基于文本属性的微博用户相似度研究
2018-05-25李梦洁
李梦洁,邵 曦
(南京邮电大学 通信与信息工程学院,江苏 南京 210003)
0 引 言
微博模仿了人类社会的结构,将用户组织成完整的社会网络,实现了用户的个性化信息发布、社会性传播和一些私人或公开的社交的需求。在自媒体时代,用户不再仅仅是信息的接受者,也是信息的发布者,信息在用户的社交行为中发生了由点到面的爆炸式传播[1]。
微博用户的兴趣可以体现在用户关系中[2],但是由于微博的用户量巨大,往往拥有数以亿计的用户节点。2017年5月份的微博官网数据显示,微博活跃用户达到3.4亿,已超过Twitter的3.28亿。在如此大的数据量下,用户在建立自己的社会关系时,将面临数据超载的问题。因此,帮助用户在茫茫人海中找到他们可能感兴趣的人是非常重要的。所以,相似用户的研究在好友推荐、用户聚类、社区发现、热点预测和舆论引导等方面都有重要的意义[3-4]。
与在现实中的交友类似:新的陌生环境中,人往往会对与自己相似的人产生兴趣。譬如,在新班级中会先认识老乡;在新单位中会与有相同兴趣爱好的人产生共同话题等。
文中就利用了微博用户的部分背景信息,以及发送微博和转发微博等社交行为,针对不同的属性数据采用不同的计算方式,构建综合相似度计算模型,计算、筛选出与该用户最相似的用户列表。
1 相似度计算相关研究
以往的一些相似度计算方法需要转换数据,并对数据归一后进行计算[5],但微博用户的描述不仅需要用户本身的背景信息,更需要注意用户的社交行为,简单地转换数据类型和计算不能准确合理地评价用户,在转换过程中也会导致大量的数据丢失。
基于微博的相似度计算研究可以分为三类:
(1)Krishnamurthy[6]通过Twitter中关注(following)与被关注的关系将用户分成三类,基于用户关系构建网络拓扑,算法的核心思想是用户之间的关注关系,而不考虑用户自己的背景信息;
(2)用户之间的共同邻居数量作为相似度计算标准,即用户之间的共同好友越多,用户之间的相似度越高。CN(common neighbors)模型[7]、Cosine相似度模型以及Jaccard相似度模型、Hub Promoted(HP)相似度模型、HD相似度模型等[8]属于这类方法。上述方法将用户间的共同好友数量占自身好友数量的比例作为相似度的度量。但这些方法没有考虑用户自己的信息对相似度计算的影响;
(3)徐志明等[9]对微博的相似性进行研究,将微博社会网络视为一个加权无向图,该文将用户关系强度定义为用户之间的相似度,分别给出了基于各种用户属性信息的用户相似度计算方法。该算法没有考虑用户的性别、年龄和兴趣点,也没有综合考虑用户的基本信息和交互信息。
2 用户属性相似度模型
根据获取到的新浪微博的用户数据,分析用户的各种属性信息,根据属性的数据结构,用不同方法来具体计算各个相似度,根据获取的数据属性所占比例、属性分布情况等确定各个属性的权值,最后对各个相似度求出加权均值得出用户总的相似度。
文中相似度主要划分为两个角度:背景相似和兴趣相似(如图1所示)。这两种角度的相似相辅相成,并存在相互影响,甚至相互转化的关系[10]。
2.1 背景相似度
背景相似度主要是指与社交活动无关的用户自身条件,如用户所在地理位置,使用设备,习惯的活动时间,以及性别、工作信息、教育信息等。
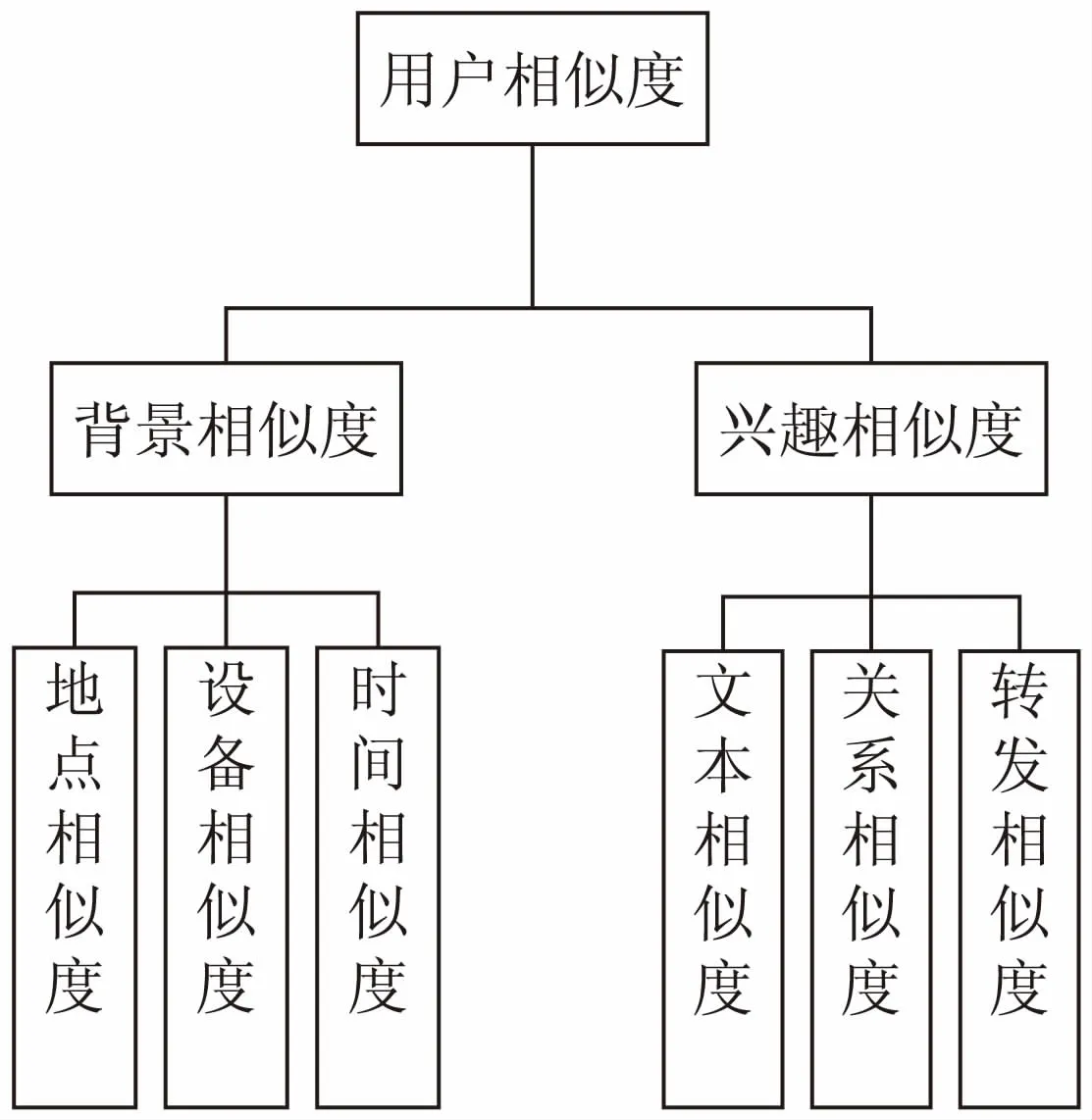
图1 用户相似度模型
2.1.1 地点相似度
用户所在地是微博客户端中每个用户主页的第一条信息,是每个用户给人的第一印象。用户所在地是用户在申请账号时所填写的用户所在的地理位置,海外用户精确到国家,国内用户精确到省市,直辖市用户精确到区。
人们本能地亲近于与自己处在同一地域的人,在心理学上,这称为地域文化心理。表现为对自己的地域及地域基础上生活的人有一种本能的亲近心理。同一所在地的用户,往往对政治、经济、历史等有着相似的关注点和见解,所以由用户所在地计算出的用户地点相似度,是用户相似度的重要组成部分。
用D(Ux,Uy)表示两用户之间的距离,其中Dactual表示两用户的实际空间距离,由用户填写的所在地对应到点的经纬度,根据两个经纬度点计算出两点之间的距离,其中用到Haversine公式。
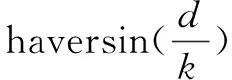
cos(φ1)cos(φ2)haversin(Δλ)
(1)
(2)
其中,R表示地球半径,可取平均值6 371 km;φ1,φ2表示两点的纬度;Δλ表示两点经度的差值。
用Dextra表示不同行政区用户之间存在的附加距离,这一附加距离既不能完全否定距离相近的用户的相似性,又要体现不同行政区域内的用户之间的差异。取Dcountry为国内两用户距离的均值,以区分国内用户和海外用户。取Dprovince为同省两用户的平均距离,以保证实际距离相同时,同省的用户更加具有相似性这一事实。得出的距离D(Ux,Uy)需要用一个定义在0到正无穷的减函数进行归一化,从而计算出地点相似度Simd(Ux,Uy)。
D(Ux,Uy)=Dactual+Dextra
(3)
(4)
2.1.2 设备相似度
由微博官方提供的数据显示,截至2017年3月底,移动端月活跃用户占比已提升至91%。现如今,智能手机和平板电脑已经成为人们日常生活的重要组成部分。微博客户端中会显示每条微博的来源,包括发送微博的使用设备,或由站外的哪个应用所发送。使用的设备能体现出该用户的上网习惯,并能从一方面体现出该用户对电子设备的选择倾向以及购买力;站外来源也能反映出该用户最近使用的应用。拥有相同来源的用户,必然比使用不同来源的用户更加具有相似度。定义设备相似度为Sime(Ux,Uy),拥有相同来源的用户,在设备这一维度的相似度为1,否则为0。
(5)
2.1.3 时间相似度
用户发微博的时间习惯常常被忽略,其实这也是能反映用户信息的。用户会选择工作学习的休息时间使用微博,并且大多数微博用户都有睡前看微博的习惯。所以微博的发送时间,能部分体现出用户的作息时间。使用两用户发微博的时间差T(Ux,Uy)来衡量时间相似度Simt(Ux,Uy)。时间差越大,相似度越小,需要使用合适的减函数来归一化时间差。经过测试,考虑到时间差最大为24小时,而当时间差过大,则不具备区分度。当时间差大于3小时,相似度小于0.5,使用指数函数来归一化该相似度,取底数为0.75。
Simt(Ux,Uy)=0.75T(Ux,Uy)
(6)
考虑到性别、教育水平填写不完善,不能区分出用户的兴趣点。在实验调查中,大于50%的用户都没有填写教育工作信息,所以暂不考虑这几个属性。
2.2 兴趣相似度
在微博这个社交平台中,用户的兴趣点体现在其社交行为上。越相似的两个用户,就会拥有越多相似的社交行为。
2.2.1 文本相似度
微博文本信息数据量庞大,用户在浏览这些信息的同时,需要花大量的时间和精力来对其进行筛选和辨别。而用户发出的文本信息,是所有社交行为中最主观最直接的信息输出,是体现用户个性以及兴趣点的最重要部分。所以在对相似用户的研究中,需要着重研究该部分的相似度,文本相似度模型如图2所示。

图2 文本相似度模型
(1)预处理。
预处理中需要对微博文本进行噪声处理。过滤微博文本中无意义的“@用户名”或网址,或者发自某应用等。这些信息是在发微博的过程中自动生成的,而非用户主观输出。
(2)分词及去停用词。
分词后利用完善的停用词表对文档去除停用词,去除一些不包含有用信息的符号、数字、语气词、转折词以及使用频率特高的单汉字等。将这些词过滤掉,减少了索引量,增加了检索效率,并且通常都会提高检索的效果。
(3)TF-IDF变换。
TF-IDF(term frequency-inverse document frequency)是一种用于信息检索与数据挖掘的常用加权技术。IDF指“逆向文件频率”,将用词频向量中的词频,变换为词的重要性。该方法评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。其实在文本信息的提取中,高频词区分能力较小,而低频词也常常可以作为关键特征词,所以并不是高词频就是主题词。在TF-IDF变换中,字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降,这样能全面体现一句话中每个词的地位[11-12]。
(4)余弦相似度。
余弦相似度是一种非常有用的算法,只要是计算两个向量的相似程度,都可以采用。假定A和B是两个n维向量,A是[A1,A2,…,An],B是[B1,B2,…,Bn],则A与B的夹角θ的余弦等于:
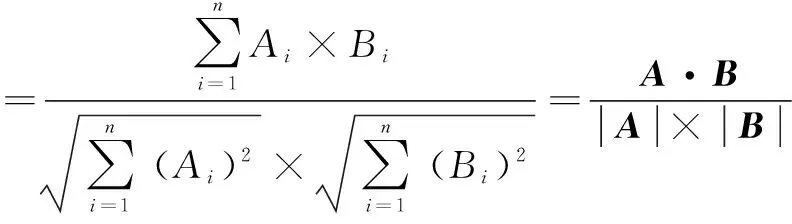
(7)
余弦值越接近1,就表明夹角越接近0°,也就是两个向量越相似,这就叫“余弦相似性”。当两个文本的TF-IDF向量夹角越小,则表示这两个文本越相似。用余弦相似度来表示文本相似度Simw(Ux,Uy)[13-14]。
2.2.2 关系相似度
关注同一用户、拥有相同的粉丝都能表现出两用户兴趣点的相似。微博中两个用户之间的关系分为单向关注或者双向关注,双向关注即为好友关系。文中关系相似度分为两个方面:
(1)用户x与用户y的共同关注比例,两用户共同关注的人越多,占据关注总数的比例越高,则两用户的关注相似度就越高。设用户x的关注列表为Fx,其数量为num(Fx),则相似度为:
(8)
(2)用户x与用户y是否为相互关注,即x∈Fy且y∈Fx,则用户x与y为好友。
(9)
两种关系相似度能共同体现出用户之间的社交关系[15]。
2.2.3 转发相似度
对同样的微博内容进行转发操作,代表着对同一条信息的密切关注,并且对这一条信息进行了再次传播,这样关注了该用户的人也能看到这一信息,转发是微博中的重要社交行为。若两用户之间发生多次转发,则这两个用户一定有着非常密切的联系。文中用正切三角函数tanh对转发次数rcount进行归一化,得到转发相似度Simf(Ux,Uy) 。
Simf(Ux,Uy)=tanh(rcount)
(10)
其中,用tanh(count)把次数转换为0到1的相似度。
3 结合层次分析法的相似度模型
对于已经得到的背景相似度Simb(Ux,Uy)和兴趣相似度Simi(Ux,Uy),需要进一步求和处理才能得到最终的用户相似度。其中背景相似度由地点相似度、设备相似度以及时间相似度决定,而兴趣相似度由文本相似度、关系相似度、转发相似度决定。各个相似度属性均已归一化处理,使之取值在区间[0,1]上。
其中各个相似度属性明显具有不同的地位,简单的加和求均值不能全面准确地描述两用户之间的相似度。所以需要选择合适的方法,给各个相似度分配合理的权重w1,w2,w3…,计算后得到最终的用户相似度Sim(Ux,Uy)。
Sim(Ux,Uy)=wbSimb(Ux,Uy)+wiSimi(Ux,Uy)=
w1Siml(Ux,Uy)+w2Sime(Ux,Uy)+
w3Simt(Ux,Uy)+w4Simw(Ux,Uy)+
w5Simr(Ux,Uy)+w6Simf(Ux,Uy)
(11)
由于有六个相似度参数,简单粗糙地给权重赋值[16]往往不甚合理,此时需要使用层次分析法。层次分析法能够将一个复杂的问题分解为各个组成因素,并将这些因素按支配关系分组,从而形成一个有序的递阶层次结构,通过两两比较的方式来确定层次中的各个因素的重要性,生成判别矩阵,从而计算出各属性对影响决策所占的比重,即权值。定义判断矩阵An×n:
(12)
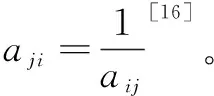
4 实验及结果分析
采用新浪微博及其API接口、Pycharm、Mysql作为数据的获取、统计以及属性权值、相似度计算工具。数据集包括63 641个新浪微博用户的基本信息和这些用户之间的1 391 718条好友关系,以及这些用户发出的84 168条微博和微博之间的27 759条转发关系。用户信息中包括了3 192个海外用户,60 449个国内用户。
4.1 文本相似度
在相似度计算中,对微博文本进行预处理、分词、过滤停用词等操作,经过TF-IDF变换后进行文本相似度计算。以ID为2609400635的用户微博为例,对文本进行处理。
预处理可以去除微博文本中“@某用户”、网址、表情符号等内容。在表1中的两个表情“[馋嘴]”、“[抓狂]”被过滤掉。分词后的结果内容较多,如“了”、“呀”、“马上”这些词,出现频率很高但没有实际意义,作为停用词被剔除后可以提高后续TF-IDF处理的效率。
在做TF-IDF变换之前需要生成构造词典,构造词典中为每个词组编号,便于后续数字化的向量处理。该实验中的构造词典中包含了132 827个词组,在上述微博文本的例子中用到的词组及其对应编号有:149:我要,411:一个月,7073:复习,13955:看书,18714:中考,40216:劳逸结合,41616:真累。生成语料库,转换为词频向量方便处理。在TF-IDF变换中,将词频向量中的词频转换为词的重要性,词组的重要性随着词频成正比增加,同时也随着它在语料库中出现的频率成反比下降。

表1 文本处理
经过以上处理后比较余弦相似度,文本A:“还有一个月就要中考了,最近复习真累呀,所以我要劳逸结合下,马上又要看书了!”;文本B:“宁愿看韩剧也不想看书”;文本C:“故事由此开始...Lin,林书豪,林疯狂,我要疯狂~闪电突破!”。经比较后,文本AB的相似度为0.263 104,文本AC的相似度为0.079 880 9。显然,文本A与文本B都是在讨论看书与否,而与C无关。
4.2 处理权重
文中使用层次分析法计算各个相似度的属性的权重,由式12得:
微博用户背景相似度与兴趣相似度的判断矩阵分别为:
地点 设备 时间
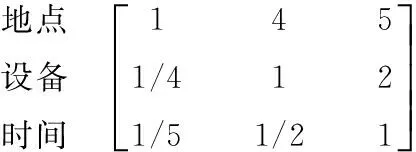
文本 关系 转发
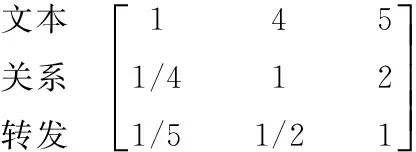
背景相似度与兴趣相似度之间的判断矩阵为:
文本 关系
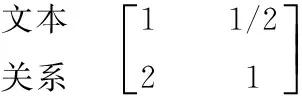
Saaty等建议用对应于最大特征根的特征向量作为权向量,得到各个相似度的权重,见表2。

表2 权值分配
4.3 评价指标及结果分析
文中采用准确率(Precision) 、召回率(Recall)、F1度量值(F1-measure)作为实验结果的评估指标。以用户关注的公众号话题信息以及微博的主题标签为相似用户的标准答案,比较基于文本相似度的算法与不使用文本相似度的算法之间的指标差别。
按表2中的权值计算基于文本相似度和未考虑文本相似度的用户相似度。分别计算后,取相似度最大的N%用户作为相似用户的计算结果,比较不同N值下的准确率、召回率和F1度量值。
准确率是提取出的正确相似用户个数Nc与提取出的用户数Nt的比值,该值越大,准确率越高。计算方法如下:
(13)
召回率是提取出的正确相似用户个数Nc与所有正确相似用户个数Nts的比值,比值大的结果更优越。计算方法如下:
(14)
两者取值在0和1之间,数值越接近1,查准率或查全率就越高。
F1度量值是综合准确率和召回率的评估指标,即为准确率和召回率的调和平均值。该度量值越大,该方法的结果越准确。计算方法如下:
(15)
各指标计算结果如图3所示。
图3的结果体现了基于文本相似性的相似用户计算方法的优越性。当然,希望检索结果Precision越高越好,同时Recall也越高越好,但事实上这两者在某些情况下是有矛盾的,而F1值则是综合这二者指标的评估指标,用于综合反映整体的指标。如图3(c)所示,当N%取50%时,未结合文本的相似度算法的F1值为0.306,而基于文本属性的相似用户计算方法取得的F1值达到了0.411,提高了34.3%。

图3 两种算法对比
5 结束语
提出了一种基于文本属性的相似用户计算方法。简单概括了相似度计算的相关研究;接着分析介绍了文中用到的用户属性相似度模型,对各个属性做了一一分析,重点分析了文本相似度计算方法,其中的分词过程和TF-IDF变换都是计算文本相似度的重要部分,用余弦相似度衡量了微博中的文本相似度。为了更好地衡量微博用户的兴趣相似度,又对微博的转发与用户好友关系加以充分利用。最后用层次分析法确定各个参数的权重,因此从多个角度,更为全面、准确地衡量了微博用户之间的相似性。用F1度量值对结果进行了评价,结果表明,基于文本属性的微博相似用户的计算方法提高了算法的准确度。同时,该方法也存在一定的局限,即未能用动态数据进行测试,若以用户最新的微博文本来计算用户的相似度,会在好友推荐、用户聚类、热点预测中有更好的效果。
参考文献:
[1] 王连喜,蒋盛益,庞观松,等.微博用户关系挖掘研究综述
[J].情报杂志,2012,31(12):91-97.
[2] 张俊豪,顾益军,张士豪.基于距离模型的用户关系强度评估[J].信息网络安全,2015(10):86-91.
[3] 谢耘耕,徐 颖.微博的历史、现状与发展趋势[J].现代传播:中国传媒大学学报,2011(4):75-80.
[4] LIAO Yang,MOSHTAGHI M,HAN Bo,et al.Mining micro-blogs:opportunities and challenges[M]//Performance evaluation of social network using data mining techniques.London:Springer,2012:129-159.
[5] 郭金玉,张忠彬,孙庆云.层次分析法的研究与应用[J].中国安全科学学报,2008,18(5):148-153.
[6] KRISHNAMURTHY B,GILL P,ARLITT M.A few chirps about Twitter[C]//Proceedings of the first workshop on online social networks.Seattle,WA,USA:ACM,2008:19-24.
[7] 逯 鹏,张姗姗,高庆一.基于共同邻居的点权有限BBV模型研究[J].计算机科学,2014,41(4):49-52.
[8] 秦宏宇.网络舆情热点发现相关技术研究[D].哈尔滨:哈尔滨工程大学,2010.
[9] 徐志明,李 栋,刘 挺,等.微博用户的相似性度量及其应用[J].计算机学报,2014,37(1):207-218.
[10] 乔秀全,杨 春,李晓峰,等.社交网络服务中一种基于用户上下文的信任度计算方法[J].计算机学报,2011,34(12):2403-2413.
[11] 王振振,何 明,杜永萍.基于LDA主题模型的文本相似度计算[J].计算机科学,2013,40(12):229-232.
[12] 陈 攀,杨 浩,吕 品,等.基于LDA模型的文本相似度研究[J].计算机技术与发展,2016,26(4):82-85.
[13] 黄贤英,陈红阳,刘英涛.短文本相似度研究及其在微博话题检测中的应用[J].计算机工程与设计,2015,36(11):3128-3133.
[14] SHARIFIB M,HUTTON A,KALITAJ K.Automatic microblog classification and summarization[C]//Proceedings of human language technologies:conference of the North American chapter of the association of computational linguistics.Stroudsburg:Association for Computational Linguistics,2010:685-688.
[15] YIN Dawei,HONG Liangjie,DAVISON B D.Structural link analysis and prediction in microblogs[C]//ACM conference on information and knowledge management.Glasgow,United Kingdom:ACM,2011:1163-1168.
[16] SONG Dezhao,HEFLIN J.Domain-independent entity conference in RDF graphs[C]//Proceedings of the 19th ACM international conference on Information and knowledge management.Toronto,Ontario,Canada:ACM,2010:1821-1824.
[17] 郑志蕴,贾春园,王振飞,等.基于微博的用户相似度计算研究[J].计算机科学,2017,44(2):262-266.
