基于3D卷积的视频错帧筛选方法
2018-05-25缪宇杰吴智钧
缪宇杰,吴智钧,宫 婧
(1.南京邮电大学 物联网学院,江苏 南京 210003; 2.南京邮电大学 理学院,江苏 南京 210003)
0 引 言
近年来,随着深度学习的兴起,诸如CNN等深度学习框架的提出,很多机器学习的问题得到了解决,比如在真实场景下的目标识别、人体行为分析等等。但是,其识别结果的精准度还是不能令人满意,精准度的提高依然是深度学习领域一项具有挑战性的任务。
好的视频特征应该具备丰富的与识别内容相关的信息。视频可以看作是一组连续帧,即静态图片。每张静态图片所提取的特征是独立的、互不相关的,并且只存在于空间维度上。为了更好地提取视频信息,有必要找到帧与帧之间的联系。文中采用3D卷积的方法,能够同时在时间和空间维度上提取视频特征[1]。
要正确提取视频的特征视频,首要条件是必须保证帧序列有序。假设帧序列是无序的,那么根据该序列所提取的特征很有可能是不准确的,利用这样的特征来训练或者测试深度学习的模型,很可能会导致最终结果的误判。所以,验证帧序列是否有序是一项很重要的任务。
文中提出一种方法来验证视频帧序列的顺序。首先,提出错帧筛选模型,描述了其整体结构;其次,对该模型的主要技术关键点进行详细介绍;最后,通过实验对该方法进行验证。
1 相关研究
机器学习[2]分为有监督和无监督两个类,基本上可以从它们会不会得到一个特定的标签输出来区分。监督学习(supervised learning)是通过已有的训练样本(即已知数据及其对应的输出)来训练,从而得到一个最优模型,再利用这个模型将所有新的数据样本映射为相应的输出结果,对输出结果进行简单的判断从而实现分类的目的。那么这个最优模型也就具有了对未知数据进行分类的能力。而无监督学习(unsupervised learning)[3]事先没有任何训练数据样本,需要直接对数据进行建模。无监督学习在学习时并不知道其分类结果是否正确,亦即没有受到监督式增强(告诉它何种学习是正确的)。其特点是仅对此种网络提供输入范例,且自动从这些范例中找出其潜在类别规则。当学习完毕并经测试后,也可以将之应用到新的案例上。
现有的大多数深度学习模式识别方法通常由两个关键步骤组成:第一步是手工标注数据集的特征,第二步是在已标注的特征基础上学习分类器[4-7]。但是,手工标注作为有监督学习的特点之一正变得越来越不受欢迎,原因是耗费了大量的时间和精力,尤其在数据集更加复杂的情况下,手工标注的代价成倍增长。因此,文中采用无监督学习的方法来学习没有经过手工标注的视频特征。
2 错帧筛选模型
文中的目标是通过错帧筛选模型,从若干组帧序列中,将错误的一组帧序列筛选出来。从同一个视频中采样出若干组视频帧序列(详见3.1小节),假设有N+1组帧序列,那么此模型的输入可表示为f={f1,f2,…,fN+1,其中,fi为第i组帧序列。在这组输入中,有N组帧序列是有序的,只有一组帧序列是错序的,且这组错帧的位置随机。
将f的每一组帧分别输入错帧筛选模型的一个分支,如图1所示。首先对其进行编码(详见2.2小节),编码后每个分支会通过5个卷积层和1个全连接层,这一部分与AlexNet[13]相同。每个分支网络的权值以及参数均相同。

图1 错帧筛选模型

将上述计算结果输入最后两个全连接层和一个线性分类器,这个分类器能够对N+1个输入进行分析对比,进而预测出错帧的一组视频序列。
3 关键技术
3.1 视频帧采样
视频帧的采样也是一项非常重要的工作,具有良好特性的帧序列有助于预测结果精准度的提升。如果采样的帧序列之间的变化很小,那么很难判断出这组帧序列是顺序还是乱序。图2所示为一组有序的视频帧,帧a和b、帧e和f之间的动作变化很小,而帧b、c、d、e之间差别很明显。由图2易知,很难判断{a,b,c}、{b,a,c}哪组是乱序,但{c,d,e}、{e,c,d}很容易判断,因此需要选取帧间差异较大的帧作为输入。使用粗帧级光流[14]来测量帧与帧之间的变化程度,把每个帧的平均流量大小作为该帧的权重,并用它来偏置采样较大变化帧的窗口。此方法保证了采样的帧序列不会出现难以分辨是否为错帧的情况。

图2 帧间差异示例
设采样结果为I=I1,I2, …,In这样一组包含n帧的视频序列,且有序,即I1I2…In。在上述的采样结果I中,还需要再进行一次采样作为错帧筛选模型的输入。在这个步骤中,采用了随机采样的方法。在I中随机采样出X帧图像N次,则产生了N组有序的帧序列,每组有X帧。乱序的帧序列的采样也是随机采样X帧,并保证乱序。
3.2 视频帧编码
在完成视频帧采样之后,需要对每一组帧序列进行编码,编码的目的是提取帧序列的结构信息。完成编码后,可以将多帧图片合并为一帧。这样做的好处是在训练错帧筛选模型时,不需要限定每组输入的帧数,因为不论每组输入的帧数是多少,通过编码都可以提取为一帧的信息。
文中采用3D卷积[15]的方法进行编码。在2D CNN中,2D卷积在卷积层具有提取局部邻域上层特征映射的功能。坐标为(x,y)的单元在第i层的第j个特征映射的值为:
成本有效是指成本可以被收益补偿。再生水项目的投资较大,而再生水水价一般需要维持在低于甚至远低于饮用水水价的水平,因此再生水项目实现成本有效性面临很大困难。除了选择有利的技术方案以降低成本外,争取到拨款和优惠利率的长期贷款对于降低成本也很重要,而用户收费(包括使用费和入户管网费等)也必须有保障。成本有效是再生水项目作为公用事业实现商业化运作的前提。
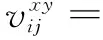
(1)
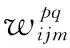
2D CNN中的特征映射也是2D的,只反映了图像空间上的信息,没有考虑时间上的信息。文中采用3D CNN中的3D卷积方法,在卷积层的特征映射连接了上一层多帧连续图像,这样既包含了空间信息,也包含了时间信息,从而可以获取一组帧序列的信息。则式1可以改写为:

(2)
其中,Ri是3D卷积核在时间维度上的大小。
在视频帧编码中只进行了一次卷积运算,然后对一组帧序列的特征映射求均值,结果即为编码的结果。
4 实验结果与分析
使用UCF101数据集进行实验。UCF101数据集是由真实用户拍摄上传的具有复杂背景的视频,共有101个动作类别,13 000个视频片段,时长共27小时。
实验中,从同一个视频片段中采样7组帧序列,其中6组是有序的,1组是无序的。每组帧序列有7帧图像,大小为80*60,卷积核大小为7*7*3(7*7表示空间维度,3表示时间维度)。将帧序列输入网络,首先对帧序列进行编码,编码结果如图3所示。

图3 帧序列编码结果
为了验证该方法的有效性,将实验获得的验证错帧结果的准确性与文献[12]比较,结果如表1所示。从表1可见,文中方法提高了对错帧检验的准确性。
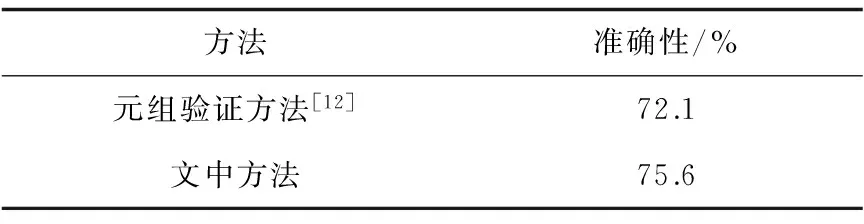
表1 不同帧顺序验证方法准确性对比
5 结束语
文中提出了一种基于3D卷积的视频帧顺序验证方法,能够对视频帧序列顺序与否进行验证。通过无监督学习视频特征的方法,避免了有监督学习中所需的手工标注标签的过程,很大程度上减少了时间与精力的耗费。3D卷积对视频序列特征的提取,不仅获取了该序列空间上的信息,同时获取到了时间上的信息,提升了验证的准确性。
参考文献:
[1] 林海波,李 扬,张 毅,等.基于时序分析的人体运动模式的识别及应用[J].计算机应用与软件,2014,31(12):225-228.
[2] 郭丽丽,丁世飞. 深度学习研究进展[J].计算机科学,2015,42(5):28-33.
[3] 殷瑞刚,魏 帅,李 晗,等.深度学习中的无监督学习方法综述[J].计算机系统应用,2016,25(8):1-7.
[4] 王满一,宋亚玲,李 玉,等.结合区域光流特征的时序模板行为识别[J].系统仿真学报,2015,27(5):1146-1151.
[5] JHUANG H,SERRE T,WOLF L,et al. A biologically inspired system for action recognition[C]//International conference on computer vision.Rio de Janeiro,Brazil:IEEE,2007:1-8.
[6] 杨祎玥,伏 潜,万定生.基于深度循环神经网络的时间序列预测模型[J].计算机技术与发展,2017,27(3):35-38.
[7] 徐庆伶,汪西莉.一种基于支持向量机的半监督分类方法[J].计算机技术与发展,2010,20(10):115-117.
[8] DOERSCH C,GUPTA A,EFROS A A.Unsupervised visual representation learning by context prediction[C]//International conference on computer vision.[s.l.]:IEEE,2015.
[9] 朱 陶,任海军,洪卫军.一种基于前向无监督卷积神经网络的人脸表示学习方法[J].计算机科学,2016,43(6):303-307.
[10] PICKUP L C,PAN Z,WEI D,et al.Seeing the arrow of time[C]//IEEE conference on computer vision and pattern recognition.Columbus,OH,USA:IEEE,2014:2043-2050.
[11] JAYARAMAN D,GRAUMAN K.Learning image representations tied to ego-motion[C]//International conference on computer vision.Santiago,Chile:IEEE,2015:1413-1421.
[12] MISRA I,ZITNICK C L,HEBERT M.Shuffle and learn:unsupervised learning using temporal order verification[C]//European conference on computer vision.Berlin:Springer,2016:527-544.
[13] JEFF D,JIA Yangqing,VINYALS O,et al.DeCAF:a deep convolutional activation feature for generic visual recognition[C]//International conference on machine learning.Beijing,China:ACM,2014.
[15] JI Shuiwang,XU Wei,YANG Ming,et al.3D convolutional neural networks for human action recognition[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2013,35(1):221-231.
