型综述表i
进一步利用绘图程序如下完成标准化残差震动情况对比。其中,虚线表示无交互虚拟变量回归模型标准化残差的震动情况,实线表示新方法得到的虚拟变量回归模型的标准化残差震动情况,得到明显改善。见图1。
*Sequence Charts.
TSPLOT VARIABLES=ZRE_1 ZRE_2
/NOLOG.

图1 两种模型序列图对比
因此,从表7中可以看出无论是模型的拟合优度、估计误差还是从模型残差的震动情况来看,经过改良后的虚拟变量交互回归模型的效果更好,更适宜于预测估计。相比较协方差分析的参数情况,虽然拟合度更高,残差标准差也更小,但在SPSS中方差分析只给出因素重要性指标,不能直接给出模型的具体公式,对于利用模型进一步预测来说很不方便,因此实用性并不如虚拟变量回归模型好。
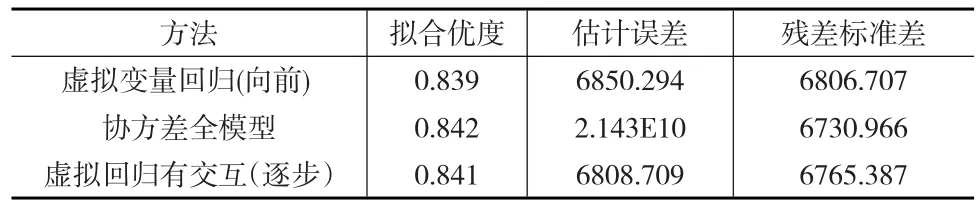
表7 三种模型估计指标汇总对比
综上所述,在虚拟变量回归模型分析中,可以结合方差协方差分析结果,对虚拟回归模型的实现方法进行改进,从而得到更优化的模型参数和估计效果。
3 结论
考虑到经济现象的复杂性,定性因素的影响非常多,其影响的程度也有所不同,因此要判断模型中何时要加入虚拟变量,采用何种方式加入,首先必须根据实际的经济背景并运用正确的经济理论进行分析,其次在引入虚拟变量的前后模型的模拟结果进行比较,如果回归的拟合优度或估计标准误差等效果更好,则可考虑增加虚拟变量;最后如果能结合方差、协方差分析模型并利用SPSS软件来分析考虑交互因素的作用,将会得到更好的回归结果。本文通过具体的示例展示了这种研究方法的优点。
[1]甘伦知.虚拟变量回归和方差分析的联系[J].统计与决策,2011,(8).
[2]陈凌宇,王桂明.虚拟变量在方差分析中的应用[J].统计与决策,2009,(11).
[3]章晓英.虚拟变量在线性回归模型中的应用[J].重庆工业管理学院学报,1998,(4).
[4]刘振亚.计量经济学教程[M].北京:中国人民大学出版社,1997.
[5]庞皓.计量经济学[M].成都:西南财经大学出版社,2004.
[6]贾俊平.统计学[M].北京:中国人民大学出版社,2007.
