多模式并行处理纹理引擎硬件体系结构设计
2018-05-11韩立敏郑新建任向隆
韩立敏,田 泽,郑新建,张 骏,任向隆
(1.中国航空工业集团有限公司西安计算技术研究所,陕西 西安 710068;2.集成电路与微系统设计航空科技重点实验室,陕西 西安 710068)
0 引言
3D计算机图形学领域发明和应用了大量的渲染技术,对于合成高质量的图像来说,纹理贴图技术不需要执行大量的计算操作就可以产生真实感的高质量图像,使纹理贴图成为提高3D图形表面真实感最受欢迎的技术之一[1]。
在纹理贴图应用程序的执行过程中,每个像素(Fragment)的纹理请求需要串行的执行多种操作,包括纹素采样地址的计算、纹理缓冲区的存储器访问、纹素颜色数据的格式转换和纹理过滤操作。每个像素的1个纹理请求包含1~8个外部存储器(DDR3)的存储访问请求,因此需要为每个纹理请求计算1~8个纹素地址,为每个纹理请求执行1~8个纹素数据的格式转换操作、多模式(线性,双线性,三线性)的纹素过滤操作。
本文采用自顶向下完全正向的设计方法,在分析Opengl纹理图像加载函数的功能和纹理对象管理机制的基础上,独创性地提出纹理映射系统的组成结构,总结出纹理映射的执行流程。纹理贴图既是一种存储密集型的操作,也是一种计算密集型的操作。通过挖掘纹理映射请求内多个计算步骤数据操作的并行性、纹素数据在纹理贴图过程中时间与空间维度上的存储访问局部性,设计了一种支持Opengl 2.0标准的流水结构、多路并行处理的硬件纹理映射引擎,采用硬件并行加速手段为航空工业计算所自主研发GPU解除了性能瓶颈。
1 相关研究工作
纹理映射操作中的纹理存储器访问需要消耗图形加速器的大量存储器带宽和功耗。以嵌入式GPU为例,GPU获取纹素数据平均消耗62%的存储器带宽[2-4]。现代3D图形应用中使用了大量的纹理图像,存储纹理图像需要消耗大量的存储器容量,为了解决这个问题,出现了大量的纹理压缩算法[5]。为了降低纹理请求对纹理存储器的带宽需求,工业界和学术界在片上纹理Cache的设计和纹理数据压缩方面已经取得大量的成果。在学术界,Jhe-Yu Liou提出了一种6D数据块结构的纹理Cache,然而,获取一个大数据块需要触发多个突发式的存储器访问请求,导致存储器访问的效率降低[6]。Michael Doggett预测在未来一段时间内,为了实现高性能,纹理Cache依然必须存在于GPU的硬件逻辑中[7]。文献[8]综述了现代GPU的纹理压缩算法。为了获取高质量的图像数据,一般对纹理的压缩操作没有实时性的需求,可以离线实现压缩,然而,为了在GPU中实现实时解压缩操作,要求纹理解压缩操作不但要支持随机存储器访问而且容易采用硬件实现。
主流高端GPU均集成了多个硬件纹理映射单元,专门用于加速纹理映射操作。例如,2012年8月28日,AMD推出了radeon 7970 GCN结构的GPU,该GPU包含一个全相联的纹理Cache,每个计算单元(CU)包含了4个纹理单元,每个纹理单元包含8个纹理地址产生单元、20个纹理采样器和4个纹素过滤单元。这些纹理单元支持DXTC/S3TC和3Dc格式的自动解压缩[9]。Imagination公司的powerVR系列6 rogue GPU具有一个统一着色簇阵列,每个簇包含大量的纹理单元和1个512 KB的纹理Cache[10]。ARM mali-T880移动GPU具有一个共享的纹理流水线(Texture Pipeline),能够执行各向异性计算,产生梯度描述符,该GPU的存储器带宽优化机制包括ASTC和AFBC[11]。NVIDIA的GF100 GPU的每个统一着色核(Streaming Multiprocessor,SM)具有4个纹理单元(Texture Unit),将纹理单元作为统一着色核的一个执行部件,加速纹理操作。为了降低片外的存储访问次数,NVIDIA Tegra 4处理器中的GPU包含了片上的顶点Cache、纹理Cache和像素Cache。每个像素着色器包含一个能够执行FP16纹理过滤操作的纹理过滤单元[12]。Broadcom公司的Videocore IV四核处理器的每个着色核包含一个TMU(纹理和存储器查询单元),每个纹理单元具有一个L1 Cache,L2 Cache被所有的纹理单元所共享[13]。
虽然国外商用GPU的纹理单元均实现了基本相同的功能,但是其微体系结构的组织方式、输入和输出接口的设计、纹理请求输入参数的传输方式、纹理参数的存储和获取方式,以及并行流水线的个数随着GPU统一着色核的指令集和统一着色核的微结构不同,存在较大的差异。此外,描述纹理单元内部的微结构和实现原理相关公开文献资料非常少,全自主知识产权的GPU研制难以借鉴成熟商用的GPU相关的设计思想。
国内在纹理映射的原理及其相关算法开展较早,卢章平等人对纹理映射的方法进行了综述[14]。简洪登使用GLSL语言在算法级对多重视频纹理映射和融合技术进行了研究和实现[15-16]。在硬件加速方面,中国科学技术大学研究了纹理映射算法的FGPA实现[17],天津大学提出了一种专用的硬件纹理映射系统结构[18]。西安邮电大学的焦继业等人总结了嵌入式图形处理器高性能和低功耗设计技术的研究现状,并预测了纹理压缩技术等存储访问技术的发展趋势[19]。西安电子科技大学的董梁对图形处理器中的光照和纹理映射进行了流水化的硬件设计[20]。总体上,国内的相关研究对纹理映射操作各个阶段的算法进行了较为深入的研究,但是从系统角度对纹理贴图操作的实现原理和操作并行化问题研究的较少。
图形绘制性能是GPU竞争的重要因素,硬件纹理单元在高性能GPU中依然是非常重要的固定功能逻辑。结合上文对于研究现状的分析,在全自主知识产权的国产嵌入式高性能统一着色架构GPU的研制中,研究和设计高效的专用纹理单元仍然具有重要意义。
2 纹理映射系统
完成纹理映射功能需要统一着色架构GPU多个子功能单元的协同工作,实现以下功能:纹理图像数据到DDR3的加载、纹理图像参数的配置和存储、像素的纹理地址产生、纹理请求在纹理映射单元TMU(Texture Map Unit)中的解析和执行。纹理映射系统如图1所示。

图1 纹理映射系统
图1中的纹理映射系统除了TMU,还包括为纹理映射操作提供输入请求、纹理图像数据和纹理参数的相关逻辑,包括统一着色处理器、图形命令解析单元、纹理图像加载单元、纹理图像参数存储器、DDR3和PCIe。结合图1所示的纹理映射系统,图形绘制接口(以OpenGL为例)定义的3D图形绘制原理描述纹理贴图操作的工作流程如下:
步骤1:使用图形绘制API为每个图元的顶点关联纹理坐标,统一着色处理器使用纹理矩阵完成纹理坐标的变换操作,使能1D、2D、3D和CUBE纹理映射;
步骤2:图形命令解析单元解析图形命令缓冲器发送的纹理图像加载函数和纹理参数配置函数;
步骤3:纹理图像加载单元依据图形命令解析单元发送的API类型、输入参数执行纹理图像数据到DDR3的加载;根据相应的使能开关,硬件自动产生mipmap图像层并存储在DDR3;将过滤模式、纹理内部格式、纹理图像的尺寸、纹理的维度和纹理比较函数等纹理的参数存储在纹理参数存储器;纹理参数存储器依据1D、2D、3D和CUBE纹理映射的使能开关,结合优先级规则产生纹理映射有效标识;
步骤4:光栅化单元以图元的顶点所绑定的纹理坐标作为输入源,通过插值操作产生每个片元(像素)的纹理坐标;
步骤5:统一着色处理器初步解析纹理存储器访问指令后向TMU发出纹理请求。TMU根据纹理请求所携带的控制参数依次执行如下操作:访问纹理参数存储器、计算lod、计算1~8个纹素采样地址、组装1~8个纹理存储器访问、执行1~8个纹素数据转换操作、执行纹素过滤和比较操作和纹素数据的归一化处理。以上操作全部执行完毕之后,TMU将最终处理的纹素颜色数据返回给统一着色处理器。
3 纹理引擎硬件体系结构
纹理引擎的硬件体系结构如图2所示。纹理引擎由6个主要的部分组成:纹理属性存储器、mipmap的层次细节(lod)计算逻辑、纹素地址产生、纹理cache、纹素数据格式转换、纹素过滤和纹素数据归一化单元。纹理参数存储器为纹理引擎的其他逻辑阶段提供控制信息,实现多模式可配置的纹理映射操作。

图2 纹理引擎的硬件体系结构
光栅化单元为每个像素通过插值操作计算出一组纹理坐标P(s,t,r,q),作为像素的输入属性进入统一着色核心执行像素着色操作。如果纹理使能开关有效,则统一着色核心将包含纹理坐标P的纹理请求转发给TMU,TMU使用纹理坐标P查询纹理图像(纹素数据组成的多维数组),实施临近采样或者4个空间上相邻纹素的多纹素采样,然后执行纹素过滤的线性插值操作。最终向统一着色核心返回一个fp32格式的RGBA纹素颜色数据。
基于以下原因,纹理引擎选择了动态可配置、流水化处理和多路并行结构。
① 纹理请求包含多个逻辑步骤:mipmap细节层次的确定、纹素地址的产生、纹素的收集和纹素的过滤。纹理请求的这些内部操作具有流水化、串行化的执行特征。
② 一方面,项目组自主研发的统一着色架构GPU的光栅化单元将空间上相邻的像素组织成2×2像素块,这种2×2像素块通常被称之为quad,TMU接收quad结构的纹理请求,4个空间上相邻的纹理请求并行流入和流出TMU。使用4路并行的流水线结构处理连续到来的2×2的像素块的纹理请求符合纹理请求的处理需求。另一方面,每个纹理请求具有多组需要能够被并行处理的数据。细节层次计算单元需要通过计算像素quad中4个相邻像素的纹理坐标的差值计算mipmap的细节层次(LOD);像素Quad的4个纹理请求的16个纹素的格式转换操作可以并行实施;像素Quad的纹理请求的4个纹理请求的16个纹素的颜色分量(R,G,B,A)的过滤操作可以并行实施。
③ 多模式的纹理贴图功能。纹理过滤模式和纹理内部格式是API可配置,因此,TMU的大多数逻辑操作阶段是可配置的。此外,纹理参数的不会非常频繁,所以动态配置的性能损失代价较低。
以下结合纹理映射操作数据处理特征详细描述TMU内部子功能单元的设计原理。
lod细节层次计算逻辑产生TMU的流水线“控制字”,流水线“控制字”顺着TMU的流水线向下传递,被纹素地址产生单元和纹理过滤单元逐步消费掉。由于纹理内部格式的种类众多,设计高效的纹理Cache和纹理映射单元非常困难。根据对典型应用程序的分析,考虑到设计复杂度,纹理过滤单元和纹理Cache以及纹素数据格式转换单元支持OpenGL图形API所定义的几种常用的纹理内部格式(例如RGBA8888,RGB565等)。
以2D纹理为例,纹素地址产生单元将每个纹理地址P(s,t)乘以纹理的宽、高,为每个纹理请求计算1/2/4/8纹素存储器地址(U,V)。将1/2/4/8纹素存储器地址(U,V)作为一个整体送给纹理Cache,当一组纹素数据返回之后,纹素数据被转发给纹素过滤单元之前,纹素数据格式转换器负责实现纹素数据的格式转换操作。
纹理引擎包含16个纹素数据格式转换器,每个纹素数据格式转换器将纹素转换为TMU内部流水线的数据格式。数据格式转换单元能够根据应用程序中的Opengl的API所定义的各种1D/2D/3D/CUBE的mipmap的纹理数据,各种过滤模式和各种内部纹理格式的控制下完成指定的数据格式转换功能,使得纹理引擎能够以高效率的方式处理各种类型的数据,适应各种绘制场景。
纹理引擎包含4个并行工作的纹素过滤单元,每个纹素过滤器为quad(2×2的像素块)内的1个像素的纹理请求的4个颜色分量(RGBA)并行实施带有权重的过滤操作。因此,对于一个quad,纹理引擎具有16个并行工作的过滤单元(每个纹理过滤器包含4个过滤单元)。纹素的权重值来自纹素地址(U,V)的U分量和V分量的小数部分。每个纹素过滤器根据Opengl API所定义的过滤模式(线性过滤,双线性过滤,三线性过滤)执行过滤操作。当2D纹理映射操作的过滤模式为线性过滤,则将4个权重值(Ufrac,Vfrac,1-Ufrac,1-Vfrac)和4组RGBA纹素数据作为纹素过滤器的输入,计算出1个纹素数据。纹素过滤单元可以被多种过滤模式所复用,因此采用全功能的纹素过滤器有利于减少计算资源的面积,而且纹素过滤单元总是处于忙状态。在最后一个处理步骤中,纹素数据归一化单元将TMU的过滤单元输出的纹素数据转换为像素着色器(统一着色核心)所需要的fp32格式的RGBA数据。
在纹理贴过程中,纹理数据蕴含大量空间和时间局部性,通常在一幅场景中需要执行纹理贴图的片元数量非常大,每个需要被贴图的片元(像素)需要执行多个纹理存储器的查询操作(例如,通常为1~8个纹素);相邻像素在执行纹理过滤操作阶段会使用相同的纹素数据;对于一幅图像的相邻几帧,通常所需要的纹理数据是相同。为了降低纹理映射操作的存储带宽需求,捕捉相邻片元(fragment或者像素)之间的数据重用性,纹理Cache成为图形渲染系统的必要组成部分。参见图2纹理引擎硬件结构,结合多种过滤模式的纹理采样特性,在TMU中集成了一种多端口、多存储体、非阻塞只读纹理Cache。纹理Cache位于纹素地址产生单元和纹素数据格式转换单元之间。纹理Cache每次为纹素过滤单元最多提供16个纹素,以便4个纹素过滤单元能够并行工作。使用二维的纹素坐标(U,V)作为纹理Cache的输入,纹理Cache负责输出对应的纹素数据。纹理Cache采用全相联结构,总容量为16 KB,每个Cache行为2 048 bit。纹理Cache包含一个缺失信息保持寄存器,用于支持非阻塞Cache的存储访问功能。在纹理Cache中存储压缩格式的纹理有利于提高Cache的空间利用率,使得Cache可以存储更多的数据,据此本文将纹理数据的解压缩逻辑设置在纹理Cache之后。解压缩操作比较简单,对于S3TC的每个4×4的纹素块,根据2 bit的颜色索引,使用2个额外的颜色值和2个基本的颜色值执行插值计算就可以得到的每个纹素的颜色值。
4 性能评价
本文基于Xilinx Vertex6 xc6v1x760构建FPGA原型开发平台设计和实现了具有硬件纹理引擎的GPU硬件结构。图3为4个OpenGL程序在FPGA原型开发平台的纹理贴图效果。测试程序集包含4个经典Opengl测试程序,图4(a)为Marbles,测试1D、3D纹理的点采样效果;图4(b)为Environment Mapping,测试CUBE纹理贴图的效果;图4(c)为Protechny,测试基于mipmap的纹理贴图效果;1个2D矩形像素区域;图4(d)为sunset,测试2D纹理的双线性过滤的绘制结果。本文以量化的方式对纹理引擎的性能进行了评测。当纹理引擎的工作频率为270 MHz,4个OpenGL程序的绘制分辨率为512×512,具有纹理引擎的GPU的硬件实现平均绘制性能可以达到35.5 fps。

图3 纹理映射的绘制效果
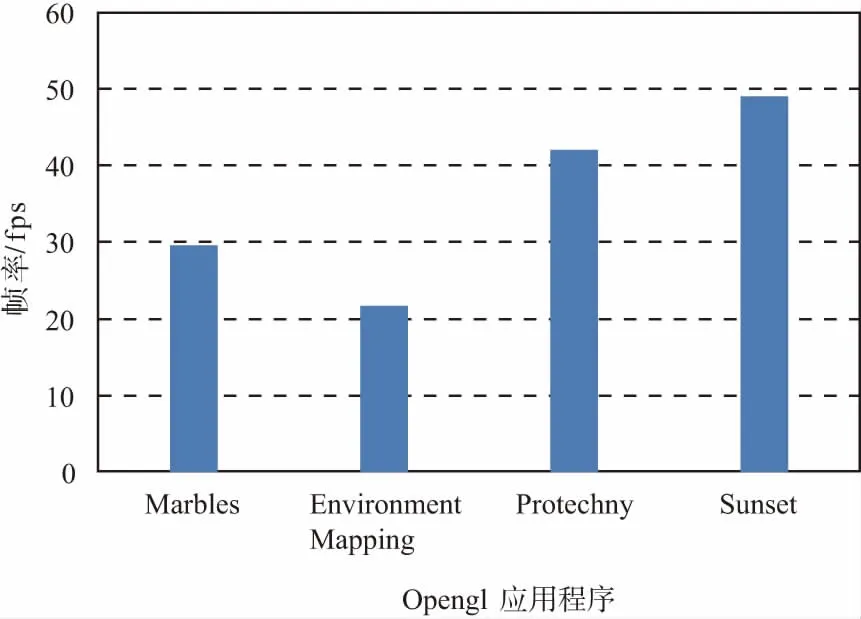
图4 Opengl测试程序的绘制性能
5 结束语
纹理请求的纹理采样操作、纹素数据格式转换操作和纹素过滤操作蕴含大量的数据并行性,经典的quad像素块结构具有并行处理纹理请求的需求。本文据此提出一种多路并行流水化纹理引擎的硬件体系结构。实验结果表明,本文的设计方案能够较好满足3D图形实时绘制的性能和功能需求。为了提高全自主知识产权国产图形处理器的可编程性,本文计划下一步研究和实现一款支持GLSL1.40标准的纹理处理器,使统一着色核心能够对用户定义的顶点和片段着色程序进行硬件加速。
[1] EUH J,CHITTARMURU J ,BURLESON W.A Low-Power Content-Adaptive Texture Mapping Architecture for Real Time 3D Graphics[C]∥2nd International Workshop on Power-aware Computer Systems,Springer-verlag berlin,2002:99-109.
[2] MOREIN S.ATI Radeon Hyperz Technology[C]∥Proc.of Hot3d Graphics Hardware Workshop,2000:1-24.
[3] AKENINE-MOLLER T,STROM J.Graphics Processing Units for Handhelds[J].IEEE,2008,96(5):779-789.
[4] ARNAU J M,PARCERISA J M,XEKALAKIS P.Boosting Mobile GPU Performance With A Decoupled Access/Execute Fragment Processor[C]∥ISCA 2012.IEEE Computer Society,2012:84-93.
[5] KIM H S,LEE J,KIM H,KANG S,et.al.A Lossless Color Image Compression Architecture Using a Parallel Golomb-Rice Hardware CODEC[J].IEEE Transactions on Circuits and Systems for Video Technology,2011,21(11):1581-1587.
[6] LIOU J Y.Re-visit Blocking Texture Cache Design for Modern GPU[C]∥ISOCC2014.IEEE,2014:288-289.
[7] DOGGETT M.Texture Caches[C]∥IEEE Micro,IEEE Computer Society,2012:136-141.
[8] NAWANDHAR A A.3D Graphics Texture Compression and Its Recent Trends[J].International Journal of Engineering Research and Applications (IJERA),2013,3(2):1381-1385.
[9] MANTOR M.AMD RadeonTMhd 7970 with Graphics Core Next (GCN) Architecture[R].IEEE,2012:1-35.
[10] IMAGINATION.The Architecture of High-end Mobile Graphics Hardware[C/OL]∥2013-01-01,http:∥www.imgtec.com
[11] IAN B.The ARM© MaliTM-T880 Mobile GPU[J].IEEE,2016:1-27.
[12] NVIDIA.NVIDIA Tegra 4 Family GPU Architecture[C/OL]∥2014-04-27.http:∥www.nvidia.com/docs/IO∥116757/Tegra_4_GPU_Whitepaper_FINALv2.pdf,2014.
[13] BROADCOM.VideoCore IV 3D architecture reference guide[C]∥VideoCoreIV-AG100-R,2013.
[14] 卢章平,丁立军,戴立玲.基于分类的纹理映射方法综述[J].江苏大学学报(自然科学版),27(5A),2006:13-16.
[15] KESSENICH J.The OpenGL Shading Language[M].The Khronos Group Inc,2009.
[16] 简洪登,范湘涛.基于GLSL的多重视频纹理映射与融合[J].计算机程与计,2014,35(11):3873-3878.
[17] 周珍艮.纹理映射算法研究与FGPA实现[D].合肥:中国科学技术大学,2007.
[18] 赵国宇,郭炜,常轶松.一种高效纹理映射单元的硬件体系结构设计[J].计算机工程,2013,39(5):92-105.
[19] 焦继业,李涛,杜慧敏,等.移动图形处理器的现状、技术及其发展[J].计算机辅助设计与图形学学报,2015,27(6):1005-1016.
[20] 董梁,刘海,韩俊刚.图形处理器中光照和纹理映射的设计与仿真实现[J].计算机科学,2011,38(2):284-301.
