随机森林在阿尔茨海默病患病分析中的应用
2018-05-11姜博原刘丽
姜博原 刘丽
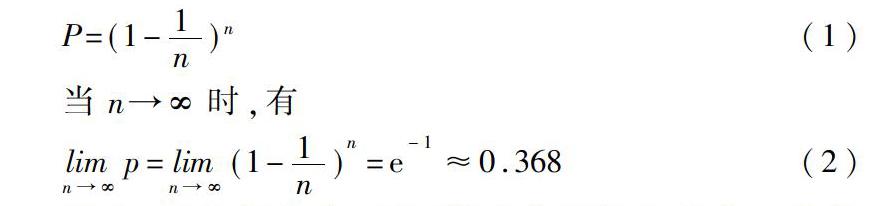
【摘 要】基于随机森林算法能够对阿尔茨海默病患病的情况进行分析。通过去除常量、基于有监督学习的特征选择及相关数据检测,对人体各项指标的数据进行合理的降维处理。创建基于随机森林的分类器,将其应用于阿尔茨海默病患病分析,利用降维后有效的特征属性得到的结果可以反应患病情况和诊断状况。
【关键词】随机森林;决策树;降维;阿尔茨海默病
中图分类号: F273.2 文献标识码: A 文章编号:2095-2457(2018)06-0088-002
【Abstract】Based on the random forest algorithm, we can analyze the prevalence of Alzheimers disease. Through the removal of constants, feature selection based on supervised learning, and related data detection, the data on the human bodys indexes are rationally reduced. A random forest-based classifier was created and applied to the analysis of Alzheimers disease. The results obtained by using the effective characteristic attributes after dimension reduction can reflect the prevalence and diagnosis.
【Keywords】Random forest; Decision tree; Dimension reduction; Alzheimers disease
1 理論基础
随机森林是由Leo Breiman(2001)提出的一种比较新的机器学习模型[1]。它是由多个随机创建的决策树所构成的分类器,因此,决策树之间不存在必然联系,所以被称为随机决策树。当随机森林收到数据时,将通过所有决策树依次对数据进行分类,从而得到与决策树个数相同的分类结果数,然后把全部分类结果中出现次数最多的类别作结果。因此,它是一个通过投票方式,将票数最多结果作最终结果的分类器。
1.1 Bootstrap法重采样
设样本集S*中含有n个不同的样本{X1,X2,…,Xn},假设有放回地从样本集S中每次抽取一个样本,总共抽取n次,组成新的样本集S*,那么样本集S*中不包含某个样本Xi(i=1,2,…,n)的概率为
因此,虽然新集合S*的样本总量与原集合S的样本总量相等(都为n),但是在新集合S*中,由于采用有放回的方法抽取,因此存在重复样本,如果去除重复样本,那么新集合S*中只包含了原集合S中约1-0.368×100%=63.2%的样本总量。
1.2 Bagging算法概述
Bagging(Bootstrap aggregating的缩写)算法是最早的集成学习算法[2]。它的基本思想如图1所示,具体的步骤如下:
(1)使用Bootstrap方法,在允许重复抽取样本的前提下,随机产生T个可用于建立模型的训练集S1,S2,…,Sn;
(2)通过随机产生的训练集,建立决策树模型C1,C2,…,Cn;
(3)利用全部决策树模型,对测试集X进行测试,并得到所有决策树的最优解C1(X),C2(X),…,Cn(X);
(4)通过投票的方法,把全部最优解中出现次数最多解作为测试集X的最优解。
1.3 随机森林算法流程
随机森林是一种集成树形分类器,它采用 bootstrap 采样,从原始训练集中得到多个训练子集[3-4]。两者的区别是,随机森林算法采用了随机抽取分裂特征集的方法构建决策树。设M,m大于零,样本特征的个数为M,M大于m,具体的随机森林算法步骤如下所示:
(1)利用Bootstrap方法从原始样本集中随机抽取T个训练集S1,S2,…,Sn[5]。
(2)利用T个训练集,构建相应的决策树模型C1,C2,…,CT;设每棵决策树有M个特征,从这些特征中随机选取m个特征进行测试,然后获得这m个特征中的最优解,最后对这个最优解进行分裂。
(3)不对决策树模型进行简化处理,忽略过度拟合,允许它完整生长。
(4)利用每个决策树对测试集X进行处理,得到对应的最优解C1(X),C2(X),…,CT(X)。
(5)用投票的方法处理T个决策树中出现的最优解,把出现次数最多的最优解作为测试集X的测试结果。
2 随机森林在阿尔茨海默病患病分析中的应用
2.1 问题描述
选取来自某医学论坛与阿尔茨海默病相关的人体各项指标检测的数据。数据中包含了大量各项人体指标,这些数据都可能与阿尔茨海默病存在联系。由于研究对象为高维矩阵,面临维数灾难问题,因此,需要对该高维矩阵进行降维处理,筛选出与阿尔茨海默病关联性较强的数据,并建立一个确定的模型来描述高维矩阵中各个量化特征与阿尔茨海默病之间的关系,从而可以根据降维后各项人体指标的量化特征得出被检测人员的阿尔茨海默病的患病情况。
2.2 建模过程
2.2.1 设计思路
首先对阿尔茨海默病的数据进行降维,将降维后的数据作为模型的输入数据,正常和患病作为模型的输出结果。利用训练集数据构建随机森林模型,然后通过仿真测试获得相应结果并进行整理分析。
2.2.2 设计步骤
根据上述设计思路,设计基于随机森林算法对阿尔茨海默病患病情况的分析步骤主要包括以下几个部分,如图2所示。
2.2.3 数据采集
数据来源于某医学论坛与阿尔茨海默病相关的人体各项指标检测的的数据集,共包括10000个检测结果,第238列為目标列。通过常量筛选和有监督学习的特征选择降维后剩3000个检测结果,第238列仍为目标列,如图3所示。随机抽取300组数据作为测试集,其余2700组数据作为训练集。
2.2.4 数据降维
利用SPSS实现常量去除,实现初步降维,利用SPSS Modeler实现有监督学习的特征选择,获取有效特征属性,实现特征降维。
2.2.5 随机森林分类器
以训练数据为依据,在数据获取和数据降维完成后,构建一个随机森林分类器,使用randomforest-matlab工具箱中的方法classRF_train()。其调用格式为:
model=classRF_train(X,Y,ntree,mtry,extra_options)
上述方法中,X表示输入的数据;Y表示输出的数据;ntree表示决策树个数;mtry表示做分裂处理的特征集中元素的个数;extra_options表示可控参数;model表示当前采用的随机森林模型。
2.2.6 仿真测试
完成对随机森林的构建后,开始进行仿真测试,通过使用randomforest-matlab工具箱中的方法classRF_predict()。其调用格式为:
[Y_hat,votes]=classRF_predict(X,model,ext_options)
上述方法中,Y_hat表示测试集样本的类别;votes用于记录每一个类别获得的票数;X表示待输入的测试集样本,它的行表示单个样本,它的列表示单个变量;model表示当前采用的随机森林模型;extra_options表示可控参数。
2.2.7 输出结果
利用随机森林模型进行仿真测试的输出结果,如图4所示,可以得到正常者和患病者的人数,并能得到误诊率(包括正常和患病被误诊为另一项),从而可以对该方法的可行性进行评价。同时,也可以与其他仿真方法结果进行比较,探讨该方法的有效性。
3 性能分析
这里仅在默认的决策树棵树(500)情况下进行分析讨论。这里用一个布尔型问题进行阐述,因此随机森林中的决策树的输出类别只有两种(1:患病,-1:正常)。如图5所示,横轴表示所有决策树中,输出结果为1的决策树数量;纵轴表示输出结果为-1的决策树数量。理想状态下,对于某一个样本而言,其在图5上的坐标p(x,y)总体上应满足以下关系:
x+y=500(3)
并且,如果随机森林对该样本的预测类别与真实的类别一致,则在图中用“o”标记;反之,则用“*”标记。
3.1 错误分类样本个数
一个具有较好泛化性能的随机森林分类器,其错误分类的样本数应该越少越好;若一个随机森林分类器对于很多个样本都不能正确地分类,显然这个(下转第40页)(上接第89页)随机森林分类器的泛化性能是有待商讨的。
3.2 错误分类样本的位置
从理论上分析,如果图像中被错误分类的样本分散在函数图像附近,即仿真测试结果中,决策树输出为1的类别和-1的类别数量基本相同,那么,这样的错误样本是可以被允许的,此时的随机森林泛化性良好。
相反,如果偏离函数图像的样本都为错误分类的样本,说明在当前随机森林模型中,输出结果为1和-1的决策树数量相差较大,并且被错误分类。这种结果被认为是不合理的,因为当前随机森林模型无法对训练集以外的数据集进行良好分类。
3.3 随机森林棵树
随机森林中构建的决策数量,对其泛化性也有一定影响。为了分析随机森林的性能,需要尽量消除决策树数量对结果造成的影响,因此,在确定决策树数量后,依次建立100个随机森林模型进行仿真测试,最终把当前决策树数目下正确率的平均值,作为当前分类的正确率。
对于本次测试数据,经过大量测试和分析,综合考虑决策树数量和建模速度对测试的影响,当决策树数量在50~100时,所得分类结果较为理想。
4 小结
随机森林能够通过对与阿尔茨海默病相关的各项人体指标数据的仿真测试,分析预测是否患有阿尔茨海默病,但由于分类样本结果在一定程度上偏离相关函数,因此,这个随机森林分类器无法很较好的对训练集之外的数据集进行正确分类,我们后期将会继续改进。同时分析预测性能受决策树棵树影响,因此,我们也会加强对随机森林的性能分析的研究,确定随机森林中最优的决策树棵树,以便获得更加准确的结果。此外,不少专家对随机森林做了不少改进和完善,并且取得了丰硕的研究成果。也有一些学者尝试将随机森林思想与其他分类器相结合,也取得了不错的进展,因此,在以后,我们也将做一些尝试和深入研究。
【参考文献】
[1]苏亚麟,吕开云.基于随机森林算法的特征选择的水稻分类——以南昌市为例[J].江西科学,2018,01(36):161-167.
[2]Beriman L.Bagging predictors[J].Machine Learning,1996,24(2):123-140.
[3]全雪峰.基于随机森林的乳腺癌计算机辅助诊断[J].软件,2017,03(38):57-59.
[4]朱炜,李东,沈飞,汤根云,吴建明,陈继民,刘政,王志辉.高光谱遥感森林树种分类研究进展[J].浙江林业科技,2013,02(33):84-90.
[5]方匡南,吴建彬,朱建平,谢邦昌.随机森林研究方法综述[J].统计与信息论坛,2011,26(3):32-37.