基于多损失的生成式对抗目标跟踪算法
2018-06-12张毅锋
程 旭 周 琳 张毅锋,3
(1东南大学信息科学与工程学院, 南京 210096)(2中船重工鹏力(南京)智能装备系统有限公司, 南京 210003)(3南京大学计算机软件新技术国家重点实验室, 南京 210023)
跟踪算法通常可分为生成式跟踪算法和判别式跟踪算法两大类[1].生成式模型是在当前时刻搜索与目标表观特征最为相似的图像区域作为目标跟踪的结果,包括增量视觉跟踪(IVT)[2]、视觉跟踪分解[3]等;其缺点是没有利用目标周围的背景信息,易发生目标漂移.随着机器学习技术的快速发展,基于判别式模型的学习跟踪算法已成为近年来研究的热点.该类算法将目标跟踪阐述为二元分类问题,在跟踪决策时利用目标周围的背景信息,将目标从背景中分离出来,常见算法包括集成跟踪算法[4]、多示例跟踪算法[5]、跟踪学习检测算法[6]、MEEM算法[7]、SCM算法[8]等.
Wang等[9]最早将深度学习算法引入到目标跟踪领域.随着卷积神经网络在计算机视觉领域的发展,文献[10]将卷积神经网络输出50×50像素的特征图像来表示每个像素处于目标之内的概率.Nam等[11]提出了MDNet网络,其网络结构输出K个全连接层,对应K个训练的序列,通过卷积神经网络学习性能强的分类器,将目标和背景分开,缺点是速度慢.Tao等[12]提出了一种通过相似性学习方式进行目标跟踪的孪生网络,将训练好的网络直接应用于跟踪过程,无需更新.Zhang等[13]提出了一种不需要预训练的卷积神经网络模型框架,与传统的基于深度学习的算法相比,该算法无需大量的数据预训练模型,设计的神经网络结构简单.
本文采用对抗式生成网络的结构来跟踪目标,从外界干扰的图像中重构高清晰的目标表观.通过该算法重构的目标图像能够保留原目标的结构信息,提高目标跟踪的效率.
1 生成式对抗网络模型
生成式对抗网络(generative adversarial nets,GAN)是一个“二元极小极大博弈”问题[14],其特点是2位博弈方分别由生成式网络和判别式网络充当.生成式网络用来捕获样本数据的分布,生成与原始数据相似的图像,看起来自然真实,试图欺骗判别器;判别式网络用于估计一个样本来自于训练数据而非生成数据的概率,判别式网络试图努力不被生成式网络欺骗,从而形成竞争与对抗.GAN网络模型结构见图1.
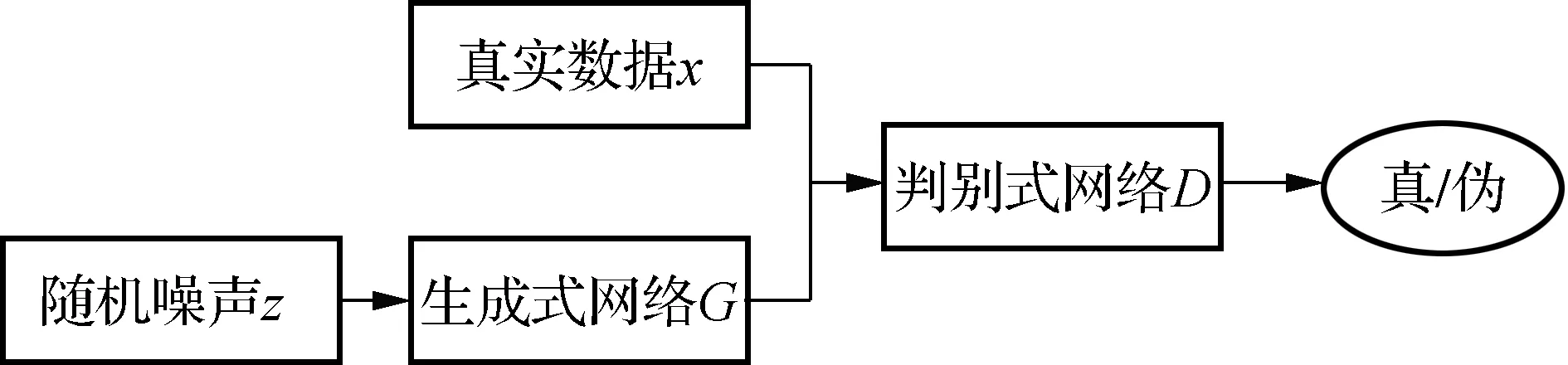
图1 生成式对抗网络原始模型结构
2 多损失生成式对抗目标跟踪算法
本文利用生成式对抗网络从模糊的图像中恢复出清晰的表观图像.在复杂的环境下,遮挡、光照变化和目标快速运动等外界因素通常会导致目标特征难以提取或者提取的目标特征不准确,造成跟踪目标失败.针对上述问题,采用生成式对抗网络从输入的问题视频帧目标Iin中重构清晰的目标表观If,得到高分辨率的目标表观,再与目标模板匹配,找到精确的位置.
2.1 总体架构
随着GAN理论的不断发展,学者们开始考虑根据各种实际问题来定义输入分布和期望分布.例如,输入分布为一幅低分辨率图像,输出分布为高分辨率的目标图像,希望系统能够学习到低分辨率图像和高分辨率图像之间的映射,输出满足一个预期的期望分布.GAN的本质就是学习输入和输出两者之间的映射.
在实际情况中,目标遮挡、尺度变化、运动模糊以及外界环境光照变化等因素直接影响着跟踪性能.结合深度学习前沿对抗生成网络(GAN)理论,本文提出了一种对抗生成网络结构,生成式网络G由编码器和解码器2个部分构成.跟踪时,编码器作为目标的特征提取器;编码器对所有可能的外界情况(遮挡、光照变化和运动模糊)采用相同的网络结构,并且共享网络的参数值GE(θ),而编码器针对遮挡、光照变化和运动模糊3种不同的场景干扰,分别采用遮挡解码器、光照变化解码器和运动模糊解码器完成对目标图像的重构.为了应对目标遮挡等情况造成的信息缺失问题,本文从不同角度定义了损失函数,通过对损失函数求梯度来逐级更新生成式网络G的参数.将生成式网络得到的图像和真实图像作为判别式网络的训练数据集.
图2为本文提出的基于多损失的生成式对抗目标跟踪算法框图.
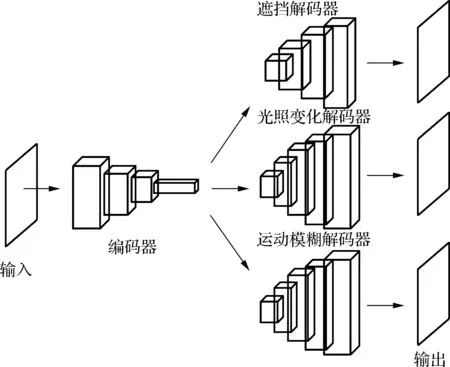
图2 基于多损失的生成式对抗目标跟踪算法框图
2.2 网络结构
本文设计的网络在跟踪过程中能够应对目标遮挡、光照变化、运动模糊等挑战.当目标发生遮挡时,利用训练得到的生成式网络G能够从一幅遮挡的输入图像中重构出清晰的目标.在ImageNet数据集上训练生成式网络G的参数θg,损失函数值最小时生成式网络G的参数为
(1)
式中,N为需要训练图像的数目;Loss()为损失函数;In,occ为第n幅遮挡的图像;In为原始未遮挡的图像.式(1)表示第n幅遮挡的图像In,occ经过生成式网络G重构后与原始未遮挡图像的相似程度.判别式网络的参数θd也可用类似方法得到.训练得到的生成式网络G能够生成与没有遮挡时一致的图像,使得判别式网络D难以判别是真实图像还是生成器生成的图像.
生成式网络G由编码器和解码器2个部分组成(见图2).在编码器部分,遭受外界环境干扰的目标(遮挡目标和低分辨率目标)都会进入具有相同参数设置的编码器进行处理,本文使用3个卷积层来降低输入图像帧的分辨率,每次卷积后特征数量都会翻倍增加.遮挡解码器用于重构遮挡的目标;光照变化解码器用于重构遭受光照表观发生变化的目标;运动模糊解码器用于重构低分辨率的目标.网络中每一层输出作为下一层的输入.干扰方式不同,解码器的结构也不尽相同.对于目标遮挡,使用与编码器相对称的3个转置卷积层重构出目标;对于低分辨率的目标,则使用4个转置卷积层来提高图像帧的分辨率.将泄漏线性整流作为编码器阶段的激活函数,整流函数作为解码器的激活函数.判别式网络D的结构与生成式网络G中的编码器结构类似.网络结构中具体参数见表1~表4.
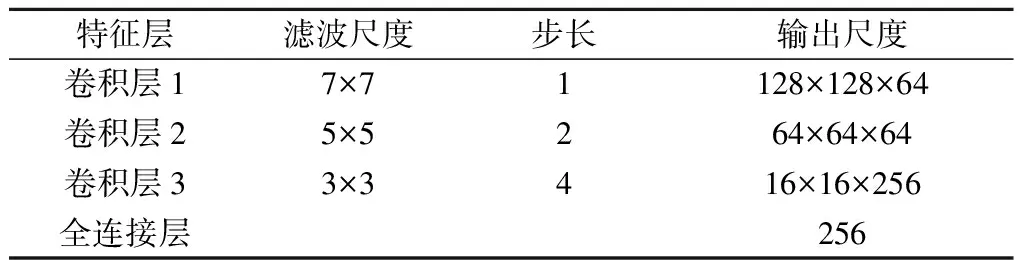
表1 GAN编码器的结构 像素

表2 GAN遮挡的解码器结构 像素

表3 GAN光照变化的解码器结构 像素

表4 GAN运动模糊的解码器结构 像素
在跟踪过程中,只采用生成式网络G中的编码器作为目标特征提取器,进而完成对目标的跟踪.当目标遭受外界干扰导致其特征难以提取时,采用生成式网络G中的解码器重构清晰目标.整个过程不需要更新目标模板.
训练网络参数时,将真实数据作为正样本,生成式网络G中得到的数据作为负样本,交替训练生成式网络和判别式网络的参数.
2.3 损失函数
本文针对不同的挑战场景提出了相应的损失函数,即遮挡损失LOCC、光照变化损失LIC和运动模糊损失LMB.
通常情况下,使用Softmax作为损失函数,定义为
(2)
式中,xi为第i个属于标记yi的深度特征;α为权重;bi为第i个特征的偏置项.
本文考虑了内容损失,即生成式网络G输出的图像和真实训练图像间的欧氏距离损失,从而确保在输入对抗网络前2幅图像的特征相似.内容损失的数学表达式定义为
(3)
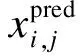
为了提高目标特征的判别能力,定义类内损失函数Lc为
(4)
式中,ci为中心向量,通过相应类别的特征平均值计算得到.
为了保留目标的表观信息,使用身份保留损失函数保持模型表观的相似性.基于解码器的最后2个隐层定义身份保留损失为
(5)
式中,Fi,j()为身份保留映射函数.
最后,为了与原始数据的负对数似然分布相似,定义对抗损失为
(6)
式中,G(Iocc)表示遮挡的目标图像经过生成式网络G后的输出.
遮挡损失LOCC为
LOCC=λ1Ls+λ2Lpixel+λ4Lip+λ5Lgen
(7)
光照变化损失LIC为
LIC=λ2Lpixel+λ3Lc+λ4Lip+λ5Lgen
(8)
运动模糊损失LMB为
LMB=λ2Lpixel+λ4Lip+λ5Lgen
(9)
式中,λ1,λ2,λ3,λ4,λ5分别为Softmax损失项、内容损失项、类内损失、身份保留损失项和对抗损失的惩罚值.
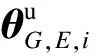
(10)
式中,θG,E,i为编码器第i个隐层更新前的参数;γ为遮挡损失函数对编码器第i个隐层的学习率;μ1为光照变化损失函数对编码器第i个隐层的学习率;μ2为运动模糊函数对编码器第i个隐层的学习率.
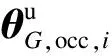
(11)
式中,θG,occ,i为目标遮挡解码器第i个隐层更新前的参数;γ1为目标遮挡解码器第i个隐层参数更新的学习率.
(12)
式中,θG,ic,i为光照变化解码器第i个隐层更新前的参数;γ2为光照变化解码器第i个隐层参数更新的学习率.
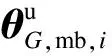
(13)
式中,θG,mb,i为运动模糊解码器第i个隐层更新前的参数;γ3为运动模糊解码器第i个隐层参数更新的学习率.
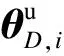
(14)
式中,θD,i为判别式网络第i个隐层更新前的参数;η为判别式网络第i个隐层参数更新的学习率.
2.4 目标跟踪
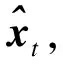
(15)
式中,xi表示第i个候选目标状态;f+()表示特征提取器;N表示候选目标状态数.
3 实验结果及分析
3.1 实验环境
实验所选用的测试数据库OTB100[15]中包含了丰富的挑战性场景,如目标遮挡、光照和尺度的变化、运动模糊等.将本文提出的跟踪算法与当前跟踪领域主流跟踪算法(IVT算法[2]、MIL算法[5]、TLD算法[6]、SCM算法[8]、DLT算法[9]、CNT算法[13])进行了跟踪性能比较,每一种算法的参数设置均使用相应文献中的默认值.
3.2 定性分析
图3给出了目标在遮挡视频中的跟踪结果.Faceocc1序列中,视频背景是静态的,因此所有跟踪算法都能够成功地跟踪目标.Faceocc2序列中,在目标遭遇变化时,CNT算法、SCM算法、DLT算法都产生不同程度的漂移,IVT算法、MIL算法、TLD算法甚至丢失了目标.本文算法重构出的图像能够正确地跟踪目标,避免了漂移现象的发生.

(a) Faceocc1序列 (b) Faceocc2序列
图4给出了目标在光照变化时的跟踪结果.Singer1序列中,光照强度剧烈变化使得MIL算法、IVT算法和TLD算法跟踪失败,其余算法能够适应尺度的变化从而成功跟踪目标,且本文算法的跟踪性能更佳.在Car4序列中,除IVT算法、MIL算法和DLT算法外,其余算法都能够跟踪目标,但均存在跟踪误差.Car11序列中,目标车辆在低照度情况下行驶,且运动中伴随着光流变化及相机抖动引起的轻微模糊,TLD算法、SCM算法、MIL算法、DLT算法从跟踪开始不久就产生漂移.
图5给出了目标快速运动产生图像模糊时的跟踪结果.在Deer序列中,目标的快速运动导致图像的分辨率下降.第36帧时,目标的大幅运动使得IVT算法、MIL算法、DLT算法、TLD算法、SCM算法丢失了跟踪目标,但本文算法能够快速捕获和学习目标表观的变化,成功地跟踪目标.
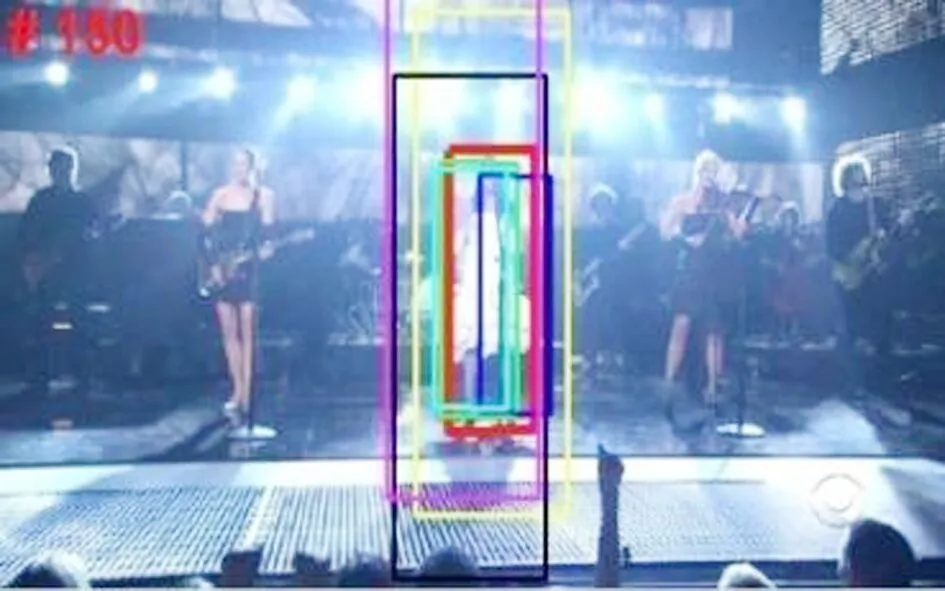
(a) Singer1序列 (b) Car4序列

(c) Car11序列

图5 目标快速运动产生图像模糊时的跟踪结果
3.3 定量分析
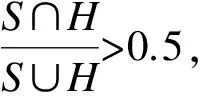

表5 部分典型视频序列跟踪结果的跟踪成功率
为了进一步验证本文采用的损失函数对网络训练性能的影响,在测试数据库(OTB100)中对目标遮挡、光照变化和运动模糊3类数据集上进行验证.在每一种挑战场景的损失函数中仅保留其中一项损失,结果见表6.由表可知,本文采用的损失函数对训练出的网络具有良好的鲁棒性.
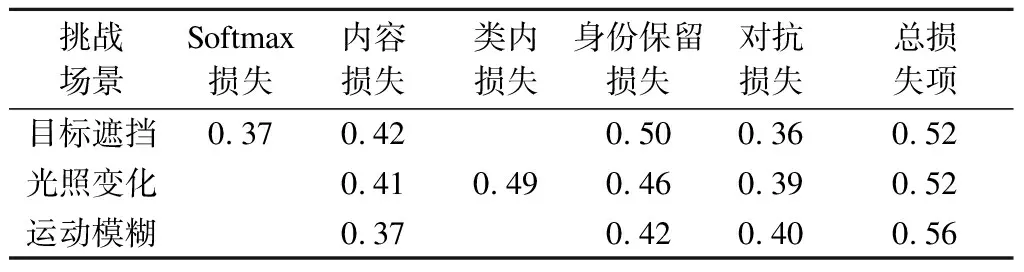
表6 损失函数对生成结果的跟踪成功率
3.4 算法的运行速度分析
在相同实验平台上,对包括本文算法在内的7种跟踪算法的运行速度进行了分析,结果见表7.由表可知,本文算法虽未实现实时跟踪,但其处理速度达到4帧/s,相比目前主流的跟踪算法仍然处于中上水平.此外,本文算法的实现代码没有经过优化和并行处理,约1/2的运行时间耗费在生成式对抗网络对问题图像的重构阶段,因而其计算效率仍有进一步提升的空间.

表7 不同跟踪算法的运行速度
4 结论
1) 提出了一种对抗生成网络结构,能够从遭受外界干扰(遮挡、光照变化和运动模糊)的图像中重构出清晰的目标表观,重构目标保留了身份特征,便于对其进行特征提取.
2) 为了应对目标遮挡等情况造成的信息缺失问题,本文从不同角度定义了损失函数.将从对抗训练得到的先验知识与目标先验知识相结合,精确恢复了缺失信息.
3) 选用OTB100测试数据库对本文算法进行了验证.实验结果表明,在大量遮挡、光照变化和运动模糊情况下,本文算法取得了较好的跟踪性能.
参考文献(References)
[1] Li X, Hu W, Shen C, et al. A survey of appearance models in visual object tracking [J].ACMTransactionsonIntelligentSystemsandTechnology, 2013,4(4): 478-488.DOI:10.1145/2508037.2508039.
[2] Ross D A, Lim J, Lin R S, et al. Incremental learning for robust visual tracking[J].InternationalJournalofComputerVision, 2008,77(1): 125-141.DOI:10.1007/s11263-007-0075-7.
[3] Kwon J, Lee K M. Visual tracking decomposition [C]//2010IEEEConferenceonComputerVisionandPatternRecognition. San Francisco, CA, USA, 2010: 1269-1276.DOI:10.1109/cvpr.2010.5539821.
[4] Avidan S. Ensemble tracking [J].IEEETransactionsonPatternAnalysisandMachineIntelligence, 2007,29(2): 261-271.DOI:10.1109/TPAMI.2007.35.
[5] Babenko B, Yang M H, Belongie S. Visual tracking with online multiple instance learning [J].IEEETransactionsonPatternAnalysisandMachineIntelligence, 2011,33(8): 1619-1632.DOI:10.1109/TPAMI.2010.226.
[6] Kalal Z, Mikolajczyk K, Matas J. Tracking-learning-detection [J].IEEETransactionsonPatternAnalysisandMachineIntelligence, 2012,34(7): 1409-1422. DOI:10.1109/TPAMI.2011.239.
[7] Zhang J, Ma S,Sclaroff S. MEEM: Robust tracking via multiple experts using entropy minimization [C]//2014ProceedingsofEuropeanConferenceonComputerVision. Zurich, Switzerland, 2014: 188-203.DOI:10.1007/978-3-319-10599-4_13.
[8] Zhong W, Lu H, Yang M H. Robust object tracking via sparse collaborative appearance model [J].IEEETransactionsonImageProcessing, 2014,23(5): 2356-2368.DOI:10.1109/TIP.2014.2313227.
[9] Wang N,Yeung D Y. Learning a deep compact image representation for visual tracking [C]//2013AdvancesinNeuralInformationProcessingSystems. Lake Tahoe, CA,USA, 2013: 809-817.
[10] Wang N, Li S, Gupta A, et al. Transferring rich feature hierarchies for robust visual tracking [EB/OL]. (2015-04-23) [2016-02-19]. https://arxiv.org/abs/1501.04587.
[11] Nam H, Han B. Learning multi-domain convolutional neural networks for visual tracking [C]//2016IEEEConferenceonComputerVisionandPatternRecognition. Las Vegas, CA,USA, 2016: 4293-4302. DOI:10.1109/cvpr.2016.465.
[12] Tao R, Gavves E, Smeulders A W M. Siamese instance search for tracking [C]//2016IEEEConferenceonComputerVisionandPatternRecognition. Las Vegas, CA,USA, 2016: 1420-1429. DOI:10.1109/cvpr.2016.158.
[13] Zhang K, Liu Q, Wu Y, et al. Robust visual tracking via convolutional networks without training [J].IEEETransactionsonImageProcessing, 2016,25(4): 1779-1792. DOI: 10.1109/TIP.2016.2531283.
