基于生成对抗网络的多视图学习与重构算法
2018-06-07孙亮韩毓璇康文婧葛宏伟
孙亮 韩毓璇 康文婧 葛宏伟
实际应用问题中,同一事物通常可以通过不同途径从不同角度进行表达.例如:多媒体记录可以通过视频描述,也可以通过音频描述;网页记录可以通过其本身的信息描述,也可以通过超链接包含的信息描述;同一语义对象,可以用多种语言描述.此外,同一事物由于数据采集方法不同,也可以有不同的表达方法.例如:人脸识别问题中,人脸数据可以采集成二维,也可以采集成三维;指纹识别问题中,同一指纹可以通过不同采集器采集出不同的印痕.上述每一类型数据称为一个特定视图,多类型数据的总体称为多视图数据.针对多视图数据的分析研究,已经引起机器学习研究者的关注[1−4].按不同任务,已有方法可分为多视图子空间学习[5−6]、多视图字典学习[7−8]、多视图度量学习[9]等.完成这些任务的重要工作是获得视图间的匹配关系,可以通过协同训练[10−11]、协同映射[12−13]、信息传播[14]等方法实现.在实现过程中,通常要求每个实例的所有视图都是完整的.然而,现实问题中数据通常独立地收集、处理和存储,受环境因素的影响,给定一实例,通常很难获得其所有视图的数据.因此,利用已掌握的单一视图,通过生成式方法获得其他视图数据,能够更全面地认识事物,对其进行更准确的表达[4],具有重要的意义.
给定单一视图,首先需要解决的问题是构建它的恰当表示,即表征.传统的手动提取特征方法需要大量的人力并且依赖于专业知识,同时还不便于推广.随着深度学习技术的发展,通过深度神经网络(Deep neural networks,DNN)学习事物的表征获得了成功[15−17],它允许算法使用特征的同时也提取特征,避免了手动提取特征的繁琐,能够获得单一视图恰当的表征[18].通过单一视图的表征构建完整视图,表征中不仅需要包含其本身的信息,而且这些信息能够用来构建其他视图.为解决该问题,已有方法主要在表征空间通过最大化不同视图间相互关系[1]、最小化不同视图间差异[19]、为差异添加惩罚因子[20−21]、典型相关分析[22]等方法实现.然而,由于现实世界数据的复杂性,如何构建适用于多视图的有效表征,仍然是需要研究和解决的问题.
利用单一视图的表征,通过生成式方法构建完整视图依赖于生成模型的好坏,需要根据学习而来的模型生成新样本.传统的生成式方法包括极大似然估计法[23]、近似法[24]、马尔科夫链法[25]等.与此同时,基于DNN构建的生成式模型也获得了成功,典型的网络结构包括循环神经网络(Recurrent neural networks,RNN)[26]、卷积神经网络(Convolutional neural networks,CNN)[27]、变分自编码器(Variation autoencoders,VAE)[28]、生成对抗网络(Generative adversarial networks,GAN)[29−30]等.这些方法针对已掌握的数据进行分布假设和参数学习.然而在实际应用过程中,不同视图(例如图像、视频、传感器等)的数据数量巨大,并且都非常复杂、冗余并且异构[31],如何在生成模型中融入已有视图的表征信息,仍然是需要研究和解决的问题.
本文的主要工作集中于利用已知单一视图,通过生成式方法构建其他视图.为构建适用于多视图的表征,提出一种新型表征学习方法,该方法通过DNN来实现.首先,对于每一视图,分别搭建DNN,通过逐层转换与表达,借助DNN的无限拟合能力将数据映射至特征空间.通过构建并优化训练过程中的损失函数,将同一实例的不同视图映射至相同或相近的表征向量.在众多生成式模型中,生成式对抗网络(GAN)在结构上受博弈论中二人零和博弈启发,通过构建生成模型和判别模型捕捉真实数据样本的潜在分布并生成新的数据样本.与其他生成式模型不同,GAN避免了马尔科夫链式的学习机制,使得真实数据样本概率密度不可计算时,模型依然可以应用.为在生成模型中融入已有视图的表征信息,本文提出基于GAN的生成式模型.对于每一视图,分别搭建GAN,在生成模型和判别模型的输入端加入随机变量和原始数据及已有视图生成的表征信息,使得生成模型能够生成与已有视图相对应的新视图数据.综上所述,本文的主要贡献包括:1)提出基于DNN的多视图表征学习方法,对于同一实例,将不同视图数据映射至相同或相近的表征向量,避免了视图间的直接映射;2)对于每一视图,分别搭建DNN,训练过程中将每一对视图的DNN组合训练,不需要训练数据的完整视图,解决了训练数据不完整问题;3)提出基于GANs的多视图数据生成方法,将已知视图的表征向量加入生成模型和判别模型中,解决了新视图数据与已知视图数据正确对应的问题.
本文章节安排如下:第1节用数学模型描述要解决的多视图重构问题;第2节提出基于DNN的多视图表征学习方法;第3节提出基于GANs的多视图数据生成方法;第4节通过手写体数字数据集MNIST,街景数字数据集SVHN和人脸数据集CelebA验证提出方法的有效性,并与其他已有算法进行比较分析;第5节总结全文,并指出进一步的研究方向.
1 问题描述
假定χ为一组包含n个实例,v个视图的实例集,每一实例表示为其中表示第i个实例的第k个视图数据,dk为第k个视图的维度.与此同时,每一实例对应指示向量表示视图数据可观测,表示不可观测.
本文工作的主要目标是通过一组训练实例χ构建生成模型,给定任意测试实例的源视图预测其他视图,使得生成模型获得的视图接近真实视图即最大化条件概率为表述方便,记可观测的第k个视图为x(k).
2 基于DNN的多视图表征学习
给定第k个视图数据x(k),通过构造DNN编码模型,可以将其编码成低维向量c(k),假设网络的映射函数为f(k)(x(k)),则c(k)=f(k)(x(k)).为所有视图分别构造编码模型,可以得到v个DNN.这种表示不能获得多视图相同或相近的表征.因此,借助DNN 能够逼近任意函数的能力,将x(1),x(2),···,x(v)映射至相同的表征空间,如图1(a)所示.为了保证同一实例的不同视图映射至同一表征向量,在网络训练过程中,对任意一对视图k和r,最小化目标向量间的JS散度,网络优化的目标函数定义为
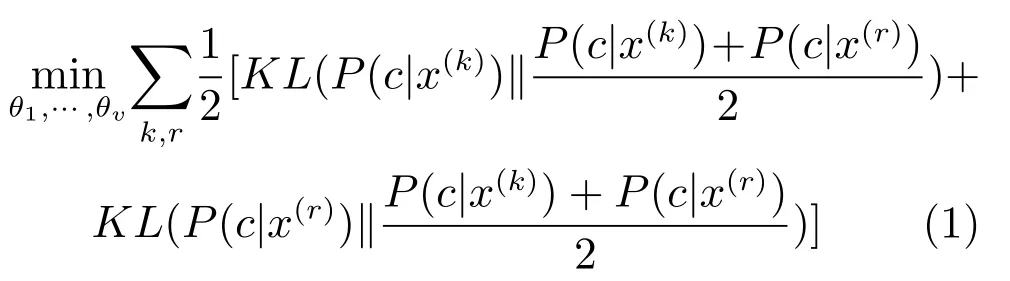
其中,θ1,θ2,···,θv分别为v个 DNN 网络中的所有参数,KL(P1kP2)表示分布函数P1与P2间的KL散度.实际应用过程中,为保证表征信息的紧凑性,将设置为较低维度.
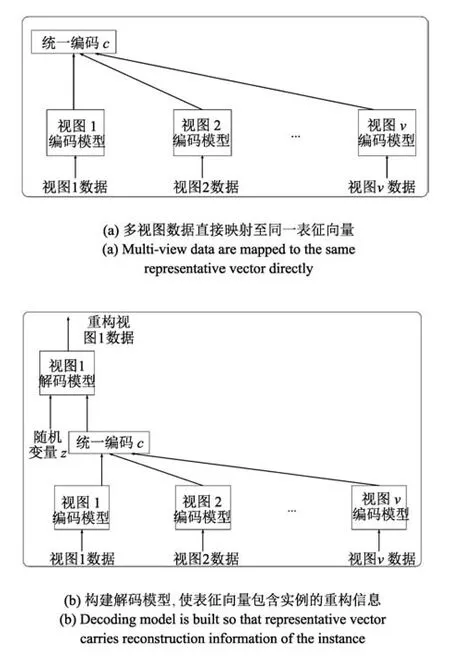
图1 多视图表征向量映射Fig.1Multi-view representative vector mapping
图1(a)的网络结构保证了对于任意实例xi的所有视图能够通过相应的神经网络映射至相同的表征向量ci,但不能保证表征向量ci中包含实例xi中的重构信息.根据信息理论,给定随机变量x包含的信息可以通过下式计算:

随机变量x与随机变量y之间的互信息I(x;y)可以定义为随机变量x中包含随机变量y的信息量,如图2(a)所示,可以通过下式计算:
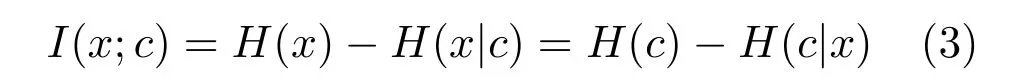
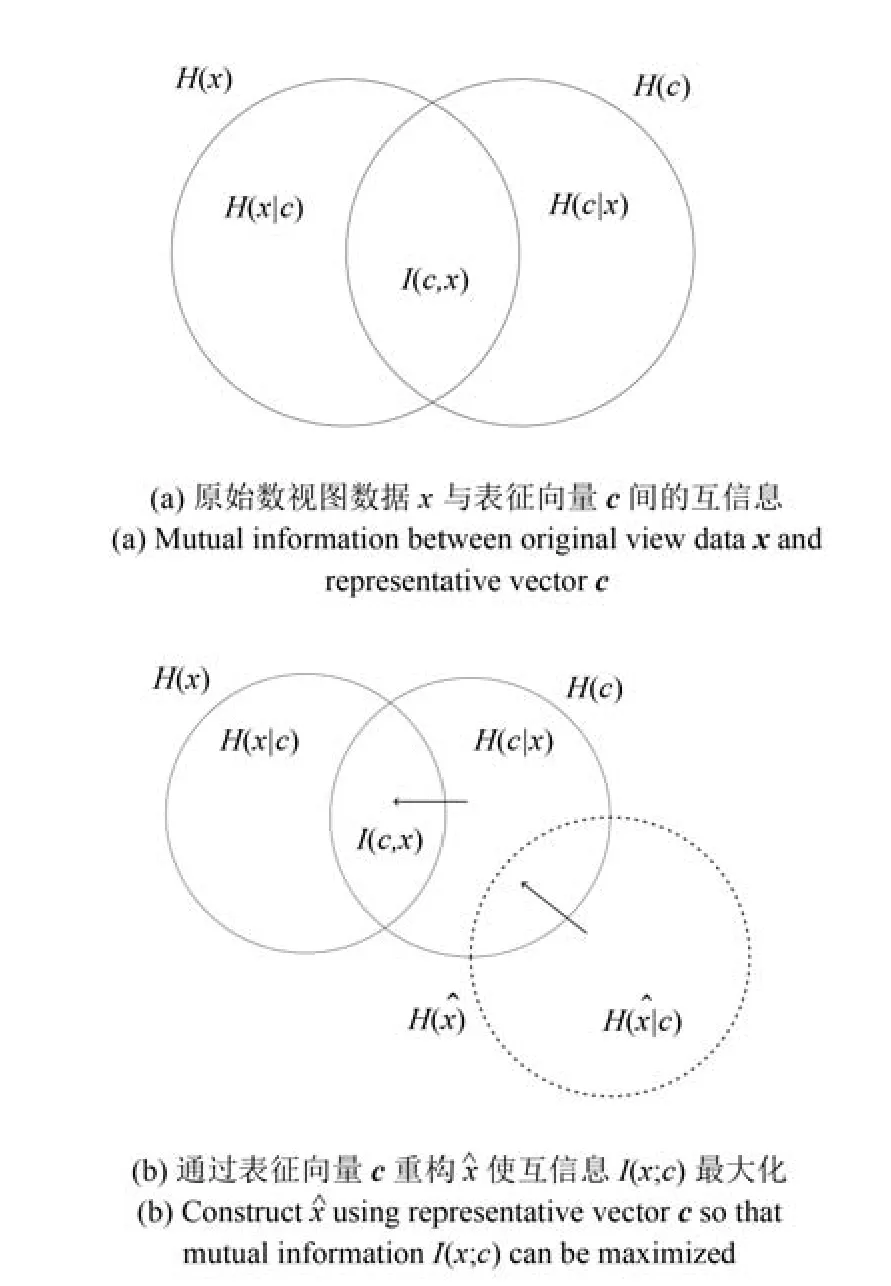
图2 原始视图数据x,表征向量 c,重构视图数据间的互信息示意图Fig.2Schematic diagram of mutual information among original view data x,representative vector c,reconstructed data
从图2(a)可以看出,为最大化x与ccc之间的互信息I(x;c),可以拟合H(x|c)与H(c|x),其中H(c|x)可以通过视图的DNN编码模型进行优化调整.然而,H(x|c)很难直接计算.为此本文提出以c为约束条件,构建基于DNN的解码模型重构,网络结构如图1(b)所示.x,,c之间的互信息关系如图2(b)所示.H(x|c)与H(|c)可以通过比较原始训练数据与重构数据获得.通过编码模型可以调整H(c|x),通过解码模型可以调整H(|c).不断调整H(c|x),H(|c)可以使其逼近H(x|c),从而最大化互信息I(x;c).具体做法如下:从v个视图中,任选一个视图,假定为视图1,为视图1构建解码模型,解码模型的输入包括来自正态分布的随机向量和编码模型生成的表征向量.解码模型的输出为(1).网络优化的目标函数重新定义为
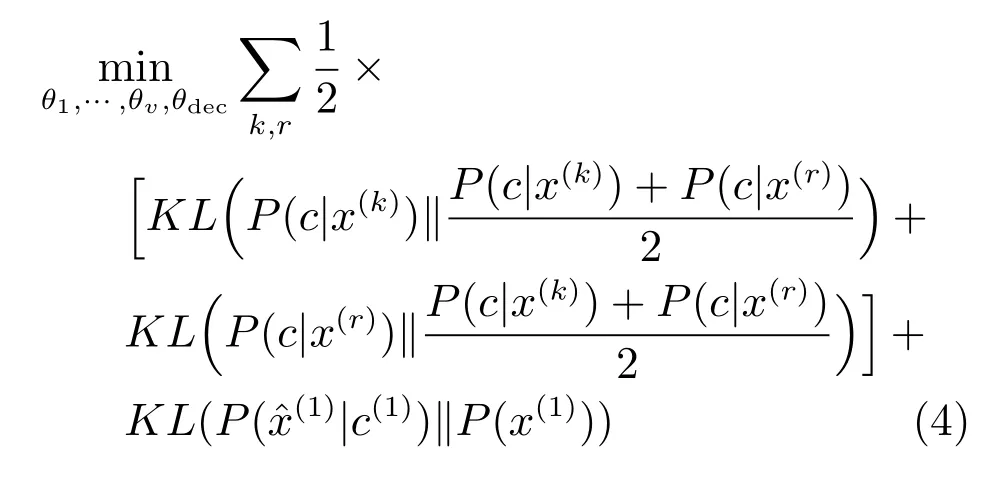
其中,θdec为解码模型中的所有参数,
综上所述,为构建适用于多视图的表征,本文提出的基于DNN的多视图表征学习方法概括为:1)为每个视图分别构建DNN,将同一实例不同视图的数据映射至相同的表征向量;2)搭建条件解码模型,保证表征向量包含关于实例的重构信息.
3 基于GANs的多视图数据生成
给定第2节提出的基于DNN的多视图表征学习方法,对于测试实例的任意源视图,可以获得关于该实例通用的表征向量.接下来的任务是通过表征向量,重构其他视图.
生成对抗网络的思想来源于博弈论中的纳什均衡,它利用DNN分别构建生成模型(G)和判别模型(D),通过生成模型和判别模型之间迭代的对抗学习预测真实数据的潜在分布并生成新的样本.网络优化的目标定义为生成模型与判别模型的博弈,目标函数如下:
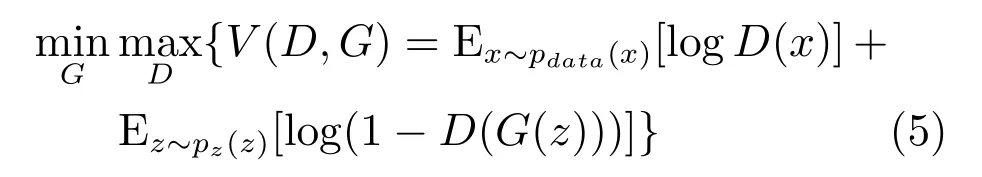
为生成多视图数据,可以为所有视图分别构建GAN网络,并生成相应视图的数据.然而,由于标准的GAN生成模型以随机变量z为输入,因此,它无法指定生成与表征向量相对应的视图数据.为解决这一问题,有效的方法是构建条件生成对抗网络(Conditional generative adversarial nets,CGAN)[32].其基本思想是在生成模型和判别模型中引入条件变量,利用条件变量指导数据的生成.因此,本文提出基于对抗生成网络的多视图数据生成算法.为每一视图构建条件生成对抗网络.在生成模型中和判别模型中分别加入表征向量作为约束条件作为输入层的一部分,从而实现利用表征向量指导新视图数据的生成.网络结构如图3所示.每个GAN网络的优化的目标重新定义为以表征向量为约束条件的生成模型与判别模型的博弈.
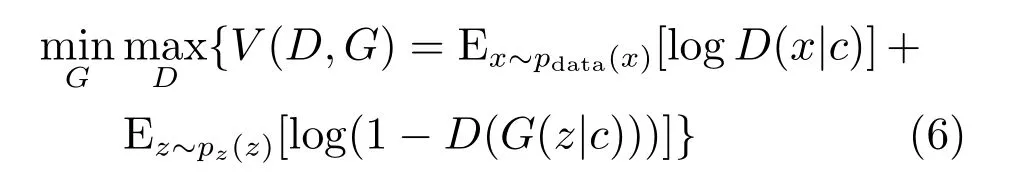

图3 基于生成对抗网络的多视图数据生成框架Fig.3Framework of the generative adversarial network based multi-view data generation
从图3可以看出,每个视图的GAN网络在训练开始前,由编码模型生成表征向量.训练过程中,生成模型G以采样自正态分布的随机变量作为输入,同时以表征向量c为约束条件.判别模型D以真实训练数据,或生成模型生成的数据为输入,同时以表征向量c为约束条件.生成模型和判别模型通过式(6)中的对抗训练不断逼近约束条件c下真实数据的潜在分布,并生成新样本.测试过程中,由源视图通过编码模型生成表征向量c,由于式(4)中优化目标条件的限制,向量c将包含实例完整的重构信息,并且可以将其做为约束条件传递至任意其他视图的生成模型.对应视图的生成模型将以随机变量z为输入,表征向量c为约束条件,生成与源视图相匹配的数据.
4 实验结果与分析
4.1 多视图测试数据集
为验证本文所提算法的有效性,在如下数据集合上展开实验.
1)手写数据集合(MNIST dataset of handwritten digits).MNIST包含约7万幅图像,每幅图像对应一个手写体数字,大小为28像素×28像素[33];
2)街景数字集合(Street view house numbers,SVHN).SVHN包含约8.9万幅图像,每幅图像对应一个真实世界的街道门牌号,并且以门牌号的数字为中心,大小为32像素×32像素[34];
3)人脸数据集合(CelebFaces attributes,CelebA).CelebA包含约20万幅图像,每幅图像对应一个真实世界的人脸,大小裁剪为64像素×64像素[35].
4.2 模型评价标准
为了定量地衡量所提算法,采用结构相似性(Structural similarity index,SSIM)[36]和峰值信噪比(Peak signal to noise ratio,PSNR)[37]作为评价指标衡量真实图像数据与模型生成的图像数据之间的相似度以及生成图片的质量.
SSIM作为一种衡量两幅图像相似度的指标,能够反映图像间的结构相似性.假定Ix为模型生成的图像,Iy为真实图像(Ground truth),Ix与Iy之间的SSIM定义为
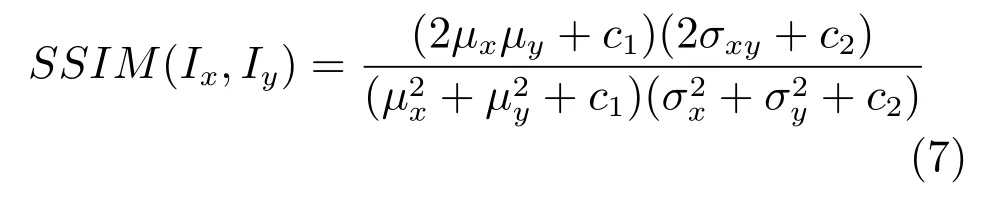
其中,µx,µy是Ix和Iy的像素均值,分别是Ix和Iy的方差,σxy是Ix与Iy之间的协方差.式(7)表明SSIM值越高,Ix与Iy之间的相似性就越高,生成的图像越接近真实图像.
PSNR是一种评价图像的客观标准.图像经过处理之后,输出的图像都会在某种程度与原始图像不同.将真实图像与生成图像对比,得到生成的图像的PSNR值来测试模型的重构效果.
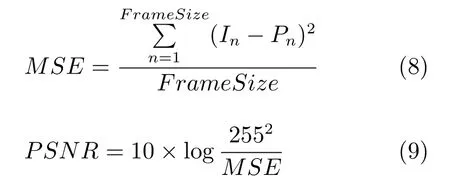
其中,MSE代表平均均方误差,In是原始图像第n个像素值,Pn指处理后图像第n个像素值,Frame-Size是图像长×宽×通道数.PSNR的单位为dB.PSNR值越大,表明图片质量越好,失真度越小.
4.3 实验设置与结果
4.3.1 MNIST数据集实验结果
对于MNIST数据集,考虑3个视图,其中原始图像为视图1,将图像遮挡14像素×14像素的区域作为视图2,将图像进行LBP特征提取[38],以特征向量作为视图3.对原始图像进行LBP特征提取得到了一个236维的特征向量,将特征向量映射到二维空间,示意图如图4(图4中,灰度条展示了0∼9不同数字对应的灰度,横纵坐标代表降维后二维特征,共8000张图片)从图4可以看出,每个类别的特征向量趋向于聚集在一起,并且类别为7的数字与类别为1的数字更加接近.此外,类别之间出现了轻微重叠现象,并且有少量数据点分布在坐标系的边缘.在实验过程中,首先以训练数据的3个视图数据为输入,训练图1(b)中的编码模型与解码模型.训练过程采用每一对视图单独训练的方式,网络训练以式(4)为目标函数.编码模型与解码模型训练完成后,以表征向量为约束条件,每一视图训练图3中的生成对抗网络.网络训练以式(6)为目标函数.测试过程中分别以测试实例的视图2和视图3作为源视图构建表征向量,分别以表征向量作为约束条件利用视图1的生成模型生成对应的视图1数据.
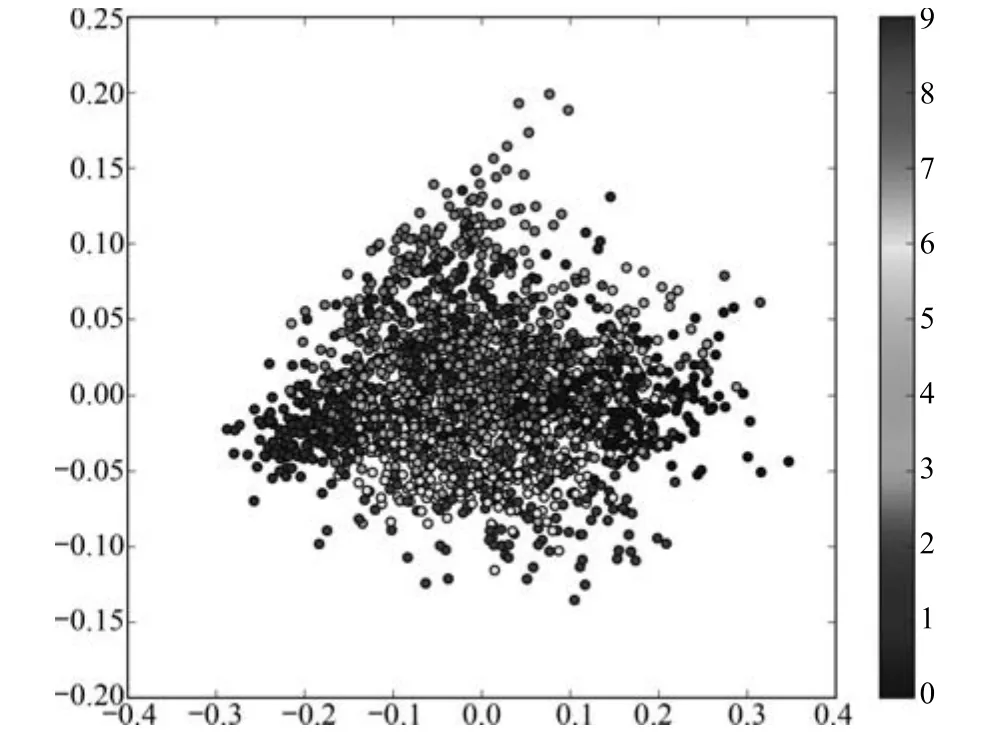
图4 MNIST视图3数据经过PCA后的可视化二维图Fig.4The 2D-visualization of view 3 on MNIST after PCA
图5显示了以视图2为源视图在随机挑选的15幅测试图像上的实验结果,第1行表示遮挡一部分的源视图,第2行表示源视图对应的真实图像,第3行表示视图1生成模型构建的图像.图6显示了以视图3为源视图在随机挑选的15幅测试图像上的实验结果,第1行表示源视图对应的真实图像,第2行表示视图1生成模型构建的图像.
从图5和图6可以看出,尽管源视图2有较大比例遮挡,源视图3从表达方式方面与原始数据有较大差异,本文提出的生成算法仍然能够有效重构对应视图1数据.表明第2节提出的表征学习方法不仅能获得图像中的语义信息,而且能够获得包括方向、粗细、倾斜角度等其他信息,同时表明本文提出的生成模型能够有效根据表征向量重构完整视图.
为进一步表明所提出算法的有效性,将提的多视图生成对抗网络的实验结果(Multi-view generative adversarial networks,MVGAN)与条件生成对抗网络(Conditional generative adversarial nets,CGAN)[30]和条件变分自编码模型(Conditional variational autoencoders,CVAE)[39]产生的实验结果进行比较.表1给出了三种算法在测试数据上的平均SSIM值与平均PSNR值.从表1可以看出,所提的MVGAN模型以视图2为源数据重构视图1,SSIM值和PSNR值均高于CGAN和CVAE,表明MVGAN重构的图像更接近真实图像,并且失真度最小.在MVGAN模型以视图3为源数据重构视图1上,SSIM值比CGAN和CVAE的SSIM值低0.09和0.14左右,PSNR值比CGAN和CVAE的PSNR值高0.18dB和0.09dB左右,表明MVGAN模型中以视图3为源数据重构视图1得到的图片比CGAN和CVAE得到的图片失真度小.对图片做纹理特征提取并应用数学的统计降维得到的特征向量比原图片损失了部分信息,由缺失信息的数据重构完整数据时SSIM值会相对较低.与此同时CGAN和CVAE使用了图片的完整信息,因此获得了较高的SSIM值.
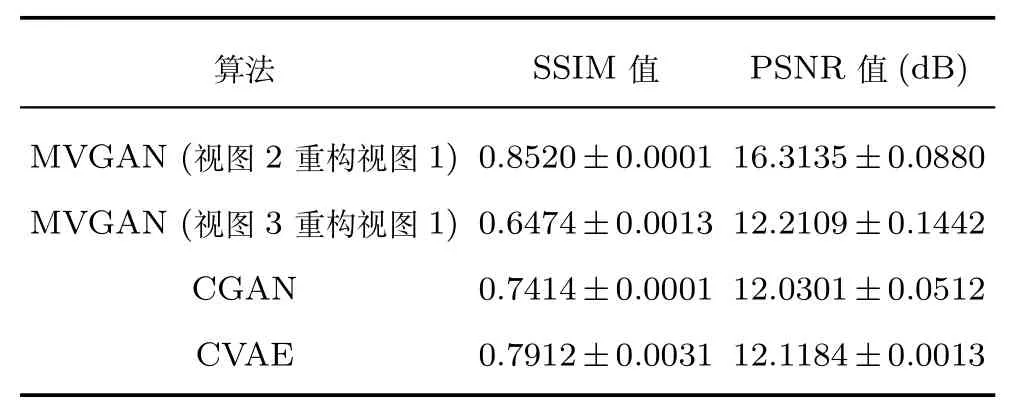
表1 MNIST数据集上的SSIM和PSNR比较结果Table 1 Comparison results of SSIM and PSNR on MNIST
4.3.2 SVHN数据集实验结果
对于SVHN数据集,考虑3个视图,其中原始图像为视图1,将图像遮挡16像素×16像素的区域作为视图2,将图像进行LBP特征提取,以特征向量作为视图3.在实验过程中,展开与在MNIST数据集上相似的实验.首先以训练数据的3个视图数据为输入,训练图1(b)中的编码模型与解码模型.训练过程采用每一对视图单独训练的方式,网络训练以式(4)为目标函数.编码模型与解码模型训练完成后,以表征向量为约束条件,每一视图训练图3中的生成对抗网络.网络训练以式(6)为目标函数.测试过程中分别以测试实例的视图2和视图3作为源视图构建表征向量,分别以表征向量作为约束条件利用视图1的生成模型生成对应的视图1数据.

图5 以视图2为源数据在MNIST上的重构结果Fig.5 Reconstruction results that take view 2 as source data on MNIST

图6 以视图3为源数据在MNIST上的重构结果Fig.6 Reconstruction results that take view 3 as source data on MNIST
图7显示了以视图2为源视图在随机挑选的15幅测试图像上的实验结果,第1行表示遮挡一部分的源视图,第2行表示源视图对应的真实图像,第3行表示视图1生成模型构建的图像.图8显示了以视图3为源视图在随机挑选的15幅测试图像上的实验结果,第1行表示源视图对应的真实图像,第2二行表示视图1生成模型构建的图像.
从图7和图8中可以看出,尽管源视图2有较大比例的遮挡,源视图3从表达方式上与原始数据有较大差异,但是本文提出的生成式算法仍然可以重构视图1的数字类别,背景以及形状等信息.表明提出的算法可以通过共同的表征学习达到重构视图数据的目的.
为了进一步说明算法的有效性,将提出的多视图生成对抗网络(MVGAN)的实验结果与CGAN和CVAE产生的实验结果进行比较.
表2给出了这三种算法在测试数据上的平均SSIM值与平均PSNR值,从表2可以看出,所提的MVGAN模型以视图2为源数据重构视图1,SSIM值和PSNR值均高于CGAN和CVAE,表明MVGAN重构的图像更接近真实图像,并且失真度最小.在MVGAN模型以视图3为源数据重构视图1上,SSIM值比CGAN和CVAE低0.15和0.16左右,PSNR值比CGAN和CVAE的PSNR值高0.91dB和0.79dB左右.表明MVGAN模型中以视图3为源数据重构视图1得到的图片比CGAN和CVAE得到的图片失真度小,同时因为对图片做纹理特征提取并应用数学的统计降维得到的特征向量比原始图片损失了部分信息,所以由缺失信息的数据重构完整数据得到的SSIM值会相对较低,与此同时CGAN和CVAE使用了图片的完整信息,因此获得了较高的SSIM值.
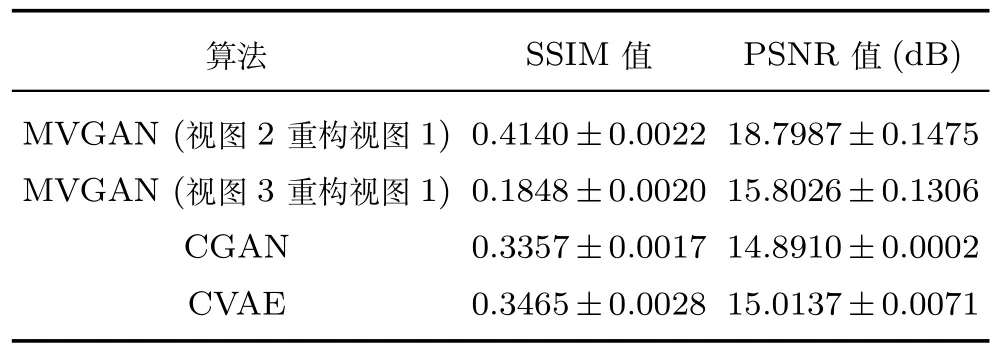
表2 SVHN数据集上的SSIM和PSNR比较结果Table 2 Comparison results of SSIM and PSNR on SVHN
4.3.3 CelebA数据集实验结果
对于CelebA数据集,考虑3个视图,其中原始图像为视图1,将图像遮挡32像素×32像素的区域作为视图2,选取图像的10种属性作为视图3.视图3包含的图像属性有秃顶(Bald),刘海(Bangs),黑发(Black hair),眼镜(Eyeglass),男性(Male),嘴微张(Mouth slightly open),窄眼(Narrow eyes),无胡须(No beard),苍白肤色(Pale skin),戴帽(Wearing hat).表3展示了随机选取的15幅图片的属性向量的具体取值,其中“1”表示属性为真,“−1”表示属性为假.

图7 以视图2为源数据在SVHN上的重构结果Fig.7 Reconstruction results that take view 2 as source data on SVHN
图9显示了与表3对应的15幅测试图像上的实验结果,第1行表示遮挡了一部分数据的视图2,第2行表示视图对应的真实图像,第3行表示以视图2为源数据构建视图1的实验结果,第4行表示以视图3为源数据构建视图1的实验结果.
从图9可以看出,视图2虽然有较大比例的遮挡,但是MVGAN能够依据视图2对应的10维属性信息重构一幅完整的图像,例如第1张图像的人物具有戴眼镜、男性、有胡须的属性,对应的重构图像同样具有戴眼镜、男性、有胡须的属性.把原始图像的10维属性信息作为视图3,可以看出新提出的算法可以根据视图3的属性取值重构对应的图像,例如图9第2行第2张人物具有黑发、男性、有胡须的属性,对应的第4行第2张人物也具有黑发、男性、有胡须的属性.表明提出的表征学习方法隐式地获取了实例中的表征信息,并且能够通过表征信息重构其他视图的数据.
为进一步说明算法的有效性,将MVGAN的实验结果与CGAN和CVAE产生的实验结果进行比较.表4给出了三种算法在测试数据上的SSIM值与PSNR值,从表4可以看出,MVGAN模型的SSIM值和PSNR值均高于CGAN和CVAE,表明MVGAN重构的图像比CGAN和CVAE重构的图像更接近真实图像且失真度最小.因为MVGAN模型在CelebA数据集上以重构10维属性信息为标准,且SSIM 评价指标是一种衡量两张图片相似程度的评价标准,因此与在MNIST与SVHN数据集上重构完整视图信息的实验结果相比,在CelebA数据集上得到了较低的SSIM值.PSNR评价指标是一种衡量图片失真度的评价标准,可以看出MVGAN模型重构的图片具有较小的失真度.
5 结论

图9 以视图2为源数据在CelebA上的重构结果Fig.9 Reconstruction results that take view 2 and view 3 as source data respectively on CelebA
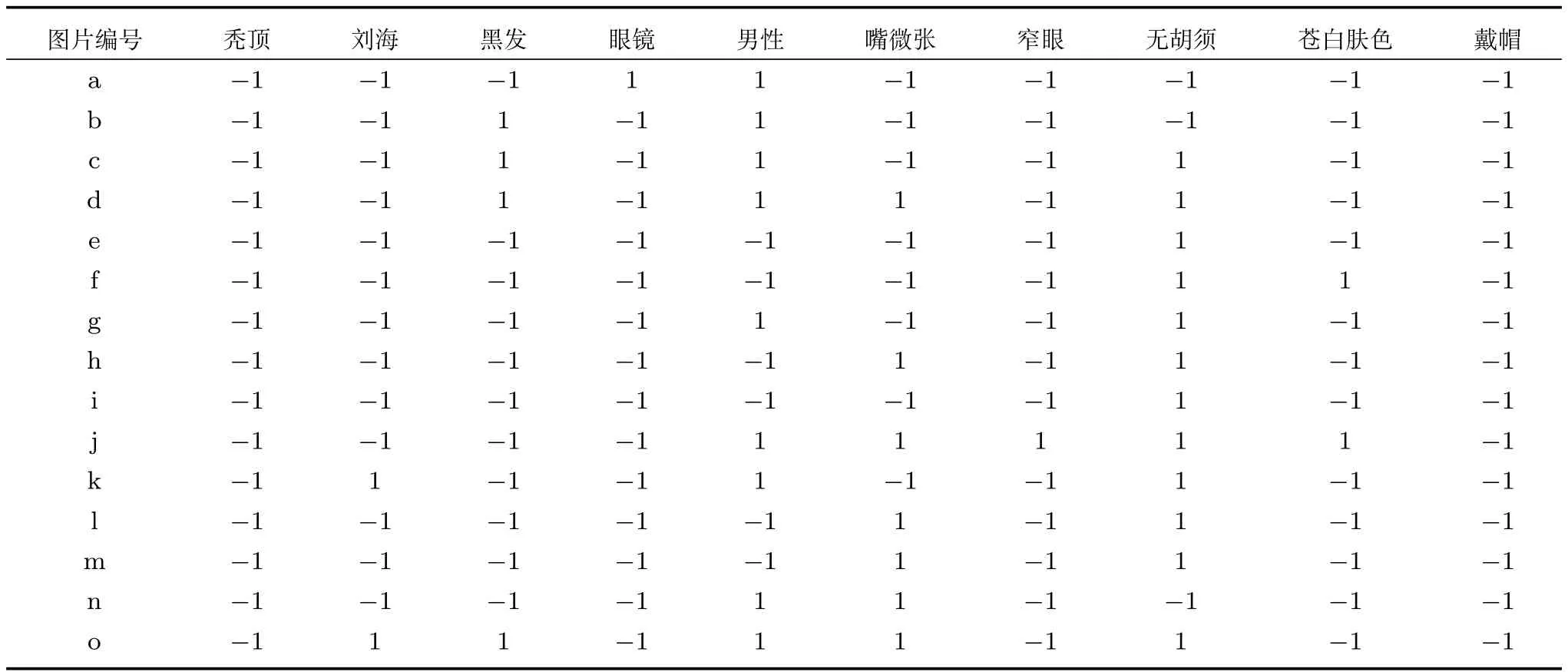
表3 CelebA视图2和视图3对应选中的10维属性Table 3 The chosen attributes for view 2 and view 3(10 dimensions)
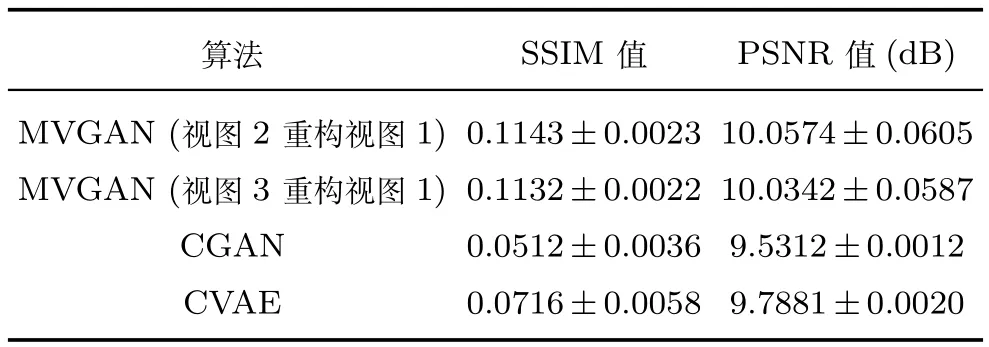
表4 CelebA数据集上的SSIM和PSNR比较结果Table 4 Comparison results of SSIM and PSNR on CelebA
在多视图学习领域,研究如何根据已有视图构建完整视图具有重要意义.其中一个需要解决的问题是构建表征向量映射模型,使得属于同一实例的不同视图数据能够映射至相同的表征向量,同时表征向量还需包含关于实例的完整重构信息.针对该问题,本文提出一种基于DNN的多视图表征学习算法,通过为每一视图构建DNN,借助DNN能够拟合任何分布的能力将不同视图的数据映射至通用的表征向量,并且本文提出构建解码模型保证了表征向量中包含关于实例的完整重构信息.为了依据表征向量信息重构完整视图,本文提出一种基于生成对抗网络的多视图重构算法.以表征向量为约束条件,通过生成器与判别器的对抗训练来生成与源视图匹配的多视图数据.实验结果表明,提出的表征向量学习算法不仅得到了实例本身所带有的语义信息,而且得到了方向、粗细、倾斜角度等其他重构信息.因此,提出的生成对抗网络方法能够根据低维的表征信息进行有效的重构.
接下来的研究工作将集中于研究如何获取表征向量的显式含义信息,并指导多视图数据的生成.
1 Chaudhuri K,Kakade S M,Livescu K,Sridharan K.Multiview clustering via canonical correlation analysis.In:Proceedings of the 26th Annual International Conference on Machine Learning.Montreal,Canada:ACM,2009.129−136
2 Kumar A,Daume III H.A co-training approach for multiview spectral clustering.In:Proceedings of the 28th International Conference on Machine Learning.Washington,USA:Omnipress,2011.393−400
3 Wang W R,Arora R,Livescu K,Bilmes J.On deep multiview representation learning.In:Proceedings of the 32nd International Conference on Machine Learning.Lille,France:ICML,2015.1083−1092
4 Sun S L.A survey of multi-view machine learning.Neural Computing and Applications,2013,23(7−8):2031−2038
5 White M,Yu Y L,Zhang X H,Schuurmans D.Convex multiview subspace learning.In:Proceedings of the 25th Annual Conference on Neural Information Processing Systems.Lake Tahoe,USA:NIPS,2012.1673−1681
6 Guo Y H.Convex subspace representation learning from multi-view data.In:Proceedings of the 27th AAAI Conference on Arti ficial Intelligence.Washington,USA:AIAA,2013.387−393
7 Shekhar S,Patel V M,Nasrabadi N M,Chellappa R.Joint sparse representation for robust multimodal biometrics recognition.IEEE Transactions on Pattern Analysis and Machine Intelligence,2014,36(1):113−126
8 Gangeh M J,Fewzee P,Ghodsi A,Kamel M S,Karray F.Multiview supervised dictionary learning in speech emotion recognition.IEEE/ACM Transactions on Audio,Speech,and Language Processing,2014,22(6):1056−1068
9 Zhai D M,Chang H,Shan S G,Chen X L,Gao W.Multiview metric learning with global consistency and local smoothness.ACM Transactions on Intelligent Systems and Technology,2012,3(3):Article No.53
10 Kumar A,Rai P,Daumé III H.Co-regularized multiview spectral clustering.In:Proceedings of the 24th Annual Conference on Neural Information Processing Systems.Granada,Spain:Curran Associates Inc.,2011.1413−1421
11 Chen M M,Weinberger K Q,Blitzer J C.Co-training for domain adaptation.In:Proceedings of the 24th Annual Conference on Neural Information Processing Systems.Granada,Spain:Curran Associates Inc.,2011.2456−2464
12 Eaton E,desJardins M,Jacob S.Multi-view constrained clustering with an incomplete mapping between views.Knowledge and Information Systems,2014,38(1):231−257
13 Zhang X C,Zong L L,Liu X Y,Yu H.Constrained NMF-based multi-view clustering on unmapped data.In:Proceedings of the 29th AAAI Conference on Arti ficial Intelligence.Austin,Texas,USA:AIAA Press,2015.3174−3180
14 Yu S,Tranchevent L C,Liu X H,Glanzel W,Suykens J A K,De Moor B,et al.Optimized data fusion for kernel k-means clustering.IEEE Transactions on Pattern Analysis and Machine Intelligence,2012,34(5):1031−1039
15 Yu Kai,Jia Lei,Chen Yu-Qiang,Xu Wei.Deep learning:yesterday,today,and tomorrow.Journal of Computer Research and Development,2013,50(9):1799−1804(余凯,贾磊,陈雨强,徐伟.深度学习的昨天、今天和明天.计算机研究与发展,2013,50(9):1799−1804)
16 Guo Li-Li,Ding Shi-Fei.Research progress on deep learning.Computer Science,2015,42(5):28−33(郭丽丽,丁世飞.深度学习研究进展.计算机科学,2015,42(5):28−33)
17 Hu Chang-Sheng,Zhan Shu,Wu Cong-Zhong.Image superresolution based on deep learning features.Acta Automatica Sinica,2017,43(5):814−821(胡长胜,詹曙,吴从中.基于深度特征学习的图像超分辨率重建.自动化学报,2017,43(5):814−821)
18 Hinton G E,Salakhutdinov R R.Reducing the dimensionality of data with neural networks.Science,2006,313(5876):504−507
19 Farquhar J D R,Hardoon D R,Meng H Y,Shawe-Taylor J,Szedmak S.Two view learning:SVM-2k,theory and practice.In:Proceedings of the 18th Annual Conference on Neural Information Processing Systems.Vancouver,Canada:MIT Press,2005.355−362
20 Sindhwani V,Rosenberg D S.An RKHS for multi-view learning and manifold co-regularization.In:Proceedings of the 25th International Conference on Machine Learning.Helsinki,Finland:ACM,2008.976−983
21 Yu S P,Krishnapuram B,Rosales R,Rao R B.Bayesian cotraining.The Journal of Machine Learning Research,2011,12:2649−2680
22 Andrew G,Arora R,Bilmes J,Livescu K.Deep canonical correlation analysis.In:Proceedings of the 30th International Conference on Machine Learning.Atlanta,GA,USA:JMLR.org,2013.1247−1255
23 Westerveld T,de Vries A,de Jong F.Generative probabilistic models.Multimedia Retrieval,Berlin:Springer,2007.177−198
24 Rezende D J,Mohamed S,Wierstra D.Stochastic backpropagation and approximate inference in deep generative models.arXiv preprint arXiv:1401.4082,2014.
25 Hinton G E,Osindero S,Teh Y W.A fast learning algorithm for deep belief nets.Neural Computation,2006,18(7):1527−1554
26 van den Oord A,Kalchbrenner N,Kavukcuoglu K.Pixel recurrent neural networks.arXiv preprint arXiv:1601.06759,2016.
27 van den Oord A,Kalchbrenner N,Vinyals O,Espeholt L,Graves A,Kavukcuoglu K.Conditional image generation with pixelCNN decoders.In:Proceedings of the 30th Annual Conference on Neural Information Processing Systems.Barcelona,Spain:NIPS,2016.4790−4798
28 Kingma D P,Welling M.Auto-encoding variational Bayes.In:Proceedings of the 2014 International Conference on Learning Representations.Ban ff,Canada:ICLR,2014.
29 Goodfellow I J,Pouget-Abadie J,Mirza M,Xu B,Warde-Farley D,Ozair S,et al.Generative adversarial nets.In:Proceedings of the 27th Annual Conference on Neural Information Processing Systems.Montreal,Canada:MIT Press,2014.2672−2680
30 Wang Kun-Feng,Gou Chao,Duan Yan-Jie,Lin Yi-Lun,Zheng Xin-Hu,Wang Fei-Yue.Generative adversarial networks:the state of the art and beyond.Acta Automatica Sinica,2017,43(3):321−332(王坤峰,苟超,段艳杰,林懿伦,郑心湖,王飞跃.生成式对抗网络GAN的研究进展与展望.自动化学报,2017,43(3):321−332)
31 Chen Wei-Hong,An Ji-Yao,Li Ren-Fa,Li Wan-Li.Review on deep-learning-based cognitive computing.Acta Automatica Sinica,2017,43(11):1886−1897(陈伟宏,安吉尧,李仁发,李万里.深度学习认知计算综述.自动化学报,2017,43(11):1886−1897)
32 Mirza M,Osindero S.Conditional generative adversarial nets.arXiv preprint arXiv:1411.1784,2014.
33 LeCun Y,Bottou L,Bengio Y,Haffner P.Gradient-based learning applied to document recognition.Proceedings of the IEEE,1998,86(11):2278−2324
34 Sermanet P,Chintala S,LeCun Y.Convolutional neural networks applied to house numbers digit classi fication.In:Proceedings of the 21st International Conference on Pattern Recognition(ICPR).Tsukuba,Japan:IEEE,2012.3288−3291
35 Liu Z W,Luo P,Wang X G,Tang X O.Deep learning face attributes in the wild.In:Proceedings of the 2015 IEEE International Conference on Computer Vision(ICCV).Santiago,Chile:IEEE,2015.3730−3738
36 Wang Z,Bovik A C,Sheikh H R,Simoncelli E P.Image quality assessment:from error visibility to structural similarity.IEEE Transactions on Image Processing,2004,13(4):600−612
37 Huynh-Thu Q,Ghanbari M.Scope of validity of PSNR in image/video quality assessment.Electronics Letters,2008,44(13):800−801
38 Xiang Zheng,Tan Heng-Liang,Ma Zheng-Ming.Performance comparison of improved HoG,Gabor and LBP.Journal of Computer-Aided Design and Computer Graphics,2012,24(6):787−792(向征,谭恒良,马争鸣.改进的HOG 和Gabor,LBP性能比较.计算机辅助设计与图形学学报,2012,24(6):787−792)
39 Kingma D P,Rezende D J,Mohamed S,Weling M.Semisupervised learning with deep generative models.In:Proceedings of the 27th Annual Conference on Neural Information Processing Systems.Montreal,Canada:MIT Press,2014.3581−3589
